 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJunbo Chen
HVOFusion: Incremental Mesh Reconstruction Using Hybrid Voxel Octree
Apr 27, 2024
Incremental scene reconstruction is essential to the navigation in robotics. Most of the conventional methods typically make use of either TSDF (truncated signed distance functions) volume or neural networks to implicitly represent the surface. Due to the voxel representation or involving with time-consuming sampling, they have difficulty in balancing speed, memory storage, and surface quality. In this paper, we propose a novel hybrid voxel-octree approach to effectively fuse octree with voxel structures so that we can take advantage of both implicit surface and explicit triangular mesh representation. Such sparse structure preserves triangular faces in the leaf nodes and produces partial meshes sequentially for incremental reconstruction. This storage scheme allows us to naturally optimize the mesh in explicit 3D space to achieve higher surface quality. We iteratively deform the mesh towards the target and recovers vertex colors by optimizing a shading model. Experimental results on several datasets show that our proposed approach is capable of quickly and accurately reconstructing a scene with realistic colors.
Not All Voxels Are Equal: Hardness-Aware Semantic Scene Completion with Self-Distillation
Apr 18, 2024Semantic scene completion, also known as semantic occupancy prediction, can provide dense geometric and semantic information for autonomous vehicles, which attracts the increasing attention of both academia and industry. Unfortunately, existing methods usually formulate this task as a voxel-wise classification problem and treat each voxel equally in 3D space during training. As the hard voxels have not been paid enough attention, the performance in some challenging regions is limited. The 3D dense space typically contains a large number of empty voxels, which are easy to learn but require amounts of computation due to handling all the voxels uniformly for the existing models. Furthermore, the voxels in the boundary region are more challenging to differentiate than those in the interior. In this paper, we propose HASSC approach to train the semantic scene completion model with hardness-aware design. The global hardness from the network optimization process is defined for dynamical hard voxel selection. Then, the local hardness with geometric anisotropy is adopted for voxel-wise refinement. Besides, self-distillation strategy is introduced to make training process stable and consistent. Extensive experiments show that our HASSC scheme can effectively promote the accuracy of the baseline model without incurring the extra inference cost. Source code is available at: https://github.com/songw-zju/HASSC.
MGMap: Mask-Guided Learning for Online Vectorized HD Map Construction
Apr 01, 2024



Currently, high-definition (HD) map construction leans towards a lightweight online generation tendency, which aims to preserve timely and reliable road scene information. However, map elements contain strong shape priors. Subtle and sparse annotations make current detection-based frameworks ambiguous in locating relevant feature scopes and cause the loss of detailed structures in prediction. To alleviate these problems, we propose MGMap, a mask-guided approach that effectively highlights the informative regions and achieves precise map element localization by introducing the learned masks. Specifically, MGMap employs learned masks based on the enhanced multi-scale BEV features from two perspectives. At the instance level, we propose the Mask-activated instance (MAI) decoder, which incorporates global instance and structural information into instance queries by the activation of instance masks. At the point level, a novel position-guided mask patch refinement (PG-MPR) module is designed to refine point locations from a finer-grained perspective, enabling the extraction of point-specific patch information. Compared to the baselines, our proposed MGMap achieves a notable improvement of around 10 mAP for different input modalities. Extensive experiments also demonstrate that our approach showcases strong robustness and generalization capabilities. Our code can be found at https://github.com/xiaolul2/MGMap.
LVIC: Multi-modality segmentation by Lifting Visual Info as Cue
Mar 08, 2024


Multi-modality fusion is proven an effective method for 3d perception for autonomous driving. However, most current multi-modality fusion pipelines for LiDAR semantic segmentation have complicated fusion mechanisms. Point painting is a quite straight forward method which directly bind LiDAR points with visual information. Unfortunately, previous point painting like methods suffer from projection error between camera and LiDAR. In our experiments, we find that this projection error is the devil in point painting. As a result of that, we propose a depth aware point painting mechanism, which significantly boosts the multi-modality fusion. Apart from that, we take a deeper look at the desired visual feature for LiDAR to operate semantic segmentation. By Lifting Visual Information as Cue, LVIC ranks 1st on nuScenes LiDAR semantic segmentation benchmark. Our experiments show the robustness and effectiveness. Codes would be make publicly available soon.
PeP: a Point enhanced Painting method for unified point cloud tasks
Oct 11, 2023


Point encoder is of vital importance for point cloud recognition. As the very beginning step of whole model pipeline, adding features from diverse sources and providing stronger feature encoding mechanism would provide better input for downstream modules. In our work, we proposed a novel PeP module to tackle above issue. PeP contains two main parts, a refined point painting method and a LM-based point encoder. Experiments results on the nuScenes and KITTI datasets validate the superior performance of our PeP. The advantages leads to strong performance on both semantic segmentation and object detection, in both lidar and multi-modal settings. Notably, our PeP module is model agnostic and plug-and-play. Our code will be publicly available soon.
HuBo-VLM: Unified Vision-Language Model designed for HUman roBOt interaction tasks
Aug 24, 2023


Human robot interaction is an exciting task, which aimed to guide robots following instructions from human. Since huge gap lies between human natural language and machine codes, end to end human robot interaction models is fair challenging. Further, visual information receiving from sensors of robot is also a hard language for robot to perceive. In this work, HuBo-VLM is proposed to tackle perception tasks associated with human robot interaction including object detection and visual grounding by a unified transformer based vision language model. Extensive experiments on the Talk2Car benchmark demonstrate the effectiveness of our approach. Code would be publicly available in https://github.com/dzcgaara/HuBo-VLM.
FusionAD: Multi-modality Fusion for Prediction and Planning Tasks of Autonomous Driving
Aug 14, 2023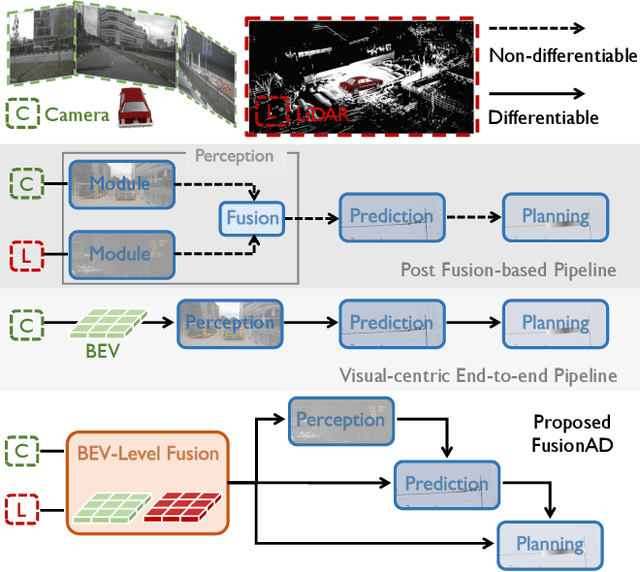
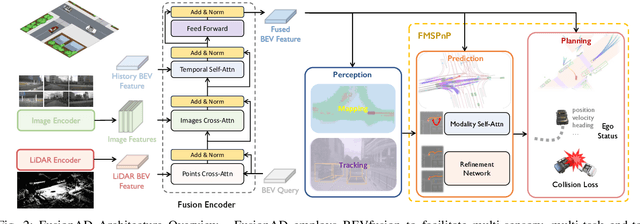
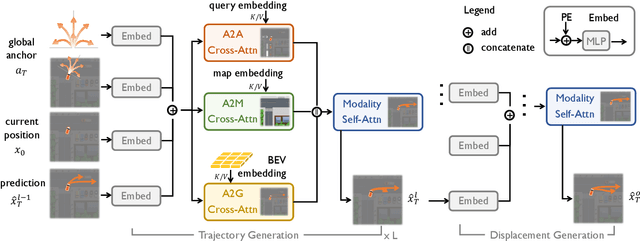
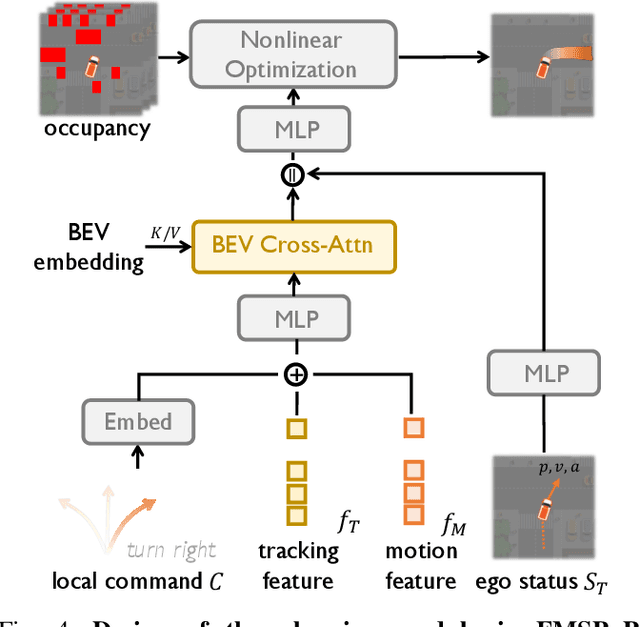
Building a multi-modality multi-task neural network toward accurate and robust performance is a de-facto standard in perception task of autonomous driving. However, leveraging such data from multiple sensors to jointly optimize the prediction and planning tasks remains largely unexplored. In this paper, we present FusionAD, to the best of our knowledge, the first unified framework that fuse the information from two most critical sensors, camera and LiDAR, goes beyond perception task. Concretely, we first build a transformer based multi-modality fusion network to effectively produce fusion based features. In constrast to camera-based end-to-end method UniAD, we then establish a fusion aided modality-aware prediction and status-aware planning modules, dubbed FMSPnP that take advantages of multi-modality features. We conduct extensive experiments on commonly used benchmark nuScenes dataset, our FusionAD achieves state-of-the-art performance and surpassing baselines on average 15% on perception tasks like detection and tracking, 10% on occupancy prediction accuracy, reducing prediction error from 0.708 to 0.389 in ADE score and reduces the collision rate from 0.31% to only 0.12%.
OG: Equip vision occupancy with instance segmentation and visual grounding
Jul 12, 2023

Occupancy prediction tasks focus on the inference of both geometry and semantic labels for each voxel, which is an important perception mission. However, it is still a semantic segmentation task without distinguishing various instances. Further, although some existing works, such as Open-Vocabulary Occupancy (OVO), have already solved the problem of open vocabulary detection, visual grounding in occupancy has not been solved to the best of our knowledge. To tackle the above two limitations, this paper proposes Occupancy Grounding (OG), a novel method that equips vanilla occupancy instance segmentation ability and could operate visual grounding in a voxel manner with the help of grounded-SAM. Keys to our approach are (1) affinity field prediction for instance clustering and (2) association strategy for aligning 2D instance masks and 3D occupancy instances. Extensive experiments have been conducted whose visualization results and analysis are shown below. Our code will be publicly released soon.
CCIL: Context-conditioned imitation learning for urban driving
May 04, 2023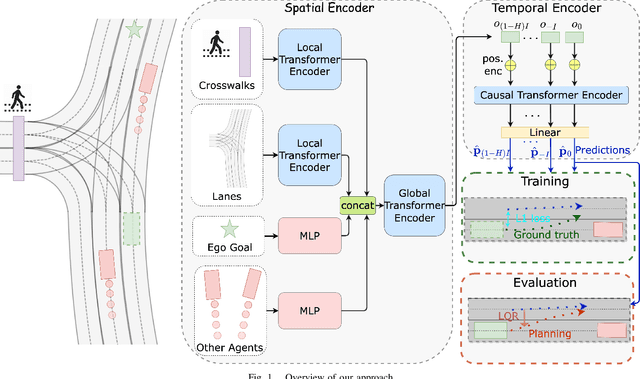
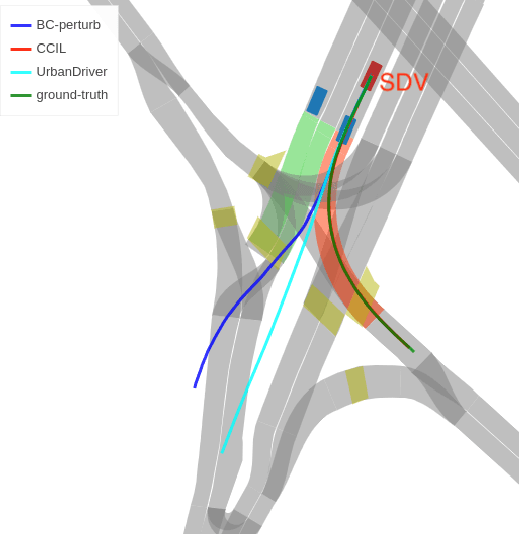
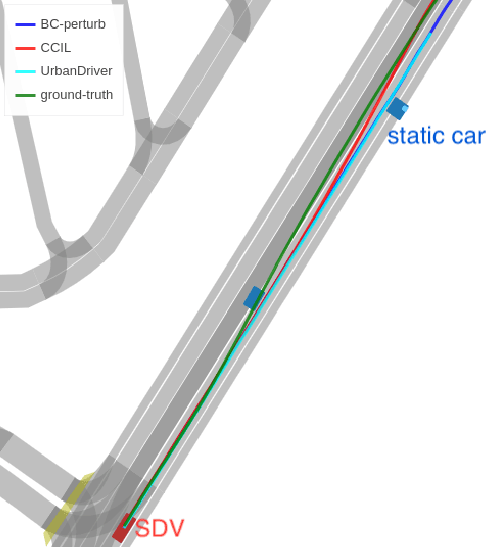

Imitation learning holds great promise for addressing the complex task of autonomous urban driving, as experienced human drivers can navigate highly challenging scenarios with ease. While behavior cloning is a widely used imitation learning approach in autonomous driving due to its exemption from risky online interactions, it suffers from the covariate shift issue. To address this limitation, we propose a context-conditioned imitation learning approach that employs a policy to map the context state into the ego vehicle's future trajectory, rather than relying on the traditional formulation of both ego and context states to predict the ego action. Additionally, to reduce the implicit ego information in the coordinate system, we design an ego-perturbed goal-oriented coordinate system. The origin of this coordinate system is the ego vehicle's position plus a zero mean Gaussian perturbation, and the x-axis direction points towards its goal position. Our experiments on the real-world large-scale Lyft and nuPlan datasets show that our method significantly outperforms state-of-the-art approaches.
Zero-shot Transfer Learning of Driving Policy via Socially Adversarial Traffic Flow
Apr 25, 2023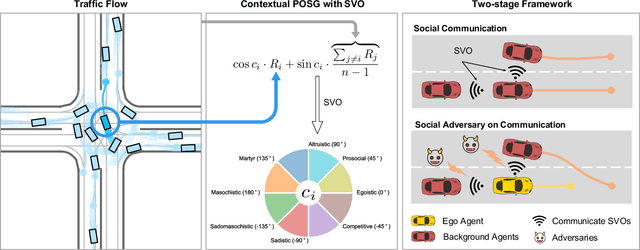
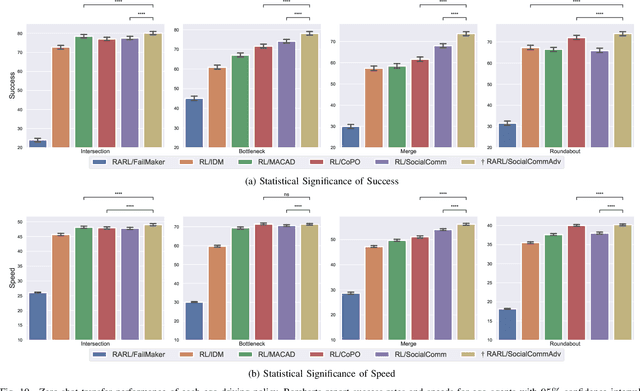
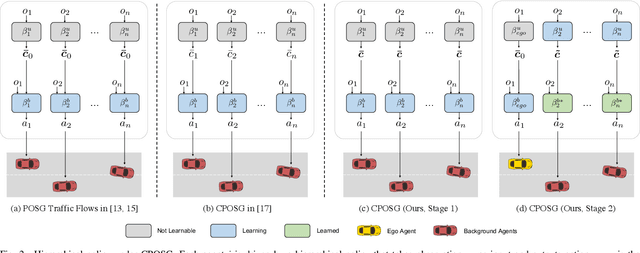
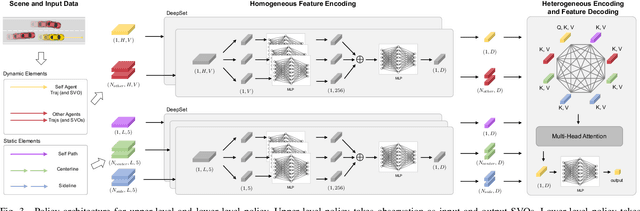
Acquiring driving policies that can transfer to unseen environments is challenging when driving in dense traffic flows. The design of traffic flow is essential and previous studies are unable to balance interaction and safety-criticism. To tackle this problem, we propose a socially adversarial traffic flow. We propose a Contextual Partially-Observable Stochastic Game to model traffic flow and assign Social Value Orientation (SVO) as context. We then adopt a two-stage framework. In Stage 1, each agent in our socially-aware traffic flow is driven by a hierarchical policy where upper-level policy communicates genuine SVOs of all agents, which the lower-level policy takes as input. In Stage 2, each agent in the socially adversarial traffic flow is driven by the hierarchical policy where upper-level communicates mistaken SVOs, taken by the lower-level policy trained in Stage 1. Driving policy is adversarially trained through a zero-sum game formulation with upper-level policies, resulting in a policy with enhanced zero-shot transfer capability to unseen traffic flows. Comprehensive experiments on cross-validation verify the superior zero-shot transfer performance of our method.