 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYuancheng Wang
RALL-E: Robust Codec Language Modeling with Chain-of-Thought Prompting for Text-to-Speech Synthesis
Apr 06, 2024
We present RALL-E, a robust language modeling method for text-to-speech (TTS) synthesis. While previous work based on large language models (LLMs) shows impressive performance on zero-shot TTS, such methods often suffer from poor robustness, such as unstable prosody (weird pitch and rhythm/duration) and a high word error rate (WER), due to the autoregressive prediction style of language models. The core idea behind RALL-E is chain-of-thought (CoT) prompting, which decomposes the task into simpler steps to enhance the robustness of LLM-based TTS. To accomplish this idea, RALL-E first predicts prosody features (pitch and duration) of the input text and uses them as intermediate conditions to predict speech tokens in a CoT style. Second, RALL-E utilizes the predicted duration prompt to guide the computing of self-attention weights in Transformer to enforce the model to focus on the corresponding phonemes and prosody features when predicting speech tokens. Results of comprehensive objective and subjective evaluations demonstrate that, compared to a powerful baseline method VALL-E, RALL-E significantly improves the WER of zero-shot TTS from $6.3\%$ (without reranking) and $2.1\%$ (with reranking) to $2.8\%$ and $1.0\%$, respectively. Furthermore, we demonstrate that RALL-E correctly synthesizes sentences that are hard for VALL-E and reduces the error rate from $68\%$ to $4\%$.
NaturalSpeech 3: Zero-Shot Speech Synthesis with Factorized Codec and Diffusion Models
Mar 05, 2024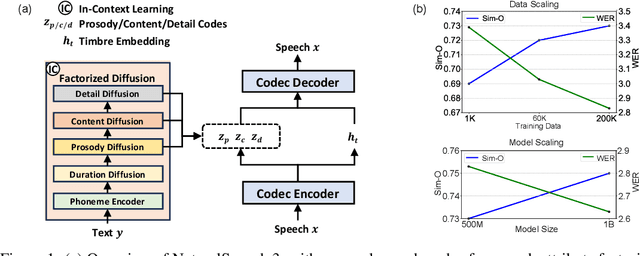
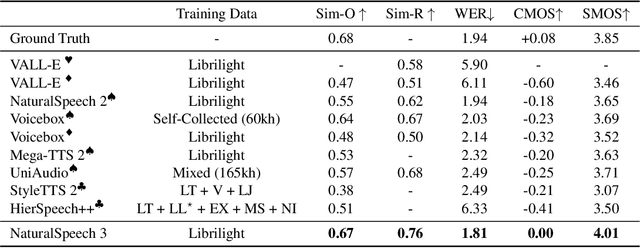
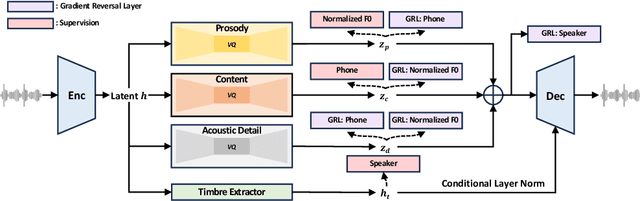
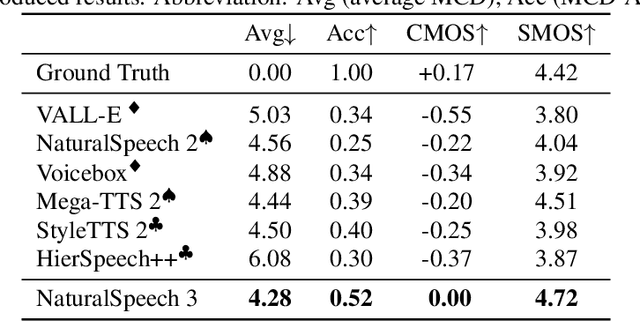
While recent large-scale text-to-speech (TTS) models have achieved significant progress, they still fall short in speech quality, similarity, and prosody. Considering speech intricately encompasses various attributes (e.g., content, prosody, timbre, and acoustic details) that pose significant challenges for generation, a natural idea is to factorize speech into individual subspaces representing different attributes and generate them individually. Motivated by it, we propose NaturalSpeech 3, a TTS system with novel factorized diffusion models to generate natural speech in a zero-shot way. Specifically, 1) we design a neural codec with factorized vector quantization (FVQ) to disentangle speech waveform into subspaces of content, prosody, timbre, and acoustic details; 2) we propose a factorized diffusion model to generate attributes in each subspace following its corresponding prompt. With this factorization design, NaturalSpeech 3 can effectively and efficiently model the intricate speech with disentangled subspaces in a divide-and-conquer way. Experiments show that NaturalSpeech 3 outperforms the state-of-the-art TTS systems on quality, similarity, prosody, and intelligibility. Furthermore, we achieve better performance by scaling to 1B parameters and 200K hours of training data.
Amphion: An Open-Source Audio, Music and Speech Generation Toolkit
Dec 15, 2023
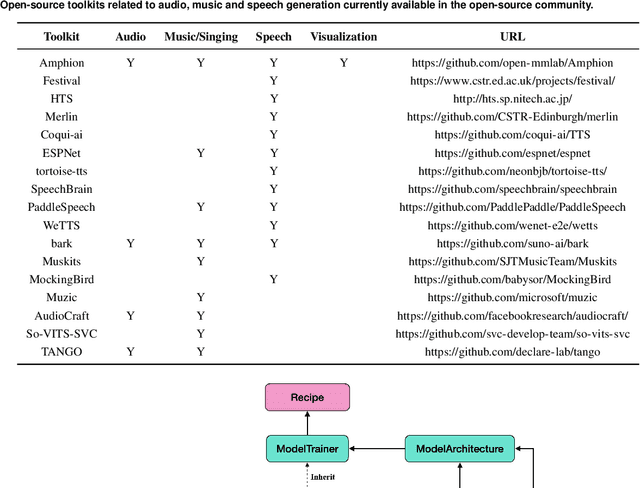
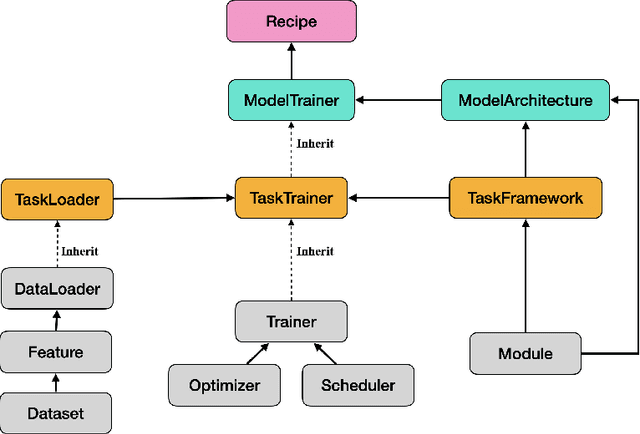
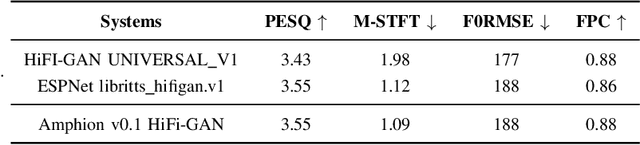
Amphion is a toolkit for Audio, Music, and Speech Generation. Its purpose is to support reproducible research and help junior researchers and engineers get started in the field of audio, music, and speech generation research and development. Amphion offers a unique feature: visualizations of classic models or architectures. We believe that these visualizations are beneficial for junior researchers and engineers who wish to gain a better understanding of the model. The North-Star objective of Amphion is to offer a platform for studying the conversion of any inputs into general audio. Amphion is designed to support individual generation tasks. In addition to the specific generation tasks, Amphion also includes several vocoders and evaluation metrics. A vocoder is an important module for producing high-quality audio signals, while evaluation metrics are critical for ensuring consistent metrics in generation tasks. In this paper, we provide a high-level overview of Amphion.
Trustworthy Multi-phase Liver Tumor Segmentation via Evidence-based Uncertainty
May 09, 2023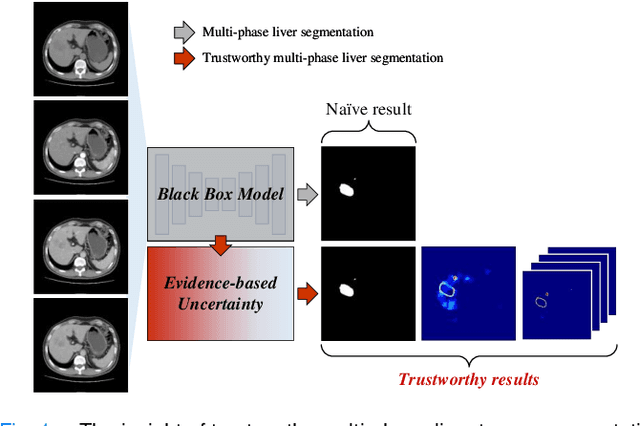
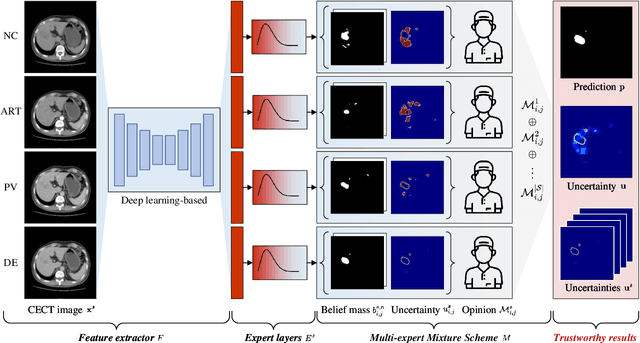
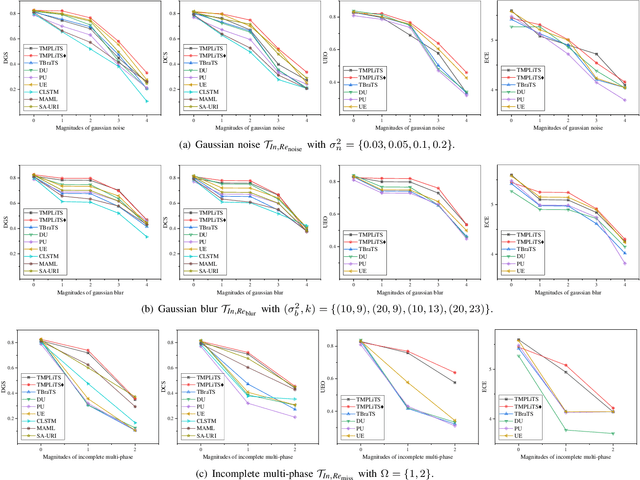
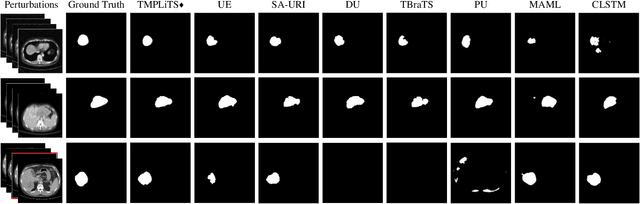
Multi-phase liver contrast-enhanced computed tomography (CECT) images convey the complementary multi-phase information for liver tumor segmentation (LiTS), which are crucial to assist the diagnosis of liver cancer clinically. However, the performances of existing multi-phase liver tumor segmentation (MPLiTS)-based methods suffer from redundancy and weak interpretability, % of the fused result, resulting in the implicit unreliability of clinical applications. In this paper, we propose a novel trustworthy multi-phase liver tumor segmentation (TMPLiTS), which is a unified framework jointly conducting segmentation and uncertainty estimation. The trustworthy results could assist the clinicians to make a reliable diagnosis. Specifically, Dempster-Shafer Evidence Theory (DST) is introduced to parameterize the segmentation and uncertainty as evidence following Dirichlet distribution. The reliability of segmentation results among multi-phase CECT images is quantified explicitly. Meanwhile, a multi-expert mixture scheme (MEMS) is proposed to fuse the multi-phase evidences, which can guarantee the effect of fusion procedure based on theoretical analysis. Experimental results demonstrate the superiority of TMPLiTS compared with the state-of-the-art methods. Meanwhile, the robustness of TMPLiTS is verified, where the reliable performance can be guaranteed against the perturbations.
AUDIT: Audio Editing by Following Instructions with Latent Diffusion Models
Apr 05, 2023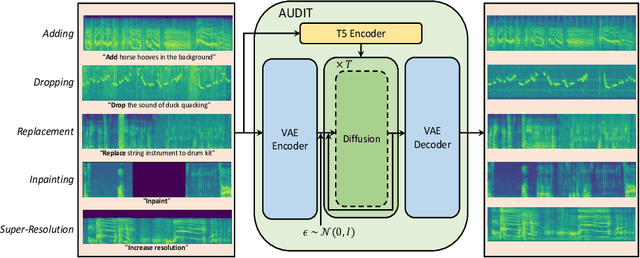
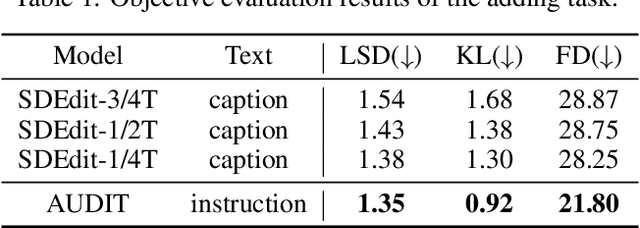
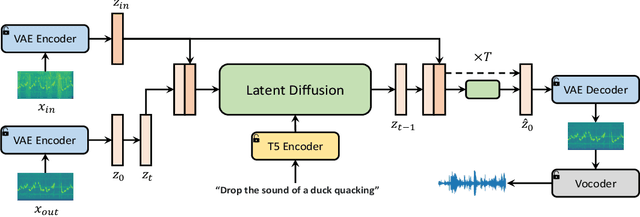
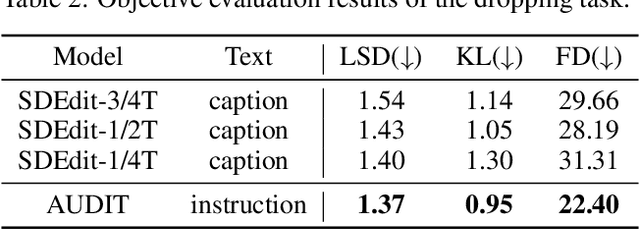
Audio editing is applicable for various purposes, such as adding background sound effects, replacing a musical instrument, and repairing damaged audio. Recently, some diffusion-based methods achieved zero-shot audio editing by using a diffusion and denoising process conditioned on the text description of the output audio. However, these methods still have some problems: 1) they have not been trained on editing tasks and cannot ensure good editing effects; 2) they can erroneously modify audio segments that do not require editing; 3) they need a complete description of the output audio, which is not always available or necessary in practical scenarios. In this work, we propose AUDIT, an instruction-guided audio editing model based on latent diffusion models. Specifically, AUDIT has three main design features: 1) we construct triplet training data (instruction, input audio, output audio) for different audio editing tasks and train a diffusion model using instruction and input (to be edited) audio as conditions and generating output (edited) audio; 2) it can automatically learn to only modify segments that need to be edited by comparing the difference between the input and output audio; 3) it only needs edit instructions instead of full target audio descriptions as text input. AUDIT achieves state-of-the-art results in both objective and subjective metrics for several audio editing tasks (e.g., adding, dropping, replacement, inpainting, super-resolution). Demo samples are available at https://audit-demo.github.io/.
An Attention-Based Approach for Single Image Super Resolution
Jul 18, 2018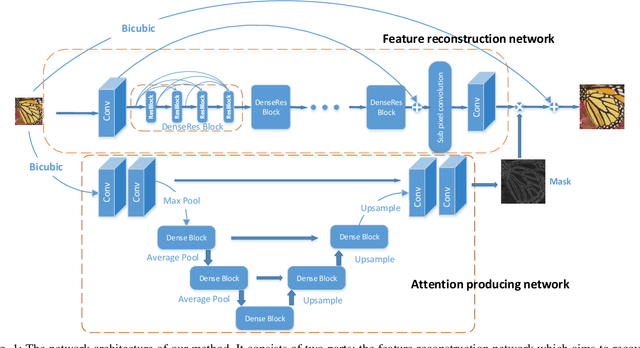
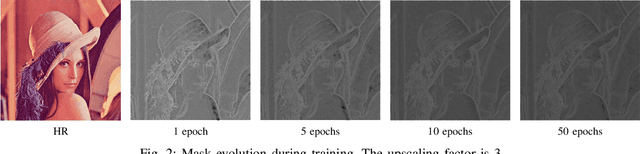

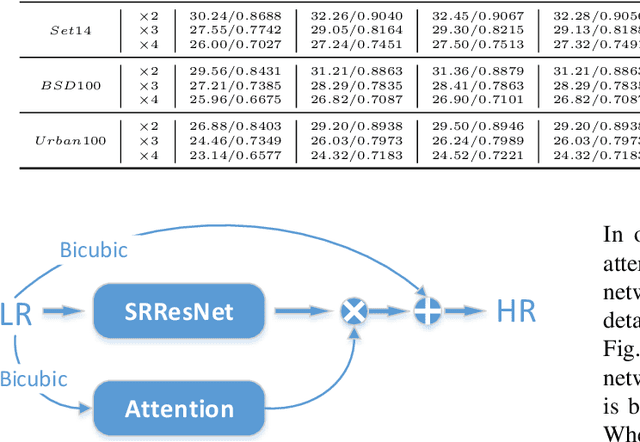
The main challenge of single image super resolution (SISR) is the recovery of high frequency details such as tiny textures. However, most of the state-of-the-art methods lack specific modules to identify high frequency areas, causing the output image to be blurred. We propose an attention-based approach to give a discrimination between texture areas and smooth areas. After the positions of high frequency details are located, high frequency compensation is carried out. This approach can incorporate with previously proposed SISR networks. By providing high frequency enhancement, better performance and visual effect are achieved. We also propose our own SISR network composed of DenseRes blocks. The block provides an effective way to combine the low level features and high level features. Extensive benchmark evaluation shows that our proposed method achieves significant improvement over the state-of-the-art works in SISR.