 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXiaohui Tao
DE-CGAN: Boosting rTMS Treatment Prediction with Diversity Enhancing Conditional Generative Adversarial Networks
Apr 25, 2024
Repetitive Transcranial Magnetic Stimulation (rTMS) is a well-supported, evidence-based treatment for depression. However, patterns of response to this treatment are inconsistent. Emerging evidence suggests that artificial intelligence can predict rTMS treatment outcomes for most patients using fMRI connectivity features. While these models can reliably predict treatment outcomes for many patients for some underrepresented fMRI connectivity measures DNN models are unable to reliably predict treatment outcomes. As such we propose a novel method, Diversity Enhancing Conditional General Adversarial Network (DE-CGAN) for oversampling these underrepresented examples. DE-CGAN creates synthetic examples in difficult-to-classify regions by first identifying these data points and then creating conditioned synthetic examples to enhance data diversity. Through empirical experiments we show that a classification model trained using a diversity enhanced training set outperforms traditional data augmentation techniques and existing benchmark results. This work shows that increasing the diversity of a training dataset can improve classification model performance. Furthermore, this work provides evidence for the utility of synthetic patients providing larger more robust datasets for both AI researchers and psychiatrists to explore variable relationships.
CrimeAlarm: Towards Intensive Intent Dynamics in Fine-grained Crime Prediction
Apr 10, 2024Granularity and accuracy are two crucial factors for crime event prediction. Within fine-grained event classification, multiple criminal intents may alternately exhibit in preceding sequential events, and progress differently in next. Such intensive intent dynamics makes training models hard to capture unobserved intents, and thus leads to sub-optimal generalization performance, especially in the intertwining of numerous potential events. To capture comprehensive criminal intents, this paper proposes a fine-grained sequential crime prediction framework, CrimeAlarm, that equips with a novel mutual distillation strategy inspired by curriculum learning. During the early training phase, spot-shared criminal intents are captured through high-confidence sequence samples. In the later phase, spot-specific intents are gradually learned by increasing the contribution of low-confidence sequences. Meanwhile, the output probability distributions are reciprocally learned between prediction networks to model unobserved criminal intents. Extensive experiments show that CrimeAlarm outperforms state-of-the-art methods in terms of NDCG@5, with improvements of 4.51% for the NYC16 and 7.73% for the CHI18 in accuracy measures.
MealRec$^+$: A Meal Recommendation Dataset with Meal-Course Affiliation for Personalization and Healthiness
Apr 08, 2024Meal recommendation, as a typical health-related recommendation task, contains complex relationships between users, courses, and meals. Among them, meal-course affiliation associates user-meal and user-course interactions. However, an extensive literature review demonstrates that there is a lack of publicly available meal recommendation datasets including meal-course affiliation. Meal recommendation research has been constrained in exploring the impact of cooperation between two levels of interaction on personalization and healthiness. To pave the way for meal recommendation research, we introduce a new benchmark dataset called MealRec$^+$. Due to constraints related to user health privacy and meal scenario characteristics, the collection of data that includes both meal-course affiliation and two levels of interactions is impeded. Therefore, a simulation method is adopted to derive meal-course affiliation and user-meal interaction from the user's dining sessions simulated based on user-course interaction data. Then, two well-known nutritional standards are used to calculate the healthiness scores of meals. Moreover, we experiment with several baseline models, including separate and cooperative interaction learning methods. Our experiment demonstrates that cooperating the two levels of interaction in appropriate ways is beneficial for meal recommendations. Furthermore, in response to the less healthy recommendation phenomenon found in the experiment, we explore methods to enhance the healthiness of meal recommendations. The dataset is available on GitHub (https://github.com/WUT-IDEA/MealRecPlus).
Primary and Secondary Factor Consistency as Domain Knowledge to Guide Happiness Computing in Online Assessment
Feb 17, 2024Happiness computing based on large-scale online web data and machine learning methods is an emerging research topic that underpins a range of issues, from personal growth to social stability. Many advanced Machine Learning (ML) models with explanations are used to compute the happiness online assessment while maintaining high accuracy of results. However, domain knowledge constraints, such as the primary and secondary relations of happiness factors, are absent from these models, which limits the association between computing results and the right reasons for why they occurred. This article attempts to provide new insights into the explanation consistency from an empirical study perspective. Then we study how to represent and introduce domain knowledge constraints to make ML models more trustworthy. We achieve this through: (1) proving that multiple prediction models with additive factor attributions will have the desirable property of primary and secondary relations consistency, and (2) showing that factor relations with quantity can be represented as an importance distribution for encoding domain knowledge. Factor explanation difference is penalized by the Kullback-Leibler divergence-based loss among computing models. Experimental results using two online web datasets show that domain knowledge of stable factor relations exists. Using this knowledge not only improves happiness computing accuracy but also reveals more significative happiness factors for assisting decisions well.
Towards Causal Classification: A Comprehensive Study on Graph Neural Networks
Jan 27, 2024The exploration of Graph Neural Networks (GNNs) for processing graph-structured data has expanded, particularly their potential for causal analysis due to their universal approximation capabilities. Anticipated to significantly enhance common graph-based tasks such as classification and prediction, the development of a causally enhanced GNN framework is yet to be thoroughly investigated. Addressing this shortfall, our study delves into nine benchmark graph classification models, testing their strength and versatility across seven datasets spanning three varied domains to discern the impact of causality on the predictive prowess of GNNs. This research offers a detailed assessment of these models, shedding light on their efficiency, and flexibility in different data environments, and highlighting areas needing advancement. Our findings are instrumental in furthering the understanding and practical application of GNNs in diverse datacentric fields
Persona-centric Metamorphic Relation guided Robustness Evaluation for Multi-turn Dialogue Modelling
Jan 23, 2024Recently there has been significant progress in the field of dialogue system thanks to the introduction of training paradigms such as fine-tune and prompt learning. Persona can function as the prior knowledge for maintaining the personality consistency of dialogue systems, which makes it perform well on accuracy. Nonetheless, the conventional reference-based evaluation method falls short in capturing the genuine text comprehension prowess of the model, significantly relying on the quality of data annotation. In contrast, the application of metamorphic testing offers a more profound insight into the model's distinct capabilities without necessitating supplementary annotation labels. This approach furnishes a more comprehensive portrayal of the model's intricacies and exposes intricacies concealed within reference-based validation techniques. Consequently, we introduce a persona-centric metamorphic relation construction for metamorphic testing, aimed at evaluating both the persona consistency and robustness of personalized dialogue models. For that reason, this work evaluates several widely used training paradigms including learning from scratch, pretrain + fine-tune and prompt learning in personalized dialogue retrieval to know if they are more robust or if they have the same flaws as their predecessor. Under three kinds of designed metamorphic relations with consistent outputs, our experimental results reveal that prompt learning shows stronger robustness compared to training from scratch and fine-tune. Although tested retrieval models gain competitively high retrieval accuracy according to the traditional reference-based validation, they are still fragile and demonstrate various unexpected behaviors, thus there is still room for future improvement in personalized dialogue retrieval.
Parameter-Efficient Fine-Tuning Methods for Pretrained Language Models: A Critical Review and Assessment
Dec 19, 2023With the continuous growth in the number of parameters of transformer-based pretrained language models (PLMs), particularly the emergence of large language models (LLMs) with billions of parameters, many natural language processing (NLP) tasks have demonstrated remarkable success. However, the enormous size and computational demands of these models pose significant challenges for adapting them to specific downstream tasks, especially in environments with limited computational resources. Parameter Efficient Fine-Tuning (PEFT) offers an effective solution by reducing the number of fine-tuning parameters and memory usage while achieving comparable performance to full fine-tuning. The demands for fine-tuning PLMs, especially LLMs, have led to a surge in the development of PEFT methods, as depicted in Fig. 1. In this paper, we present a comprehensive and systematic review of PEFT methods for PLMs. We summarize these PEFT methods, discuss their applications, and outline future directions. Furthermore, we conduct experiments using several representative PEFT methods to better understand their effectiveness in parameter efficiency and memory efficiency. By offering insights into the latest advancements and practical applications, this survey serves as an invaluable resource for researchers and practitioners seeking to navigate the challenges and opportunities presented by PEFT in the context of PLMs.
Exploring Causal Learning through Graph Neural Networks: An In-depth Review
Nov 25, 2023In machine learning, exploring data correlations to predict outcomes is a fundamental task. Recognizing causal relationships embedded within data is pivotal for a comprehensive understanding of system dynamics, the significance of which is paramount in data-driven decision-making processes. Beyond traditional methods, there has been a surge in the use of graph neural networks (GNNs) for causal learning, given their capabilities as universal data approximators. Thus, a thorough review of the advancements in causal learning using GNNs is both relevant and timely. To structure this review, we introduce a novel taxonomy that encompasses various state-of-the-art GNN methods employed in studying causality. GNNs are further categorized based on their applications in the causality domain. We further provide an exhaustive compilation of datasets integral to causal learning with GNNs to serve as a resource for practical study. This review also touches upon the application of causal learning across diverse sectors. We conclude the review with insights into potential challenges and promising avenues for future exploration in this rapidly evolving field of machine learning.
AI-Driven Patient Monitoring with Multi-Agent Deep Reinforcement Learning
Sep 24, 2023


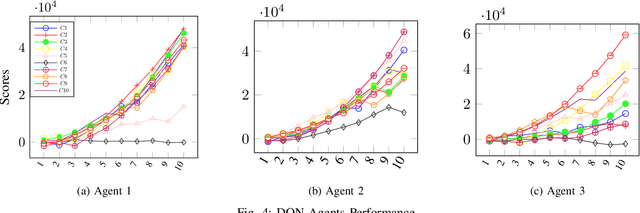
Effective patient monitoring is vital for timely interventions and improved healthcare outcomes. Traditional monitoring systems often struggle to handle complex, dynamic environments with fluctuating vital signs, leading to delays in identifying critical conditions. To address this challenge, we propose a novel AI-driven patient monitoring framework using multi-agent deep reinforcement learning (DRL). Our approach deploys multiple learning agents, each dedicated to monitoring a specific physiological feature, such as heart rate, respiration, and temperature. These agents interact with a generic healthcare monitoring environment, learn the patients' behavior patterns, and make informed decisions to alert the corresponding Medical Emergency Teams (METs) based on the level of emergency estimated. In this study, we evaluate the performance of the proposed multi-agent DRL framework using real-world physiological and motion data from two datasets: PPG-DaLiA and WESAD. We compare the results with several baseline models, including Q-Learning, PPO, Actor-Critic, Double DQN, and DDPG, as well as monitoring frameworks like WISEML and CA-MAQL. Our experiments demonstrate that the proposed DRL approach outperforms all other baseline models, achieving more accurate monitoring of patient's vital signs. Furthermore, we conduct hyperparameter optimization to fine-tune the learning process of each agent. By optimizing hyperparameters, we enhance the learning rate and discount factor, thereby improving the agents' overall performance in monitoring patient health status. Our AI-driven patient monitoring system offers several advantages over traditional methods, including the ability to handle complex and uncertain environments, adapt to varying patient conditions, and make real-time decisions without external supervision.
FRAMU: Attention-based Machine Unlearning using Federated Reinforcement Learning
Sep 24, 2023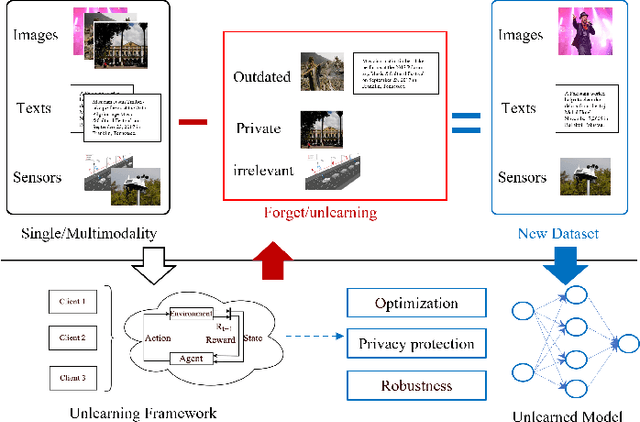
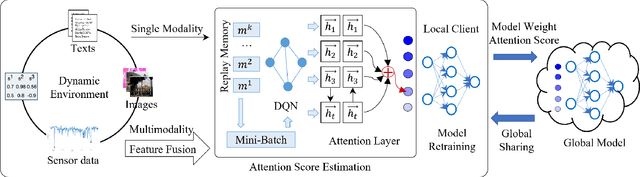
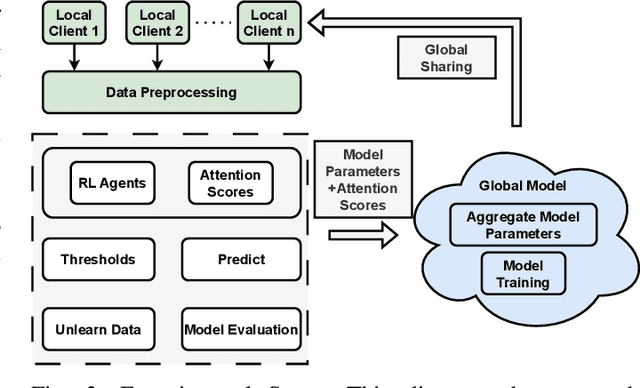
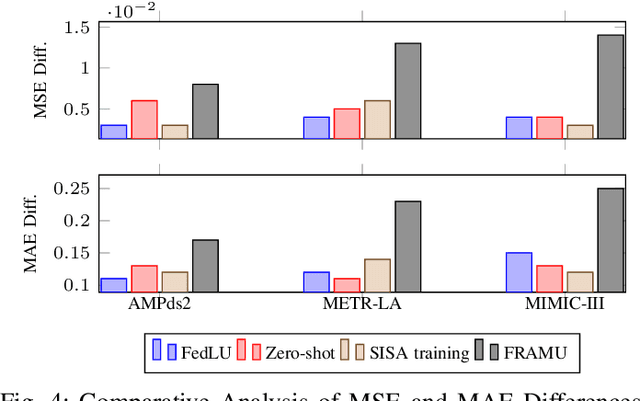
Machine Unlearning is an emerging field that addresses data privacy issues by enabling the removal of private or irrelevant data from the Machine Learning process. Challenges related to privacy and model efficiency arise from the use of outdated, private, and irrelevant data. These issues compromise both the accuracy and the computational efficiency of models in both Machine Learning and Unlearning. To mitigate these challenges, we introduce a novel framework, Attention-based Machine Unlearning using Federated Reinforcement Learning (FRAMU). This framework incorporates adaptive learning mechanisms, privacy preservation techniques, and optimization strategies, making it a well-rounded solution for handling various data sources, either single-modality or multi-modality, while maintaining accuracy and privacy. FRAMU's strength lies in its adaptability to fluctuating data landscapes, its ability to unlearn outdated, private, or irrelevant data, and its support for continual model evolution without compromising privacy. Our experiments, conducted on both single-modality and multi-modality datasets, revealed that FRAMU significantly outperformed baseline models. Additional assessments of convergence behavior and optimization strategies further validate the framework's utility in federated learning applications. Overall, FRAMU advances Machine Unlearning by offering a robust, privacy-preserving solution that optimizes model performance while also addressing key challenges in dynamic data environments.