 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYudong Chen
Prelimit Coupling and Steady-State Convergence of Constant-stepsize Nonsmooth Contractive SA
Apr 09, 2024
Motivated by Q-learning, we study nonsmooth contractive stochastic approximation (SA) with constant stepsize. We focus on two important classes of dynamics: 1) nonsmooth contractive SA with additive noise, and 2) synchronous and asynchronous Q-learning, which features both additive and multiplicative noise. For both dynamics, we establish weak convergence of the iterates to a stationary limit distribution in Wasserstein distance. Furthermore, we propose a prelimit coupling technique for establishing steady-state convergence and characterize the limit of the stationary distribution as the stepsize goes to zero. Using this result, we derive that the asymptotic bias of nonsmooth SA is proportional to the square root of the stepsize, which stands in sharp contrast to smooth SA. This bias characterization allows for the use of Richardson-Romberg extrapolation for bias reduction in nonsmooth SA.
Span-Based Optimal Sample Complexity for Weakly Communicating and General Average Reward MDPs
Mar 18, 2024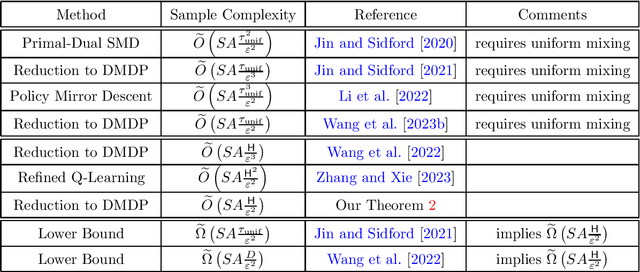
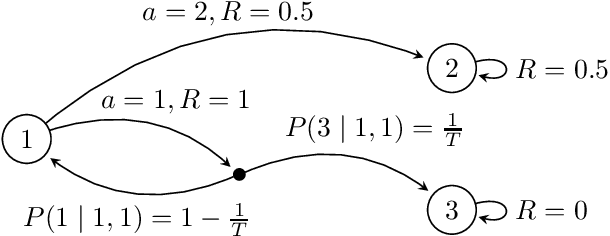
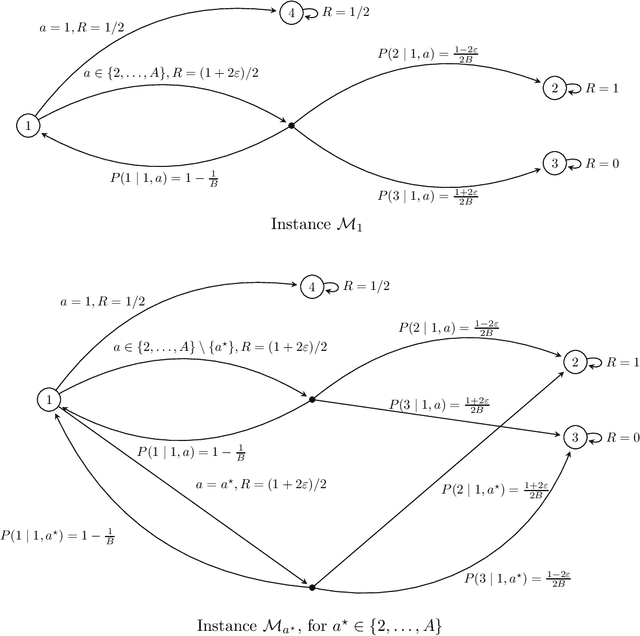
We study the sample complexity of learning an $\epsilon$-optimal policy in an average-reward Markov decision process (MDP) under a generative model. For weakly communicating MDPs, we establish the complexity bound $\tilde{O}(SA\frac{H}{\epsilon^2})$, where $H$ is the span of the bias function of the optimal policy and $SA$ is the cardinality of the state-action space. Our result is the first that is minimax optimal (up to log factors) in all parameters $S,A,H$ and $\epsilon$, improving on existing work that either assumes uniformly bounded mixing times for all policies or has suboptimal dependence on the parameters. We further investigate sample complexity in general (non-weakly-communicating) average-reward MDPs. We argue a new transient time parameter $B$ is necessary, establish an $\tilde{O}(SA\frac{B+H}{\epsilon^2})$ complexity bound, and prove a matching (up to log factors) minimax lower bound. Both results are based on reducing the average-reward MDP to a discounted MDP, which requires new ideas in the general setting. To establish the optimality of this reduction, we develop improved bounds for $\gamma$-discounted MDPs, showing that $\tilde{\Omega}\left(SA\frac{H}{(1-\gamma)^2\epsilon^2}\right)$ samples suffice to learn an $\epsilon$-optimal policy in weakly communicating MDPs under the regime that $\gamma\geq 1-1/H$, and $\tilde{\Omega}\left(SA\frac{B+H}{(1-\gamma)^2\epsilon^2}\right)$ samples suffice in general MDPs when $\gamma\geq 1-\frac{1}{B+H}$. Both these results circumvent the well-known lower bound of $\tilde{\Omega}\left(SA\frac{1}{(1-\gamma)^3\epsilon^2}\right)$ for arbitrary $\gamma$-discounted MDPs. Our analysis develops upper bounds on certain instance-dependent variance parameters in terms of the span and transient time parameters. The weakly communicating bounds are tighter than those based on the mixing time or diameter of the MDP and may be of broader use.
Entry-Specific Bounds for Low-Rank Matrix Completion under Highly Non-Uniform Sampling
Feb 29, 2024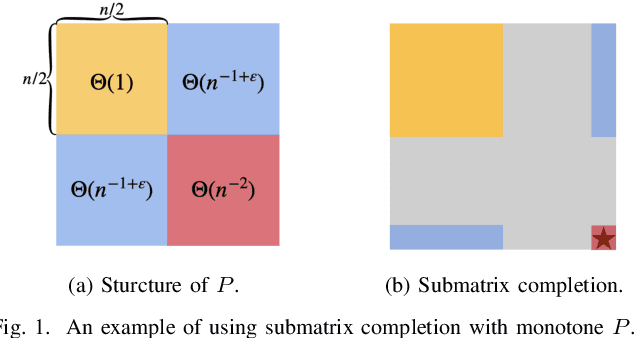
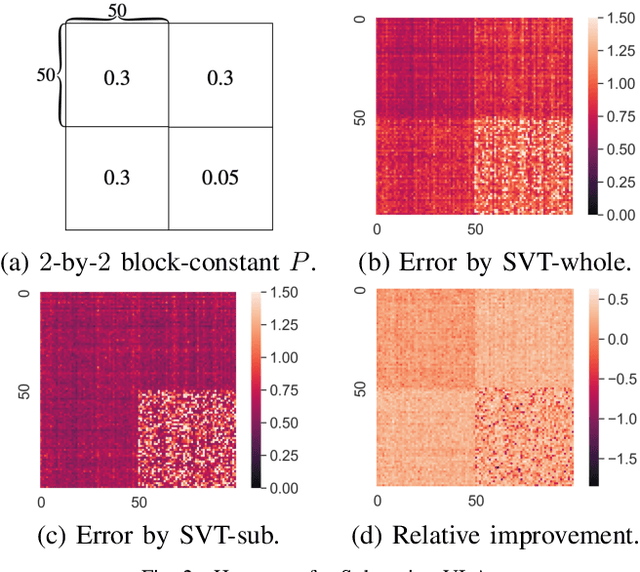
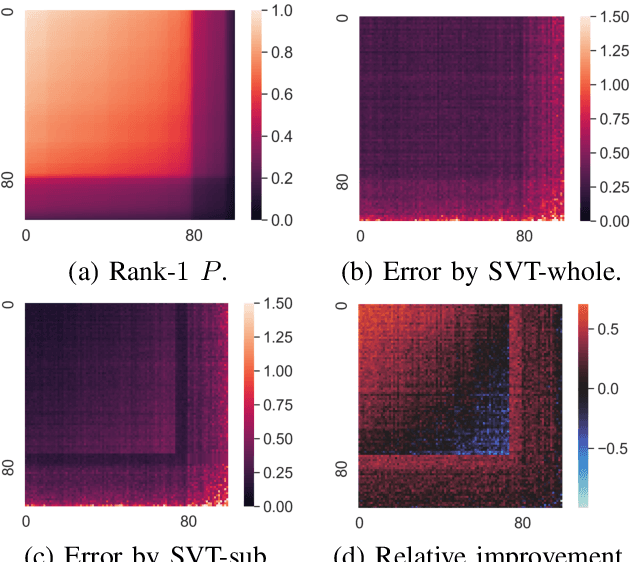
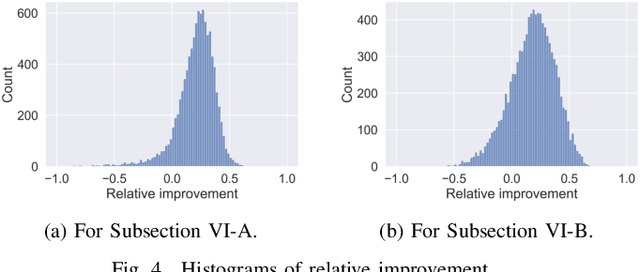
Low-rank matrix completion concerns the problem of estimating unobserved entries in a matrix using a sparse set of observed entries. We consider the non-uniform setting where the observed entries are sampled with highly varying probabilities, potentially with different asymptotic scalings. We show that under structured sampling probabilities, it is often better and sometimes optimal to run estimation algorithms on a smaller submatrix rather than the entire matrix. In particular, we prove error upper bounds customized to each entry, which match the minimax lower bounds under certain conditions. Our bounds characterize the hardness of estimating each entry as a function of the localized sampling probabilities. We provide numerical experiments that confirm our theoretical findings.
Unichain and Aperiodicity are Sufficient for Asymptotic Optimality of Average-Reward Restless Bandits
Feb 08, 2024We consider the infinite-horizon, average-reward restless bandit problem in discrete time. We propose a new class of policies that are designed to drive a progressively larger subset of arms toward the optimal distribution. We show that our policies are asymptotically optimal with an $O(1/\sqrt{N})$ optimality gap for an $N$-armed problem, provided that the single-armed relaxed problem is unichain and aperiodic. Our approach departs from most existing work that focuses on index or priority policies, which rely on the Uniform Global Attractor Property (UGAP) to guarantee convergence to the optimum, or a recently developed simulation-based policy, which requires a Synchronization Assumption (SA).
Effectiveness of Constant Stepsize in Markovian LSA and Statistical Inference
Dec 18, 2023In this paper, we study the effectiveness of using a constant stepsize in statistical inference via linear stochastic approximation (LSA) algorithms with Markovian data. After establishing a Central Limit Theorem (CLT), we outline an inference procedure that uses averaged LSA iterates to construct confidence intervals (CIs). Our procedure leverages the fast mixing property of constant-stepsize LSA for better covariance estimation and employs Richardson-Romberg (RR) extrapolation to reduce the bias induced by constant stepsize and Markovian data. We develop theoretical results for guiding stepsize selection in RR extrapolation, and identify several important settings where the bias provably vanishes even without extrapolation. We conduct extensive numerical experiments and compare against classical inference approaches. Our results show that using a constant stepsize enjoys easy hyperparameter tuning, fast convergence, and consistently better CI coverage, especially when data is limited.
Span-Based Optimal Sample Complexity for Average Reward MDPs
Nov 22, 2023We study the sample complexity of learning an $\varepsilon$-optimal policy in an average-reward Markov decision process (MDP) under a generative model. We establish the complexity bound $\widetilde{O}\left(SA\frac{H}{\varepsilon^2} \right)$, where $H$ is the span of the bias function of the optimal policy and $SA$ is the cardinality of the state-action space. Our result is the first that is minimax optimal (up to log factors) in all parameters $S,A,H$ and $\varepsilon$, improving on existing work that either assumes uniformly bounded mixing times for all policies or has suboptimal dependence on the parameters. Our result is based on reducing the average-reward MDP to a discounted MDP. To establish the optimality of this reduction, we develop improved bounds for $\gamma$-discounted MDPs, showing that $\widetilde{O}\left(SA\frac{H}{(1-\gamma)^2\varepsilon^2} \right)$ samples suffice to learn a $\varepsilon$-optimal policy in weakly communicating MDPs under the regime that $\gamma \geq 1 - \frac{1}{H}$, circumventing the well-known lower bound of $\widetilde{\Omega}\left(SA\frac{1}{(1-\gamma)^3\varepsilon^2} \right)$ for general $\gamma$-discounted MDPs. Our analysis develops upper bounds on certain instance-dependent variance parameters in terms of the span parameter. These bounds are tighter than those based on the mixing time or diameter of the MDP and may be of broader use.
GTP-ViT: Efficient Vision Transformers via Graph-based Token Propagation
Nov 06, 2023Vision Transformers (ViTs) have revolutionized the field of computer vision, yet their deployments on resource-constrained devices remain challenging due to high computational demands. To expedite pre-trained ViTs, token pruning and token merging approaches have been developed, which aim at reducing the number of tokens involved in the computation. However, these methods still have some limitations, such as image information loss from pruned tokens and inefficiency in the token-matching process. In this paper, we introduce a novel Graph-based Token Propagation (GTP) method to resolve the challenge of balancing model efficiency and information preservation for efficient ViTs. Inspired by graph summarization algorithms, GTP meticulously propagates less significant tokens' information to spatially and semantically connected tokens that are of greater importance. Consequently, the remaining few tokens serve as a summarization of the entire token graph, allowing the method to reduce computational complexity while preserving essential information of eliminated tokens. Combined with an innovative token selection strategy, GTP can efficiently identify image tokens to be propagated. Extensive experiments have validated GTP's effectiveness, demonstrating both efficiency and performance improvements. Specifically, GTP decreases the computational complexity of both DeiT-S and DeiT-B by up to 26% with only a minimal 0.3% accuracy drop on ImageNet-1K without finetuning, and remarkably surpasses the state-of-the-art token merging method on various backbones at an even faster inference speed. The source code is available at https://github.com/Ackesnal/GTP-ViT.
Minimally Modifying a Markov Game to Achieve Any Nash Equilibrium and Value
Nov 02, 2023We study the game modification problem, where a benevolent game designer or a malevolent adversary modifies the reward function of a zero-sum Markov game so that a target deterministic or stochastic policy profile becomes the unique Markov perfect Nash equilibrium and has a value within a target range, in a way that minimizes the modification cost. We characterize the set of policy profiles that can be installed as the unique equilibrium of some game, and establish sufficient and necessary conditions for successful installation. We propose an efficient algorithm, which solves a convex optimization problem with linear constraints and then performs random perturbation, to obtain a modification plan with a near-optimal cost.
Understanding the Effects of Projectors in Knowledge Distillation
Oct 26, 2023Conventionally, during the knowledge distillation process (e.g. feature distillation), an additional projector is often required to perform feature transformation due to the dimension mismatch between the teacher and the student networks. Interestingly, we discovered that even if the student and the teacher have the same feature dimensions, adding a projector still helps to improve the distillation performance. In addition, projectors even improve logit distillation if we add them to the architecture too. Inspired by these surprising findings and the general lack of understanding of the projectors in the knowledge distillation process from existing literature, this paper investigates the implicit role that projectors play but so far have been overlooked. Our empirical study shows that the student with a projector (1) obtains a better trade-off between the training accuracy and the testing accuracy compared to the student without a projector when it has the same feature dimensions as the teacher, (2) better preserves its similarity to the teacher beyond shallow and numeric resemblance, from the view of Centered Kernel Alignment (CKA), and (3) avoids being over-confident as the teacher does at the testing phase. Motivated by the positive effects of projectors, we propose a projector ensemble-based feature distillation method to further improve distillation performance. Despite the simplicity of the proposed strategy, empirical results from the evaluation of classification tasks on benchmark datasets demonstrate the superior classification performance of our method on a broad range of teacher-student pairs and verify from the aspects of CKA and model calibration that the student's features are of improved quality with the projector ensemble design.
No Token Left Behind: Efficient Vision Transformer via Dynamic Token Idling
Oct 09, 2023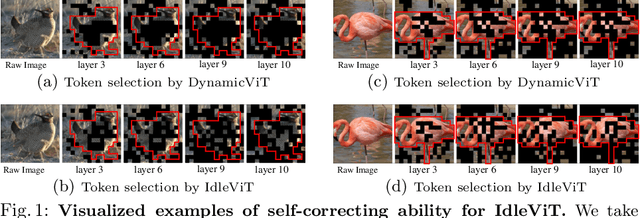
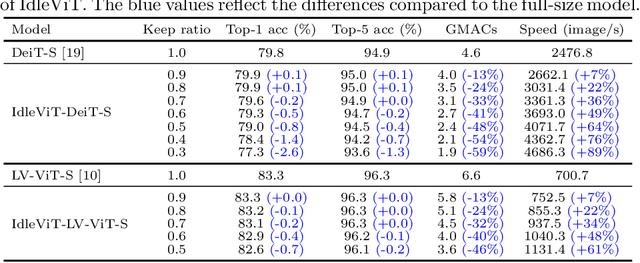
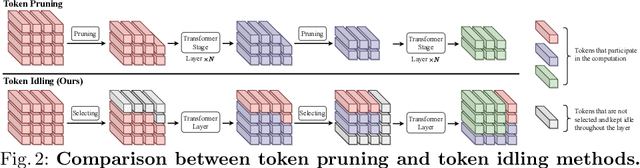

Vision Transformers (ViTs) have demonstrated outstanding performance in computer vision tasks, yet their high computational complexity prevents their deployment in computing resource-constrained environments. Various token pruning techniques have been introduced to alleviate the high computational burden of ViTs by dynamically dropping image tokens. However, some undesirable pruning at early stages may result in permanent loss of image information in subsequent layers, consequently hindering model performance. To address this problem, we propose IdleViT, a dynamic token-idle-based method that achieves an excellent trade-off between performance and efficiency. Specifically, in each layer, IdleViT selects a subset of the image tokens to participate in computations while keeping the rest of the tokens idle and directly passing them to this layer's output. By allowing the idle tokens to be re-selected in the following layers, IdleViT mitigates the negative impact of improper pruning in the early stages. Furthermore, inspired by the normalized graph cut, we devise a token cut loss on the attention map as regularization to improve IdleViT's token selection ability. Our method is simple yet effective and can be extended to pyramid ViTs since no token is completely dropped. Extensive experimental results on various ViT architectures have shown that IdleViT can diminish the complexity of pretrained ViTs by up to 33\% with no more than 0.2\% accuracy decrease on ImageNet, after finetuning for only 30 epochs. Notably, when the keep ratio is 0.5, IdleViT outperforms the state-of-the-art EViT on DeiT-S by 0.5\% higher accuracy and even faster inference speed. The source code is available in the supplementary material.