 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZhixin Lai
InsectMamba: Insect Pest Classification with State Space Model
Apr 04, 2024
The classification of insect pests is a critical task in agricultural technology, vital for ensuring food security and environmental sustainability. However, the complexity of pest identification, due to factors like high camouflage and species diversity, poses significant obstacles. Existing methods struggle with the fine-grained feature extraction needed to distinguish between closely related pest species. Although recent advancements have utilized modified network structures and combined deep learning approaches to improve accuracy, challenges persist due to the similarity between pests and their surroundings. To address this problem, we introduce InsectMamba, a novel approach that integrates State Space Models (SSMs), Convolutional Neural Networks (CNNs), Multi-Head Self-Attention mechanism (MSA), and Multilayer Perceptrons (MLPs) within Mix-SSM blocks. This integration facilitates the extraction of comprehensive visual features by leveraging the strengths of each encoding strategy. A selective module is also proposed to adaptively aggregate these features, enhancing the model's ability to discern pest characteristics. InsectMamba was evaluated against strong competitors across five insect pest classification datasets. The results demonstrate its superior performance and verify the significance of each model component by an ablation study.
The New Agronomists: Language Models are Experts in Crop Management
Mar 28, 2024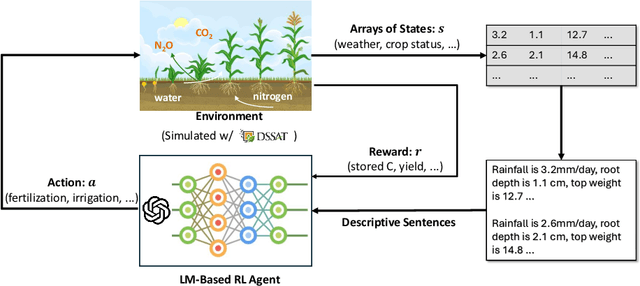
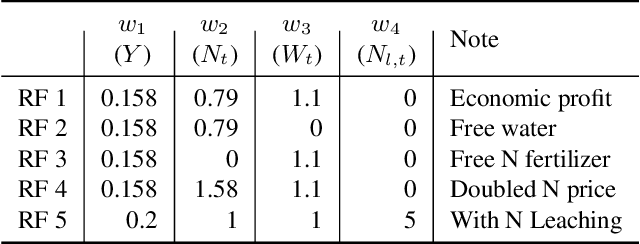
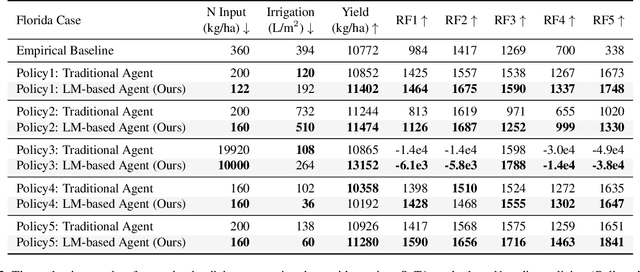
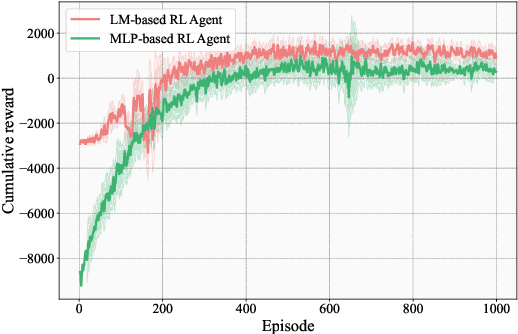
Crop management plays a crucial role in determining crop yield, economic profitability, and environmental sustainability. Despite the availability of management guidelines, optimizing these practices remains a complex and multifaceted challenge. In response, previous studies have explored using reinforcement learning with crop simulators, typically employing simple neural-network-based reinforcement learning (RL) agents. Building on this foundation, this paper introduces a more advanced intelligent crop management system. This system uniquely combines RL, a language model (LM), and crop simulations facilitated by the Decision Support System for Agrotechnology Transfer (DSSAT). We utilize deep RL, specifically a deep Q-network, to train management policies that process numerous state variables from the simulator as observations. A novel aspect of our approach is the conversion of these state variables into more informative language, facilitating the language model's capacity to understand states and explore optimal management practices. The empirical results reveal that the LM exhibits superior learning capabilities. Through simulation experiments with maize crops in Florida (US) and Zaragoza (Spain), the LM not only achieves state-of-the-art performance under various evaluation metrics but also demonstrates a remarkable improvement of over 49\% in economic profit, coupled with reduced environmental impact when compared to baseline methods. Our code is available at \url{https://github.com/jingwu6/LM_AG}.
Residual-based Language Models are Free Boosters for Biomedical Imaging
Mar 28, 2024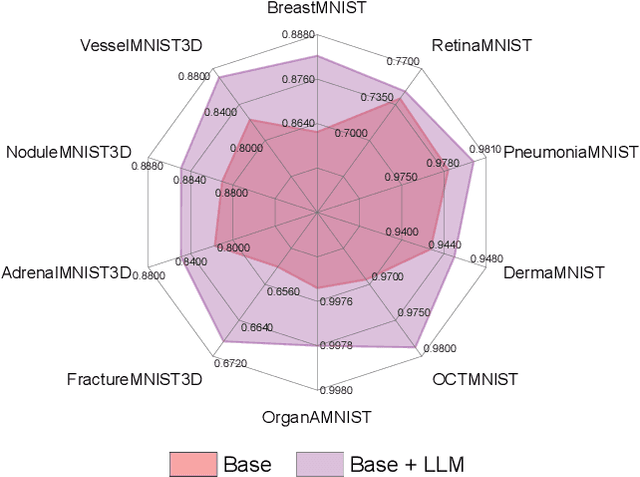

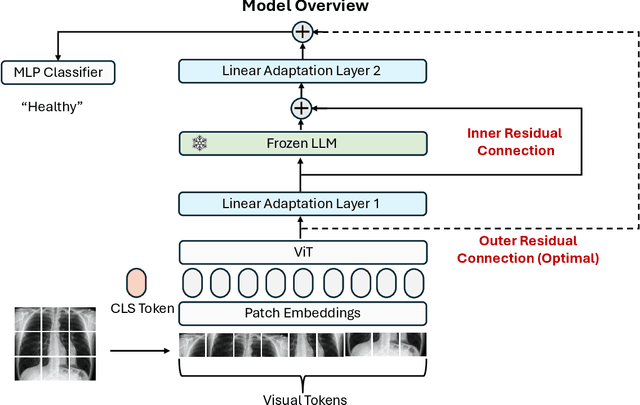

In this study, we uncover the unexpected efficacy of residual-based large language models (LLMs) as part of encoders for biomedical imaging tasks, a domain traditionally devoid of language or textual data. The approach diverges from established methodologies by utilizing a frozen transformer block, extracted from pre-trained LLMs, as an innovative encoder layer for the direct processing of visual tokens. This strategy represents a significant departure from the standard multi-modal vision-language frameworks, which typically hinge on language-driven prompts and inputs. We found that these LLMs could boost performance across a spectrum of biomedical imaging applications, including both 2D and 3D visual classification tasks, serving as plug-and-play boosters. More interestingly, as a byproduct, we found that the proposed framework achieved superior performance, setting new state-of-the-art results on extensive, standardized datasets in MedMNIST-2D and 3D. Through this work, we aim to open new avenues for employing LLMs in biomedical imaging and enriching the understanding of their potential in this specialized domain.
ECNet: Effective Controllable Text-to-Image Diffusion Models
Mar 27, 2024
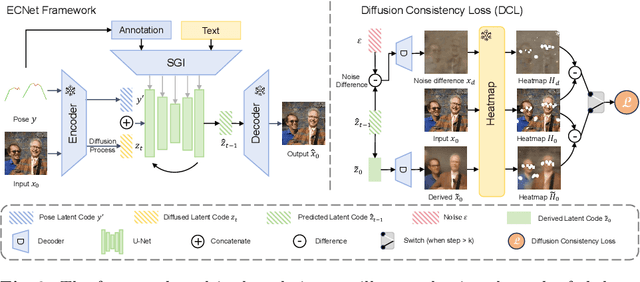
The conditional text-to-image diffusion models have garnered significant attention in recent years. However, the precision of these models is often compromised mainly for two reasons, ambiguous condition input and inadequate condition guidance over single denoising loss. To address the challenges, we introduce two innovative solutions. Firstly, we propose a Spatial Guidance Injector (SGI) which enhances conditional detail by encoding text inputs with precise annotation information. This method directly tackles the issue of ambiguous control inputs by providing clear, annotated guidance to the model. Secondly, to overcome the issue of limited conditional supervision, we introduce Diffusion Consistency Loss (DCL), which applies supervision on the denoised latent code at any given time step. This encourages consistency between the latent code at each time step and the input signal, thereby enhancing the robustness and accuracy of the output. The combination of SGI and DCL results in our Effective Controllable Network (ECNet), which offers a more accurate controllable end-to-end text-to-image generation framework with a more precise conditioning input and stronger controllable supervision. We validate our approach through extensive experiments on generation under various conditions, such as human body skeletons, facial landmarks, and sketches of general objects. The results consistently demonstrate that our method significantly enhances the controllability and robustness of the generated images, outperforming existing state-of-the-art controllable text-to-image models.
Adaptive Ensembles of Fine-Tuned Transformers for LLM-Generated Text Detection
Mar 20, 2024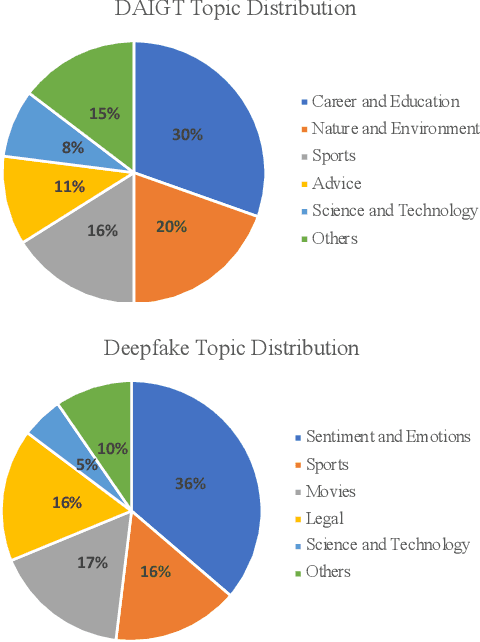
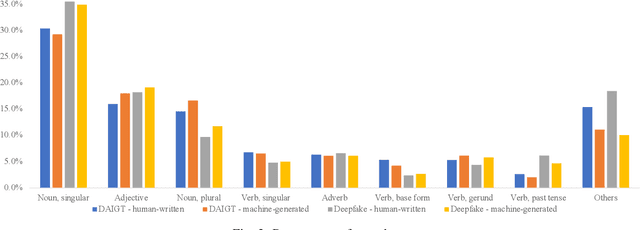

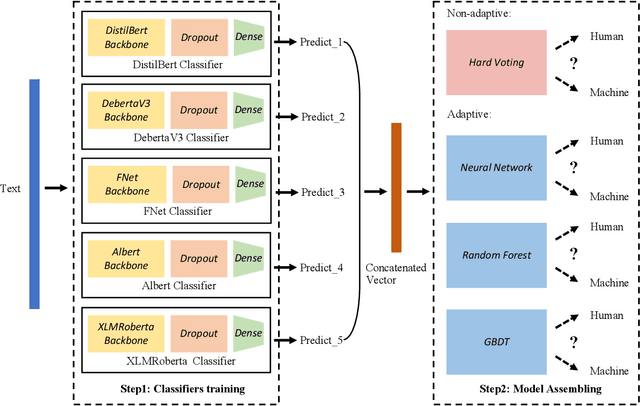
Large language models (LLMs) have reached human-like proficiency in generating diverse textual content, underscoring the necessity for effective fake text detection to avoid potential risks such as fake news in social media. Previous research has mostly tested single models on in-distribution datasets, limiting our understanding of how these models perform on different types of data for LLM-generated text detection task. We researched this by testing five specialized transformer-based models on both in-distribution and out-of-distribution datasets to better assess their performance and generalizability. Our results revealed that single transformer-based classifiers achieved decent performance on in-distribution dataset but limited generalization ability on out-of-distribution dataset. To improve it, we combined the individual classifiers models using adaptive ensemble algorithms, which improved the average accuracy significantly from 91.8% to 99.2% on an in-distribution test set and from 62.9% to 72.5% on an out-of-distribution test set. The results indicate the effectiveness, good generalization ability, and great potential of adaptive ensemble algorithms in LLM-generated text detection.