 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYing Wang
On the Scalability of Diffusion-based Text-to-Image Generation
Apr 03, 2024
Scaling up model and data size has been quite successful for the evolution of LLMs. However, the scaling law for the diffusion based text-to-image (T2I) models is not fully explored. It is also unclear how to efficiently scale the model for better performance at reduced cost. The different training settings and expensive training cost make a fair model comparison extremely difficult. In this work, we empirically study the scaling properties of diffusion based T2I models by performing extensive and rigours ablations on scaling both denoising backbones and training set, including training scaled UNet and Transformer variants ranging from 0.4B to 4B parameters on datasets upto 600M images. For model scaling, we find the location and amount of cross attention distinguishes the performance of existing UNet designs. And increasing the transformer blocks is more parameter-efficient for improving text-image alignment than increasing channel numbers. We then identify an efficient UNet variant, which is 45% smaller and 28% faster than SDXL's UNet. On the data scaling side, we show the quality and diversity of the training set matters more than simply dataset size. Increasing caption density and diversity improves text-image alignment performance and the learning efficiency. Finally, we provide scaling functions to predict the text-image alignment performance as functions of the scale of model size, compute and dataset size.
Learning-Based Joint Beamforming and Antenna Movement Design for Movable Antenna Systems
Apr 02, 2024In this paper, we investigate a multi-receiver communication system enabled by movable antennas (MAs). Specifically, the transmit beamforming and the double-side antenna movement at the transceiver are jointly designed to maximize the sum-rate of all receivers under imperfect channel state information (CSI). Since the formulated problem is non-convex with highly coupled variables, conventional optimization methods cannot solve it efficiently. To address these challenges, an effective learning-based algorithm is proposed, namely heterogeneous multi-agent deep deterministic policy gradient (MADDPG), which incorporates two agents to learn policies for beamforming and movement of MAs, respectively. Based on the offline learning under numerous imperfect CSI, the proposed heterogeneous MADDPG can output the solutions for transmit beamforming and antenna movement in real time. Simulation results validate the effectiveness of the proposed algorithm, and the MA can significantly improve the sum-rate performance of multiple receivers compared to other benchmark schemes.
Weak Distribution Detectors Lead to Stronger Generalizability of Vision-Language Prompt Tuning
Mar 31, 2024We propose a generalized method for boosting the generalization ability of pre-trained vision-language models (VLMs) while fine-tuning on downstream few-shot tasks. The idea is realized by exploiting out-of-distribution (OOD) detection to predict whether a sample belongs to a base distribution or a novel distribution and then using the score generated by a dedicated competition based scoring function to fuse the zero-shot and few-shot classifier. The fused classifier is dynamic, which will bias towards the zero-shot classifier if a sample is more likely from the distribution pre-trained on, leading to improved base-to-novel generalization ability. Our method is performed only in test stage, which is applicable to boost existing methods without time-consuming re-training. Extensive experiments show that even weak distribution detectors can still improve VLMs' generalization ability. Specifically, with the help of OOD detectors, the harmonic mean of CoOp and ProGrad increase by 2.6 and 1.5 percentage points over 11 recognition datasets in the base-to-novel setting.
Compositional Kronecker Context Optimization for Vision-Language Models
Mar 18, 2024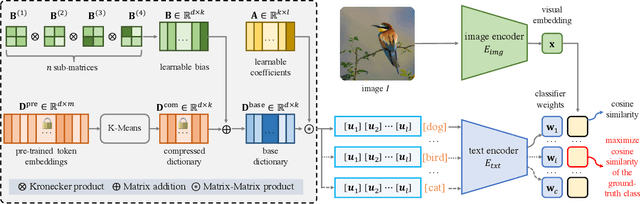
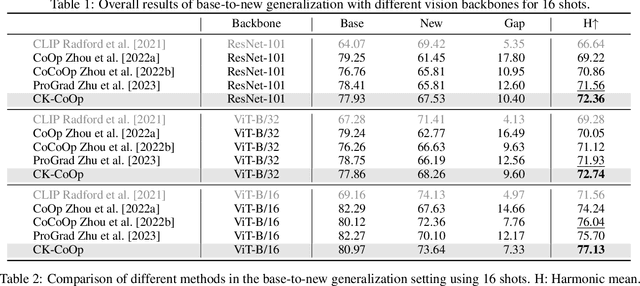
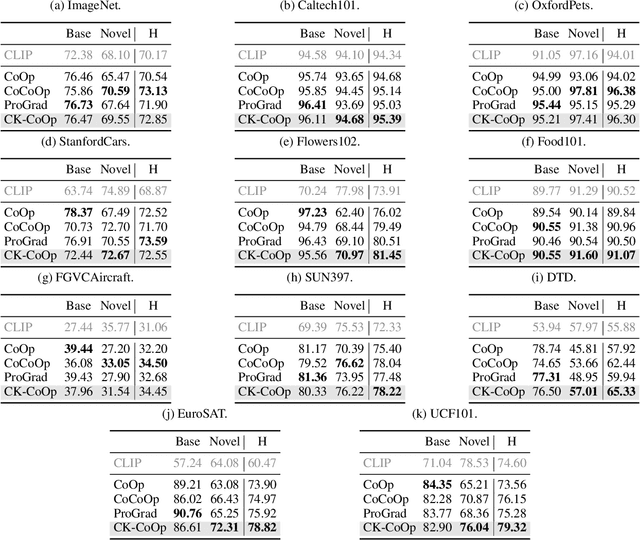

Context Optimization (CoOp) has emerged as a simple yet effective technique for adapting CLIP-like vision-language models to downstream image recognition tasks. Nevertheless, learning compact context with satisfactory base-to-new, domain and cross-task generalization ability while adapting to new tasks is still a challenge. To tackle such a challenge, we propose a lightweight yet generalizable approach termed Compositional Kronecker Context Optimization (CK-CoOp). Technically, the prompt's context words in CK-CoOp are learnable vectors, which are crafted by linearly combining base vectors sourced from a dictionary. These base vectors consist of a non-learnable component obtained by quantizing the weights in the token embedding layer, and a learnable component constructed by applying Kronecker product on several learnable tiny matrices. Intuitively, the compositional structure mitigates the risk of overfitting on training data by remembering more pre-trained knowledge. Meantime, the Kronecker product breaks the non-learnable restrictions of the dictionary, thereby enhancing representation ability with minimal additional parameters. Extensive experiments confirm that CK-CoOp achieves state-of-the-art performance under base-to-new, domain and cross-task generalization evaluation, but also has the metrics of fewer learnable parameters and efficient training and inference speed.
Wavenumber Domain Sparse Channel Estimation in Holographic MIMO
Mar 17, 2024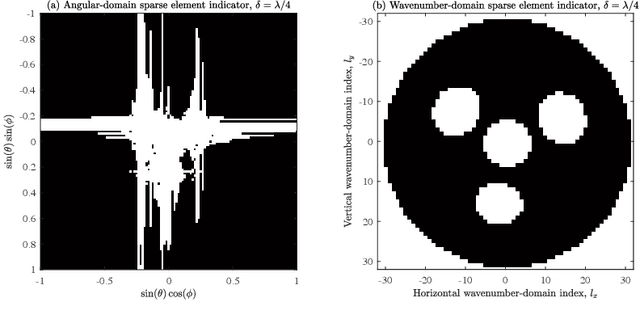
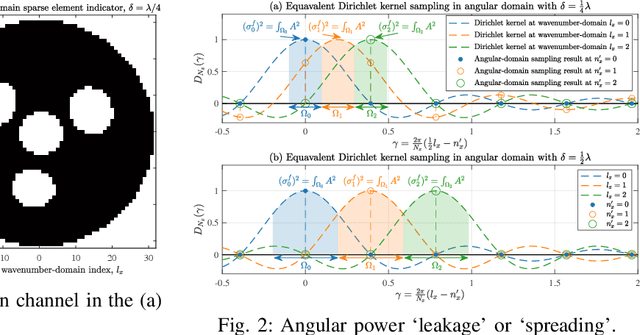

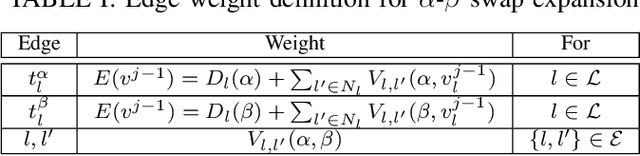
In this paper, we investigate the sparse channel estimation in holographic multiple-input multiple-output (HMIMO) systems. The conventional angular-domain representation fails to capture the continuous angular power spectrum characterized by the spatially-stationary electromagnetic random field, thus leading to the ambiguous detection of the significant angular power, which is referred to as the power leakage. To tackle this challenge, the HMIMO channel is represented in the wavenumber domain for exploring its cluster-dominated sparsity. Specifically, a finite set of Fourier harmonics acts as a series of sampling probes to encapsulate the integral of the power spectrum over specific angular regions. This technique effectively eliminates power leakage resulting from power mismatches induced by the use of discrete angular-domain probes. Next, the channel estimation problem is recast as a sparse recovery of the significant angular power spectrum over the continuous integration region. We then propose an accompanying graph-cut-based swap expansion (GCSE) algorithm to extract beneficial sparsity inherent in HMIMO channels. Numerical results demonstrate that this wavenumber-domainbased GCSE approach achieves robust performance with rapid convergence.
Data is all you need: Finetuning LLMs for Chip Design via an Automated design-data augmentation framework
Mar 17, 2024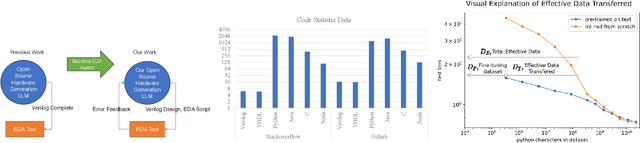
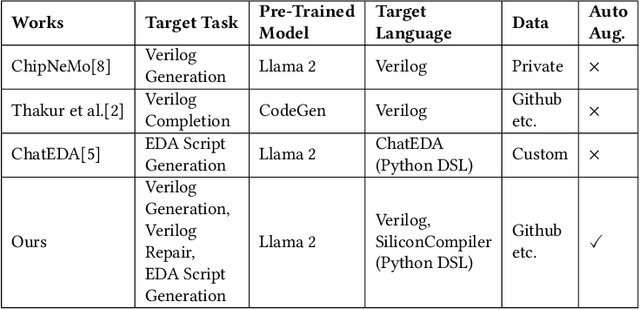
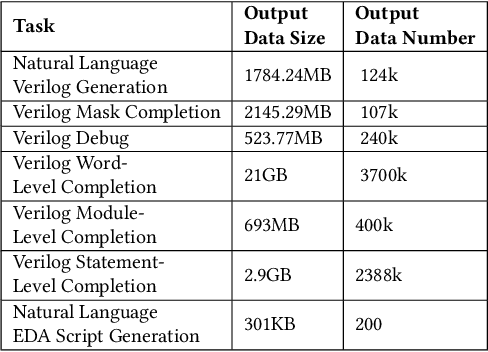
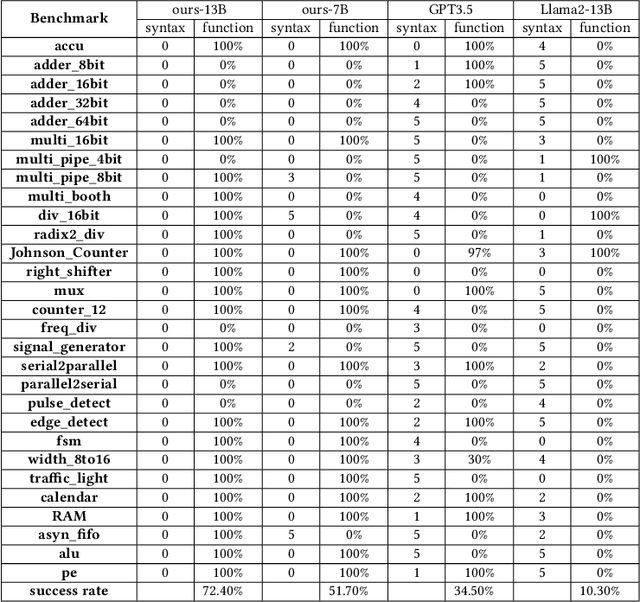
Recent advances in large language models have demonstrated their potential for automated generation of hardware description language (HDL) code from high-level prompts. Researchers have utilized fine-tuning to enhance the ability of these large language models (LLMs) in the field of Chip Design. However, the lack of Verilog data hinders further improvement in the quality of Verilog generation by LLMs. Additionally, the absence of a Verilog and Electronic Design Automation (EDA) script data augmentation framework significantly increases the time required to prepare the training dataset for LLM trainers. This paper proposes an automated design-data augmentation framework, which generates high-volume and high-quality natural language aligned with Verilog and EDA scripts. For Verilog generation, it translates Verilog files to an abstract syntax tree and then maps nodes to natural language with a predefined template. For Verilog repair, it uses predefined rules to generate the wrong verilog file and then pairs EDA Tool feedback with the right and wrong verilog file. For EDA Script generation, it uses existing LLM(GPT-3.5) to obtain the description of the Script. To evaluate the effectiveness of our data augmentation method, we finetune Llama2-13B and Llama2-7B models using the dataset generated by our augmentation framework. The results demonstrate a significant improvement in the Verilog generation tasks with LLMs. Moreover, the accuracy of Verilog generation surpasses that of the current state-of-the-art open-source Verilog generation model, increasing from 58.8% to 70.6% with the same benchmark. Our 13B model (ChipGPT-FT) has a pass rate improvement compared with GPT-3.5 in Verilog generation and outperforms in EDA script (i.e., SiliconCompiler) generation with only 200 EDA script data.
Multi-step Temporal Modeling for UAV Tracking
Mar 07, 2024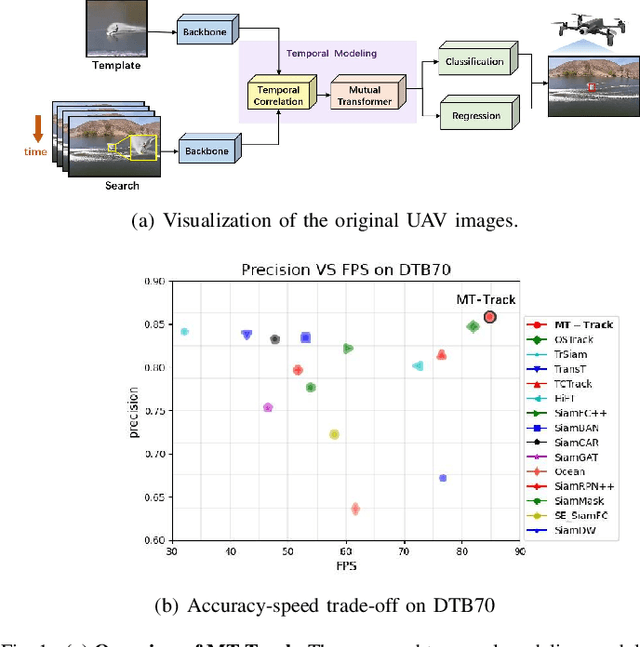
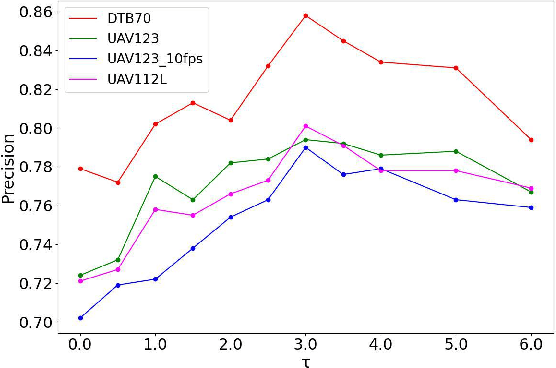

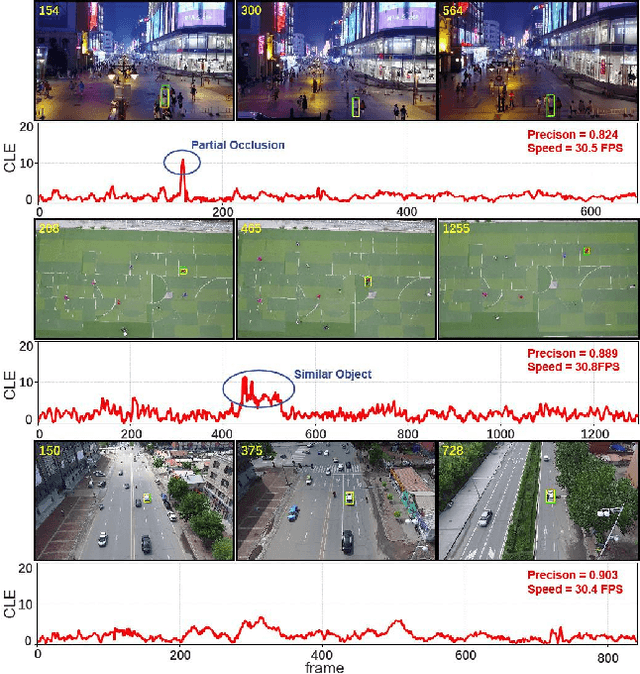
In the realm of unmanned aerial vehicle (UAV) tracking, Siamese-based approaches have gained traction due to their optimal balance between efficiency and precision. However, UAV scenarios often present challenges such as insufficient sampling resolution, fast motion and small objects with limited feature information. As a result, temporal context in UAV tracking tasks plays a pivotal role in target location, overshadowing the target's precise features. In this paper, we introduce MT-Track, a streamlined and efficient multi-step temporal modeling framework designed to harness the temporal context from historical frames for enhanced UAV tracking. This temporal integration occurs in two steps: correlation map generation and correlation map refinement. Specifically, we unveil a unique temporal correlation module that dynamically assesses the interplay between the template and search region features. This module leverages temporal information to refresh the template feature, yielding a more precise correlation map. Subsequently, we propose a mutual transformer module to refine the correlation maps of historical and current frames by modeling the temporal knowledge in the tracking sequence. This method significantly trims computational demands compared to the raw transformer. The compact yet potent nature of our tracking framework ensures commendable tracking outcomes, particularly in extended tracking scenarios.
Intensive Vision-guided Network for Radiology Report Generation
Feb 06, 2024Automatic radiology report generation is booming due to its huge application potential for the healthcare industry. However, existing computer vision and natural language processing approaches to tackle this problem are limited in two aspects. First, when extracting image features, most of them neglect multi-view reasoning in vision and model single-view structure of medical images, such as space-view or channel-view. However, clinicians rely on multi-view imaging information for comprehensive judgment in daily clinical diagnosis. Second, when generating reports, they overlook context reasoning with multi-modal information and focus on pure textual optimization utilizing retrieval-based methods. We aim to address these two issues by proposing a model that better simulates clinicians' perspectives and generates more accurate reports. Given the above limitation in feature extraction, we propose a Globally-intensive Attention (GIA) module in the medical image encoder to simulate and integrate multi-view vision perception. GIA aims to learn three types of vision perception: depth view, space view, and pixel view. On the other hand, to address the above problem in report generation, we explore how to involve multi-modal signals to generate precisely matched reports, i.e., how to integrate previously predicted words with region-aware visual content in next word prediction. Specifically, we design a Visual Knowledge-guided Decoder (VKGD), which can adaptively consider how much the model needs to rely on visual information and previously predicted text to assist next word prediction. Hence, our final Intensive Vision-guided Network (IVGN) framework includes a GIA-guided Visual Encoder and the VKGD. Experiments on two commonly-used datasets IU X-Ray and MIMIC-CXR demonstrate the superior ability of our method compared with other state-of-the-art approaches.
Quantum-Assisted Adaptive Beamforming in UASs Network: Enhancing Airborne Communication via Collaborative UASs for NextG IoT
Jan 26, 2024This paper introduces a novel quantum-based method for dynamic beamforming and re-forming in Unmanned Aircraft Systems (UASs), specifically addressing the critical challenges posed by the unavoidable hovering characteristics of UAVs. Hovering creates significant beam path distortions, impacting the reliability and quality of distributed beamforming in airborne networks. To overcome these challenges, our Quantum Search for UAS Beamforming (QSUB) employs quantum superposition, entanglement, and amplitude amplification. It adaptively reconfigures beams, enhancing beam quality and maintaining robust communication links in the face of rapid UAS state changes due to hovering. Furthermore, we propose an optimized framework, Quantum-Position-Locked Loop (Q-P-LL), that is based on the principle of the Nelder-Mead optimization method for adaptive search to reduce prediction error and improve resilience against angle-of-arrival estimation errors, crucial under dynamic hovering conditions. We also demonstrate the scalability of the system performance and computation complexity by comparing various numbers of active UASs. Importantly, QSUB and Q-P-LL can be applied to both classical and quantum computing architectures. Comparative analyses with conventional Maximum Ratio Transmission (MRT) schemes demonstrate the superior performance and scalability of our quantum approaches, marking significant advancements in the next-generation Internet of Things (IoT) applications requiring reliable airborne communication networks.
CIM-MLC: A Multi-level Compilation Stack for Computing-In-Memory Accelerators
Jan 23, 2024In recent years, various computing-in-memory (CIM) processors have been presented, showing superior performance over traditional architectures. To unleash the potential of various CIM architectures, such as device precision, crossbar size, and crossbar number, it is necessary to develop compilation tools that are fully aware of the CIM architectural details and implementation diversity. However, due to the lack of architectural support in current popular open-source compiling stacks, existing CIM designs either manually deploy networks or build their own compilers, which is time-consuming and labor-intensive. Although some works expose the specific CIM device programming interfaces to compilers, they are often bound to a fixed CIM architecture, lacking the flexibility to support the CIM architectures with different computing granularity. On the other hand, existing compilation works usually consider the scheduling of limited operation types (such as crossbar-bound matrix-vector multiplication). Unlike conventional processors, CIM accelerators are featured by their diverse architecture, circuit, and device, which cannot be simply abstracted by a single level if we seek to fully explore the advantages brought by CIM. Therefore, we propose CIM-MLC, a universal multi-level compilation framework for general CIM architectures. We first establish a general hardware abstraction for CIM architectures and computing modes to represent various CIM accelerators. Based on the proposed abstraction, CIM-MLC can compile tasks onto a wide range of CIM accelerators having different devices, architectures, and programming interfaces. More importantly, compared with existing compilation work, CIM-MLC can explore the mapping and scheduling strategies across multiple architectural tiers, which form a tractable yet effective design space, to achieve better scheduling and instruction generation results.