 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKun Ding
Weak Distribution Detectors Lead to Stronger Generalizability of Vision-Language Prompt Tuning
Mar 31, 2024
We propose a generalized method for boosting the generalization ability of pre-trained vision-language models (VLMs) while fine-tuning on downstream few-shot tasks. The idea is realized by exploiting out-of-distribution (OOD) detection to predict whether a sample belongs to a base distribution or a novel distribution and then using the score generated by a dedicated competition based scoring function to fuse the zero-shot and few-shot classifier. The fused classifier is dynamic, which will bias towards the zero-shot classifier if a sample is more likely from the distribution pre-trained on, leading to improved base-to-novel generalization ability. Our method is performed only in test stage, which is applicable to boost existing methods without time-consuming re-training. Extensive experiments show that even weak distribution detectors can still improve VLMs' generalization ability. Specifically, with the help of OOD detectors, the harmonic mean of CoOp and ProGrad increase by 2.6 and 1.5 percentage points over 11 recognition datasets in the base-to-novel setting.
Compositional Kronecker Context Optimization for Vision-Language Models
Mar 18, 2024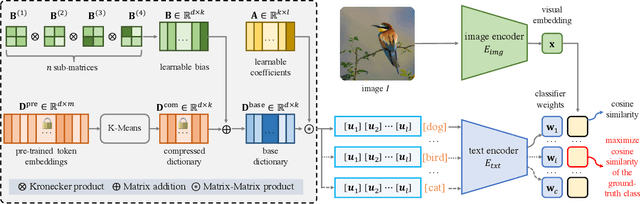
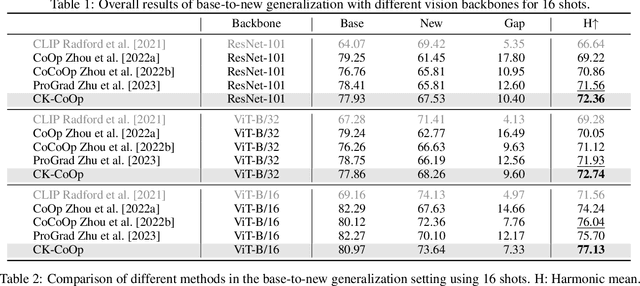
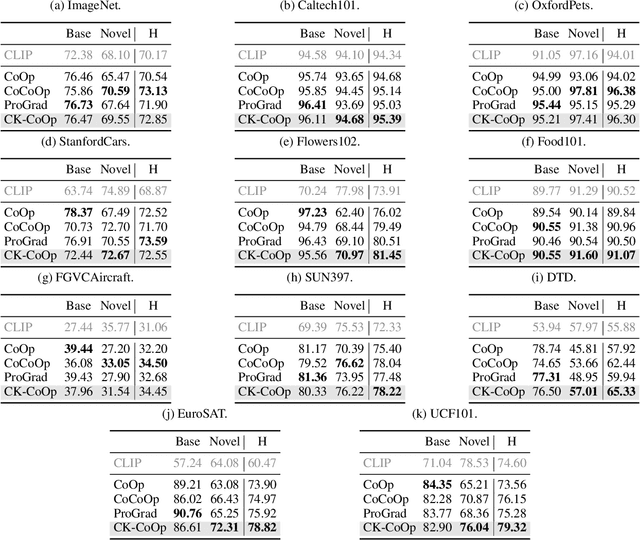

Context Optimization (CoOp) has emerged as a simple yet effective technique for adapting CLIP-like vision-language models to downstream image recognition tasks. Nevertheless, learning compact context with satisfactory base-to-new, domain and cross-task generalization ability while adapting to new tasks is still a challenge. To tackle such a challenge, we propose a lightweight yet generalizable approach termed Compositional Kronecker Context Optimization (CK-CoOp). Technically, the prompt's context words in CK-CoOp are learnable vectors, which are crafted by linearly combining base vectors sourced from a dictionary. These base vectors consist of a non-learnable component obtained by quantizing the weights in the token embedding layer, and a learnable component constructed by applying Kronecker product on several learnable tiny matrices. Intuitively, the compositional structure mitigates the risk of overfitting on training data by remembering more pre-trained knowledge. Meantime, the Kronecker product breaks the non-learnable restrictions of the dictionary, thereby enhancing representation ability with minimal additional parameters. Extensive experiments confirm that CK-CoOp achieves state-of-the-art performance under base-to-new, domain and cross-task generalization evaluation, but also has the metrics of fewer learnable parameters and efficient training and inference speed.
Zero-shot Generalizable Incremental Learning for Vision-Language Object Detection
Mar 04, 2024
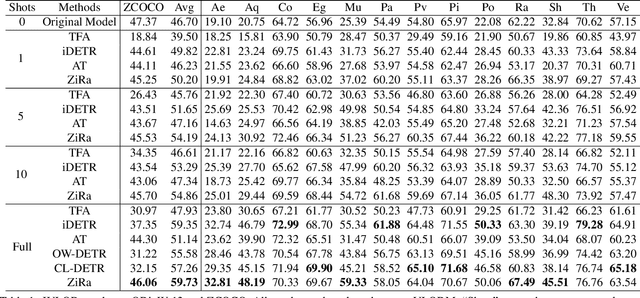
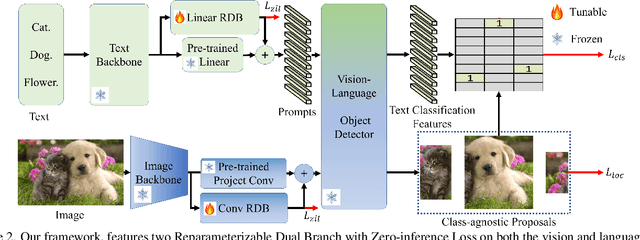

This paper presents Incremental Vision-Language Object Detection (IVLOD), a novel learning task designed to incrementally adapt pre-trained Vision-Language Object Detection Models (VLODMs) to various specialized domains, while simultaneously preserving their zero-shot generalization capabilities for the generalized domain. To address this new challenge, we present the Zero-interference Reparameterizable Adaptation (ZiRa), a novel method that introduces Zero-interference Loss and reparameterization techniques to tackle IVLOD without incurring additional inference costs or a significant increase in memory usage. Comprehensive experiments on COCO and ODinW-13 datasets demonstrate that ZiRa effectively safeguards the zero-shot generalization ability of VLODMs while continuously adapting to new tasks. Specifically, after training on ODinW-13 datasets, ZiRa exhibits superior performance compared to CL-DETR and iDETR, boosting zero-shot generalizability by substantial 13.91 and 8.71 AP, respectively.
PAD: Self-Supervised Pre-Training with Patchwise-Scale Adapter for Infrared Images
Dec 13, 2023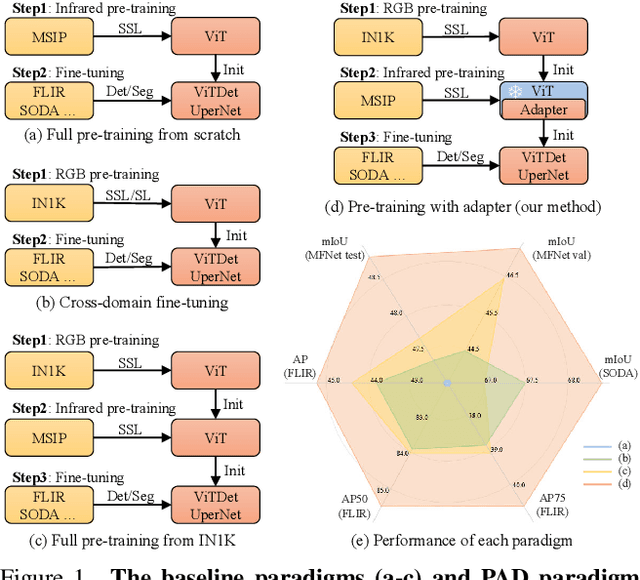
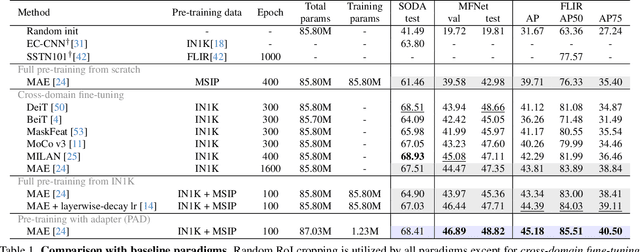

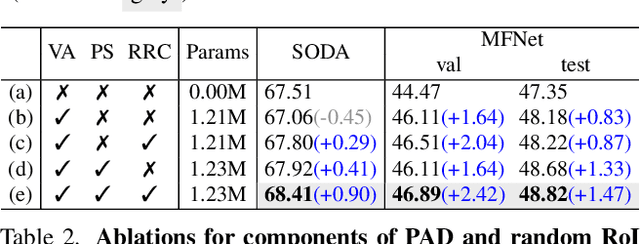
Self-supervised learning (SSL) for RGB images has achieved significant success, yet there is still limited research on SSL for infrared images, primarily due to three prominent challenges: 1) the lack of a suitable large-scale infrared pre-training dataset, 2) the distinctiveness of non-iconic infrared images rendering common pre-training tasks like masked image modeling (MIM) less effective, and 3) the scarcity of fine-grained textures making it particularly challenging to learn general image features. To address these issues, we construct a Multi-Scene Infrared Pre-training (MSIP) dataset comprising 178,756 images, and introduce object-sensitive random RoI cropping, an image preprocessing method, to tackle the challenge posed by non-iconic images. To alleviate the impact of weak textures on feature learning, we propose a pre-training paradigm called Pre-training with ADapter (PAD), which uses adapters to learn domain-specific features while freezing parameters pre-trained on ImageNet to retain the general feature extraction capability. This new paradigm is applicable to any transformer-based SSL method. Furthermore, to achieve more flexible coordination between pre-trained and newly-learned features in different layers and patches, a patchwise-scale adapter with dynamically learnable scale factors is introduced. Extensive experiments on three downstream tasks show that PAD, with only 1.23M pre-trainable parameters, outperforms other baseline paradigms including continual full pre-training on MSIP. Our code and dataset are available at https://github.com/casiatao/PAD.
Prompt Tuning with Soft Context Sharing for Vision-Language Models
Aug 29, 2022



Vision-language models have recently shown great potential on many computer vision tasks. Meanwhile, prior work demonstrates prompt tuning designed for vision-language models could acquire superior performance on few-shot image recognition compared to linear probe, a strong baseline. In real-world applications, many few-shot tasks are correlated, particularly in a specialized area. However, such information is ignored by previous work. Inspired by the fact that modeling task relationships by multi-task learning can usually boost performance, we propose a novel method SoftCPT (Soft Context Sharing for Prompt Tuning) to fine-tune pre-trained vision-language models on multiple target few-shot tasks, simultaneously. Specifically, we design a task-shared meta network to generate prompt vector for each task using pre-defined task name together with a learnable meta prompt as input. As such, the prompt vectors of all tasks will be shared in a soft manner. The parameters of this shared meta network as well as the meta prompt vector are tuned on the joint training set of all target tasks. Extensive experiments on three multi-task few-shot datasets show that SoftCPT outperforms the representative single-task prompt tuning method CoOp [78] by a large margin, implying the effectiveness of multi-task learning in vision-language prompt tuning. The source code and data will be made publicly available.