 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWei Jia
Audio-Infused Automatic Image Colorization by Exploiting Audio Scene Semantics
Jan 24, 2024
Automatic image colorization is inherently an ill-posed problem with uncertainty, which requires an accurate semantic understanding of scenes to estimate reasonable colors for grayscale images. Although recent interaction-based methods have achieved impressive performance, it is still a very difficult task to infer realistic and accurate colors for automatic colorization. To reduce the difficulty of semantic understanding of grayscale scenes, this paper tries to utilize corresponding audio, which naturally contains extra semantic information about the same scene. Specifically, a novel audio-infused automatic image colorization (AIAIC) network is proposed, which consists of three stages. First, we take color image semantics as a bridge and pretrain a colorization network guided by color image semantics. Second, the natural co-occurrence of audio and video is utilized to learn the color semantic correlations between audio and visual scenes. Third, the implicit audio semantic representation is fed into the pretrained network to finally realize the audio-guided colorization. The whole process is trained in a self-supervised manner without human annotation. In addition, an audiovisual colorization dataset is established for training and testing. Experiments demonstrate that audio guidance can effectively improve the performance of automatic colorization, especially for some scenes that are difficult to understand only from visual modality.
RPG-Palm: Realistic Pseudo-data Generation for Palmprint Recognition
Aug 08, 2023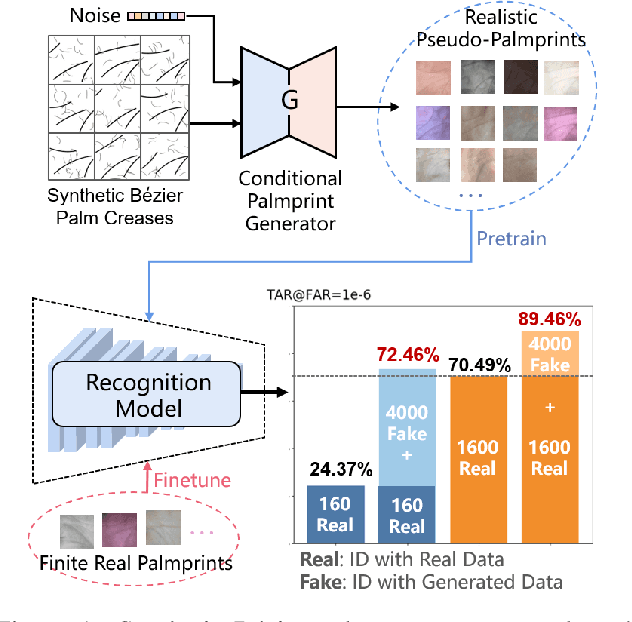

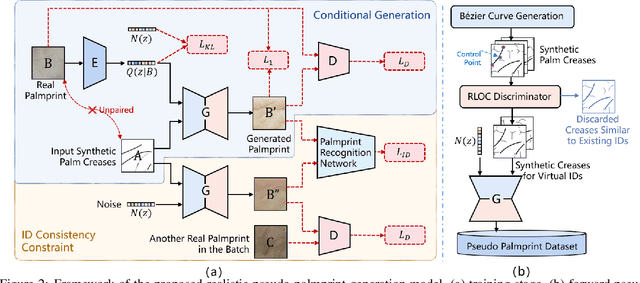
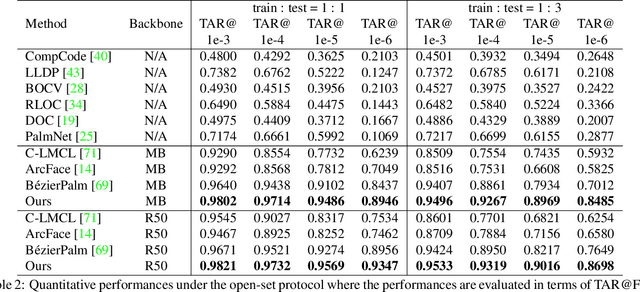
Palmprint recently shows great potential in recognition applications as it is a privacy-friendly and stable biometric. However, the lack of large-scale public palmprint datasets limits further research and development of palmprint recognition. In this paper, we propose a novel realistic pseudo-palmprint generation (RPG) model to synthesize palmprints with massive identities. We first introduce a conditional modulation generator to improve the intra-class diversity. Then an identity-aware loss is proposed to ensure identity consistency against unpaired training. We further improve the B\'ezier palm creases generation strategy to guarantee identity independence. Extensive experimental results demonstrate that synthetic pretraining significantly boosts the recognition model performance. For example, our model improves the state-of-the-art B\'ezierPalm by more than $5\%$ and $14\%$ in terms of TAR@FAR=1e-6 under the $1:1$ and $1:3$ Open-set protocol. When accessing only $10\%$ of the real training data, our method still outperforms ArcFace with $100\%$ real training data, indicating that we are closer to real-data-free palmprint recognition.
Enhancing Dynamic Image Advertising with Vision-Language Pre-training
Jun 25, 2023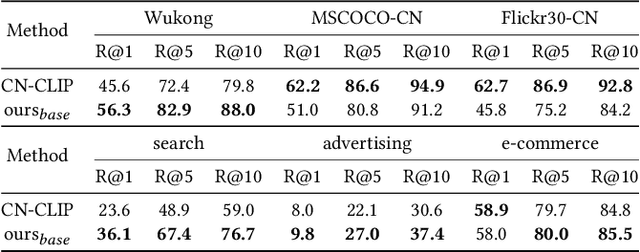
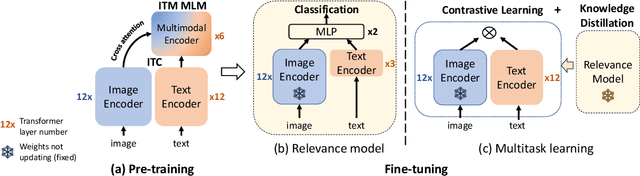


In the multimedia era, image is an effective medium in search advertising. Dynamic Image Advertising (DIA), a system that matches queries with ad images and generates multimodal ads, is introduced to improve user experience and ad revenue. The core of DIA is a query-image matching module performing ad image retrieval and relevance modeling. Current query-image matching suffers from limited and inconsistent data, and insufficient cross-modal interaction. Also, the separate optimization of retrieval and relevance models affects overall performance. To address this issue, we propose a vision-language framework consisting of two parts. First, we train a base model on large-scale image-text pairs to learn general multimodal representation. Then, we fine-tune the base model on advertising business data, unifying relevance modeling and retrieval through multi-objective learning. Our framework has been implemented in Baidu search advertising system "Phoneix Nest". Online evaluation shows that it improves cost per mille (CPM) and click-through rate (CTR) by 1.04% and 1.865%.
Learning In-context Learning for Named Entity Recognition
May 26, 2023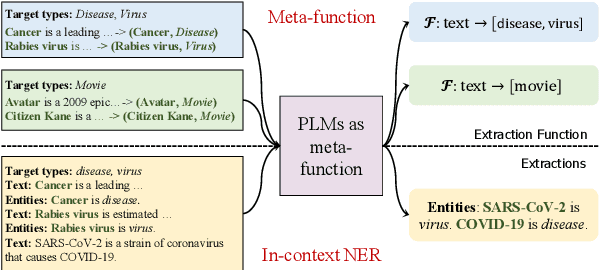
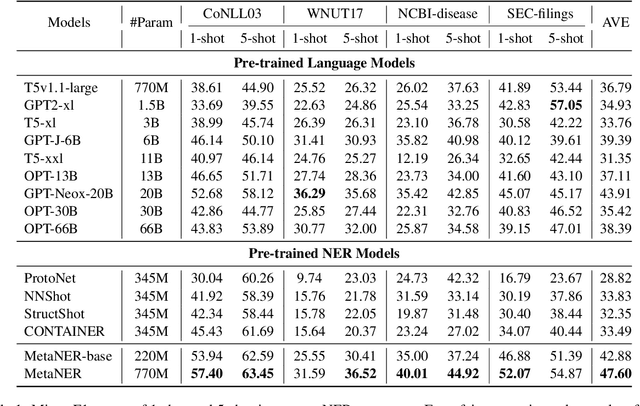

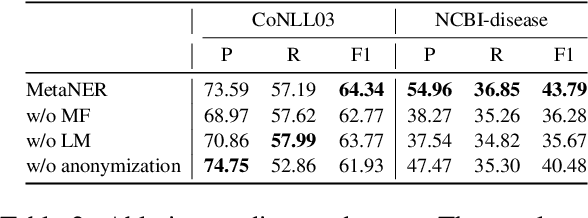
Named entity recognition in real-world applications suffers from the diversity of entity types, the emergence of new entity types, and the lack of high-quality annotations. To address the above problems, this paper proposes an in-context learning-based NER approach, which can effectively inject in-context NER ability into PLMs and recognize entities of novel types on-the-fly using only a few demonstrative instances. Specifically, we model PLMs as a meta-function $\mathcal{ \lambda_ {\text{instruction, demonstrations, text}}. M}$, and a new entity extractor can be implicitly constructed by applying new instruction and demonstrations to PLMs, i.e., $\mathcal{ (\lambda . M) }$(instruction, demonstrations) $\to$ $\mathcal{F}$ where $\mathcal{F}$ will be a new entity extractor, i.e., $\mathcal{F}$: text $\to$ entities. To inject the above in-context NER ability into PLMs, we propose a meta-function pre-training algorithm, which pre-trains PLMs by comparing the (instruction, demonstration)-initialized extractor with a surrogate golden extractor. Experimental results on 4 few-shot NER datasets show that our method can effectively inject in-context NER ability into PLMs and significantly outperforms the PLMs+fine-tuning counterparts.
Universal Information Extraction as Unified Semantic Matching
Jan 09, 2023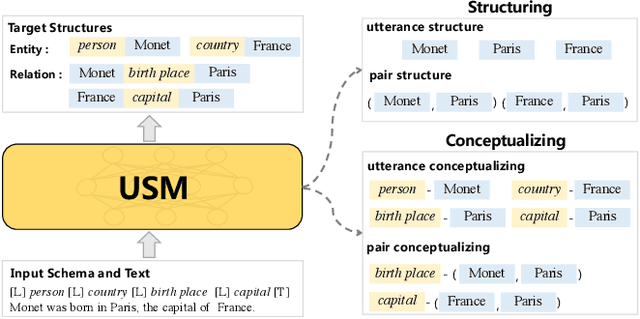
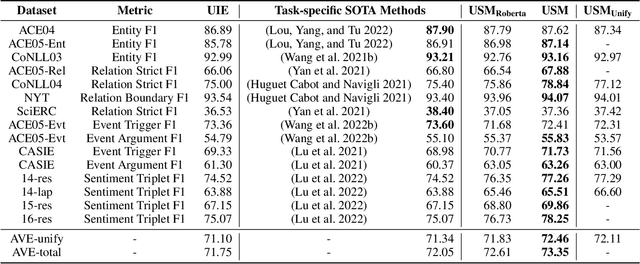
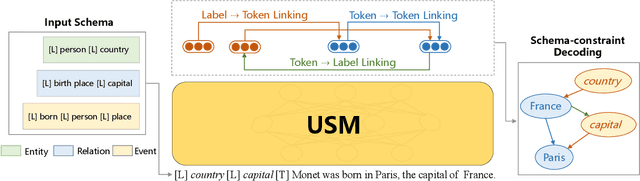
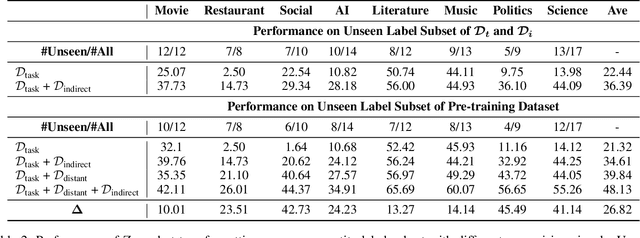
The challenge of information extraction (IE) lies in the diversity of label schemas and the heterogeneity of structures. Traditional methods require task-specific model design and rely heavily on expensive supervision, making them difficult to generalize to new schemas. In this paper, we decouple IE into two basic abilities, structuring and conceptualizing, which are shared by different tasks and schemas. Based on this paradigm, we propose to universally model various IE tasks with Unified Semantic Matching (USM) framework, which introduces three unified token linking operations to model the abilities of structuring and conceptualizing. In this way, USM can jointly encode schema and input text, uniformly extract substructures in parallel, and controllably decode target structures on demand. Empirical evaluation on 4 IE tasks shows that the proposed method achieves state-of-the-art performance under the supervised experiments and shows strong generalization ability in zero/few-shot transfer settings.
Geometric Synthesis: A Free lunch for Large-scale Palmprint Recognition Model Pretraining
Apr 11, 2022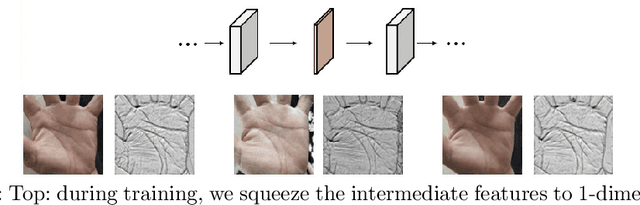

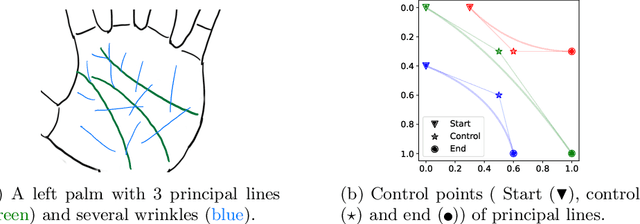

Palmprints are private and stable information for biometric recognition. In the deep learning era, the development of palmprint recognition is limited by the lack of sufficient training data. In this paper, by observing that palmar creases are the key information to deep-learning-based palmprint recognition, we propose to synthesize training data by manipulating palmar creases. Concretely, we introduce an intuitive geometric model which represents palmar creases with parameterized B\'ezier curves. By randomly sampling B\'ezier parameters, we can synthesize massive training samples of diverse identities, which enables us to pretrain large-scale palmprint recognition models. Experimental results demonstrate that such synthetically pretrained models have a very strong generalization ability: they can be efficiently transferred to real datasets, leading to significant performance improvements on palmprint recognition. For example, under the open-set protocol, our method improves the strong ArcFace baseline by more than 10\% in terms of TAR@1e-6. And under the closed-set protocol, our method reduces the equal error rate (EER) by an order of magnitude.
Depth Estimation by Combining Binocular Stereo and Monocular Structured-Light
Mar 20, 2022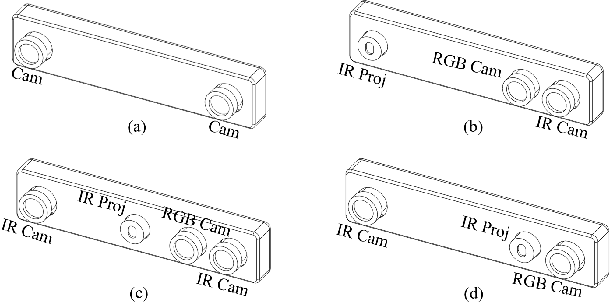
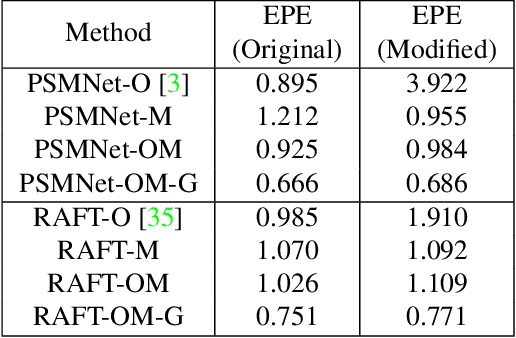
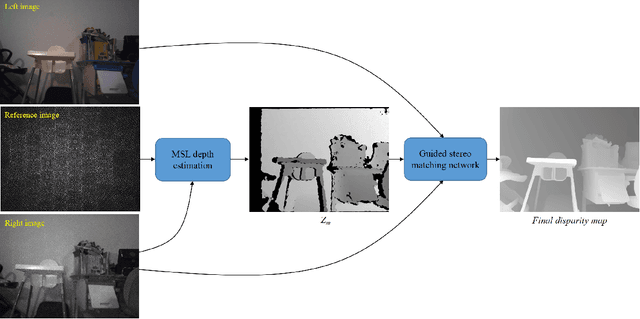
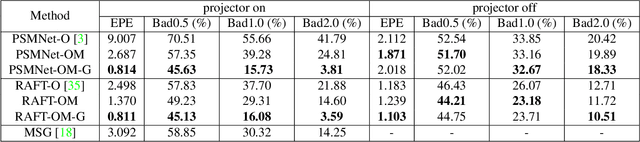
It is well known that the passive stereo system cannot adapt well to weak texture objects, e.g., white walls. However, these weak texture targets are very common in indoor environments. In this paper, we present a novel stereo system, which consists of two cameras (an RGB camera and an IR camera) and an IR speckle projector. The RGB camera is used both for depth estimation and texture acquisition. The IR camera and the speckle projector can form a monocular structured-light (MSL) subsystem, while the two cameras can form a binocular stereo subsystem. The depth map generated by the MSL subsystem can provide external guidance for the stereo matching networks, which can improve the matching accuracy significantly. In order to verify the effectiveness of the proposed system, we build a prototype and collect a test dataset in indoor scenes. The evaluation results show that the Bad 2.0 error of the proposed system is 28.2% of the passive stereo system when the network RAFT is used. The dataset and trained models are available at https://github.com/YuhuaXu/MonoStereoFusion.
Fooling the Eyes of Autonomous Vehicles: Robust Physical Adversarial Examples Against Traffic Sign Recognition Systems
Jan 17, 2022
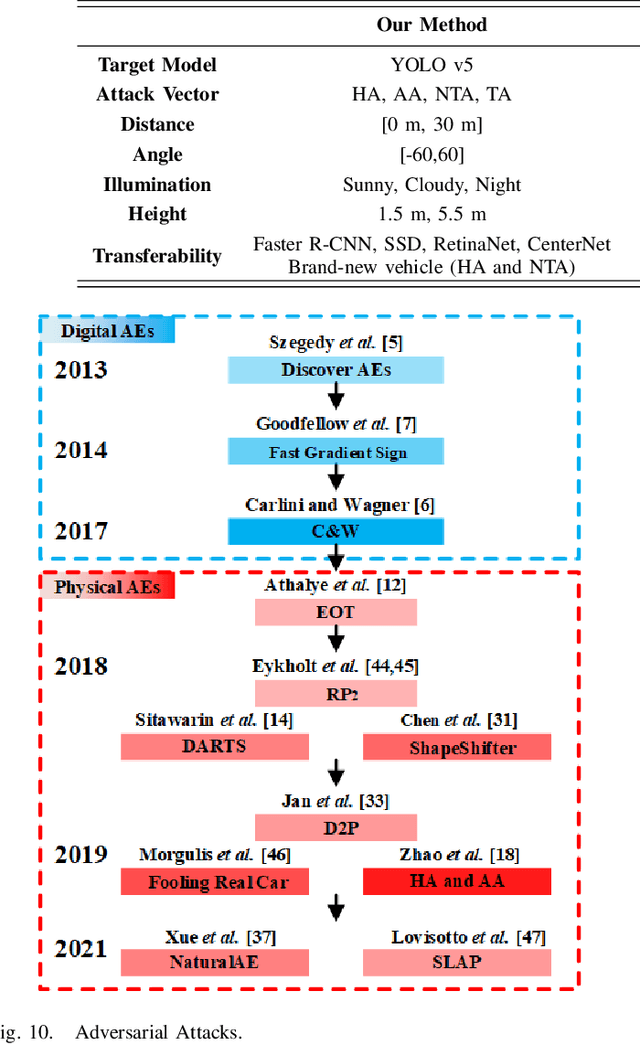
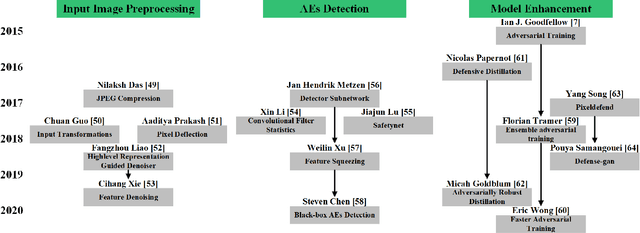

Adversarial Examples (AEs) can deceive Deep Neural Networks (DNNs) and have received a lot of attention recently. However, majority of the research on AEs is in the digital domain and the adversarial patches are static, which is very different from many real-world DNN applications such as Traffic Sign Recognition (TSR) systems in autonomous vehicles. In TSR systems, object detectors use DNNs to process streaming video in real time. From the view of object detectors, the traffic sign`s position and quality of the video are continuously changing, rendering the digital AEs ineffective in the physical world. In this paper, we propose a systematic pipeline to generate robust physical AEs against real-world object detectors. Robustness is achieved in three ways. First, we simulate the in-vehicle cameras by extending the distribution of image transformations with the blur transformation and the resolution transformation. Second, we design the single and multiple bounding boxes filters to improve the efficiency of the perturbation training. Third, we consider four representative attack vectors, namely Hiding Attack, Appearance Attack, Non-Target Attack and Target Attack. We perform a comprehensive set of experiments under a variety of environmental conditions, and considering illuminations in sunny and cloudy weather as well as at night. The experimental results show that the physical AEs generated from our pipeline are effective and robust when attacking the YOLO v5 based TSR system. The attacks have good transferability and can deceive other state-of-the-art object detectors. We launched HA and NTA on a brand-new 2021 model vehicle. Both attacks are successful in fooling the TSR system, which could be a life-threatening case for autonomous vehicles. Finally, we discuss three defense mechanisms based on image preprocessing, AEs detection, and model enhancing.
From Noise to Feature: Exploiting Intensity Distribution as a Novel Soft Biometric Trait for Finger Vein Recognition
Dec 15, 2021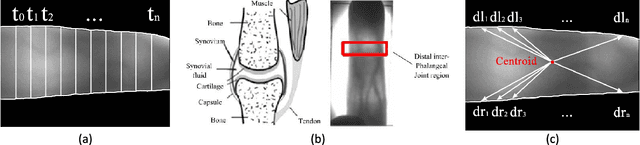
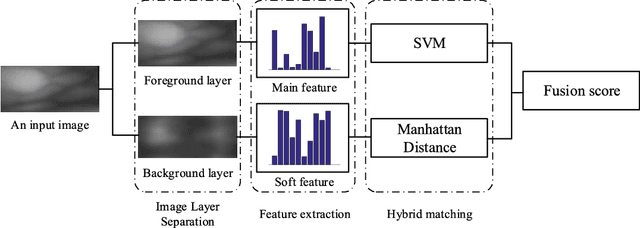
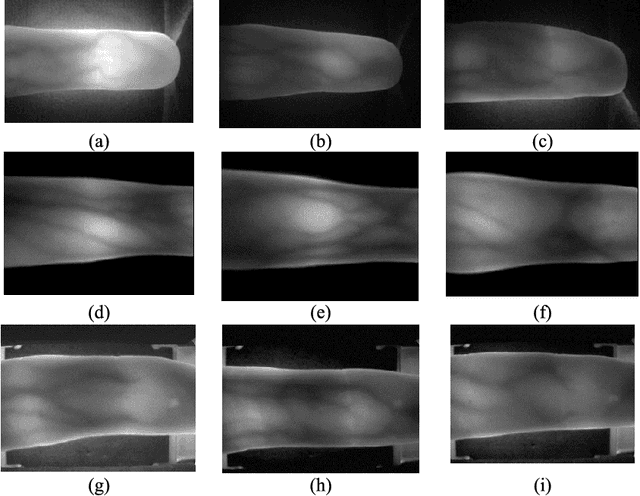

Most finger vein feature extraction algorithms achieve satisfactory performance due to their texture representation abilities, despite simultaneously ignoring the intensity distribution that is formed by the finger tissue, and in some cases, processing it as background noise. In this paper, we exploit this kind of noise as a novel soft biometric trait for achieving better finger vein recognition performance. First, a detailed analysis of the finger vein imaging principle and the characteristics of the image are presented to show that the intensity distribution that is formed by the finger tissue in the background can be extracted as a soft biometric trait for recognition. Then, two finger vein background layer extraction algorithms and three soft biometric trait extraction algorithms are proposed for intensity distribution feature extraction. Finally, a hybrid matching strategy is proposed to solve the issue of dimension difference between the primary and soft biometric traits on the score level. A series of rigorous contrast experiments on three open-access databases demonstrates that our proposed method is feasible and effective for finger vein recognition.
* 11 pages
Multi-frame Joint Enhancement for Early Interlaced Videos
Sep 29, 2021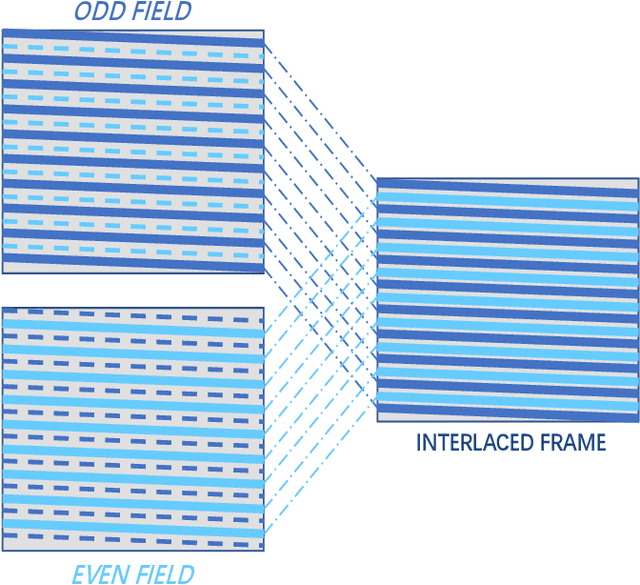


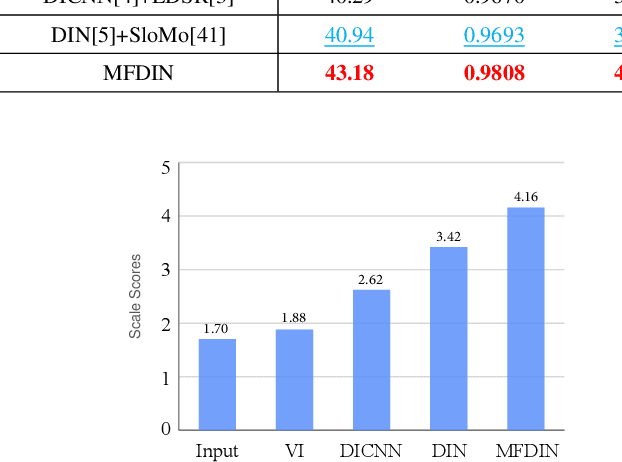
Early interlaced videos usually contain multiple and interlacing and complex compression artifacts, which significantly reduce the visual quality. Although the high-definition reconstruction technology for early videos has made great progress in recent years, related research on deinterlacing is still lacking. Traditional methods mainly focus on simple interlacing mechanism, and cannot deal with the complex artifacts in real-world early videos. Recent interlaced video reconstruction deep deinterlacing models only focus on single frame, while neglecting important temporal information. Therefore, this paper proposes a multiframe deinterlacing network joint enhancement network for early interlaced videos that consists of three modules, i.e., spatial vertical interpolation module, temporal alignment and fusion module, and final refinement module. The proposed method can effectively remove the complex artifacts in early videos by using temporal redundancy of multi-fields. Experimental results demonstrate that the proposed method can recover high quality results for both synthetic dataset and real-world early interlaced videos.