 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJiajun Liu
Recall, Retrieve and Reason: Towards Better In-Context Relation Extraction
Apr 27, 2024
Relation extraction (RE) aims to identify relations between entities mentioned in texts. Although large language models (LLMs) have demonstrated impressive in-context learning (ICL) abilities in various tasks, they still suffer from poor performances compared to most supervised fine-tuned RE methods. Utilizing ICL for RE with LLMs encounters two challenges: (1) retrieving good demonstrations from training examples, and (2) enabling LLMs exhibit strong ICL abilities in RE. On the one hand, retrieving good demonstrations is a non-trivial process in RE, which easily results in low relevance regarding entities and relations. On the other hand, ICL with an LLM achieves poor performance in RE while RE is different from language modeling in nature or the LLM is not large enough. In this work, we propose a novel recall-retrieve-reason RE framework that synergizes LLMs with retrieval corpora (training examples) to enable relevant retrieving and reliable in-context reasoning. Specifically, we distill the consistently ontological knowledge from training datasets to let LLMs generate relevant entity pairs grounded by retrieval corpora as valid queries. These entity pairs are then used to retrieve relevant training examples from the retrieval corpora as demonstrations for LLMs to conduct better ICL via instruction tuning. Extensive experiments on different LLMs and RE datasets demonstrate that our method generates relevant and valid entity pairs and boosts ICL abilities of LLMs, achieving competitive or new state-of-the-art performance on sentence-level RE compared to previous supervised fine-tuning methods and ICL-based methods.
Meta In-Context Learning Makes Large Language Models Better Zero and Few-Shot Relation Extractors
Apr 27, 2024Relation extraction (RE) is an important task that aims to identify the relationships between entities in texts. While large language models (LLMs) have revealed remarkable in-context learning (ICL) capability for general zero and few-shot learning, recent studies indicate that current LLMs still struggle with zero and few-shot RE. Previous studies are mainly dedicated to design prompt formats and select good examples for improving ICL-based RE. Although both factors are vital for ICL, if one can fundamentally boost the ICL capability of LLMs in RE, the zero and few-shot RE performance via ICL would be significantly improved. To this end, we introduce \textsc{Micre} (\textbf{M}eta \textbf{I}n-\textbf{C}ontext learning of LLMs for \textbf{R}elation \textbf{E}xtraction), a new meta-training framework for zero and few-shot RE where an LLM is tuned to do ICL on a diverse collection of RE datasets (i.e., learning to learn in context for RE). Through meta-training, the model becomes more effectively to learn a new RE task in context by conditioning on a few training examples with no parameter updates or task-specific templates at inference time, enabling better zero and few-shot task generalization. We experiment \textsc{Micre} on various LLMs with different model scales and 12 public RE datasets, and then evaluate it on unseen RE benchmarks under zero and few-shot settings. \textsc{Micre} delivers comparable or superior performance compared to a range of baselines including supervised fine-tuning and typical in-context learning methods. We find that the gains are particular significant for larger model scales, and using a diverse set of the meta-training RE datasets is key to improvements. Empirically, we show that \textsc{Micre} can transfer the relation semantic knowledge via relation label name during inference on target RE datasets.
Empirical Analysis of Dialogue Relation Extraction with Large Language Models
Apr 27, 2024Dialogue relation extraction (DRE) aims to extract relations between two arguments within a dialogue, which is more challenging than standard RE due to the higher person pronoun frequency and lower information density in dialogues. However, existing DRE methods still suffer from two serious issues: (1) hard to capture long and sparse multi-turn information, and (2) struggle to extract golden relations based on partial dialogues, which motivates us to discover more effective methods that can alleviate the above issues. We notice that the rise of large language models (LLMs) has sparked considerable interest in evaluating their performance across diverse tasks. To this end, we initially investigate the capabilities of different LLMs in DRE, considering both proprietary models and open-source models. Interestingly, we discover that LLMs significantly alleviate two issues in existing DRE methods. Generally, we have following findings: (1) scaling up model size substantially boosts the overall DRE performance and achieves exceptional results, tackling the difficulty of capturing long and sparse multi-turn information; (2) LLMs encounter with much smaller performance drop from entire dialogue setting to partial dialogue setting compared to existing methods; (3) LLMs deliver competitive or superior performances under both full-shot and few-shot settings compared to current state-of-the-art; (4) LLMs show modest performances on inverse relations but much stronger improvements on general relations, and they can handle dialogues of various lengths especially for longer sequences.
YNetr: Dual-Encoder architecture on Plain Scan Liver Tumors (PSLT)
Mar 30, 2024Background: Liver tumors are abnormal growths in the liver that can be either benign or malignant, with liver cancer being a significant health concern worldwide. However, there is no dataset for plain scan segmentation of liver tumors, nor any related algorithms. To fill this gap, we propose Plain Scan Liver Tumors(PSLT) and YNetr. Methods: A collection of 40 liver tumor plain scan segmentation datasets was assembled and annotated. Concurrently, we utilized Dice coefficient as the metric for assessing the segmentation outcomes produced by YNetr, having advantage of capturing different frequency information. Results: The YNetr model achieved a Dice coefficient of 62.63% on the PSLT dataset, surpassing the other publicly available model by an accuracy margin of 1.22%. Comparative evaluations were conducted against a range of models including UNet 3+, XNet, UNetr, Swin UNetr, Trans-BTS, COTr, nnUNetv2 (2D), nnUNetv2 (3D fullres), MedNext (2D) and MedNext(3D fullres). Conclusions: We not only proposed a dataset named PSLT(Plain Scan Liver Tumors), but also explored a structure called YNetr that utilizes wavelet transform to extract different frequency information, which having the SOTA in PSLT by experiments.
Unlocking Instructive In-Context Learning with Tabular Prompting for Relational Triple Extraction
Feb 21, 2024The in-context learning (ICL) for relational triple extraction (RTE) has achieved promising performance, but still encounters two key challenges: (1) how to design effective prompts and (2) how to select proper demonstrations. Existing methods, however, fail to address these challenges appropriately. On the one hand, they usually recast RTE task to text-to-text prompting formats, which is unnatural and results in a mismatch between the output format at the pre-training time and the inference time for large language models (LLMs). On the other hand, they only utilize surface natural language features and lack consideration of triple semantics in sample selection. These issues are blocking improved performance in ICL for RTE, thus we aim to tackle prompt designing and sample selection challenges simultaneously. To this end, we devise a tabular prompting for RTE (\textsc{TableIE}) which frames RTE task into a table generation task to incorporate explicit structured information into ICL, facilitating conversion of outputs to RTE structures. Then we propose instructive in-context learning (I$^2$CL) which only selects and annotates a few samples considering internal triple semantics in massive unlabeled samples.
Content-Conditioned Generation of Stylized Free hand Sketches
Jan 09, 2024In recent years, the recognition of free-hand sketches has remained a popular task. However, in some special fields such as the military field, free-hand sketches are difficult to sample on a large scale. Common data augmentation and image generation techniques are difficult to produce images with various free-hand sketching styles. Therefore, the recognition and segmentation tasks in related fields are limited. In this paper, we propose a novel adversarial generative network that can accurately generate realistic free-hand sketches with various styles. We explore the performance of the model, including using styles randomly sampled from a prior normal distribution to generate images with various free-hand sketching styles, disentangling the painters' styles from known free-hand sketches to generate images with specific styles, and generating images of unknown classes that are not in the training set. We further demonstrate with qualitative and quantitative evaluations our advantages in visual quality, content accuracy, and style imitation on SketchIME.
SegRefiner: Towards Model-Agnostic Segmentation Refinement with Discrete Diffusion Process
Dec 19, 2023In this paper, we explore a principal way to enhance the quality of object masks produced by different segmentation models. We propose a model-agnostic solution called SegRefiner, which offers a novel perspective on this problem by interpreting segmentation refinement as a data generation process. As a result, the refinement process can be smoothly implemented through a series of denoising diffusion steps. Specifically, SegRefiner takes coarse masks as inputs and refines them using a discrete diffusion process. By predicting the label and corresponding states-transition probabilities for each pixel, SegRefiner progressively refines the noisy masks in a conditional denoising manner. To assess the effectiveness of SegRefiner, we conduct comprehensive experiments on various segmentation tasks, including semantic segmentation, instance segmentation, and dichotomous image segmentation. The results demonstrate the superiority of our SegRefiner from multiple aspects. Firstly, it consistently improves both the segmentation metrics and boundary metrics across different types of coarse masks. Secondly, it outperforms previous model-agnostic refinement methods by a significant margin. Lastly, it exhibits a strong capability to capture extremely fine details when refining high-resolution images. The source code and trained models are available at https://github.com/MengyuWang826/SegRefiner.
GTP-ViT: Efficient Vision Transformers via Graph-based Token Propagation
Nov 06, 2023Vision Transformers (ViTs) have revolutionized the field of computer vision, yet their deployments on resource-constrained devices remain challenging due to high computational demands. To expedite pre-trained ViTs, token pruning and token merging approaches have been developed, which aim at reducing the number of tokens involved in the computation. However, these methods still have some limitations, such as image information loss from pruned tokens and inefficiency in the token-matching process. In this paper, we introduce a novel Graph-based Token Propagation (GTP) method to resolve the challenge of balancing model efficiency and information preservation for efficient ViTs. Inspired by graph summarization algorithms, GTP meticulously propagates less significant tokens' information to spatially and semantically connected tokens that are of greater importance. Consequently, the remaining few tokens serve as a summarization of the entire token graph, allowing the method to reduce computational complexity while preserving essential information of eliminated tokens. Combined with an innovative token selection strategy, GTP can efficiently identify image tokens to be propagated. Extensive experiments have validated GTP's effectiveness, demonstrating both efficiency and performance improvements. Specifically, GTP decreases the computational complexity of both DeiT-S and DeiT-B by up to 26% with only a minimal 0.3% accuracy drop on ImageNet-1K without finetuning, and remarkably surpasses the state-of-the-art token merging method on various backbones at an even faster inference speed. The source code is available at https://github.com/Ackesnal/GTP-ViT.
Understanding the Effects of Projectors in Knowledge Distillation
Oct 26, 2023Conventionally, during the knowledge distillation process (e.g. feature distillation), an additional projector is often required to perform feature transformation due to the dimension mismatch between the teacher and the student networks. Interestingly, we discovered that even if the student and the teacher have the same feature dimensions, adding a projector still helps to improve the distillation performance. In addition, projectors even improve logit distillation if we add them to the architecture too. Inspired by these surprising findings and the general lack of understanding of the projectors in the knowledge distillation process from existing literature, this paper investigates the implicit role that projectors play but so far have been overlooked. Our empirical study shows that the student with a projector (1) obtains a better trade-off between the training accuracy and the testing accuracy compared to the student without a projector when it has the same feature dimensions as the teacher, (2) better preserves its similarity to the teacher beyond shallow and numeric resemblance, from the view of Centered Kernel Alignment (CKA), and (3) avoids being over-confident as the teacher does at the testing phase. Motivated by the positive effects of projectors, we propose a projector ensemble-based feature distillation method to further improve distillation performance. Despite the simplicity of the proposed strategy, empirical results from the evaluation of classification tasks on benchmark datasets demonstrate the superior classification performance of our method on a broad range of teacher-student pairs and verify from the aspects of CKA and model calibration that the student's features are of improved quality with the projector ensemble design.
No Token Left Behind: Efficient Vision Transformer via Dynamic Token Idling
Oct 09, 2023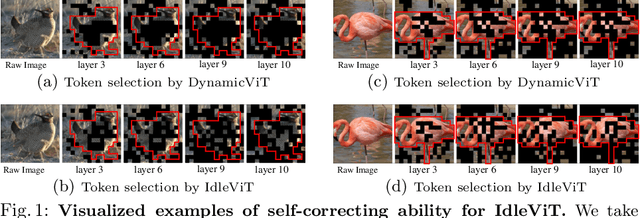
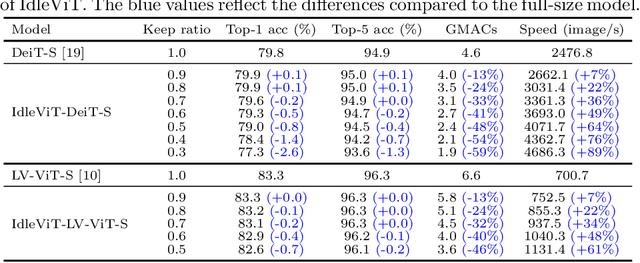
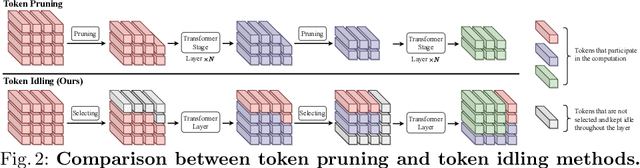

Vision Transformers (ViTs) have demonstrated outstanding performance in computer vision tasks, yet their high computational complexity prevents their deployment in computing resource-constrained environments. Various token pruning techniques have been introduced to alleviate the high computational burden of ViTs by dynamically dropping image tokens. However, some undesirable pruning at early stages may result in permanent loss of image information in subsequent layers, consequently hindering model performance. To address this problem, we propose IdleViT, a dynamic token-idle-based method that achieves an excellent trade-off between performance and efficiency. Specifically, in each layer, IdleViT selects a subset of the image tokens to participate in computations while keeping the rest of the tokens idle and directly passing them to this layer's output. By allowing the idle tokens to be re-selected in the following layers, IdleViT mitigates the negative impact of improper pruning in the early stages. Furthermore, inspired by the normalized graph cut, we devise a token cut loss on the attention map as regularization to improve IdleViT's token selection ability. Our method is simple yet effective and can be extended to pyramid ViTs since no token is completely dropped. Extensive experimental results on various ViT architectures have shown that IdleViT can diminish the complexity of pretrained ViTs by up to 33\% with no more than 0.2\% accuracy decrease on ImageNet, after finetuning for only 30 epochs. Notably, when the keep ratio is 0.5, IdleViT outperforms the state-of-the-art EViT on DeiT-S by 0.5\% higher accuracy and even faster inference speed. The source code is available in the supplementary material.