 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXudong Mao
Cross Initialization for Personalized Text-to-Image Generation
Dec 26, 2023
Recently, there has been a surge in face personalization techniques, benefiting from the advanced capabilities of pretrained text-to-image diffusion models. Among these, a notable method is Textual Inversion, which generates personalized images by inverting given images into textual embeddings. However, methods based on Textual Inversion still struggle with balancing the trade-off between reconstruction quality and editability. In this study, we examine this issue through the lens of initialization. Upon closely examining traditional initialization methods, we identified a significant disparity between the initial and learned embeddings in terms of both scale and orientation. The scale of the learned embedding can be up to 100 times greater than that of the initial embedding. Such a significant change in the embedding could increase the risk of overfitting, thereby compromising the editability. Driven by this observation, we introduce a novel initialization method, termed Cross Initialization, that significantly narrows the gap between the initial and learned embeddings. This method not only improves both reconstruction and editability but also reduces the optimization steps from 5000 to 320. Furthermore, we apply a regularization term to keep the learned embedding close to the initial embedding. We show that when combined with Cross Initialization, this regularization term can effectively improve editability. We provide comprehensive empirical evidence to demonstrate the superior performance of our method compared to the baseline methods. Notably, in our experiments, Cross Initialization is the only method that successfully edits an individual's facial expression. Additionally, a fast version of our method allows for capturing an input image in roughly 26 seconds, while surpassing the baseline methods in terms of both reconstruction and editability. Code will be made publicly available.
Cycle Encoding of a StyleGAN Encoder for Improved Reconstruction and Editability
Jul 19, 2022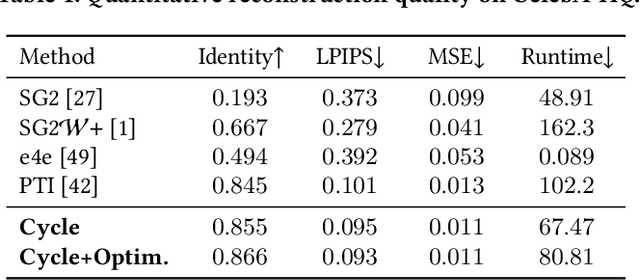
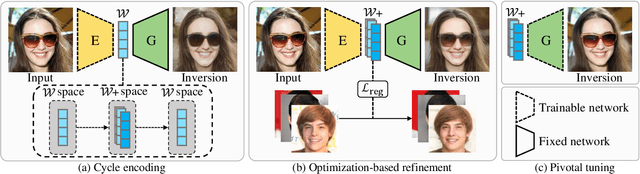
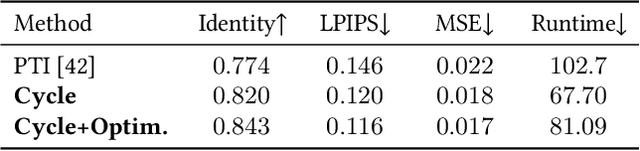
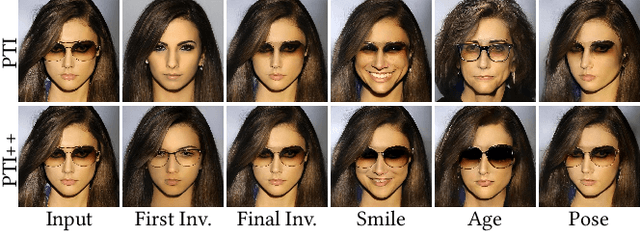
GAN inversion aims to invert an input image into the latent space of a pre-trained GAN. Despite the recent advances in GAN inversion, there remain challenges to mitigate the tradeoff between distortion and editability, i.e. reconstructing the input image accurately and editing the inverted image with a small visual quality drop. The recently proposed pivotal tuning model makes significant progress towards reconstruction and editability, by using a two-step approach that first inverts the input image into a latent code, called pivot code, and then alters the generator so that the input image can be accurately mapped into the pivot code. Here, we show that both reconstruction and editability can be improved by a proper design of the pivot code. We present a simple yet effective method, named cycle encoding, for a high-quality pivot code. The key idea of our method is to progressively train an encoder in varying spaces according to a cycle scheme: W->W+->W. This training methodology preserves the properties of both W and W+ spaces, i.e. high editability of W and low distortion of W+. To further decrease the distortion, we also propose to refine the pivot code with an optimization-based method, where a regularization term is introduced to reduce the degradation in editability. Qualitative and quantitative comparisons to several state-of-the-art methods demonstrate the superiority of our approach.
Revisiting Discriminator in GAN Compression: A Generator-discriminator Cooperative Compression Scheme
Nov 09, 2021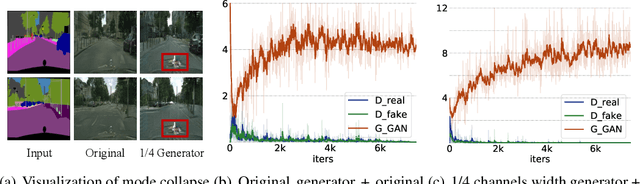
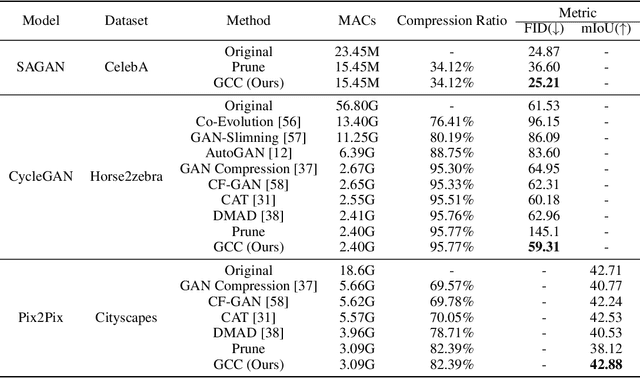


Recently, a series of algorithms have been explored for GAN compression, which aims to reduce tremendous computational overhead and memory usages when deploying GANs on resource-constrained edge devices. However, most of the existing GAN compression work only focuses on how to compress the generator, while fails to take the discriminator into account. In this work, we revisit the role of discriminator in GAN compression and design a novel generator-discriminator cooperative compression scheme for GAN compression, termed GCC. Within GCC, a selective activation discriminator automatically selects and activates convolutional channels according to a local capacity constraint and a global coordination constraint, which help maintain the Nash equilibrium with the lightweight generator during the adversarial training and avoid mode collapse. The original generator and discriminator are also optimized from scratch, to play as a teacher model to progressively refine the pruned generator and the selective activation discriminator. A novel online collaborative distillation scheme is designed to take full advantage of the intermediate feature of the teacher generator and discriminator to further boost the performance of the lightweight generator. Extensive experiments on various GAN-based generation tasks demonstrate the effectiveness and generalization of GCC. Among them, GCC contributes to reducing 80% computational costs while maintains comparable performance in image translation tasks. Our code and models are available at https://github.com/SJLeo/GCC.
The ByteDance Speaker Diarization System for the VoxCeleb Speaker Recognition Challenge 2021
Sep 05, 2021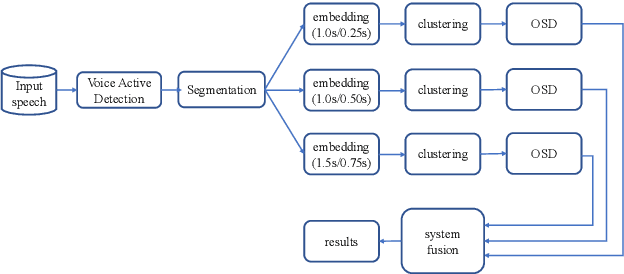

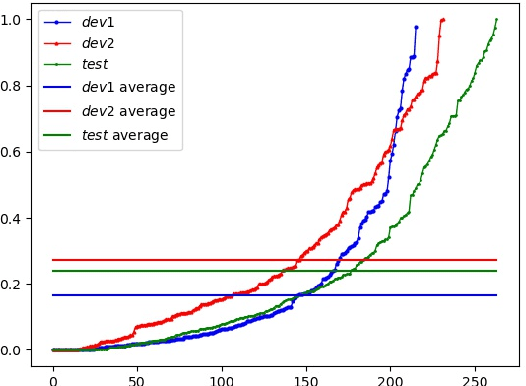
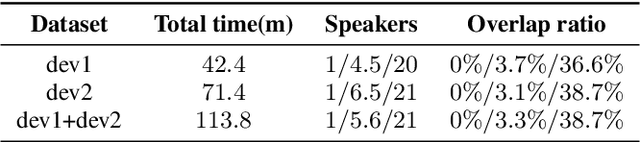
This paper describes the ByteDance speaker diarization system for the fourth track of the VoxCeleb Speaker Recognition Challenge 2021 (VoxSRC-21). The VoxSRC-21 provides both the dev set and test set of VoxConverse for use in validation and a standalone test set for evaluation. We first collect the duration and signal-to-noise ratio (SNR) of all audio and find that the distribution of the VoxConverse's test set and the VoxSRC-21's test set is more closer. Our system consists of voice active detection (VAD), speaker embedding extraction, spectral clustering followed by a re-clustering step based on agglomerative hierarchical clustering (AHC) and overlapped speech detection and handling. Finally, we integrate systems with different time scales using DOVER-Lap. Our best system achieves 5.15\% of the diarization error rate (DER) on evaluation set, ranking the second at the diarization track of the challenge.
Image-to-image Translation via Hierarchical Style Disentanglement
Mar 02, 2021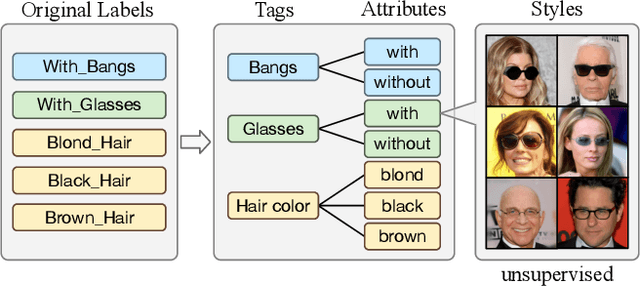


Recently, image-to-image translation has made significant progress in achieving both multi-label (\ie, translation conditioned on different labels) and multi-style (\ie, generation with diverse styles) tasks. However, due to the unexplored independence and exclusiveness in the labels, existing endeavors are defeated by involving uncontrolled manipulations to the translation results. In this paper, we propose Hierarchical Style Disentanglement (HiSD) to address this issue. Specifically, we organize the labels into a hierarchical tree structure, in which independent tags, exclusive attributes, and disentangled styles are allocated from top to bottom. Correspondingly, a new translation process is designed to adapt the above structure, in which the styles are identified for controllable translations. Both qualitative and quantitative results on the CelebA-HQ dataset verify the ability of the proposed HiSD. We hope our method will serve as a solid baseline and provide fresh insights with the hierarchically organized annotations for future research in image-to-image translation. The code has been released at https://github.com/imlixinyang/HiSD.
Virtual Mixup Training for Unsupervised Domain Adaptation
May 24, 2019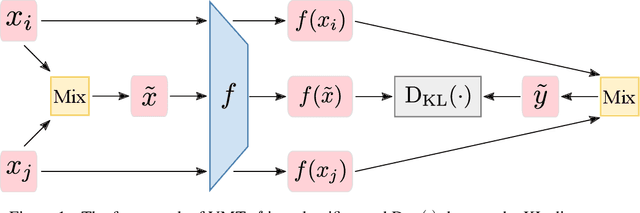
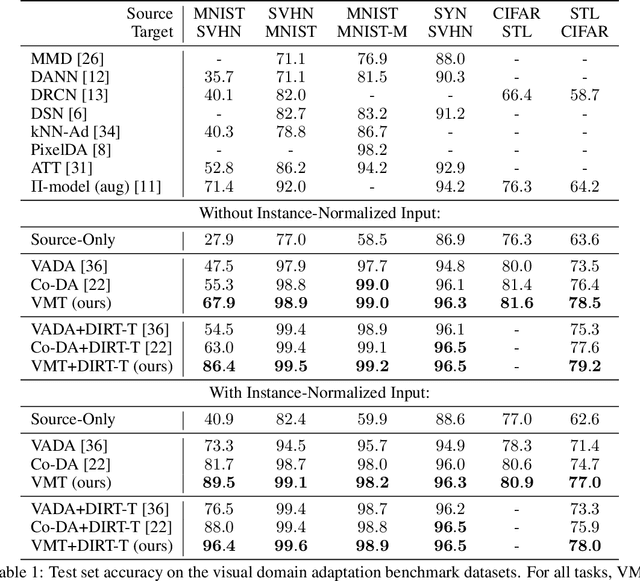
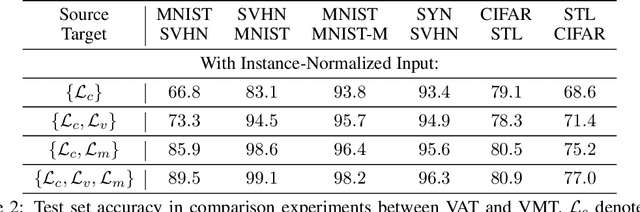

We study the problem of unsupervised domain adaptation which aims to adapt models trained on a labeled source domain to a completely unlabeled target domain. Domain adversarial training is a promising approach and has been a basis for many state-of-the-art models in unsupervised domain adaptation. The idea of domain adversarial training is to align the feature space between the source and target domains by adversarially training a domain classifier and a feature encoder. Recently, cluster assumption has been applied to unsupervised domain adaptation and achieved strong performance. In this paper, we propose a new regularization method called Virtual Mixup Training (VMT), which is able to further constrain the hypothesis of cluster assumption. The idea of VMT is to impose a locally-Lipschitz constraint on the model by smoothing the output distribution along the lines between pairs of training samples. Unlike the traditional mixup model, our method constructs the combination samples without using the label information, allowing it to be applicable to unsupervised domain adaptation. The proposed method is generic and can be combined with existing methods using domain adversarial training. We combine VMT with a recent state-of-the-art model called VADA, and extensive experiments demonstrate that VMT significantly improves the performance of VADA on several domain adaptation benchmark datasets. For the challenging task of adapting MNIST to SVHN, when not using instance normalization, VMT improves the accuracy of VADA by over 30%. When using instance normalization, our model achieves an accuracy of 96.4%, which is very close to the accuracy (96.5%) of the train-on-target model. Code will be made publicly available.
On the Effectiveness of Least Squares Generative Adversarial Networks
Sep 21, 2018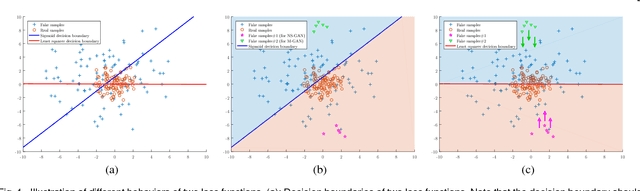
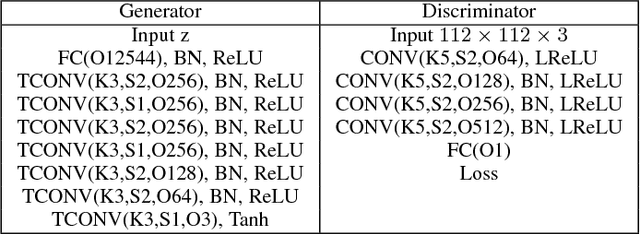
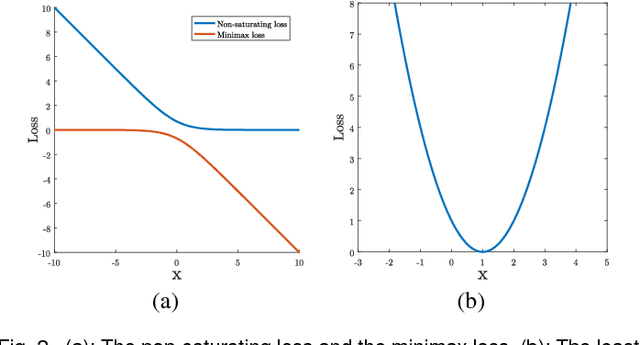
Unsupervised learning with generative adversarial networks (GANs) has proven to be hugely successful. Regular GANs hypothesize the discriminator as a classifier with the sigmoid cross entropy loss function. However, we found that this loss function may lead to the vanishing gradients problem during the learning process. To overcome such a problem, we propose in this paper the Least Squares Generative Adversarial Networks (LSGANs) which adopt the least squares loss for both the discriminator and the generator. We show that minimizing the objective function of LSGAN yields minimizing the Pearson $\chi^2$ divergence. We also show that the derived objective function that yields minimizing the Pearson $\chi^2$ divergence performs better than the classical one of using least squares for classification. There are two benefits of LSGANs over regular GANs. First, LSGANs are able to generate higher quality images than regular GANs. Second, LSGANs perform more stably during the learning process. For evaluating the image quality, we conduct both qualitative and quantitative experiments, and the experimental results show that LSGANs can generate higher quality images than regular GANs. Furthermore, we evaluate the stability of LSGANs in two groups. One is to compare between LSGANs and regular GANs without gradient penalty. We conduct three experiments, including Gaussian mixture distribution, difficult architectures, and a newly proposed method --- datasets with small variability, to illustrate the stability of LSGANs. The other one is to compare between LSGANs with gradient penalty (LSGANs-GP) and WGANs with gradient penalty (WGANs-GP). The experimental results show that LSGANs-GP succeed in training for all the difficult architectures used in WGANs-GP, including 101-layer ResNet.
Unpaired Multi-Domain Image Generation via Regularized Conditional GANs
May 07, 2018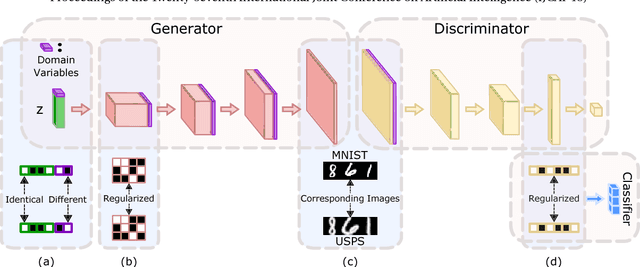
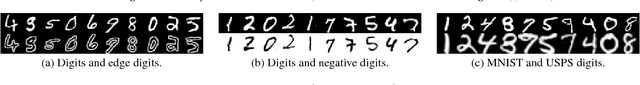
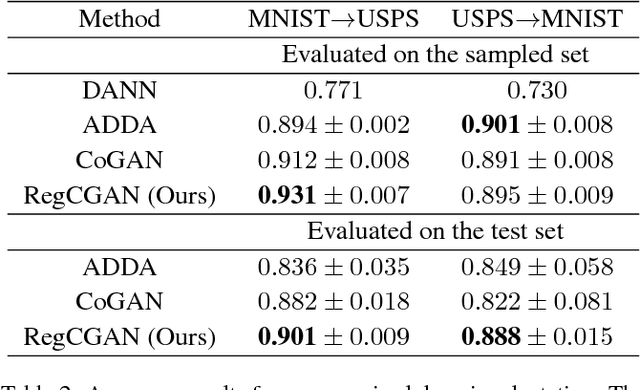

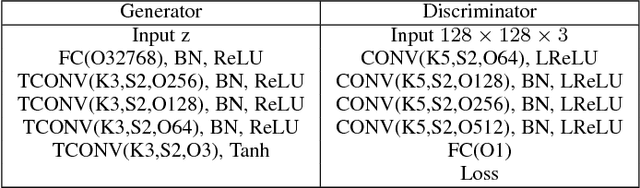
In this paper, we study the problem of multi-domain image generation, the goal of which is to generate pairs of corresponding images from different domains. With the recent development in generative models, image generation has achieved great progress and has been applied to various computer vision tasks. However, multi-domain image generation may not achieve the desired performance due to the difficulty of learning the correspondence of different domain images, especially when the information of paired samples is not given. To tackle this problem, we propose Regularized Conditional GAN (RegCGAN) which is capable of learning to generate corresponding images in the absence of paired training data. RegCGAN is based on the conditional GAN, and we introduce two regularizers to guide the model to learn the corresponding semantics of different domains. We evaluate the proposed model on several tasks for which paired training data is not given, including the generation of edges and photos, the generation of faces with different attributes, etc. The experimental results show that our model can successfully generate corresponding images for all these tasks, while outperforms the baseline methods. We also introduce an approach of applying RegCGAN to unsupervised domain adaptation.
AlignGAN: Learning to Align Cross-Domain Images with Conditional Generative Adversarial Networks
Jul 05, 2017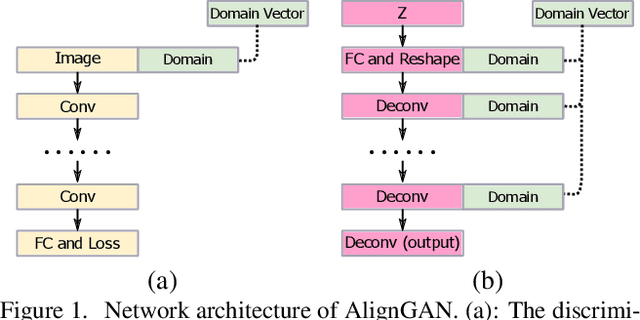
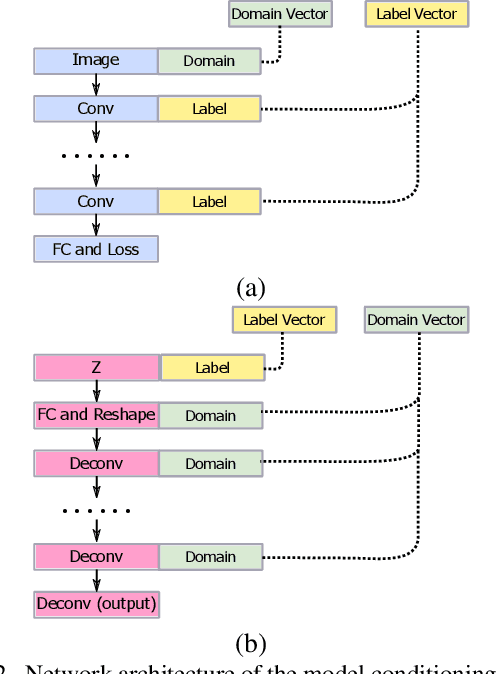


Recently, several methods based on generative adversarial network (GAN) have been proposed for the task of aligning cross-domain images or learning a joint distribution of cross-domain images. One of the methods is to use conditional GAN for alignment. However, previous attempts of adopting conditional GAN do not perform as well as other methods. In this work we present an approach for improving the capability of the methods which are based on conditional GAN. We evaluate the proposed method on numerous tasks and the experimental results show that it is able to align the cross-domain images successfully in absence of paired samples. Furthermore, we also propose another model which conditions on multiple information such as domain information and label information. Conditioning on domain information and label information, we are able to conduct label propagation from the source domain to the target domain. A 2-step alternating training algorithm is proposed to learn this model.
Least Squares Generative Adversarial Networks
Apr 05, 2017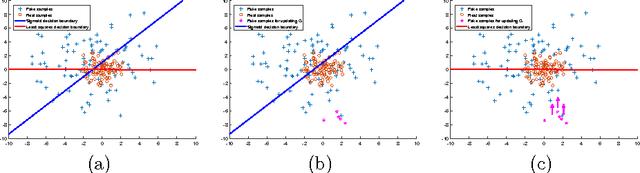
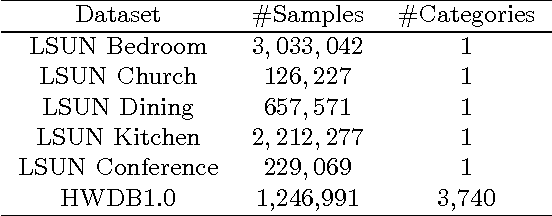
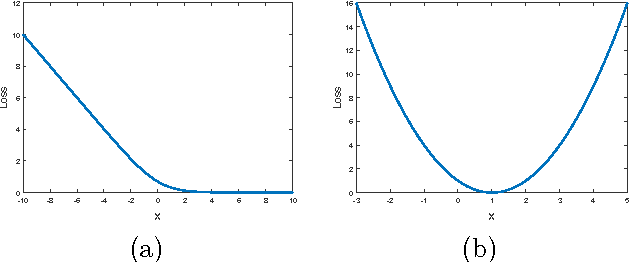

Unsupervised learning with generative adversarial networks (GANs) has proven hugely successful. Regular GANs hypothesize the discriminator as a classifier with the sigmoid cross entropy loss function. However, we found that this loss function may lead to the vanishing gradients problem during the learning process. To overcome such a problem, we propose in this paper the Least Squares Generative Adversarial Networks (LSGANs) which adopt the least squares loss function for the discriminator. We show that minimizing the objective function of LSGAN yields minimizing the Pearson $\chi^2$ divergence. There are two benefits of LSGANs over regular GANs. First, LSGANs are able to generate higher quality images than regular GANs. Second, LSGANs perform more stable during the learning process. We evaluate LSGANs on five scene datasets and the experimental results show that the images generated by LSGANs are of better quality than the ones generated by regular GANs. We also conduct two comparison experiments between LSGANs and regular GANs to illustrate the stability of LSGANs.