 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYeying Jin
MoE-TinyMed: Mixture of Experts for Tiny Medical Large Vision-Language Models
Apr 16, 2024




Mixture of Expert Tuning (MoE-Tuning) has effectively enhanced the performance of general MLLMs with fewer parameters, yet its application in resource-limited medical settings has not been fully explored. To address this gap, we developed MoE-TinyMed, a model tailored for medical applications that significantly lowers parameter demands. In evaluations on the VQA-RAD, SLAKE, and Path-VQA datasets, MoE-TinyMed outperformed LLaVA-Med in all Med-VQA closed settings with just 3.6B parameters. Additionally, a streamlined version with 2B parameters surpassed LLaVA-Med's performance in PathVQA, showcasing its effectiveness in resource-limited healthcare settings.
Joint Visual and Text Prompting for Improved Object-Centric Perception with Multimodal Large Language Models
Apr 06, 2024



Multimodal Large Language Models (MLLMs) such as GPT-4V and Gemini Pro face challenges in achieving human-level perception in Visual Question Answering (VQA), particularly in object-oriented perception tasks which demand fine-grained understanding of object identities, locations or attributes, as indicated by empirical findings. This is mainly due to their limited capability to effectively integrate complex visual cues with textual information and potential object hallucinations. In this paper, we present a novel approach, Joint Visual and Text Prompting (VTPrompt), that employs fine-grained visual information to enhance the capability of MLLMs in VQA, especially for object-oriented perception. VTPrompt merges visual and text prompts to extract key concepts from textual questions and employs a detection model to highlight relevant objects as visual prompts in images. The processed images alongside text prompts are subsequently fed into MLLMs to produce more accurate answers. Our experiments with GPT-4V and Gemini Pro, on three benchmarks, i.e., MME , MMB and POPE, demonstrate significant improvements. Particularly, our method led to a score improvement of up to 183.5 for GPT-4V on MME and enhanced MMB performance by 8.17\% for GPT-4V and 15.69\% for Gemini Pro.
How Powerful Potential of Attention on Image Restoration?
Mar 15, 2024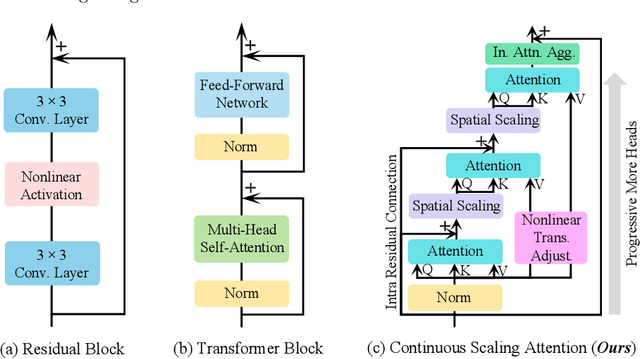
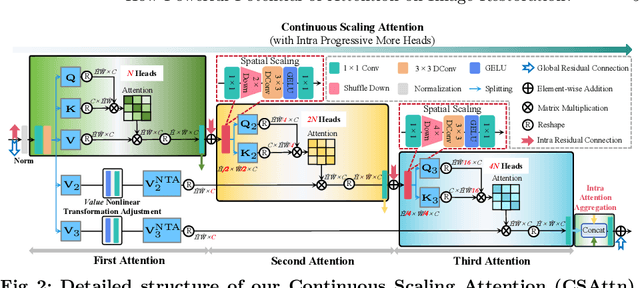
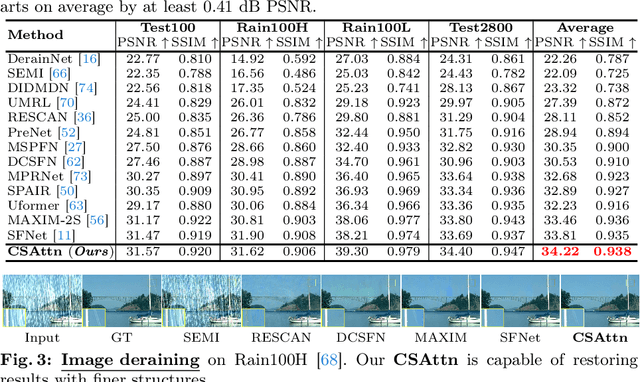
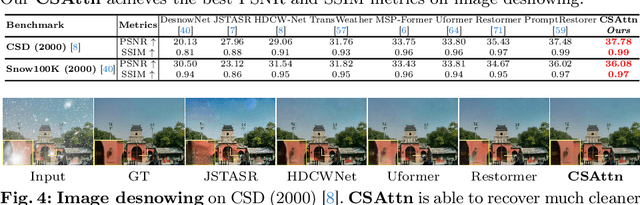
Transformers have demonstrated their effectiveness in image restoration tasks. Existing Transformer architectures typically comprise two essential components: multi-head self-attention and feed-forward network (FFN). The former captures long-range pixel dependencies, while the latter enables the model to learn complex patterns and relationships in the data. Previous studies have demonstrated that FFNs are key-value memories \cite{geva2020transformer}, which are vital in modern Transformer architectures. In this paper, we conduct an empirical study to explore the potential of attention mechanisms without using FFN and provide novel structures to demonstrate that removing FFN is flexible for image restoration. Specifically, we propose Continuous Scaling Attention (\textbf{CSAttn}), a method that computes attention continuously in three stages without using FFN. To achieve competitive performance, we propose a series of key components within the attention. Our designs provide a closer look at the attention mechanism and reveal that some simple operations can significantly affect the model performance. We apply our \textbf{CSAttn} to several image restoration tasks and show that our model can outperform CNN-based and Transformer-based image restoration approaches.
NightHaze: Nighttime Image Dehazing via Self-Prior Learning
Mar 12, 2024
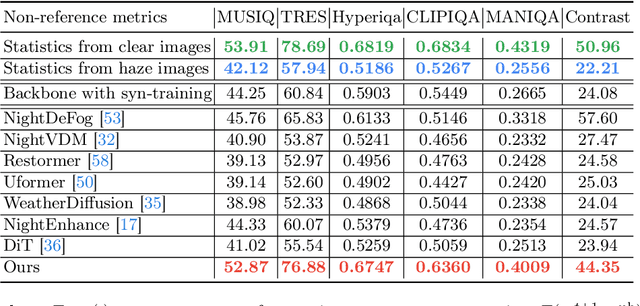
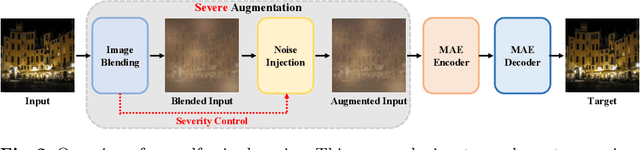
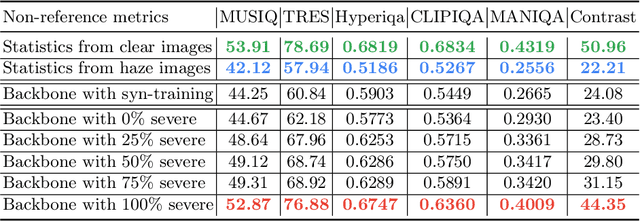
Masked autoencoder (MAE) shows that severe augmentation during training produces robust representations for high-level tasks. This paper brings the MAE-like framework to nighttime image enhancement, demonstrating that severe augmentation during training produces strong network priors that are resilient to real-world night haze degradations. We propose a novel nighttime image dehazing method with self-prior learning. Our main novelty lies in the design of severe augmentation, which allows our model to learn robust priors. Unlike MAE that uses masking, we leverage two key challenging factors of nighttime images as augmentation: light effects and noise. During training, we intentionally degrade clear images by blending them with light effects as well as by adding noise, and subsequently restore the clear images. This enables our model to learn clear background priors. By increasing the noise values to approach as high as the pixel intensity values of the glow and light effect blended images, our augmentation becomes severe, resulting in stronger priors. While our self-prior learning is considerably effective in suppressing glow and revealing details of background scenes, in some cases, there are still some undesired artifacts that remain, particularly in the forms of over-suppression. To address these artifacts, we propose a self-refinement module based on the semi-supervised teacher-student framework. Our NightHaze, especially our MAE-like self-prior learning, shows that models trained with severe augmentation effectively improve the visibility of input haze images, approaching the clarity of clear nighttime images. Extensive experiments demonstrate that our NightHaze achieves state-of-the-art performance, outperforming existing nighttime image dehazing methods by a substantial margin of 15.5% for MUSIQ and 23.5% for ClipIQA.
SeD: Semantic-Aware Discriminator for Image Super-Resolution
Feb 29, 2024Generative Adversarial Networks (GANs) have been widely used to recover vivid textures in image super-resolution (SR) tasks. In particular, one discriminator is utilized to enable the SR network to learn the distribution of real-world high-quality images in an adversarial training manner. However, the distribution learning is overly coarse-grained, which is susceptible to virtual textures and causes counter-intuitive generation results. To mitigate this, we propose the simple and effective Semantic-aware Discriminator (denoted as SeD), which encourages the SR network to learn the fine-grained distributions by introducing the semantics of images as a condition. Concretely, we aim to excavate the semantics of images from a well-trained semantic extractor. Under different semantics, the discriminator is able to distinguish the real-fake images individually and adaptively, which guides the SR network to learn the more fine-grained semantic-aware textures. To obtain accurate and abundant semantics, we take full advantage of recently popular pretrained vision models (PVMs) with extensive datasets, and then incorporate its semantic features into the discriminator through a well-designed spatial cross-attention module. In this way, our proposed semantic-aware discriminator empowered the SR network to produce more photo-realistic and pleasing images. Extensive experiments on two typical tasks, i.e., SR and Real SR have demonstrated the effectiveness of our proposed methods.
Polyp-DAM: Polyp segmentation via depth anything model
Feb 03, 2024Recently, large models (Segment Anything model) came on the scene to provide a new baseline for polyp segmentation tasks. This demonstrates that large models with a sufficient image level prior can achieve promising performance on a given task. In this paper, we unfold a new perspective on polyp segmentation modeling by leveraging the Depth Anything Model (DAM) to provide depth prior to polyp segmentation models. Specifically, the input polyp image is first passed through a frozen DAM to generate a depth map. The depth map and the input polyp images are then concatenated and fed into a convolutional neural network with multiscale to generate segmented images. Extensive experimental results demonstrate the effectiveness of our method, and in addition, we observe that our method still performs well on images of polyps with noise. The URL of our code is \url{https://github.com/zzr-idam/Polyp-DAM}.
NightRain: Nighttime Video Deraining via Adaptive-Rain-Removal and Adaptive-Correction
Jan 10, 2024Existing deep-learning-based methods for nighttime video deraining rely on synthetic data due to the absence of real-world paired data. However, the intricacies of the real world, particularly with the presence of light effects and low-light regions affected by noise, create significant domain gaps, hampering synthetic-trained models in removing rain streaks properly and leading to over-saturation and color shifts. Motivated by this, we introduce NightRain, a novel nighttime video deraining method with adaptive-rain-removal and adaptive-correction. Our adaptive-rain-removal uses unlabeled rain videos to enable our model to derain real-world rain videos, particularly in regions affected by complex light effects. The idea is to allow our model to obtain rain-free regions based on the confidence scores. Once rain-free regions and the corresponding regions from our input are obtained, we can have region-based paired real data. These paired data are used to train our model using a teacher-student framework, allowing the model to iteratively learn from less challenging regions to more challenging regions. Our adaptive-correction aims to rectify errors in our model's predictions, such as over-saturation and color shifts. The idea is to learn from clear night input training videos based on the differences or distance between those input videos and their corresponding predictions. Our model learns from these differences, compelling our model to correct the errors. From extensive experiments, our method demonstrates state-of-the-art performance. It achieves a PSNR of 26.73dB, surpassing existing nighttime video deraining methods by a substantial margin of 13.7%.
Enhancing Visibility in Nighttime Haze Images Using Guided APSF and Gradient Adaptive Convolution
Aug 05, 2023
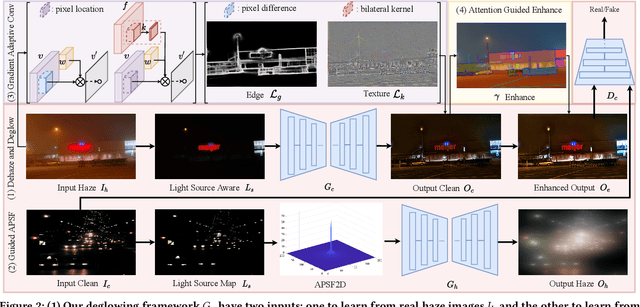

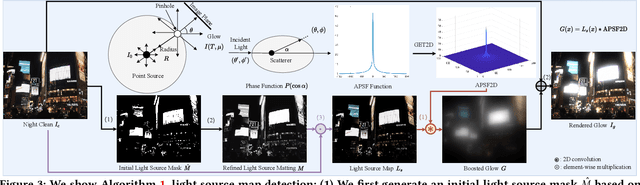
Visibility in hazy nighttime scenes is frequently reduced by multiple factors, including low light, intense glow, light scattering, and the presence of multicolored light sources. Existing nighttime dehazing methods often struggle with handling glow or low-light conditions, resulting in either excessively dark visuals or unsuppressed glow outputs. In this paper, we enhance the visibility from a single nighttime haze image by suppressing glow and enhancing low-light regions. To handle glow effects, our framework learns from the rendered glow pairs. Specifically, a light source aware network is proposed to detect light sources of night images, followed by the APSF (Angular Point Spread Function)-guided glow rendering. Our framework is then trained on the rendered images, resulting in glow suppression. Moreover, we utilize gradient-adaptive convolution, to capture edges and textures in hazy scenes. By leveraging extracted edges and textures, we enhance the contrast of the scene without losing important structural details. To boost low-light intensity, our network learns an attention map, then adjusted by gamma correction. This attention has high values on low-light regions and low values on haze and glow regions. Extensive evaluation on real nighttime haze images, demonstrates the effectiveness of our method. Our experiments demonstrate that our method achieves a PSNR of 30.38dB, outperforming state-of-the-art methods by 13$\%$ on GTA5 nighttime haze dataset. Our data and code is available at: \url{https://github.com/jinyeying/nighttime_dehaze}.
* Accepted to ACMMM2023, https://github.com/jinyeying/nighttime_dehaze
Estimating Reflectance Layer from A Single Image: Integrating Reflectance Guidance and Shadow/Specular Aware Learning
Nov 27, 2022
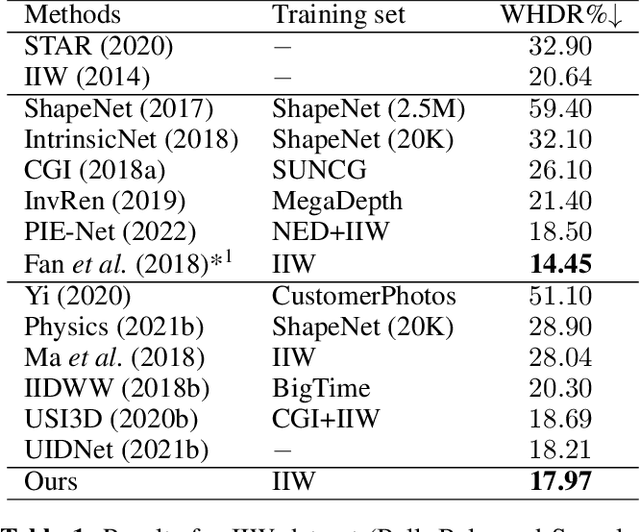

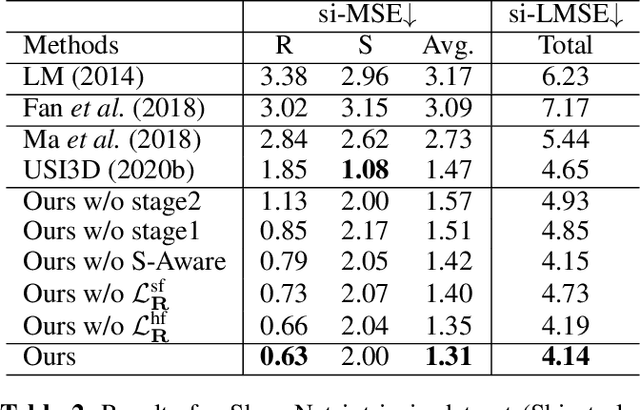
Estimating reflectance layer from a single image is a challenging task. It becomes more challenging when the input image contains shadows or specular highlights, which often render an inaccurate estimate of the reflectance layer. Therefore, we propose a two-stage learning method, including reflectance guidance and a Shadow/Specular-Aware (S-Aware) network to tackle the problem. In the first stage, an initial reflectance layer free from shadows and specularities is obtained with the constraint of novel losses that are guided by prior-based shadow-free and specular-free images. To further enforce the reflectance layer to be independent from shadows and specularities in the second-stage refinement, we introduce an S-Aware network that distinguishes the reflectance image from the input image. Our network employs a classifier to categorize shadow/shadow-free, specular/specular-free classes, enabling the activation features to function as attention maps that focus on shadow/specular regions. Our quantitative and qualitative evaluations show that our method outperforms the state-of-the-art methods in the reflectance layer estimation that is free from shadows and specularities.
* Accepted to AAAI2023
ShadowDiffusion: Diffusion-based Shadow Removal using Classifier-driven Attention and Structure Preservation
Nov 15, 2022



Shadow removal from a single image is challenging, particularly with the presence of soft and self shadows. Unlike hard shadows, soft shadows do not show any clear boundaries, while self shadows are shadows that cast on the object itself. Most existing methods require the detection/annotation of binary shadow masks, without taking into account the ambiguous boundaries of soft and self shadows. Most deep learning shadow removal methods are GAN-based and require statistical similarity between shadow and shadow-free domains. In contrast to these methods, in this paper, we present ShadowDiffusion, the first diffusion-based shadow removal method. ShadowDiffusion focuses on single-image shadow removal, even in the presence of soft and self shadows. To guide the diffusion process to recover semantically meaningful structures during the reverse diffusion, we introduce a structure preservation loss, where we extract features from the pre-trained Vision Transformer (DINO-ViT). Moreover, to focus on the recovery of shadow regions, we inject classifier-driven attention into the architecture of the diffusion model. To maintain the consistent colors of the regions where the shadows have been removed, we introduce a chromaticity consistency loss. Our ShadowDiffusion outperforms state-of-the-art methods on the SRD, AISTD, LRSS, USR and UIUC datasets, removing hard, soft, and self shadows robustly. Our method outperforms the SOTA method by 20% of the RMSE of the whole image on the SRD dataset.