 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLiang Xu
SuperCLUE-Fin: Graded Fine-Grained Analysis of Chinese LLMs on Diverse Financial Tasks and Applications
Apr 29, 2024
The SuperCLUE-Fin (SC-Fin) benchmark is a pioneering evaluation framework tailored for Chinese-native financial large language models (FLMs). It assesses FLMs across six financial application domains and twenty-five specialized tasks, encompassing theoretical knowledge and practical applications such as compliance, risk management, and investment analysis. Using multi-turn, open-ended conversations that mimic real-life scenarios, SC-Fin measures models on a range of criteria, including accurate financial understanding, logical reasoning, clarity, computational efficiency, business acumen, risk perception, and compliance with Chinese regulations. In a rigorous evaluation involving over a thousand questions, SC-Fin identifies a performance hierarchy where domestic models like GLM-4 and MoonShot-v1-128k outperform others with an A-grade, highlighting the potential for further development in transforming theoretical knowledge into pragmatic financial solutions. This benchmark serves as a critical tool for refining FLMs in the Chinese context, directing improvements in financial knowledge databases, standardizing financial interpretations, and promoting models that prioritize compliance, risk management, and secure practices. We create a contextually relevant and comprehensive benchmark that drives the development of AI in the Chinese financial sector. SC-Fin facilitates the advancement and responsible deployment of FLMs, offering valuable insights for enhancing model performance and usability for both individual and institutional users in the Chinese market..~\footnote{Our benchmark can be found at \url{https://www.CLUEbenchmarks.com}}.
On-chip Real-time Hyperspectral Imager with Full CMOS Resolution Enabled by Massively Parallel Neural Network
Apr 15, 2024Traditional spectral imaging methods are constrained by the time-consuming scanning process, limiting the application in dynamic scenarios. One-shot spectral imaging based on reconstruction has been a hot research topic recently and the primary challenges still lie in both efficient fabrication techniques suitable for mass production and the high-speed, high-accuracy reconstruction algorithm for real-time spectral imaging. In this study, we introduce an innovative on-chip real-time hyperspectral imager that leverages nanophotonic film spectral encoders and a Massively Parallel Network (MP-Net), featuring a 4 * 4 array of compact, all-dielectric film units for the micro-spectrometers. Each curved nanophotonic film unit uniquely modulates incident light across the underlying 3 * 3 CMOS image sensor (CIS) pixels, enabling a high spatial resolution equivalent to the full CMOS resolution. The implementation of MP-Net, specially designed to address variability in transmittance and manufacturing errors such as misalignment and non-uniformities in thin film deposition, can greatly increase the structural tolerance of the device and reduce the preparation requirement, further simplifying the manufacturing process. Tested in varied environments on both static and moving objects, the real-time hyperspectral imager demonstrates the robustness and high-fidelity spatial-spectral data capabilities across diverse scenarios. This on-chip hyperspectral imager represents a significant advancement in real-time, high-resolution spectral imaging, offering a versatile solution for applications ranging from environmental monitoring, remote sensing to consumer electronics.
ReGenNet: Towards Human Action-Reaction Synthesis
Mar 18, 2024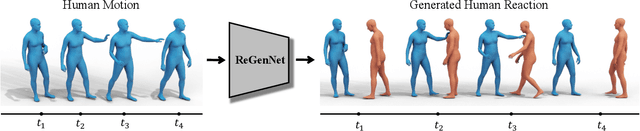
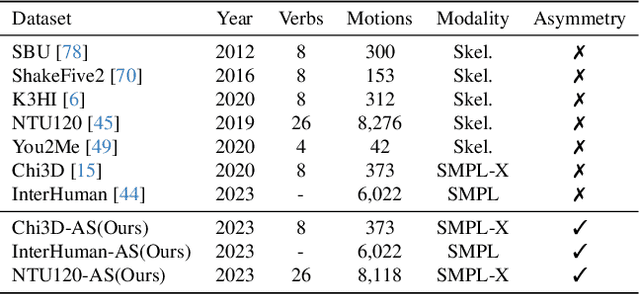

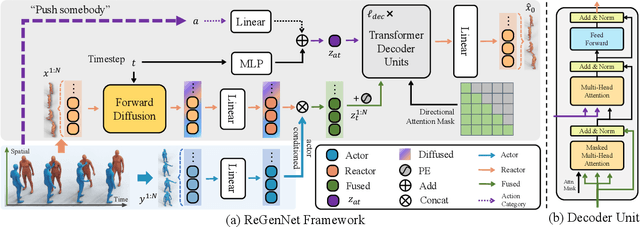
Humans constantly interact with their surrounding environments. Current human-centric generative models mainly focus on synthesizing humans plausibly interacting with static scenes and objects, while the dynamic human action-reaction synthesis for ubiquitous causal human-human interactions is less explored. Human-human interactions can be regarded as asymmetric with actors and reactors in atomic interaction periods. In this paper, we comprehensively analyze the asymmetric, dynamic, synchronous, and detailed nature of human-human interactions and propose the first multi-setting human action-reaction synthesis benchmark to generate human reactions conditioned on given human actions. To begin with, we propose to annotate the actor-reactor order of the interaction sequences for the NTU120, InterHuman, and Chi3D datasets. Based on them, a diffusion-based generative model with a Transformer decoder architecture called ReGenNet together with an explicit distance-based interaction loss is proposed to predict human reactions in an online manner, where the future states of actors are unavailable to reactors. Quantitative and qualitative results show that our method can generate instant and plausible human reactions compared to the baselines, and can generalize to unseen actor motions and viewpoint changes.
Incorporating Graph Attention Mechanism into Geometric Problem Solving Based on Deep Reinforcement Learning
Mar 14, 2024In the context of online education, designing an automatic solver for geometric problems has been considered a crucial step towards general math Artificial Intelligence (AI), empowered by natural language understanding and traditional logical inference. In most instances, problems are addressed by adding auxiliary components such as lines or points. However, adding auxiliary components automatically is challenging due to the complexity in selecting suitable auxiliary components especially when pivotal decisions have to be made. The state-of-the-art performance has been achieved by exhausting all possible strategies from the category library to identify the one with the maximum likelihood. However, an extensive strategy search have to be applied to trade accuracy for ef-ficiency. To add auxiliary components automatically and efficiently, we present deep reinforcement learning framework based on the language model, such as BERT. We firstly apply the graph attention mechanism to reduce the strategy searching space, called AttnStrategy, which only focus on the conclusion-related components. Meanwhile, a novel algorithm, named Automatically Adding Auxiliary Components using Reinforcement Learning framework (A3C-RL), is proposed by forcing an agent to select top strategies, which incorporates the AttnStrategy and BERT as the memory components. Results from extensive experiments show that the proposed A3C-RL algorithm can substantially enhance the average precision by 32.7% compared to the traditional MCTS. In addition, the A3C-RL algorithm outperforms humans on the geometric questions from the annual University Entrance Mathematical Examination of China.
Structured Deep Neural Networks-Based Backstepping Trajectory Tracking Control for Lagrangian Systems
Mar 01, 2024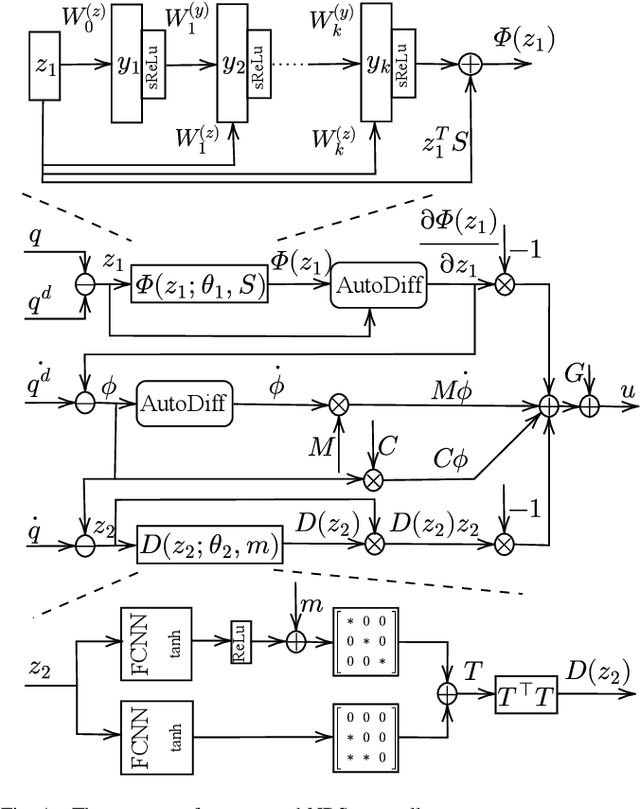
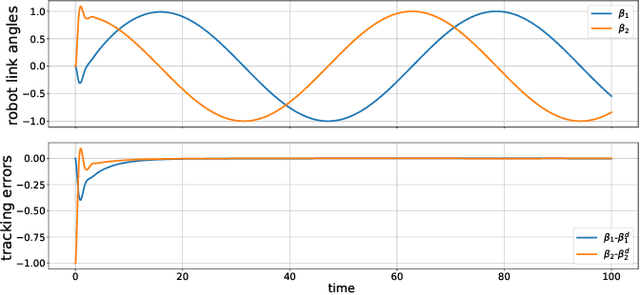
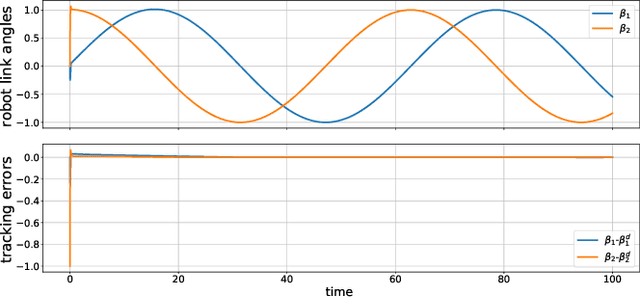
Deep neural networks (DNN) are increasingly being used to learn controllers due to their excellent approximation capabilities. However, their black-box nature poses significant challenges to closed-loop stability guarantees and performance analysis. In this paper, we introduce a structured DNN-based controller for the trajectory tracking control of Lagrangian systems using backing techniques. By properly designing neural network structures, the proposed controller can ensure closed-loop stability for any compatible neural network parameters. In addition, improved control performance can be achieved by further optimizing neural network parameters. Besides, we provide explicit upper bounds on tracking errors in terms of controller parameters, which allows us to achieve the desired tracking performance by properly selecting the controller parameters. Furthermore, when system models are unknown, we propose an improved Lagrangian neural network (LNN) structure to learn the system dynamics and design the controller. We show that in the presence of model approximation errors and external disturbances, the closed-loop stability and tracking control performance can still be guaranteed. The effectiveness of the proposed approach is demonstrated through simulations.
SuperCLUE-Math6: Graded Multi-Step Math Reasoning Benchmark for LLMs in Chinese
Feb 02, 2024We introduce SuperCLUE-Math6(SC-Math6), a new benchmark dataset to evaluate the mathematical reasoning abilities of Chinese language models. SC-Math6 is designed as an upgraded Chinese version of the GSM8K dataset with enhanced difficulty, diversity, and application scope. It consists of over 2000 mathematical word problems requiring multi-step reasoning and providing natural language solutions. We propose an innovative scheme to quantify the reasoning capability of large models based on performance over problems with different reasoning steps. Experiments on 13 representative Chinese models demonstrate a clear stratification of reasoning levels, with top models like GPT-4 showing superior performance. SC-Math6 fills the gap in Chinese mathematical reasoning benchmarks and provides a comprehensive testbed to advance the intelligence of Chinese language models.
Inter-X: Towards Versatile Human-Human Interaction Analysis
Dec 26, 2023The analysis of the ubiquitous human-human interactions is pivotal for understanding humans as social beings. Existing human-human interaction datasets typically suffer from inaccurate body motions, lack of hand gestures and fine-grained textual descriptions. To better perceive and generate human-human interactions, we propose Inter-X, a currently largest human-human interaction dataset with accurate body movements and diverse interaction patterns, together with detailed hand gestures. The dataset includes ~11K interaction sequences and more than 8.1M frames. We also equip Inter-X with versatile annotations of more than 34K fine-grained human part-level textual descriptions, semantic interaction categories, interaction order, and the relationship and personality of the subjects. Based on the elaborate annotations, we propose a unified benchmark composed of 4 categories of downstream tasks from both the perceptual and generative directions. Extensive experiments and comprehensive analysis show that Inter-X serves as a testbed for promoting the development of versatile human-human interaction analysis. Our dataset and benchmark will be publicly available for research purposes.
SC-Safety: A Multi-round Open-ended Question Adversarial Safety Benchmark for Large Language Models in Chinese
Oct 09, 2023Large language models (LLMs), like ChatGPT and GPT-4, have demonstrated remarkable abilities in natural language understanding and generation. However, alongside their positive impact on our daily tasks, they can also produce harmful content that negatively affects societal perceptions. To systematically assess the safety of Chinese LLMs, we introduce SuperCLUE-Safety (SC-Safety) - a multi-round adversarial benchmark with 4912 open-ended questions covering more than 20 safety sub-dimensions. Adversarial human-model interactions and conversations significantly increase the challenges compared to existing methods. Experiments on 13 major LLMs supporting Chinese yield the following insights: 1) Closed-source models outperform open-sourced ones in terms of safety; 2) Models released from China demonstrate comparable safety levels to LLMs like GPT-3.5-turbo; 3) Some smaller models with 6B-13B parameters can compete effectively in terms of safety. By introducing SC-Safety, we aim to promote collaborative efforts to create safer and more trustworthy LLMs. The benchmark and findings provide guidance on model selection. Our benchmark can be found at https://www.CLUEbenchmarks.com
Duration-adaptive Video Highlight Pre-caching for Vehicular Communication Network
Sep 05, 2023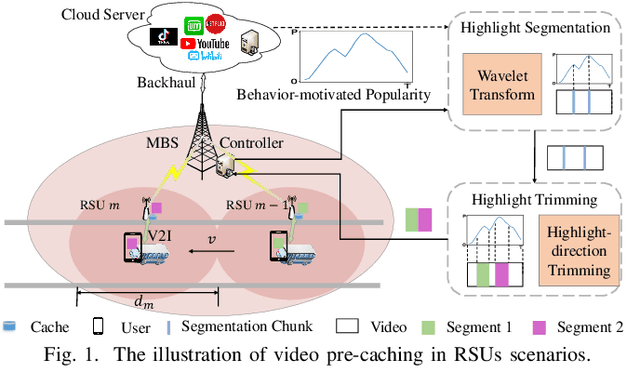
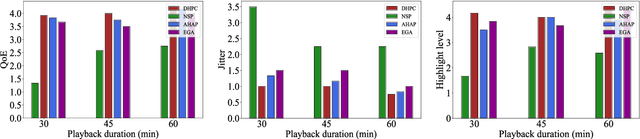
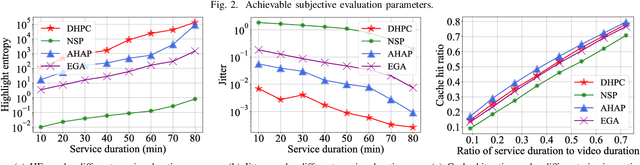
Video traffic in vehicular communication networks (VCNs) faces exponential growth. However, different segments of most videos reveal various attractiveness for viewers, and the pre-caching decision is greatly affected by the dynamic service duration that edge nodes can provide services for mobile vehicles driving along a road. In this paper, we propose an efficient video highlight pre-caching scheme in the vehicular communication network, adapting to the service duration. Specifically, a highlight entropy model is devised with the consideration of the segments' popularity and continuity between segments within a period of time, based on which, an optimization problem of video highlight pre-caching is formulated. As this problem is non-convex and lacks a closed-form expression of the objective function, we decouple multiple variables by deriving candidate highlight segmentations of videos through wavelet transform, which can significantly reduce the complexity of highlight pre-caching. Then the problem is solved iteratively by a highlight-direction trimming algorithm, which is proven to be locally optimal. Simulation results based on real-world video datasets demonstrate significant improvement in highlight entropy and jitter compared to benchmark schemes.
Federated Learning in Big Model Era: Domain-Specific Multimodal Large Models
Aug 24, 2023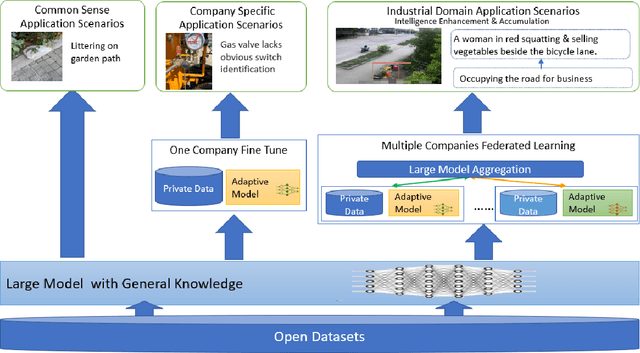


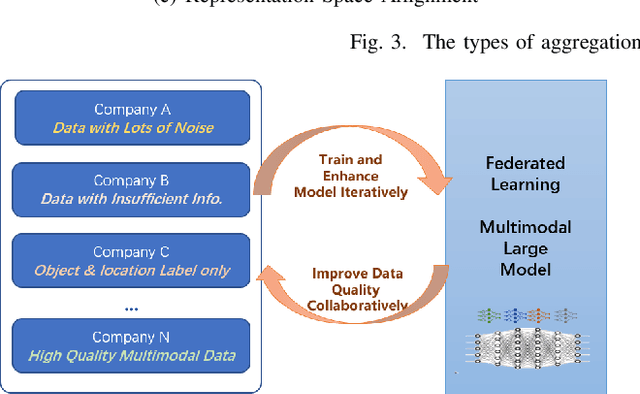
Multimodal data, which can comprehensively perceive and recognize the physical world, has become an essential path towards general artificial intelligence. However, multimodal large models trained on public datasets often underperform in specific industrial domains. This paper proposes a multimodal federated learning framework that enables multiple enterprises to utilize private domain data to collaboratively train large models for vertical domains, achieving intelligent services across scenarios. The authors discuss in-depth the strategic transformation of federated learning in terms of intelligence foundation and objectives in the era of big model, as well as the new challenges faced in heterogeneous data, model aggregation, performance and cost trade-off, data privacy, and incentive mechanism. The paper elaborates a case study of leading enterprises contributing multimodal data and expert knowledge to city safety operation management , including distributed deployment and efficient coordination of the federated learning platform, technical innovations on data quality improvement based on large model capabilities and efficient joint fine-tuning approaches. Preliminary experiments show that enterprises can enhance and accumulate intelligent capabilities through multimodal model federated learning, thereby jointly creating an smart city model that provides high-quality intelligent services covering energy infrastructure safety, residential community security, and urban operation management. The established federated learning cooperation ecosystem is expected to further aggregate industry, academia, and research resources, realize large models in multiple vertical domains, and promote the large-scale industrial application of artificial intelligence and cutting-edge research on multimodal federated learning.