 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHaoran Xie
DE-CGAN: Boosting rTMS Treatment Prediction with Diversity Enhancing Conditional Generative Adversarial Networks
Apr 25, 2024
Repetitive Transcranial Magnetic Stimulation (rTMS) is a well-supported, evidence-based treatment for depression. However, patterns of response to this treatment are inconsistent. Emerging evidence suggests that artificial intelligence can predict rTMS treatment outcomes for most patients using fMRI connectivity features. While these models can reliably predict treatment outcomes for many patients for some underrepresented fMRI connectivity measures DNN models are unable to reliably predict treatment outcomes. As such we propose a novel method, Diversity Enhancing Conditional General Adversarial Network (DE-CGAN) for oversampling these underrepresented examples. DE-CGAN creates synthetic examples in difficult-to-classify regions by first identifying these data points and then creating conditioned synthetic examples to enhance data diversity. Through empirical experiments we show that a classification model trained using a diversity enhanced training set outperforms traditional data augmentation techniques and existing benchmark results. This work shows that increasing the diversity of a training dataset can improve classification model performance. Furthermore, this work provides evidence for the utility of synthetic patients providing larger more robust datasets for both AI researchers and psychiatrists to explore variable relationships.
FilterPrompt: Guiding Image Transfer in Diffusion Models
Apr 20, 2024In controllable generation tasks, flexibly manipulating the generated images to attain a desired appearance or structure based on a single input image cue remains a critical and longstanding challenge. Achieving this requires the effective decoupling of key attributes within the input image data, aiming to get representations accurately. Previous research has predominantly concentrated on disentangling image attributes within feature space. However, the complex distribution present in real-world data often makes the application of such decoupling algorithms to other datasets challenging. Moreover, the granularity of control over feature encoding frequently fails to meet specific task requirements. Upon scrutinizing the characteristics of various generative models, we have observed that the input sensitivity and dynamic evolution properties of the diffusion model can be effectively fused with the explicit decomposition operation in pixel space. This integration enables the image processing operations performed in pixel space for a specific feature distribution of the input image, and can achieve the desired control effect in the generated results. Therefore, we propose FilterPrompt, an approach to enhance the model control effect. It can be universally applied to any diffusion model, allowing users to adjust the representation of specific image features in accordance with task requirements, thereby facilitating more precise and controllable generation outcomes. In particular, our designed experiments demonstrate that the FilterPrompt optimizes feature correlation, mitigates content conflicts during the generation process, and enhances the model's control capability.
RLGNet: Repeating-Local-Global History Network for Temporal Knowledge Graph Reasoning
Mar 31, 2024Temporal Knowledge Graph (TKG) reasoning is based on historical information to predict the future. Therefore, parsing and mining historical information is key to predicting the future. Most existing methods fail to concurrently address and comprehend historical information from both global and local perspectives. Neglecting the global view might result in overlooking macroscopic trends and patterns, while ignoring the local view can lead to missing critical detailed information. Additionally, some methods do not focus on learning from high-frequency repeating events, which means they may not fully grasp frequently occurring historical events. To this end, we propose the \textbf{R}epetitive-\textbf{L}ocal-\textbf{G}lobal History \textbf{Net}work(RLGNet). We utilize a global history encoder to capture the overarching nature of historical information. Subsequently, the local history encoder provides information related to the query timestamp. Finally, we employ the repeating history encoder to identify and learn from frequently occurring historical events. In the evaluation on six benchmark datasets, our approach generally outperforms existing TKG reasoning models in multi-step and single-step reasoning tasks.
Generative AI for Architectural Design: A Literature Review
Mar 30, 2024Generative Artificial Intelligence (AI) has pioneered new methodological paradigms in architectural design, significantly expanding the innovative potential and efficiency of the design process. This paper explores the extensive applications of generative AI technologies in architectural design, a trend that has benefited from the rapid development of deep generative models. This article provides a comprehensive review of the basic principles of generative AI and large-scale models and highlights the applications in the generation of 2D images, videos, and 3D models. In addition, by reviewing the latest literature from 2020, this paper scrutinizes the impact of generative AI technologies at different stages of architectural design, from generating initial architectural 3D forms to producing final architectural imagery. The marked trend of research growth indicates an increasing inclination within the architectural design community towards embracing generative AI, thereby catalyzing a shared enthusiasm for research. These research cases and methodologies have not only proven to enhance efficiency and innovation significantly but have also posed challenges to the conventional boundaries of architectural creativity. Finally, we point out new directions for design innovation and articulate fresh trajectories for applying generative AI in the architectural domain. This article provides the first comprehensive literature review about generative AI for architectural design, and we believe this work can facilitate more research work on this significant topic in architecture.
ECNet: Effective Controllable Text-to-Image Diffusion Models
Mar 27, 2024
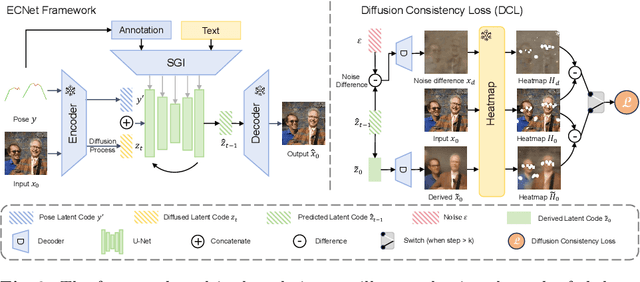
The conditional text-to-image diffusion models have garnered significant attention in recent years. However, the precision of these models is often compromised mainly for two reasons, ambiguous condition input and inadequate condition guidance over single denoising loss. To address the challenges, we introduce two innovative solutions. Firstly, we propose a Spatial Guidance Injector (SGI) which enhances conditional detail by encoding text inputs with precise annotation information. This method directly tackles the issue of ambiguous control inputs by providing clear, annotated guidance to the model. Secondly, to overcome the issue of limited conditional supervision, we introduce Diffusion Consistency Loss (DCL), which applies supervision on the denoised latent code at any given time step. This encourages consistency between the latent code at each time step and the input signal, thereby enhancing the robustness and accuracy of the output. The combination of SGI and DCL results in our Effective Controllable Network (ECNet), which offers a more accurate controllable end-to-end text-to-image generation framework with a more precise conditioning input and stronger controllable supervision. We validate our approach through extensive experiments on generation under various conditions, such as human body skeletons, facial landmarks, and sketches of general objects. The results consistently demonstrate that our method significantly enhances the controllability and robustness of the generated images, outperforming existing state-of-the-art controllable text-to-image models.
FriendNet: Detection-Friendly Dehazing Network
Mar 07, 2024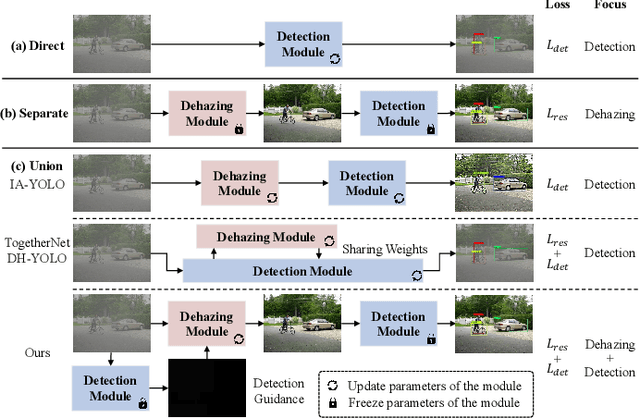
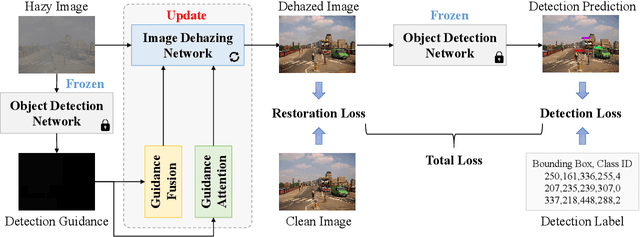
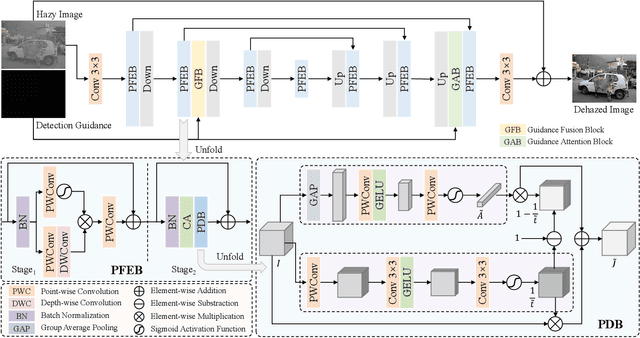
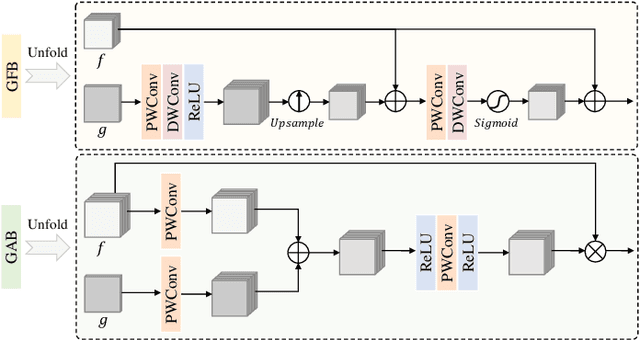
Adverse weather conditions often impair the quality of captured images, inevitably inducing cutting-edge object detection models for advanced driver assistance systems (ADAS) and autonomous driving. In this paper, we raise an intriguing question: can the combination of image restoration and object detection enhance detection performance in adverse weather conditions? To answer it, we propose an effective architecture that bridges image dehazing and object detection together via guidance information and task-driven learning to achieve detection-friendly dehazing, termed FriendNet. FriendNet aims to deliver both high-quality perception and high detection capacity. Different from existing efforts that intuitively treat image dehazing as pre-processing, FriendNet establishes a positive correlation between these two tasks. Clean features generated by the dehazing network potentially contribute to improvements in object detection performance. Conversely, object detection crucially guides the learning process of the image dehazing network under the task-driven learning scheme. We shed light on how downstream tasks can guide upstream dehazing processes, considering both network architecture and learning objectives. We design Guidance Fusion Block (GFB) and Guidance Attention Block (GAB) to facilitate the integration of detection information into the network. Furthermore, the incorporation of the detection task loss aids in refining the optimization process. Additionally, we introduce a new Physics-aware Feature Enhancement Block (PFEB), which integrates physics-based priors to enhance the feature extraction and representation capabilities. Extensive experiments on synthetic and real-world datasets demonstrate the superiority of our method over state-of-the-art methods on both image quality and detection precision. Our source code is available at https://github.com/fanyihua0309/FriendNet.
2D Matryoshka Sentence Embeddings
Feb 22, 2024Common approaches rely on fixed-length embedding vectors from language models as sentence embeddings for downstream tasks such as semantic textual similarity (STS). Such methods are limited in their flexibility due to unknown computational constraints and budgets across various applications. Matryoshka Representation Learning (MRL) (Kusupati et al., 2022) encodes information at finer granularities, i.e., with lower embedding dimensions, to adaptively accommodate ad hoc tasks. Similar accuracy can be achieved with a smaller embedding size, leading to speedups in downstream tasks. Despite its improved efficiency, MRL still requires traversing all Transformer layers before obtaining the embedding, which remains the dominant factor in time and memory consumption. This prompts consideration of whether the fixed number of Transformer layers affects representation quality and whether using intermediate layers for sentence representation is feasible. In this paper, we introduce a novel sentence embedding model called Two-dimensional Matryoshka Sentence Embedding (2DMSE). It supports elastic settings for both embedding sizes and Transformer layers, offering greater flexibility and efficiency than MRL. We conduct extensive experiments on STS tasks and downstream applications. The experimental results demonstrate the effectiveness of our proposed model in dynamically supporting different embedding sizes and Transformer layers, allowing it to be highly adaptable to various scenarios.
Towards Causal Classification: A Comprehensive Study on Graph Neural Networks
Jan 27, 2024The exploration of Graph Neural Networks (GNNs) for processing graph-structured data has expanded, particularly their potential for causal analysis due to their universal approximation capabilities. Anticipated to significantly enhance common graph-based tasks such as classification and prediction, the development of a causally enhanced GNN framework is yet to be thoroughly investigated. Addressing this shortfall, our study delves into nine benchmark graph classification models, testing their strength and versatility across seven datasets spanning three varied domains to discern the impact of causality on the predictive prowess of GNNs. This research offers a detailed assessment of these models, shedding light on their efficiency, and flexibility in different data environments, and highlighting areas needing advancement. Our findings are instrumental in furthering the understanding and practical application of GNNs in diverse datacentric fields
Cross Initialization for Personalized Text-to-Image Generation
Dec 26, 2023Recently, there has been a surge in face personalization techniques, benefiting from the advanced capabilities of pretrained text-to-image diffusion models. Among these, a notable method is Textual Inversion, which generates personalized images by inverting given images into textual embeddings. However, methods based on Textual Inversion still struggle with balancing the trade-off between reconstruction quality and editability. In this study, we examine this issue through the lens of initialization. Upon closely examining traditional initialization methods, we identified a significant disparity between the initial and learned embeddings in terms of both scale and orientation. The scale of the learned embedding can be up to 100 times greater than that of the initial embedding. Such a significant change in the embedding could increase the risk of overfitting, thereby compromising the editability. Driven by this observation, we introduce a novel initialization method, termed Cross Initialization, that significantly narrows the gap between the initial and learned embeddings. This method not only improves both reconstruction and editability but also reduces the optimization steps from 5000 to 320. Furthermore, we apply a regularization term to keep the learned embedding close to the initial embedding. We show that when combined with Cross Initialization, this regularization term can effectively improve editability. We provide comprehensive empirical evidence to demonstrate the superior performance of our method compared to the baseline methods. Notably, in our experiments, Cross Initialization is the only method that successfully edits an individual's facial expression. Additionally, a fast version of our method allows for capturing an input image in roughly 26 seconds, while surpassing the baseline methods in terms of both reconstruction and editability. Code will be made publicly available.
Parameter-Efficient Fine-Tuning Methods for Pretrained Language Models: A Critical Review and Assessment
Dec 19, 2023With the continuous growth in the number of parameters of transformer-based pretrained language models (PLMs), particularly the emergence of large language models (LLMs) with billions of parameters, many natural language processing (NLP) tasks have demonstrated remarkable success. However, the enormous size and computational demands of these models pose significant challenges for adapting them to specific downstream tasks, especially in environments with limited computational resources. Parameter Efficient Fine-Tuning (PEFT) offers an effective solution by reducing the number of fine-tuning parameters and memory usage while achieving comparable performance to full fine-tuning. The demands for fine-tuning PLMs, especially LLMs, have led to a surge in the development of PEFT methods, as depicted in Fig. 1. In this paper, we present a comprehensive and systematic review of PEFT methods for PLMs. We summarize these PEFT methods, discuss their applications, and outline future directions. Furthermore, we conduct experiments using several representative PEFT methods to better understand their effectiveness in parameter efficiency and memory efficiency. By offering insights into the latest advancements and practical applications, this survey serves as an invaluable resource for researchers and practitioners seeking to navigate the challenges and opportunities presented by PEFT in the context of PLMs.