 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIvan Vulić
Aligning with Human Judgement: The Role of Pairwise Preference in Large Language Model Evaluators
Mar 26, 2024
Large Language Models (LLMs) have demonstrated promising capabilities as automatic evaluators in assessing the quality of generated natural language. However, LLMs still exhibit biases in evaluation and often struggle to generate coherent evaluations that align with human assessments. In this work, we first conduct a systematic study of the misalignment between LLM evaluators and human judgement, revealing that existing calibration methods aimed at mitigating biases are insufficient for effectively aligning LLM evaluators. Inspired by the use of preference data in RLHF, we formulate the evaluation as a ranking problem and introduce Pairwise-preference Search (PairS), an uncertainty-guided search method that employs LLMs to conduct pairwise comparisons and efficiently ranks candidate texts. PairS achieves state-of-the-art performance on representative evaluation tasks and demonstrates significant improvements over direct scoring. Furthermore, we provide insights into the role of pairwise preference in quantifying the transitivity of LLMs and demonstrate how PairS benefits from calibration.
Analyzing and Adapting Large Language Models for Few-Shot Multilingual NLU: Are We There Yet?
Mar 04, 2024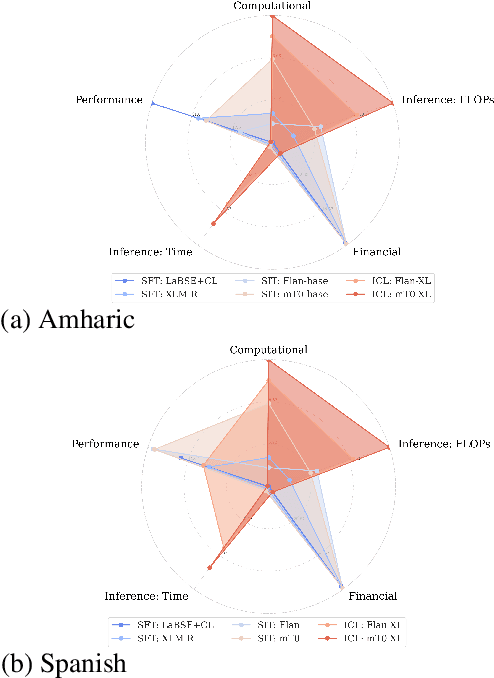

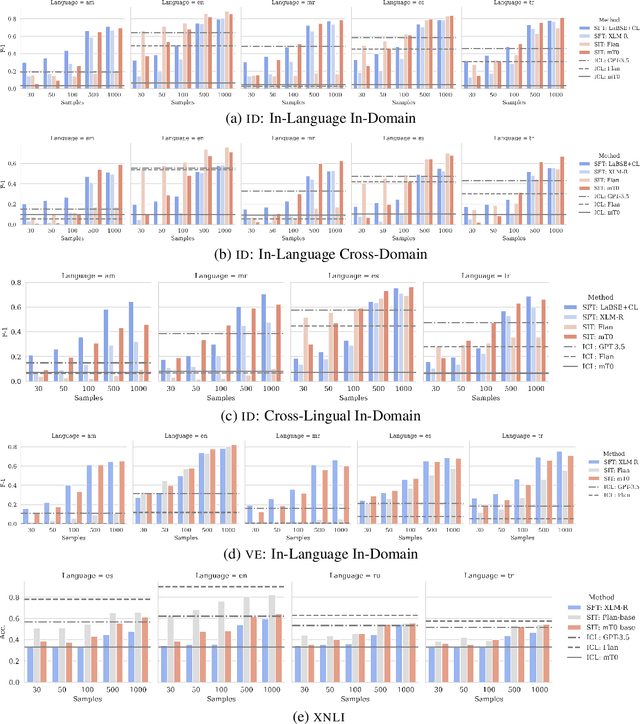
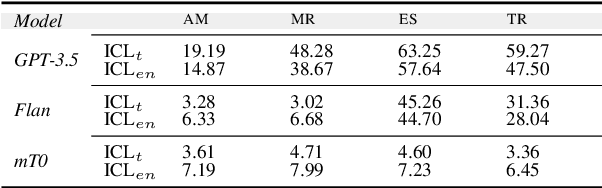
Supervised fine-tuning (SFT), supervised instruction tuning (SIT) and in-context learning (ICL) are three alternative, de facto standard approaches to few-shot learning. ICL has gained popularity recently with the advent of LLMs due to its simplicity and sample efficiency. Prior research has conducted only limited investigation into how these approaches work for multilingual few-shot learning, and the focus so far has been mostly on their performance. In this work, we present an extensive and systematic comparison of the three approaches, testing them on 6 high- and low-resource languages, three different NLU tasks, and a myriad of language and domain setups. Importantly, performance is only one aspect of the comparison, where we also analyse the approaches through the optics of their computational, inference and financial costs. Our observations show that supervised instruction tuning has the best trade-off between performance and resource requirements. As another contribution, we analyse the impact of target language adaptation of pretrained LLMs and find that the standard adaptation approaches can (superficially) improve target language generation capabilities, but language understanding elicited through ICL does not improve and remains limited, with low scores especially for low-resource languages.
Unmemorization in Large Language Models via Self-Distillation and Deliberate Imagination
Feb 15, 2024While displaying impressive generation capabilities across many tasks, Large Language Models (LLMs) still struggle with crucial issues of privacy violation and unwanted exposure of sensitive data. This raises an essential question: how should we prevent such undesired behavior of LLMs while maintaining their strong generation and natural language understanding (NLU) capabilities? In this work, we introduce a novel approach termed deliberate imagination in the context of LLM unlearning. Instead of trying to forget memorized data, we employ a self-distillation framework, guiding LLMs to deliberately imagine alternative scenarios. As demonstrated in a wide range of experiments, the proposed method not only effectively unlearns targeted text but also preserves the LLMs' capabilities in open-ended generation tasks as well as in NLU tasks. Our results demonstrate the usefulness of this approach across different models and sizes, and also with parameter-efficient fine-tuning, offering a novel pathway to addressing the challenges with private and sensitive data in LLM applications.
Self-Augmented In-Context Learning for Unsupervised Word Translation
Feb 15, 2024Recent work has shown that, while large language models (LLMs) demonstrate strong word translation or bilingual lexicon induction (BLI) capabilities in few-shot setups, they still cannot match the performance of 'traditional' mapping-based approaches in the unsupervised scenario where no seed translation pairs are available, especially for lower-resource languages. To address this challenge with LLMs, we propose self-augmented in-context learning (SAIL) for unsupervised BLI: starting from a zero-shot prompt, SAIL iteratively induces a set of high-confidence word translation pairs for in-context learning (ICL) from an LLM, which it then reapplies to the same LLM in the ICL fashion. Our method shows substantial gains over zero-shot prompting of LLMs on two established BLI benchmarks spanning a wide range of language pairs, also outperforming mapping-based baselines across the board. In addition to achieving state-of-the-art unsupervised BLI performance, we also conduct comprehensive analyses on SAIL and discuss its limitations.
Scaling Sparse Fine-Tuning to Large Language Models
Feb 02, 2024Large Language Models (LLMs) are difficult to fully fine-tune (e.g., with instructions or human feedback) due to their sheer number of parameters. A family of parameter-efficient sparse fine-tuning methods have proven promising in terms of performance but their memory requirements increase proportionally to the size of the LLMs. In this work, we scale sparse fine-tuning to state-of-the-art LLMs like LLaMA 2 7B and 13B. We propose SpIEL, a novel sparse fine-tuning method which, for a desired density level, maintains an array of parameter indices and the deltas of these parameters relative to their pretrained values. It iterates over: (a) updating the active deltas, (b) pruning indices (based on the change of magnitude of their deltas) and (c) regrowth of indices. For regrowth, we explore two criteria based on either the accumulated gradients of a few candidate parameters or their approximate momenta estimated using the efficient SM3 optimizer. We experiment with instruction-tuning of LLMs on standard dataset mixtures, finding that SpIEL is often superior to popular parameter-efficient fine-tuning methods like LoRA (low-rank adaptation) in terms of performance and comparable in terms of run time. We additionally show that SpIEL is compatible with both quantization and efficient optimizers, to facilitate scaling to ever-larger model sizes. We release the code for SpIEL at https://github.com/AlanAnsell/peft and for the instruction-tuning experiments at https://github.com/ducdauge/sft-llm.
Pheme: Efficient and Conversational Speech Generation
Jan 05, 2024In recent years, speech generation has seen remarkable progress, now achieving one-shot generation capability that is often virtually indistinguishable from real human voice. Integrating such advancements in speech generation with large language models might revolutionize a wide range of applications. However, certain applications, such as assistive conversational systems, require natural and conversational speech generation tools that also operate efficiently in real time. Current state-of-the-art models like VALL-E and SoundStorm, powered by hierarchical neural audio codecs, require large neural components and extensive training data to work well. In contrast, MQTTS aims to build more compact conversational TTS models while capitalizing on smaller-scale real-life conversational speech data. However, its autoregressive nature yields high inference latency and thus limits its real-time usage. In order to mitigate the current limitations of the state-of-the-art TTS models while capitalizing on their strengths, in this work we introduce the Pheme model series that 1) offers compact yet high-performing models, 2) allows for parallel speech generation of 3) natural conversational speech, and 4) it can be trained efficiently on smaller-scale conversational data, cutting data demands by more than 10x but still matching the quality of the autoregressive TTS models. We also show that through simple teacher-student distillation we can meet significant improvements in voice quality for single-speaker setups on top of pretrained Pheme checkpoints, relying solely on synthetic speech generated by much larger teacher models. Audio samples and pretrained models are available online.
DIALIGHT: Lightweight Multilingual Development and Evaluation of Task-Oriented Dialogue Systems with Large Language Models
Jan 04, 2024We present DIALIGHT, a toolkit for developing and evaluating multilingual Task-Oriented Dialogue (ToD) systems which facilitates systematic evaluations and comparisons between ToD systems using fine-tuning of Pretrained Language Models (PLMs) and those utilising the zero-shot and in-context learning capabilities of Large Language Models (LLMs). In addition to automatic evaluation, this toolkit features (i) a secure, user-friendly web interface for fine-grained human evaluation at both local utterance level and global dialogue level, and (ii) a microservice-based backend, improving efficiency and scalability. Our evaluations reveal that while PLM fine-tuning leads to higher accuracy and coherence, LLM-based systems excel in producing diverse and likeable responses. However, we also identify significant challenges of LLMs in adherence to task-specific instructions and generating outputs in multiple languages, highlighting areas for future research. We hope this open-sourced toolkit will serve as a valuable resource for researchers aiming to develop and properly evaluate multilingual ToD systems and will lower, currently still high, entry barriers in the field.
On Task Performance and Model Calibration with Supervised and Self-Ensembled In-Context Learning
Dec 22, 2023Following the standard supervised fine-tuning (SFT) paradigm, in-context learning (ICL) has become an efficient approach propelled by the recent advancements in large language models (LLMs), yielding promising performance across various tasks in few-shot data setups. However, both paradigms are prone to suffer from the critical problem of overconfidence (i.e., miscalibration), especially in such limited data setups. In this work, we deliver an in-depth analysis of the behavior across different choices of learning methods from the perspective of both performance and calibration, as well as their interplay. Through extensive controlled experiments, we find that simultaneous gains for both task performance and calibration are difficult to achieve, and the problem of miscalibration exists across all learning methods in low-resource scenarios. To address this challenging trade-off between performance and calibration, we then investigate the potential of self-ensembling techniques applied at different modeling stages (e.g., variations of in-context examples or variations in prompts or different ensembling strategies). We justify the feasibility of self-ensembling on SFT in addition to ICL, to make the predictions more calibrated and have comparable or even better performance. Our work sheds light on which learning paradigm to choose and how to enhance both task performance and calibration of LLMs.
Adapters: A Unified Library for Parameter-Efficient and Modular Transfer Learning
Nov 18, 2023We introduce Adapters, an open-source library that unifies parameter-efficient and modular transfer learning in large language models. By integrating 10 diverse adapter methods into a unified interface, Adapters offers ease of use and flexible configuration. Our library allows researchers and practitioners to leverage adapter modularity through composition blocks, enabling the design of complex adapter setups. We demonstrate the library's efficacy by evaluating its performance against full fine-tuning on various NLP tasks. Adapters provides a powerful tool for addressing the challenges of conventional fine-tuning paradigms and promoting more efficient and modular transfer learning. The library is available via https://adapterhub.ml/adapters.
$\textit{Dial BeInfo for Faithfulness}$: Improving Factuality of Information-Seeking Dialogue via Behavioural Fine-Tuning
Nov 16, 2023Factuality is a crucial requirement in information seeking dialogue: the system should respond to the user's queries so that the responses are meaningful and aligned with the knowledge provided to the system. However, most modern large language models suffer from hallucinations, that is, they generate responses not supported by or contradicting the knowledge source. To mitigate the issue and increase faithfulness of information-seeking dialogue systems, we introduce BeInfo, a simple yet effective method that applies behavioural tuning to aid information-seeking dialogue. Relying on three standard datasets, we show that models tuned with BeInfo} become considerably more faithful to the knowledge source both for datasets and domains seen during BeInfo-tuning, as well as on unseen domains, when applied in a zero-shot manner. In addition, we show that the models with 3B parameters (e.g., Flan-T5) tuned with BeInfo demonstrate strong performance on data from real `production' conversations and outperform GPT4 when tuned on a limited amount of such realistic in-domain dialogues.