 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJunzhe Chen
Adaptive quantization with mixed-precision based on low-cost proxy
Feb 27, 2024
It is critical to deploy complicated neural network models on hardware with limited resources. This paper proposes a novel model quantization method, named the Low-Cost Proxy-Based Adaptive Mixed-Precision Model Quantization (LCPAQ), which contains three key modules. The hardware-aware module is designed by considering the hardware limitations, while an adaptive mixed-precision quantization module is developed to evaluate the quantization sensitivity by using the Hessian matrix and Pareto frontier techniques. Integer linear programming is used to fine-tune the quantization across different layers. Then the low-cost proxy neural architecture search module efficiently explores the ideal quantization hyperparameters. Experiments on the ImageNet demonstrate that the proposed LCPAQ achieves comparable or superior quantization accuracy to existing mixed-precision models. Notably, LCPAQ achieves 1/200 of the search time compared with existing methods, which provides a shortcut in practical quantization use for resource-limited devices.
LLMArena: Assessing Capabilities of Large Language Models in Dynamic Multi-Agent Environments
Feb 26, 2024Recent advancements in large language models (LLMs) have revealed their potential for achieving autonomous agents possessing human-level intelligence. However, existing benchmarks for evaluating LLM Agents either use static datasets, potentially leading to data leakage or focus only on single-agent scenarios, overlooking the complexities of multi-agent interactions. There is a lack of a benchmark that evaluates the diverse capabilities of LLM agents in multi-agent, dynamic environments. To this end, we introduce LLMArena, a novel and easily extensible framework for evaluating the diverse capabilities of LLM in multi-agent dynamic environments. LLMArena encompasses seven distinct gaming environments, employing Trueskill scoring to assess crucial abilities in LLM agents, including spatial reasoning, strategic planning, numerical reasoning, risk assessment, communication, opponent modeling, and team collaboration. We conduct an extensive experiment and human evaluation among different sizes and types of LLMs, showing that LLMs still have a significant journey ahead in their development towards becoming fully autonomous agents, especially in opponent modeling and team collaboration. We hope LLMArena could guide future research towards enhancing these capabilities in LLMs, ultimately leading to more sophisticated and practical applications in dynamic, multi-agent settings. The code and data will be available.
Prompt Me Up: Unleashing the Power of Alignments for Multimodal Entity and Relation Extraction
Oct 25, 2023How can we better extract entities and relations from text? Using multimodal extraction with images and text obtains more signals for entities and relations, and aligns them through graphs or hierarchical fusion, aiding in extraction. Despite attempts at various fusions, previous works have overlooked many unlabeled image-caption pairs, such as NewsCLIPing. This paper proposes innovative pre-training objectives for entity-object and relation-image alignment, extracting objects from images and aligning them with entity and relation prompts for soft pseudo-labels. These labels are used as self-supervised signals for pre-training, enhancing the ability to extract entities and relations. Experiments on three datasets show an average 3.41% F1 improvement over prior SOTA. Additionally, our method is orthogonal to previous multimodal fusions, and using it on prior SOTA fusions further improves 5.47% F1.
Do Large Language Models Know about Facts?
Oct 08, 2023



Large language models (LLMs) have recently driven striking performance improvements across a range of natural language processing tasks. The factual knowledge acquired during pretraining and instruction tuning can be useful in various downstream tasks, such as question answering, and language generation. Unlike conventional Knowledge Bases (KBs) that explicitly store factual knowledge, LLMs implicitly store facts in their parameters. Content generated by the LLMs can often exhibit inaccuracies or deviations from the truth, due to facts that can be incorrectly induced or become obsolete over time. To this end, we aim to comprehensively evaluate the extent and scope of factual knowledge within LLMs by designing the benchmark Pinocchio. Pinocchio contains 20K diverse factual questions that span different sources, timelines, domains, regions, and languages. Furthermore, we investigate whether LLMs are able to compose multiple facts, update factual knowledge temporally, reason over multiple pieces of facts, identify subtle factual differences, and resist adversarial examples. Extensive experiments on different sizes and types of LLMs show that existing LLMs still lack factual knowledge and suffer from various spurious correlations. We believe this is a critical bottleneck for realizing trustworthy artificial intelligence. The dataset Pinocchio and our codes will be publicly available.
IAIFNet: An Illumination-Aware Infrared and Visible Image Fusion Network
Sep 26, 2023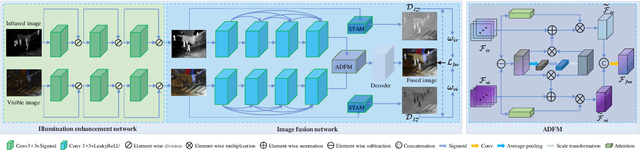
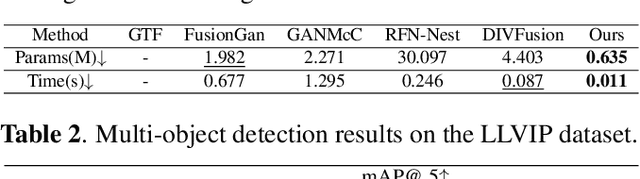

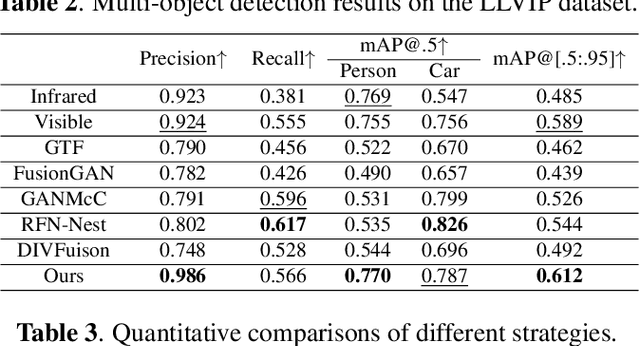
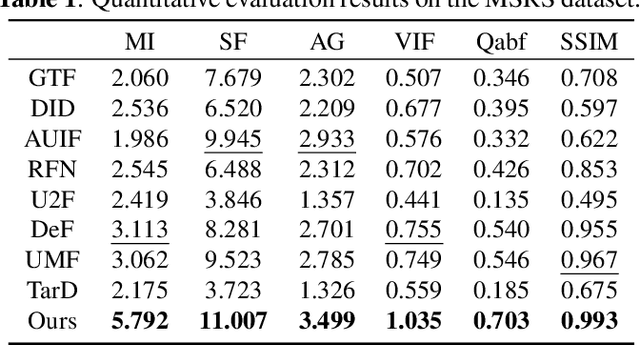
Infrared and visible image fusion (IVIF) is used to generate fusion images with comprehensive features of both images, which is beneficial for downstream vision tasks. However, current methods rarely consider the illumination condition in low-light environments, and the targets in the fused images are often not prominent. To address the above issues, we propose an Illumination-Aware Infrared and Visible Image Fusion Network, named as IAIFNet. In our framework, an illumination enhancement network first estimates the incident illumination maps of input images. Afterwards, with the help of proposed adaptive differential fusion module (ADFM) and salient target aware module (STAM), an image fusion network effectively integrates the salient features of the illumination-enhanced infrared and visible images into a fusion image of high visual quality. Extensive experimental results verify that our method outperforms five state-of-the-art methods of fusing infrared and visible images.
SSPFusion: A Semantic Structure-Preserving Approach for Infrared and Visible Image Fusion
Sep 26, 2023
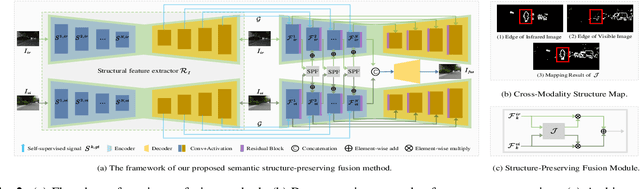
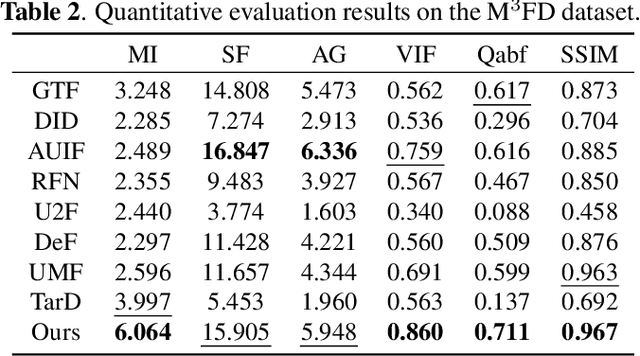
Most existing learning-based infrared and visible image fusion (IVIF) methods exhibit massive redundant information in the fusion images, i.e., yielding edge-blurring effect or unrecognizable for object detectors. To alleviate these issues, we propose a semantic structure-preserving approach for IVIF, namely SSPFusion. At first, we design a Structural Feature Extractor (SFE) to extract the structural features of infrared and visible images. Then, we introduce a multi-scale Structure-Preserving Fusion (SPF) module to fuse the structural features of infrared and visible images, while maintaining the consistency of semantic structures between the fusion and source images. Owing to these two effective modules, our method is able to generate high-quality fusion images from pairs of infrared and visible images, which can boost the performance of downstream computer-vision tasks. Experimental results on three benchmarks demonstrate that our method outperforms eight state-of-the-art image fusion methods in terms of both qualitative and quantitative evaluations. The code for our method, along with additional comparison results, will be made available at: https://github.com/QiaoYang-CV/SSPFUSION.