 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXiaojian Ma
Semantic Gaussians: Open-Vocabulary Scene Understanding with 3D Gaussian Splatting
Mar 22, 2024
Open-vocabulary 3D scene understanding presents a significant challenge in computer vision, withwide-ranging applications in embodied agents and augmented reality systems. Previous approaches haveadopted Neural Radiance Fields (NeRFs) to analyze 3D scenes. In this paper, we introduce SemanticGaussians, a novel open-vocabulary scene understanding approach based on 3D Gaussian Splatting. Our keyidea is distilling pre-trained 2D semantics into 3D Gaussians. We design a versatile projection approachthat maps various 2Dsemantic features from pre-trained image encoders into a novel semantic component of 3D Gaussians, withoutthe additional training required by NeRFs. We further build a 3D semantic network that directly predictsthe semantic component from raw 3D Gaussians for fast inference. We explore several applications ofSemantic Gaussians: semantic segmentation on ScanNet-20, where our approach attains a 4.2% mIoU and 4.0%mAcc improvement over prior open-vocabulary scene understanding counterparts; object part segmentation,sceneediting, and spatial-temporal segmentation with better qualitative results over 2D and 3D baselines,highlighting its versatility and effectiveness on supporting diverse downstream tasks.
VideoAgent: A Memory-augmented Multimodal Agent for Video Understanding
Mar 18, 2024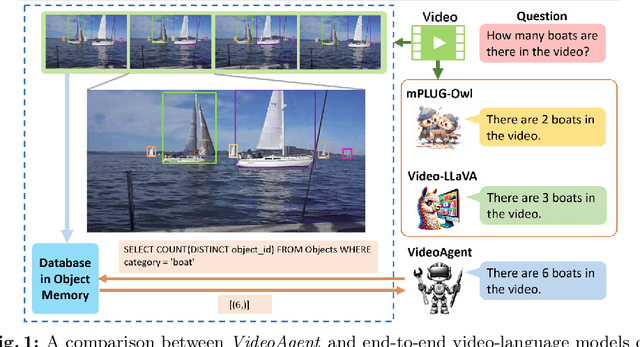

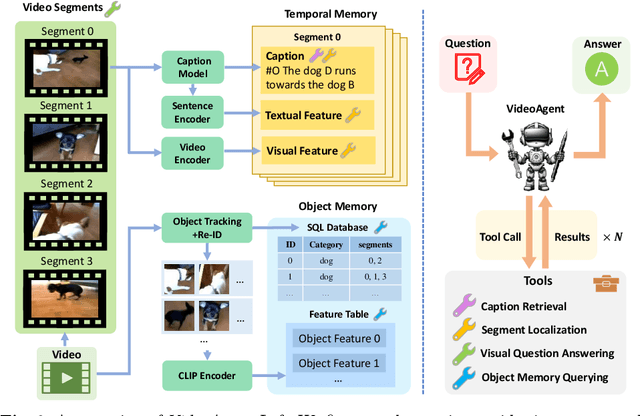
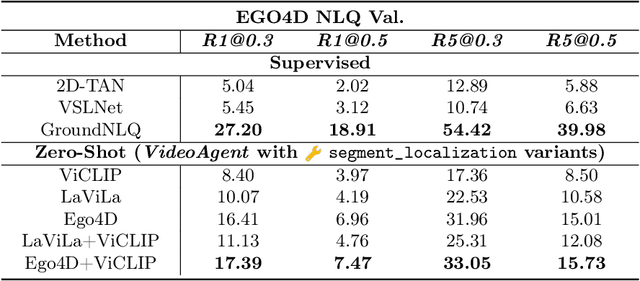
We explore how reconciling several foundation models (large language models and vision-language models) with a novel unified memory mechanism could tackle the challenging video understanding problem, especially capturing the long-term temporal relations in lengthy videos. In particular, the proposed multimodal agent VideoAgent: 1) constructs a structured memory to store both the generic temporal event descriptions and object-centric tracking states of the video; 2) given an input task query, it employs tools including video segment localization and object memory querying along with other visual foundation models to interactively solve the task, utilizing the zero-shot tool-use ability of LLMs. VideoAgent demonstrates impressive performances on several long-horizon video understanding benchmarks, an average increase of 6.6% on NExT-QA and 26.0% on EgoSchema over baselines, closing the gap between open-sourced models and private counterparts including Gemini 1.5 Pro.
RAT: Retrieval Augmented Thoughts Elicit Context-Aware Reasoning in Long-Horizon Generation
Mar 08, 2024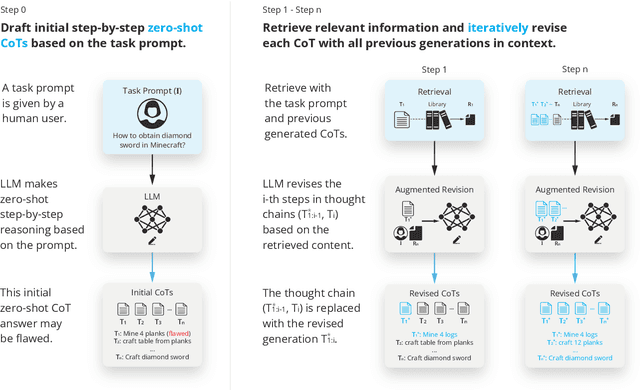
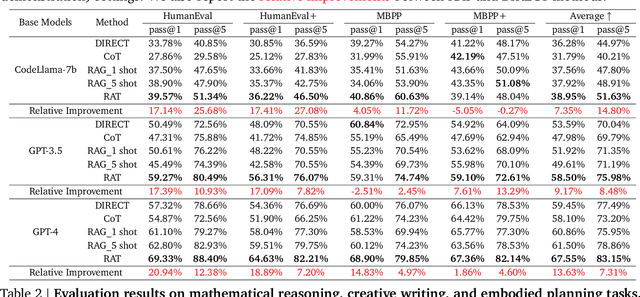
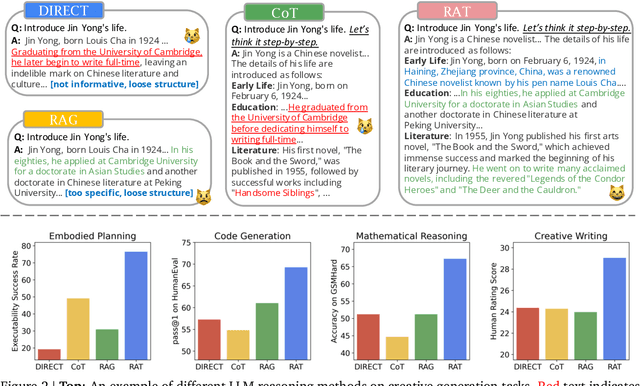
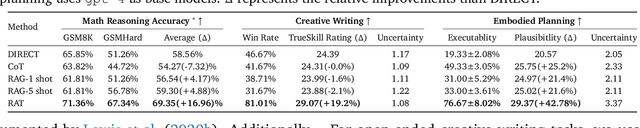
We explore how iterative revising a chain of thoughts with the help of information retrieval significantly improves large language models' reasoning and generation ability in long-horizon generation tasks, while hugely mitigating hallucination. In particular, the proposed method -- *retrieval-augmented thoughts* (RAT) -- revises each thought step one by one with retrieved information relevant to the task query, the current and the past thought steps, after the initial zero-shot CoT is generated. Applying RAT to GPT-3.5, GPT-4, and CodeLLaMA-7b substantially improves their performances on various long-horizon generation tasks; on average of relatively increasing rating scores by 13.63% on code generation, 16.96% on mathematical reasoning, 19.2% on creative writing, and 42.78% on embodied task planning. The demo page can be found at https://craftjarvis.github.io/RAT
CLOVA: A Closed-Loop Visual Assistant with Tool Usage and Update
Dec 18, 2023Leveraging large language models (LLMs) to integrate off-the-shelf tools (e.g., visual models and image processing functions) is a promising research direction to build powerful visual assistants for solving diverse visual tasks. However, the learning capability is rarely explored in existing methods, as they freeze the used tools after deployment, thereby limiting the generalization to new environments requiring specific knowledge. In this paper, we propose CLOVA, a Closed-LOop Visual Assistant to address this limitation, which encompasses inference, reflection, and learning phases in a closed-loop framework. During inference, LLMs generate programs and execute corresponding tools to accomplish given tasks. The reflection phase introduces a multimodal global-local reflection scheme to analyze whether and which tool needs to be updated based on environmental feedback. Lastly, the learning phase uses three flexible manners to collect training data in real-time and introduces a novel prompt tuning scheme to update the tools, enabling CLOVA to efficiently learn specific knowledge for new environments without human involvement. Experiments show that CLOVA outperforms tool-usage methods by 5% in visual question answering and multiple-image reasoning tasks, by 10% in knowledge tagging tasks, and by 20% in image editing tasks, highlighting the significance of the learning capability for general visual assistants.
JARVIS-1: Open-World Multi-task Agents with Memory-Augmented Multimodal Language Models
Nov 30, 2023Achieving human-like planning and control with multimodal observations in an open world is a key milestone for more functional generalist agents. Existing approaches can handle certain long-horizon tasks in an open world. However, they still struggle when the number of open-world tasks could potentially be infinite and lack the capability to progressively enhance task completion as game time progresses. We introduce JARVIS-1, an open-world agent that can perceive multimodal input (visual observations and human instructions), generate sophisticated plans, and perform embodied control, all within the popular yet challenging open-world Minecraft universe. Specifically, we develop JARVIS-1 on top of pre-trained multimodal language models, which map visual observations and textual instructions to plans. The plans will be ultimately dispatched to the goal-conditioned controllers. We outfit JARVIS-1 with a multimodal memory, which facilitates planning using both pre-trained knowledge and its actual game survival experiences. JARVIS-1 is the existing most general agent in Minecraft, capable of completing over 200 different tasks using control and observation space similar to humans. These tasks range from short-horizon tasks, e.g., "chopping trees" to long-horizon tasks, e.g., "obtaining a diamond pickaxe". JARVIS-1 performs exceptionally well in short-horizon tasks, achieving nearly perfect performance. In the classic long-term task of $\texttt{ObtainDiamondPickaxe}$, JARVIS-1 surpasses the reliability of current state-of-the-art agents by 5 times and can successfully complete longer-horizon and more challenging tasks. The project page is available at https://craftjarvis.org/JARVIS-1
An Embodied Generalist Agent in 3D World
Nov 18, 2023
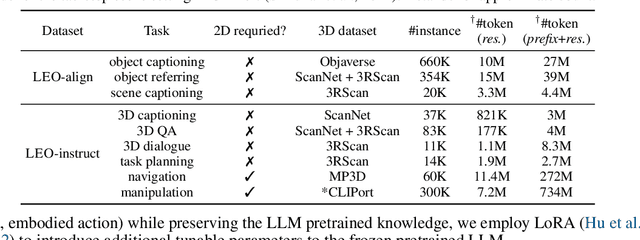
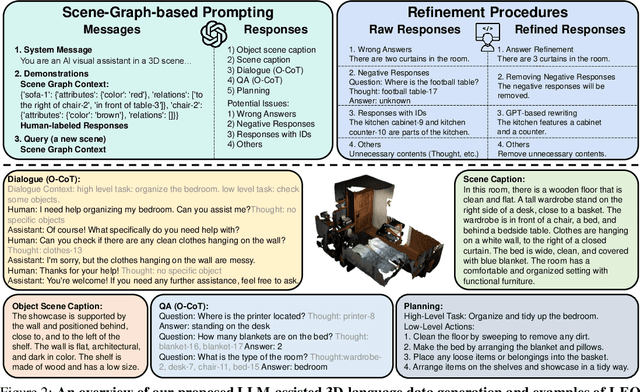
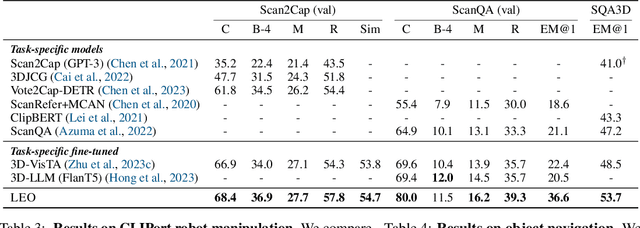
Leveraging massive knowledge and learning schemes from large language models (LLMs), recent machine learning models show notable successes in building generalist agents that exhibit the capability of general-purpose task solving in diverse domains, including natural language processing, computer vision, and robotics. However, a significant challenge remains as these models exhibit limited ability in understanding and interacting with the 3D world. We argue this limitation significantly hinders the current models from performing real-world tasks and further achieving general intelligence. To this end, we introduce an embodied multi-modal and multi-task generalist agent that excels in perceiving, grounding, reasoning, planning, and acting in the 3D world. Our proposed agent, referred to as LEO, is trained with shared LLM-based model architectures, objectives, and weights in two stages: (i) 3D vision-language alignment and (ii) 3D vision-language-action instruction tuning. To facilitate the training, we meticulously curate and generate an extensive dataset comprising object-level and scene-level multi-modal tasks with exceeding scale and complexity, necessitating a deep understanding of and interaction with the 3D world. Through rigorous experiments, we demonstrate LEO's remarkable proficiency across a wide spectrum of tasks, including 3D captioning, question answering, embodied reasoning, embodied navigation, and robotic manipulation. Our ablation results further provide valuable insights for the development of future embodied generalist agents.
Bongard-OpenWorld: Few-Shot Reasoning for Free-form Visual Concepts in the Real World
Oct 16, 2023


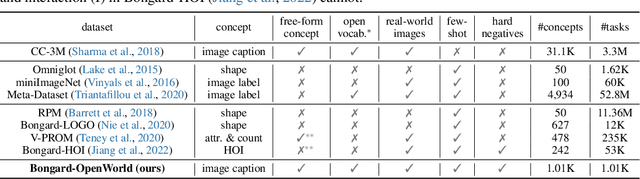
We introduce Bongard-OpenWorld, a new benchmark for evaluating real-world few-shot reasoning for machine vision. It originates from the classical Bongard Problems (BPs): Given two sets of images (positive and negative), the model needs to identify the set that query images belong to by inducing the visual concepts, which is exclusively depicted by images from the positive set. Our benchmark inherits the few-shot concept induction of the original BPs while adding the two novel layers of challenge: 1) open-world free-form concepts, as the visual concepts in Bongard-OpenWorld are unique compositions of terms from an open vocabulary, ranging from object categories to abstract visual attributes and commonsense factual knowledge; 2) real-world images, as opposed to the synthetic diagrams used by many counterparts. In our exploration, Bongard-OpenWorld already imposes a significant challenge to current few-shot reasoning algorithms. We further investigate to which extent the recently introduced Large Language Models (LLMs) and Vision-Language Models (VLMs) can solve our task, by directly probing VLMs, and combining VLMs and LLMs in an interactive reasoning scheme. We even designed a neuro-symbolic reasoning approach that reconciles LLMs & VLMs with logical reasoning to emulate the human problem-solving process for Bongard Problems. However, none of these approaches manage to close the human-machine gap, as the best learner achieves 64% accuracy while human participants easily reach 91%. We hope Bongard-OpenWorld can help us better understand the limitations of current visual intelligence and facilitate future research on visual agents with stronger few-shot visual reasoning capabilities.
GROOT: Learning to Follow Instructions by Watching Gameplay Videos
Oct 12, 2023We study the problem of building a controller that can follow open-ended instructions in open-world environments. We propose to follow reference videos as instructions, which offer expressive goal specifications while eliminating the need for expensive text-gameplay annotations. A new learning framework is derived to allow learning such instruction-following controllers from gameplay videos while producing a video instruction encoder that induces a structured goal space. We implement our agent GROOT in a simple yet effective encoder-decoder architecture based on causal transformers. We evaluate GROOT against open-world counterparts and human players on a proposed Minecraft SkillForge benchmark. The Elo ratings clearly show that GROOT is closing the human-machine gap as well as exhibiting a 70% winning rate over the best generalist agent baseline. Qualitative analysis of the induced goal space further demonstrates some interesting emergent properties, including the goal composition and complex gameplay behavior synthesis. Code and video can be found on the website https://craftjarvis-groot.github.io.
Learning Energy-Based Prior Model with Diffusion-Amortized MCMC
Oct 05, 2023



Latent space Energy-Based Models (EBMs), also known as energy-based priors, have drawn growing interests in the field of generative modeling due to its flexibility in the formulation and strong modeling power of the latent space. However, the common practice of learning latent space EBMs with non-convergent short-run MCMC for prior and posterior sampling is hindering the model from further progress; the degenerate MCMC sampling quality in practice often leads to degraded generation quality and instability in training, especially with highly multi-modal and/or high-dimensional target distributions. To remedy this sampling issue, in this paper we introduce a simple but effective diffusion-based amortization method for long-run MCMC sampling and develop a novel learning algorithm for the latent space EBM based on it. We provide theoretical evidence that the learned amortization of MCMC is a valid long-run MCMC sampler. Experiments on several image modeling benchmark datasets demonstrate the superior performance of our method compared with strong counterparts
MMICL: Empowering Vision-language Model with Multi-Modal In-Context Learning
Oct 02, 2023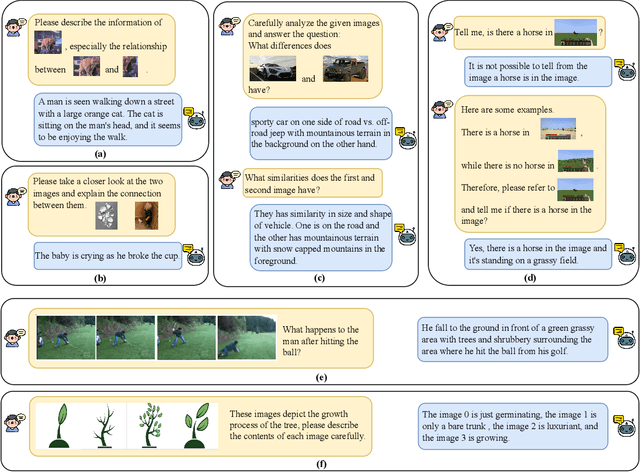
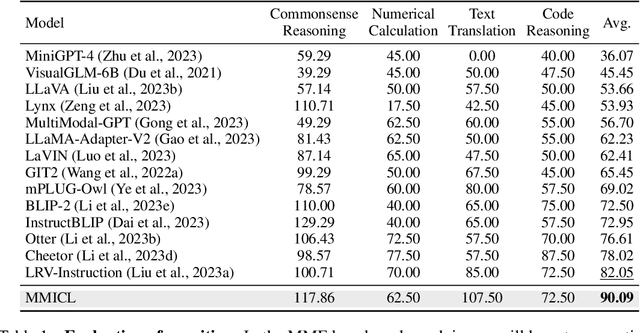
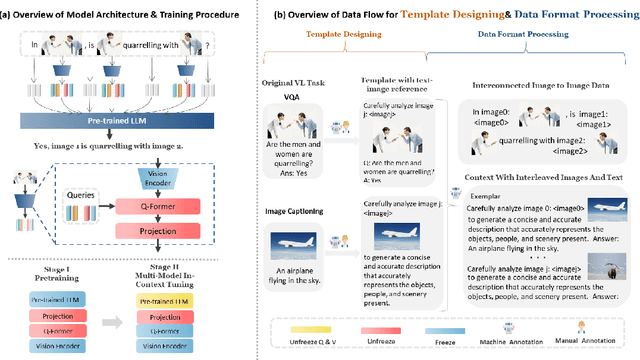
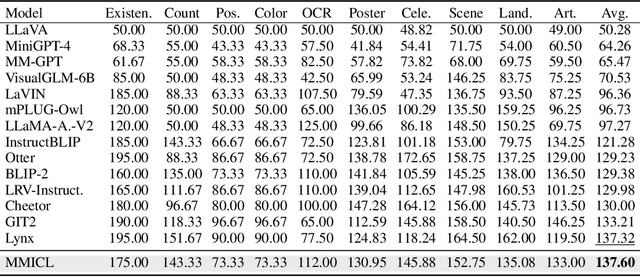
Since the resurgence of deep learning, vision-language models (VLMs) enhanced by large language models (LLMs) have grown exponentially in popularity. However, while LLMs can utilize extensive background knowledge and task information with in-context learning, most VLMs still struggle with understanding complex multi-modal prompts with multiple images, making VLMs less effective in downstream vision-language tasks. In this paper, we address the limitation above by 1) introducing MMICL, a new approach to allow the VLM to deal with multi-modal inputs efficiently; 2) proposing a novel context scheme to augment the in-context learning ability of the VLM; 3) constructing the Multi-modal In-Context Learning (MIC) dataset, designed to enhance the VLM's ability to understand complex multi-modal prompts. Our experiments confirm that MMICL achieves new state-of-the-art zero-shot performance on a wide range of general vision-language tasks, especially for complex benchmarks, including MME and MMBench. Our analysis demonstrates that MMICL effectively tackles the challenge of complex multi-modal prompt understanding and emerges the impressive ICL ability. Furthermore, we observe that MMICL successfully alleviates language bias in VLMs, a common issue for VLMs that often leads to hallucination when faced with extensive textual context.