 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYang Ye
MoE-LLaVA: Mixture of Experts for Large Vision-Language Models
Feb 04, 2024
Recent advances demonstrate that scaling Large Vision-Language Models (LVLMs) effectively improves downstream task performances. However, existing scaling methods enable all model parameters to be active for each token in the calculation, which brings massive training and inferring costs. In this work, we propose a simple yet effective training strategy MoE-Tuning for LVLMs. This strategy innovatively addresses the common issue of performance degradation in multi-modal sparsity learning, consequently constructing a sparse model with an outrageous number of parameters but a constant computational cost. Furthermore, we present the MoE-LLaVA, a MoE-based sparse LVLM architecture, which uniquely activates only the top-k experts through routers during deployment, keeping the remaining experts inactive. Extensive experiments show the significant performance of MoE-LLaVA in a variety of visual understanding and object hallucination benchmarks. Remarkably, with only approximately 3B sparsely activated parameters, MoE-LLaVA demonstrates performance comparable to the LLaVA-1.5-7B on various visual understanding datasets and even surpasses the LLaVA-1.5-13B in object hallucination benchmark. Through MoE-LLaVA, we aim to establish a baseline for sparse LVLMs and provide valuable insights for future research in developing more efficient and effective multi-modal learning systems. Code is released at \url{https://github.com/PKU-YuanGroup/MoE-LLaVA}.
Video-LLaVA: Learning United Visual Representation by Alignment Before Projection
Nov 21, 2023The Large Vision-Language Model (LVLM) has enhanced the performance of various downstream tasks in visual-language understanding. Most existing approaches encode images and videos into separate feature spaces, which are then fed as inputs to large language models. However, due to the lack of unified tokenization for images and videos, namely misalignment before projection, it becomes challenging for a Large Language Model (LLM) to learn multi-modal interactions from several poor projection layers. In this work, we unify visual representation into the language feature space to advance the foundational LLM towards a unified LVLM. As a result, we establish a simple but robust LVLM baseline, Video-LLaVA, which learns from a mixed dataset of images and videos, mutually enhancing each other. Video-LLaVA achieves superior performances on a broad range of 9 image benchmarks across 5 image question-answering datasets and 4 image benchmark toolkits. Additionally, our Video-LLaVA also outperforms Video-ChatGPT by 5.8%, 9.9%, 18.6%, and 10.1% on MSRVTT, MSVD, TGIF, and ActivityNet, respectively. Notably, extensive experiments demonstrate that Video-LLaVA mutually benefits images and videos within a unified visual representation, outperforming models designed specifically for images or videos. We aim for this work to provide modest insights into the multi-modal inputs for the LLM.
Sensory Manipulation as a Countermeasure to Robot Teleoperation Delays: System and Evidence
Oct 13, 2023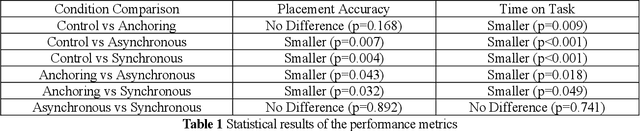
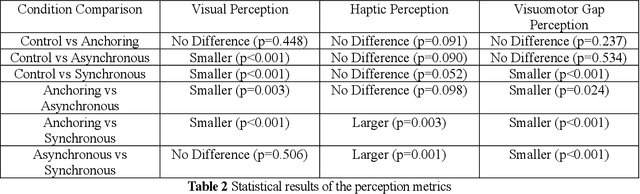

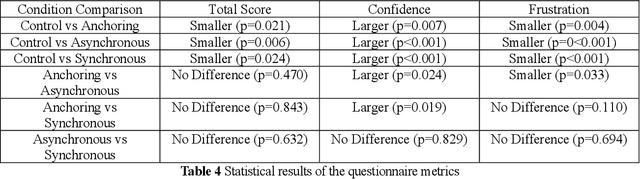
In the field of robotics, robot teleoperation for remote or hazardous environments has become increasingly vital. A major challenge is the lag between command and action, negatively affecting operator awareness, performance, and mental strain. Even with advanced technology, mitigating these delays, especially in long-distance operations, remains challenging. Current solutions largely focus on machine-based adjustments. Yet, there's a gap in using human perceptions to improve the teleoperation experience. This paper presents a unique method of sensory manipulation to help humans adapt to such delays. Drawing from motor learning principles, it suggests that modifying sensory stimuli can lessen the perception of these delays. Instead of introducing new skills, the approach uses existing motor coordination knowledge. The aim is to minimize the need for extensive training or complex automation. A study with 41 participants explored the effects of altered haptic cues in delayed teleoperations. These cues were sourced from advanced physics engines and robot sensors. Results highlighted benefits like reduced task time and improved perceptions of visual delays. Real-time haptic feedback significantly contributed to reduced mental strain and increased confidence. This research emphasizes human adaptation as a key element in robot teleoperation, advocating for improved teleoperation efficiency via swift human adaptation, rather than solely optimizing robots for delay adjustment.
Urban Drone Navigation: Autoencoder Learning Fusion for Aerodynamics
Oct 13, 2023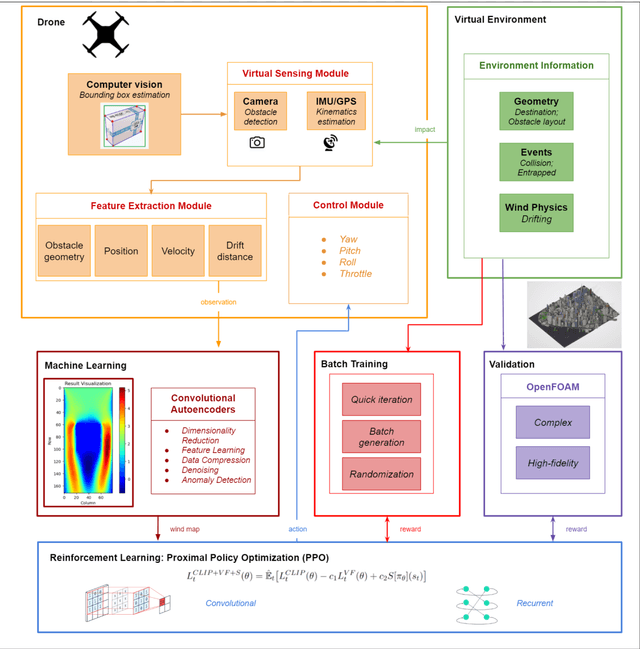
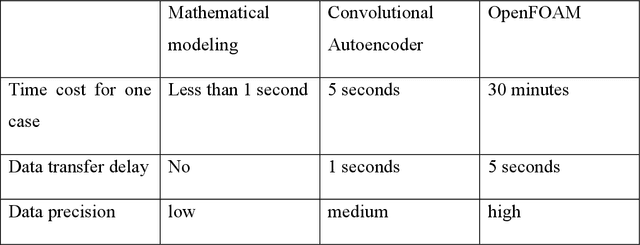
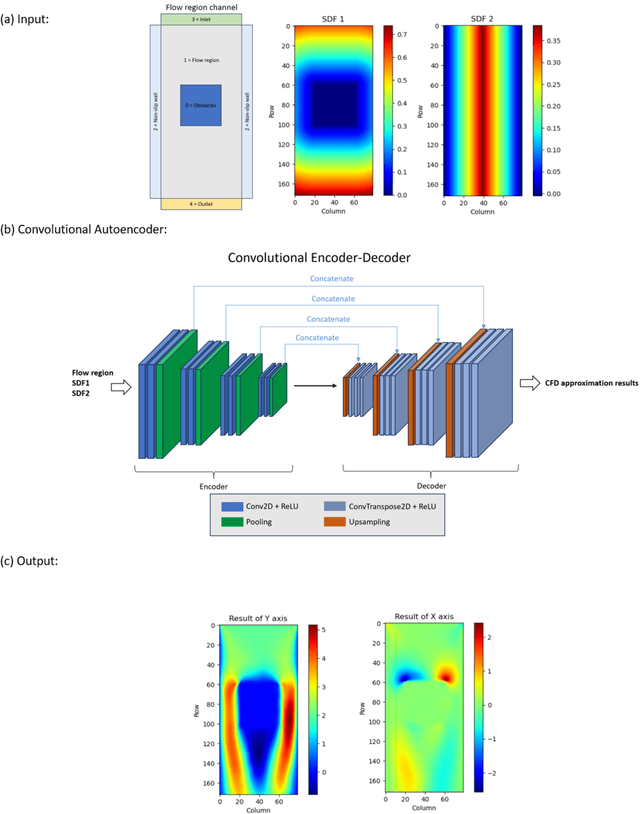
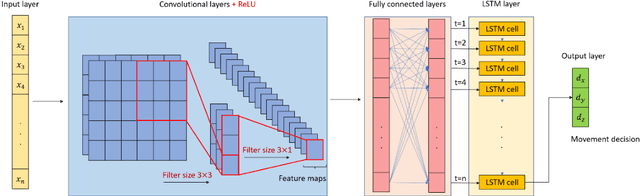
Drones are vital for urban emergency search and rescue (SAR) due to the challenges of navigating dynamic environments with obstacles like buildings and wind. This paper presents a method that combines multi-objective reinforcement learning (MORL) with a convolutional autoencoder to improve drone navigation in urban SAR. The approach uses MORL to achieve multiple goals and the autoencoder for cost-effective wind simulations. By utilizing imagery data of urban layouts, the drone can autonomously make navigation decisions, optimize paths, and counteract wind effects without traditional sensors. Tested on a New York City model, this method enhances drone SAR operations in complex urban settings.
W-procer: Weighted Prototypical Contrastive Learning for Medical Few-Shot Named Entity Recognition
Jun 10, 2023
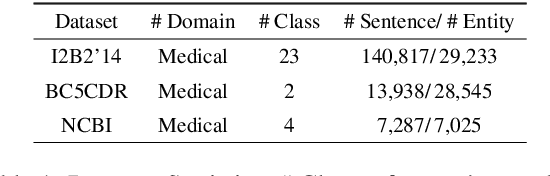
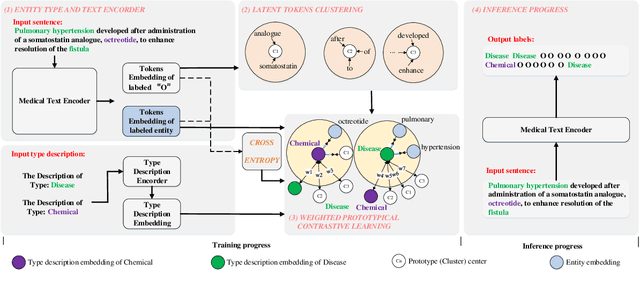
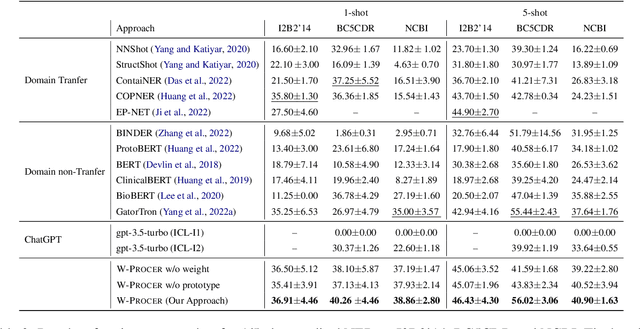
Contrastive learning has become a popular solution for few-shot Name Entity Recognization (NER). The conventional configuration strives to reduce the distance between tokens with the same labels and increase the distance between tokens with different labels. The effect of this setup may, however, in the medical domain, there are a lot of entities annotated as OUTSIDE (O), and they are undesirably pushed apart to other entities that are not labeled as OUTSIDE (O) by the current contrastive learning method end up with a noisy prototype for the semantic representation of the label, though there are many OUTSIDE (O) labeled entities are relevant to the labeled entities. To address this challenge, we propose a novel method named Weighted Prototypical Contrastive Learning for Medical Few Shot Named Entity Recognization (W-PROCER). Our approach primarily revolves around constructing the prototype-based contractive loss and weighting network. These components play a crucial role in assisting the model in differentiating the negative samples from OUTSIDE (O) tokens and enhancing the discrimination ability of contrastive learning. Experimental results show that our proposed W-PROCER framework significantly outperforms the strong baselines on the three medical benchmark datasets.
Improved Trust in Human-Robot Collaboration with ChatGPT
Apr 25, 2023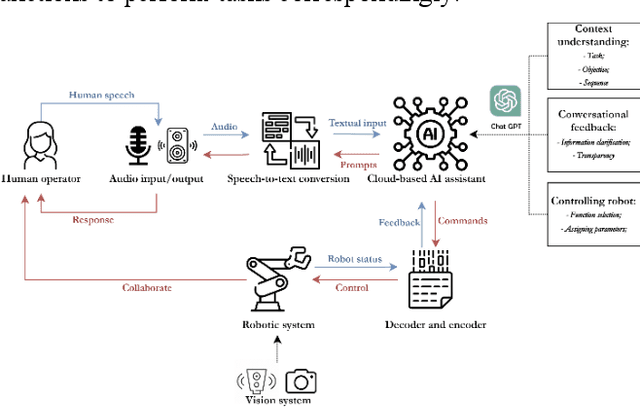
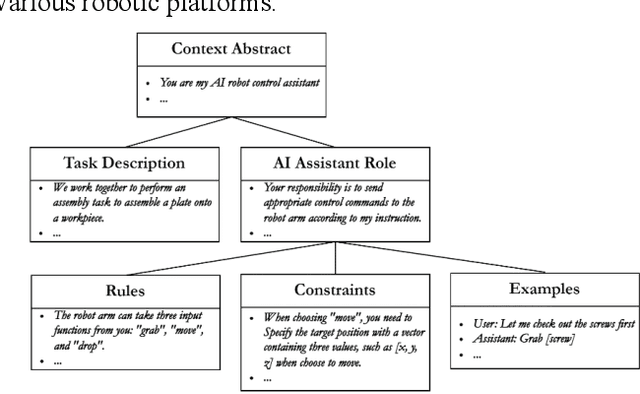
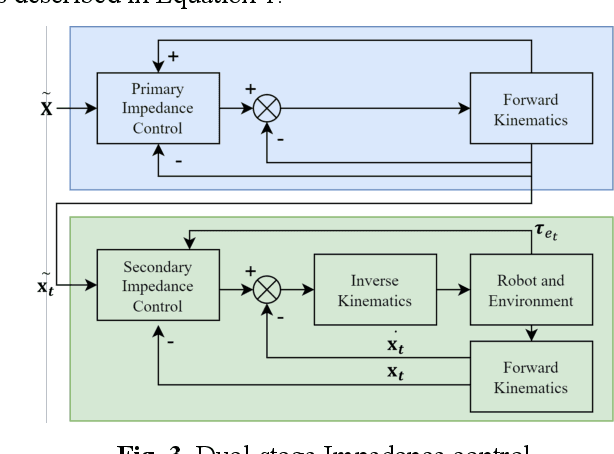
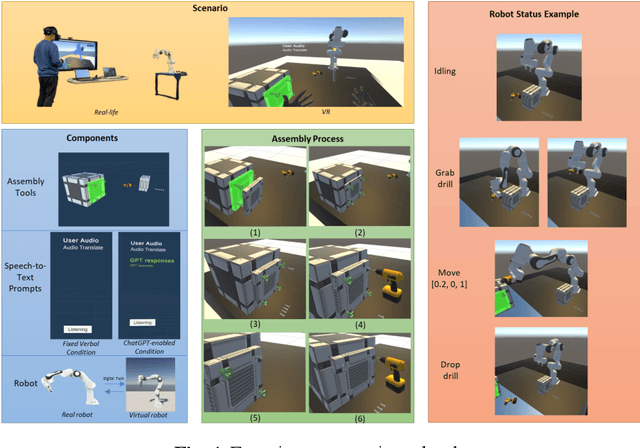
Human robot collaboration is becoming increasingly important as robots become more involved in various aspects of human life in the era of Artificial Intelligence. However, the issue of human operators trust in robots remains a significant concern, primarily due to the lack of adequate semantic understanding and communication between humans and robots. The emergence of Large Language Models (LLMs), such as ChatGPT, provides an opportunity to develop an interactive, communicative, and robust human-robot collaboration approach. This paper explores the impact of ChatGPT on trust in a human-robot collaboration assembly task. This study designs a robot control system called RoboGPT using ChatGPT to control a 7-degree-of-freedom robot arm to help human operators fetch, and place tools, while human operators can communicate with and control the robot arm using natural language. A human-subject experiment showed that incorporating ChatGPT in robots significantly increased trust in human-robot collaboration, which can be attributed to the robot's ability to communicate more effectively with humans. Furthermore, ChatGPT ability to understand the nuances of human language and respond appropriately helps to build a more natural and intuitive human-robot interaction. The findings of this study have significant implications for the development of human-robot collaboration systems.
Robot-Enabled Construction Assembly with Automated Sequence Planning based on ChatGPT: RoboGPT
Apr 21, 2023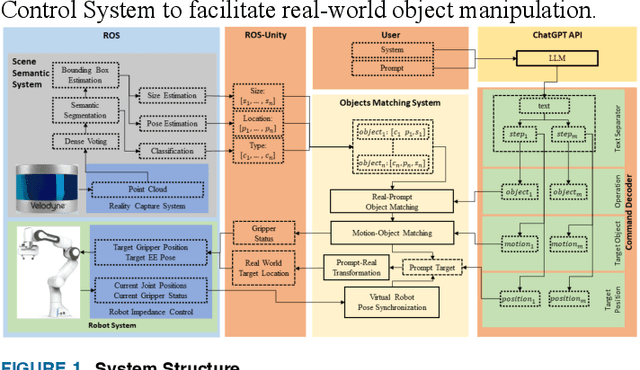
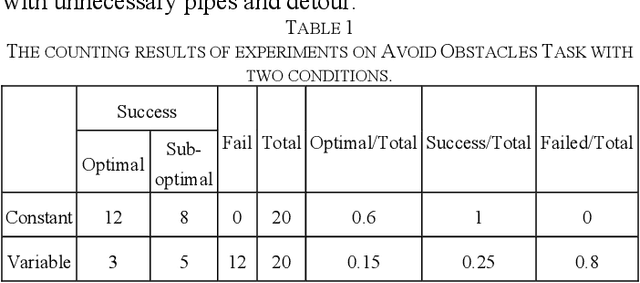


Robot-based assembly in construction has emerged as a promising solution to address numerous challenges such as increasing costs, labor shortages, and the demand for safe and efficient construction processes. One of the main obstacles in realizing the full potential of these robotic systems is the need for effective and efficient sequence planning for construction tasks. Current approaches, including mathematical and heuristic techniques or machine learning methods, face limitations in their adaptability and scalability to dynamic construction environments. To expand the ability of the current robot system in sequential understanding, this paper introduces RoboGPT, a novel system that leverages the advanced reasoning capabilities of ChatGPT, a large language model, for automated sequence planning in robot-based assembly applied to construction tasks. The proposed system adapts ChatGPT for construction sequence planning and demonstrate its feasibility and effectiveness through experimental evaluation including Two case studies and 80 trials about real construction tasks. The results show that RoboGPT-driven robots can handle complex construction operations and adapt to changes on the fly. This paper contributes to the ongoing efforts to enhance the capabilities and performance of robot-based assembly systems in the construction industry, and it paves the way for further integration of large language model technologies in the field of construction robotics.
APSNet: Attention Based Point Cloud Sampling
Oct 11, 2022
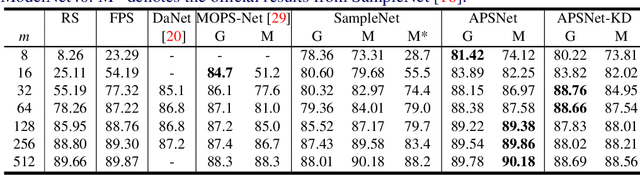
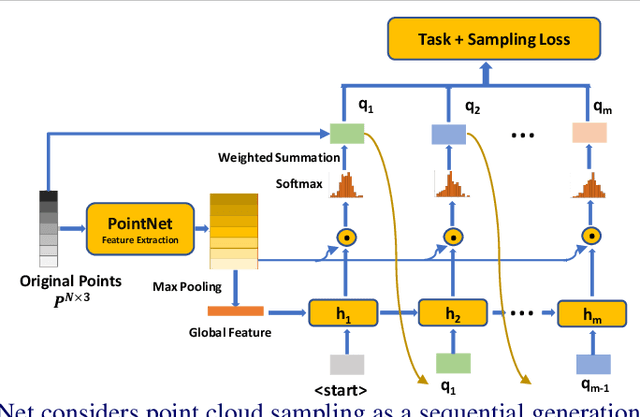
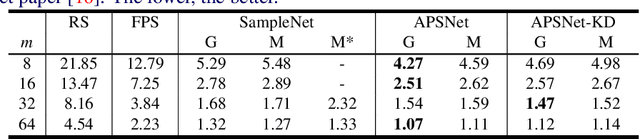
Processing large point clouds is a challenging task. Therefore, the data is often downsampled to a smaller size such that it can be stored, transmitted and processed more efficiently without incurring significant performance degradation. Traditional task-agnostic sampling methods, such as farthest point sampling (FPS), do not consider downstream tasks when sampling point clouds, and thus non-informative points to the tasks are often sampled. This paper explores a task-oriented sampling for 3D point clouds, and aims to sample a subset of points that are tailored specifically to a downstream task of interest. Similar to FPS, we assume that point to be sampled next should depend heavily on the points that have already been sampled. We thus formulate point cloud sampling as a sequential generation process, and develop an attention-based point cloud sampling network (APSNet) to tackle this problem. At each time step, APSNet attends to all the points in a cloud by utilizing the history of previously sampled points, and samples the most informative one. Both supervised learning and knowledge distillation-based self-supervised learning of APSNet are proposed. Moreover, joint training of APSNet over multiple sample sizes is investigated, leading to a single APSNet that can generate arbitrary length of samples with prominent performances. Extensive experiments demonstrate the superior performance of APSNet against state-of-the-arts in various downstream tasks, including 3D point cloud classification, reconstruction, and registration.
A Hierarchical N-Gram Framework for Zero-Shot Link Prediction
Apr 16, 2022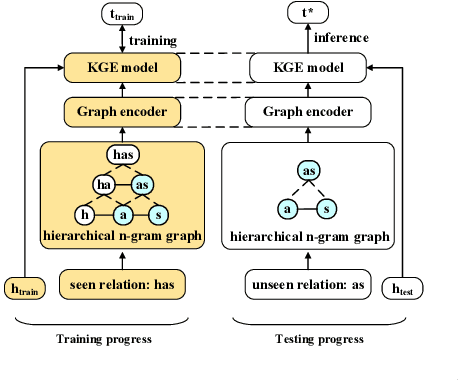
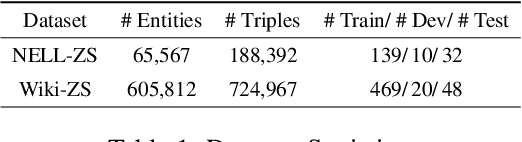
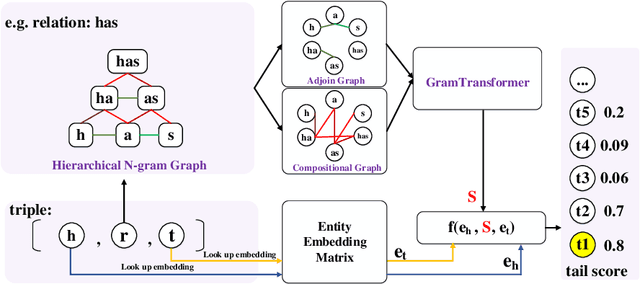
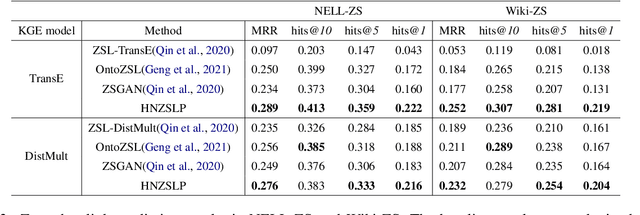
Due to the incompleteness of knowledge graphs (KGs), zero-shot link prediction (ZSLP) which aims to predict unobserved relations in KGs has attracted recent interest from researchers. A common solution is to use textual features of relations (e.g., surface name or textual descriptions) as auxiliary information to bridge the gap between seen and unseen relations. Current approaches learn an embedding for each word token in the text. These methods lack robustness as they suffer from the out-of-vocabulary (OOV) problem. Meanwhile, models built on character n-grams have the capability of generating expressive representations for OOV words. Thus, in this paper, we propose a Hierarchical N-Gram framework for Zero-Shot Link Prediction (HNZSLP), which considers the dependencies among character n-grams of the relation surface name for ZSLP. Our approach works by first constructing a hierarchical n-gram graph on the surface name to model the organizational structure of n-grams that leads to the surface name. A GramTransformer, based on the Transformer is then presented to model the hierarchical n-gram graph to construct the relation embedding for ZSLP. Experimental results show the proposed HNZSLP achieved state-of-the-art performance on two ZSLP datasets.
Generative Max-Mahalanobis Classifiers for Image Classification, Generation and More
Jan 01, 2021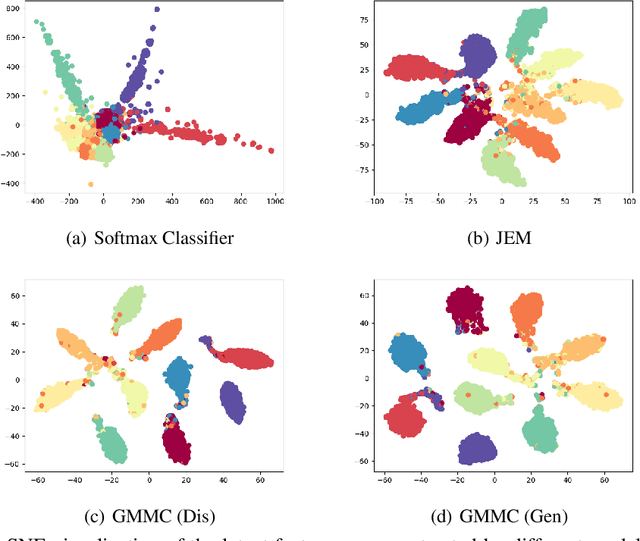
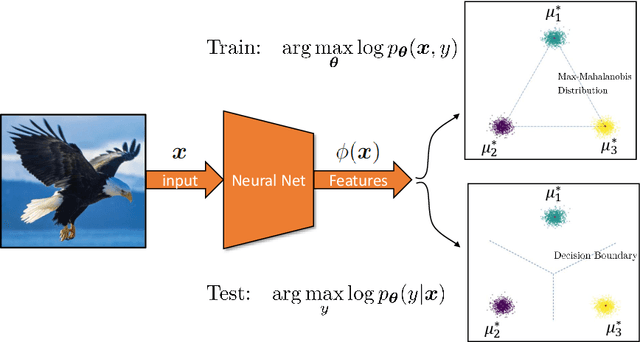

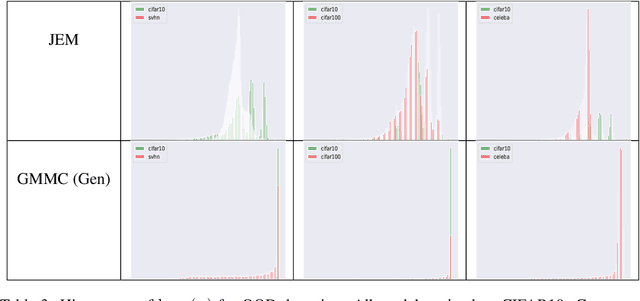
Joint Energy-based Model (JEM) of~\cite{jem} shows that a standard softmax classifier can be reinterpreted as an energy-based model (EBM) for the joint distribution $p(\boldsymbol{x}, y)$; the resulting model can be optimized with an energy-based training to improve calibration, robustness and out-of-distribution detection, while generating samples rivaling the quality of recent GAN-based approaches. However, the softmax classifier that JEM exploits is inherently discriminative and its latent feature space is not well formulated as probabilistic distributions, which may hinder its potential for image generation and incur training instability as observed in~\cite{jem}. We hypothesize that generative classifiers, such as Linear Discriminant Analysis (LDA), might be more suitable hybrid models for image generation since generative classifiers model the data generation process explicitly. This paper therefore investigates an LDA classifier for image classification and generation. In particular, the Max-Mahalanobis Classifier (MMC)~\cite{Pang2020Rethinking}, a special case of LDA, fits our goal very well since MMC formulates the latent feature space explicitly as the Max-Mahalanobis distribution~\cite{pang2018max}. We term our algorithm Generative MMC (GMMC), and show that it can be trained discriminatively, generatively or jointly for image classification and generation. Extensive experiments on multiple datasets (CIFAR10, CIFAR100 and SVHN) show that GMMC achieves state-of-the-art discriminative and generative performances, while outperforming JEM in calibration, adversarial robustness and out-of-distribution detection by a significant margin.