 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYuzhe Gu
ESC: Efficient Speech Coding with Cross-Scale Residual Vector Quantized Transformers
Apr 30, 2024
Existing neural audio codecs usually sacrifice computational complexity for audio quality. They build the feature transformation layers mainly on convolutional blocks, which are not inherently appropriate for capturing local redundancies of audio signals. As compensation, either adversarial losses from a discriminator or a large number of model parameters are required to improve the codec. To that end, we propose Efficient Speech Codec (ESC), a lightweight parameter-efficient codec laid on cross-scale residual vector quantization and transformers. Our model leverages mirrored hierarchical window-attention transformer blocks and performs step-wise decoding from coarse-to-fine feature representations. To enhance codebook utilization, we design a learning paradigm that involves a pre-training stage to assist with codec training. Extensive results show that ESC can achieve high audio quality with much lower complexity, which is a prospective alternative in place of existing codecs.
How Did We Get Here? Summarizing Conversation Dynamics
Apr 29, 2024Throughout a conversation, the way participants interact with each other is in constant flux: their tones may change, they may resort to different strategies to convey their points, or they might alter their interaction patterns. An understanding of these dynamics can complement that of the actual facts and opinions discussed, offering a more holistic view of the trajectory of the conversation: how it arrived at its current state and where it is likely heading. In this work, we introduce the task of summarizing the dynamics of conversations, by constructing a dataset of human-written summaries, and exploring several automated baselines. We evaluate whether such summaries can capture the trajectory of conversations via an established downstream task: forecasting whether an ongoing conversation will eventually derail into toxic behavior. We show that they help both humans and automated systems with this forecasting task. Humans make predictions three times faster, and with greater confidence, when reading the summaries than when reading the transcripts. Furthermore, automated forecasting systems are more accurate when constructing, and then predicting based on, summaries of conversation dynamics, compared to directly predicting on the transcripts.
InternLM2 Technical Report
Mar 26, 2024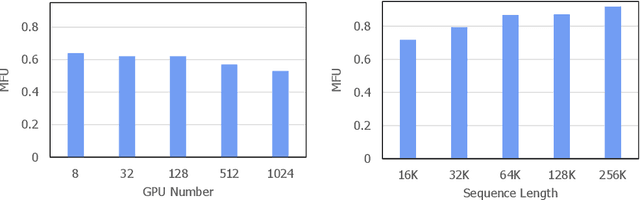
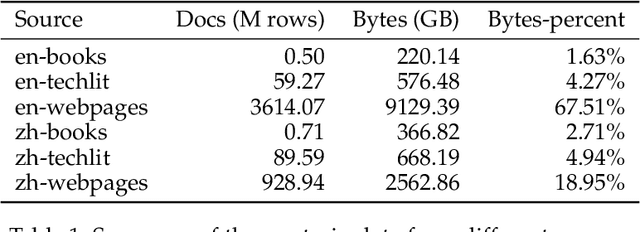


The evolution of Large Language Models (LLMs) like ChatGPT and GPT-4 has sparked discussions on the advent of Artificial General Intelligence (AGI). However, replicating such advancements in open-source models has been challenging. This paper introduces InternLM2, an open-source LLM that outperforms its predecessors in comprehensive evaluations across 6 dimensions and 30 benchmarks, long-context modeling, and open-ended subjective evaluations through innovative pre-training and optimization techniques. The pre-training process of InternLM2 is meticulously detailed, highlighting the preparation of diverse data types including text, code, and long-context data. InternLM2 efficiently captures long-term dependencies, initially trained on 4k tokens before advancing to 32k tokens in pre-training and fine-tuning stages, exhibiting remarkable performance on the 200k ``Needle-in-a-Haystack" test. InternLM2 is further aligned using Supervised Fine-Tuning (SFT) and a novel Conditional Online Reinforcement Learning from Human Feedback (COOL RLHF) strategy that addresses conflicting human preferences and reward hacking. By releasing InternLM2 models in different training stages and model sizes, we provide the community with insights into the model's evolution.