 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeijiang Yu
Exploring Low-Resource Medical Image Classification with Weakly Supervised Prompt Learning
Feb 06, 2024
Most advances in medical image recognition supporting clinical auxiliary diagnosis meet challenges due to the low-resource situation in the medical field, where annotations are highly expensive and professional. This low-resource problem can be alleviated by leveraging the transferable representations of large-scale pre-trained vision-language models via relevant medical text prompts. However, existing pre-trained vision-language models require domain experts to carefully design the medical prompts, which greatly increases the burden on clinicians. To address this problem, we propose a weakly supervised prompt learning method MedPrompt to automatically generate medical prompts, which includes an unsupervised pre-trained vision-language model and a weakly supervised prompt learning model. The unsupervised pre-trained vision-language model utilizes the natural correlation between medical images and corresponding medical texts for pre-training, without any manual annotations. The weakly supervised prompt learning model only utilizes the classes of images in the dataset to guide the learning of the specific class vector in the prompt, while the learning of other context vectors in the prompt requires no manual annotations for guidance. To the best of our knowledge, this is the first model to automatically generate medical prompts. With these prompts, the pre-trained vision-language model can be freed from the strong expert dependency of manual annotation and manual prompt design. Experimental results show that the model using our automatically generated prompts outperforms its full-shot learning hand-crafted prompts counterparts with only a minimal number of labeled samples for few-shot learning, and reaches superior or comparable accuracy on zero-shot image classification. The proposed prompt generator is lightweight and therefore can be embedded into any network architecture.
Intensive Vision-guided Network for Radiology Report Generation
Feb 06, 2024Automatic radiology report generation is booming due to its huge application potential for the healthcare industry. However, existing computer vision and natural language processing approaches to tackle this problem are limited in two aspects. First, when extracting image features, most of them neglect multi-view reasoning in vision and model single-view structure of medical images, such as space-view or channel-view. However, clinicians rely on multi-view imaging information for comprehensive judgment in daily clinical diagnosis. Second, when generating reports, they overlook context reasoning with multi-modal information and focus on pure textual optimization utilizing retrieval-based methods. We aim to address these two issues by proposing a model that better simulates clinicians' perspectives and generates more accurate reports. Given the above limitation in feature extraction, we propose a Globally-intensive Attention (GIA) module in the medical image encoder to simulate and integrate multi-view vision perception. GIA aims to learn three types of vision perception: depth view, space view, and pixel view. On the other hand, to address the above problem in report generation, we explore how to involve multi-modal signals to generate precisely matched reports, i.e., how to integrate previously predicted words with region-aware visual content in next word prediction. Specifically, we design a Visual Knowledge-guided Decoder (VKGD), which can adaptively consider how much the model needs to rely on visual information and previously predicted text to assist next word prediction. Hence, our final Intensive Vision-guided Network (IVGN) framework includes a GIA-guided Visual Encoder and the VKGD. Experiments on two commonly-used datasets IU X-Ray and MIMIC-CXR demonstrate the superior ability of our method compared with other state-of-the-art approaches.
AdaNAS: Adaptively Post-processing with Self-supervised Neural Architecture Search for Ensemble Rainfall Forecasts
Dec 26, 2023Previous post-processing studies on rainfall forecasts using numerical weather prediction (NWP) mainly focus on statistics-based aspects, while learning-based aspects are rarely investigated. Although some manually-designed models are proposed to raise accuracy, they are customized networks, which need to be repeatedly tried and verified, at a huge cost in time and labor. Therefore, a self-supervised neural architecture search (NAS) method without significant manual efforts called AdaNAS is proposed in this study to perform rainfall forecast post-processing and predict rainfall with high accuracy. In addition, we design a rainfall-aware search space to significantly improve forecasts for high-rainfall areas. Furthermore, we propose a rainfall-level regularization function to eliminate the effect of noise data during the training. Validation experiments have been performed under the cases of \emph{None}, \emph{Light}, \emph{Moderate}, \emph{Heavy} and \emph{Violent} on a large-scale precipitation benchmark named TIGGE. Finally, the average mean-absolute error (MAE) and average root-mean-square error (RMSE) of the proposed AdaNAS model are 0.98 and 2.04 mm/day, respectively. Additionally, the proposed AdaNAS model is compared with other neural architecture search methods and previous studies. Compared results reveal the satisfactory performance and superiority of the proposed AdaNAS model in terms of precipitation amount prediction and intensity classification. Concretely, the proposed AdaNAS model outperformed previous best-performing manual methods with MAE and RMSE improving by 80.5\% and 80.3\%, respectively.
Apollo's Oracle: Retrieval-Augmented Reasoning in Multi-Agent Debates
Dec 08, 2023
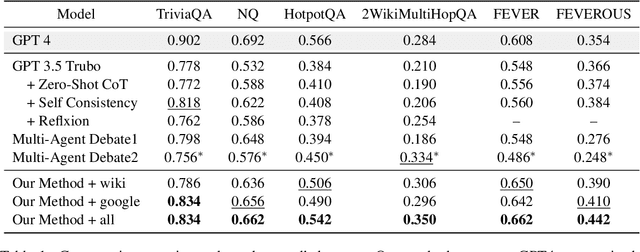
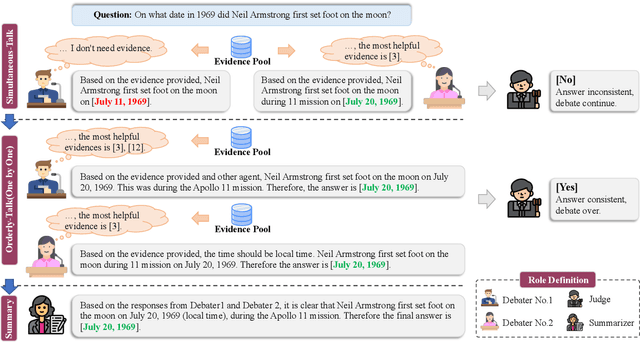

Multi-agent debate systems are designed to derive accurate and consistent conclusions through adversarial interactions among agents. However, these systems often encounter challenges due to cognitive constraints, manifesting as (1) agents' obstinate adherence to incorrect viewpoints and (2) their propensity to abandon correct viewpoints. These issues are primarily responsible for the ineffectiveness of such debates. Addressing the challenge of cognitive constraints, we introduce a novel framework, the Multi-Agent Debate with Retrieval Augmented (MADRA). MADRA incorporates retrieval of prior knowledge into the debate process, effectively breaking cognitive constraints and enhancing the agents' reasoning capabilities. Furthermore, we have developed a self-selection module within this framework, enabling agents to autonomously select pertinent evidence, thereby minimizing the impact of irrelevant or noisy data. We have comprehensively tested and analyzed MADRA across six diverse datasets. The experimental results demonstrate that our approach significantly enhances performance across various tasks, proving the effectiveness of our proposed method.
TimeBench: A Comprehensive Evaluation of Temporal Reasoning Abilities in Large Language Models
Nov 29, 2023Understanding time is a pivotal aspect of human cognition, crucial in the broader framework of grasping the intricacies of the world. Previous studies typically focus on specific aspects of time, lacking a comprehensive temporal reasoning benchmark. To address this issue, we propose TimeBench, a comprehensive hierarchical temporal reasoning benchmark that covers a broad spectrum of temporal reasoning phenomena, which provides a thorough evaluation for investigating the temporal reasoning capabilities of large language models. We conduct extensive experiments on popular LLMs, such as GPT-4, LLaMA2, and Mistral, incorporating chain-of-thought prompting. Our experimental results indicate a significant performance gap between the state-of-the-art LLMs and humans, highlighting that there is still a considerable distance to cover in temporal reasoning. We aspire for TimeBench to serve as a comprehensive benchmark, fostering research in temporal reasoning for LLMs. Our resource is available at https://github.com/zchuz/TimeBench
Trends in Integration of Knowledge and Large Language Models: A Survey and Taxonomy of Methods, Benchmarks, and Applications
Nov 10, 2023Large language models (LLMs) exhibit superior performance on various natural language tasks, but they are susceptible to issues stemming from outdated data and domain-specific limitations. In order to address these challenges, researchers have pursued two primary strategies, knowledge editing and retrieval augmentation, to enhance LLMs by incorporating external information from different aspects. Nevertheless, there is still a notable absence of a comprehensive survey. In this paper, we propose a review to discuss the trends in integration of knowledge and large language models, including taxonomy of methods, benchmarks, and applications. In addition, we conduct an in-depth analysis of different methods and point out potential research directions in the future. We hope this survey offers the community quick access and a comprehensive overview of this research area, with the intention of inspiring future research endeavors.
A Survey on Hallucination in Large Language Models: Principles, Taxonomy, Challenges, and Open Questions
Nov 09, 2023The emergence of large language models (LLMs) has marked a significant breakthrough in natural language processing (NLP), leading to remarkable advancements in text understanding and generation. Nevertheless, alongside these strides, LLMs exhibit a critical tendency to produce hallucinations, resulting in content that is inconsistent with real-world facts or user inputs. This phenomenon poses substantial challenges to their practical deployment and raises concerns over the reliability of LLMs in real-world scenarios, which attracts increasing attention to detect and mitigate these hallucinations. In this survey, we aim to provide a thorough and in-depth overview of recent advances in the field of LLM hallucinations. We begin with an innovative taxonomy of LLM hallucinations, then delve into the factors contributing to hallucinations. Subsequently, we present a comprehensive overview of hallucination detection methods and benchmarks. Additionally, representative approaches designed to mitigate hallucinations are introduced accordingly. Finally, we analyze the challenges that highlight the current limitations and formulate open questions, aiming to delineate pathways for future research on hallucinations in LLMs.
A Survey of Chain of Thought Reasoning: Advances, Frontiers and Future
Sep 27, 2023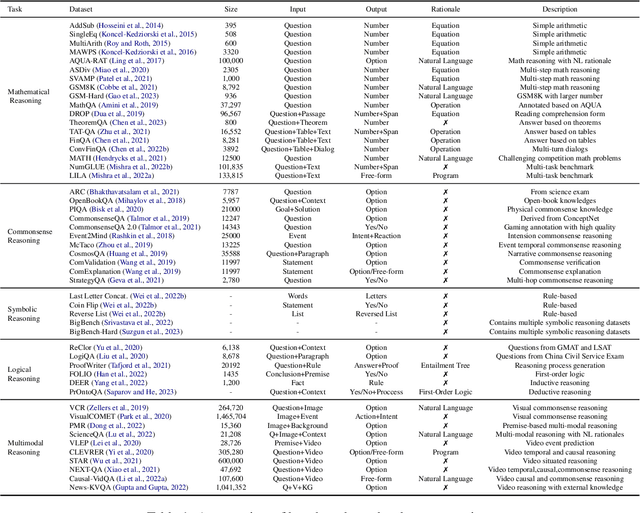

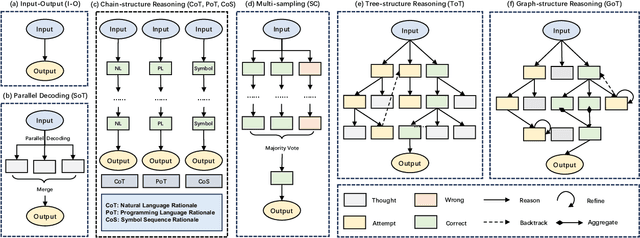

Chain-of-thought reasoning, a cognitive process fundamental to human intelligence, has garnered significant attention in the realm of artificial intelligence and natural language processing. However, there still remains a lack of a comprehensive survey for this arena. To this end, we take the first step and present a thorough survey of this research field carefully and widely. We use X-of-Thought to refer to Chain-of-Thought in a broad sense. In detail, we systematically organize the current research according to the taxonomies of methods, including XoT construction, XoT structure variants, and enhanced XoT. Additionally, we describe XoT with frontier applications, covering planning, tool use, and distillation. Furthermore, we address challenges and discuss some future directions, including faithfulness, multi-modal, and theory. We hope this survey serves as a valuable resource for researchers seeking to innovate within the domain of chain-of-thought reasoning.
Domain-Adaptive Text Classification with Structured Knowledge from Unlabeled Data
Jun 20, 2022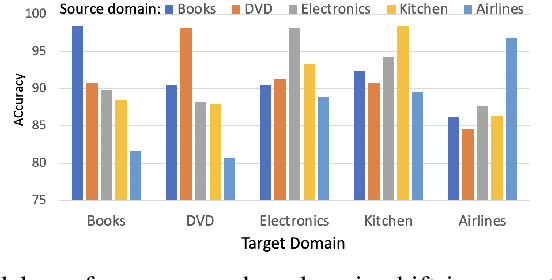
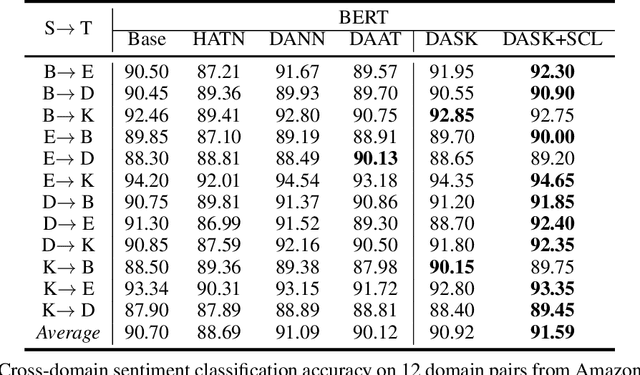
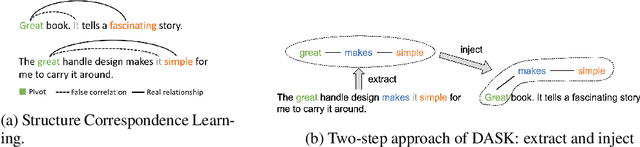
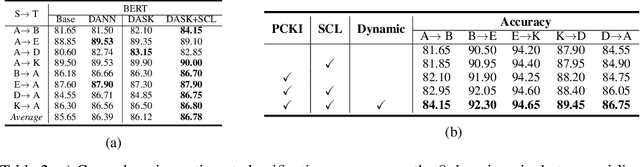
Domain adaptive text classification is a challenging problem for the large-scale pretrained language models because they often require expensive additional labeled data to adapt to new domains. Existing works usually fails to leverage the implicit relationships among words across domains. In this paper, we propose a novel method, called Domain Adaptation with Structured Knowledge (DASK), to enhance domain adaptation by exploiting word-level semantic relationships. DASK first builds a knowledge graph to capture the relationship between pivot terms (domain-independent words) and non-pivot terms in the target domain. Then during training, DASK injects pivot-related knowledge graph information into source domain texts. For the downstream task, these knowledge-injected texts are fed into a BERT variant capable of processing knowledge-injected textual data. Thanks to the knowledge injection, our model learns domain-invariant features for non-pivots according to their relationships with pivots. DASK ensures the pivots to have domain-invariant behaviors by dynamically inferring via the polarity scores of candidate pivots during training with pseudo-labels. We validate DASK on a wide range of cross-domain sentiment classification tasks and observe up to 2.9% absolute performance improvement over baselines for 20 different domain pairs. Code will be made available at https://github.com/hikaru-nara/DASK.
Bailando: 3D Dance Generation by Actor-Critic GPT with Choreographic Memory
Mar 25, 2022
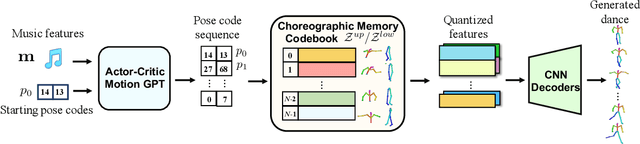
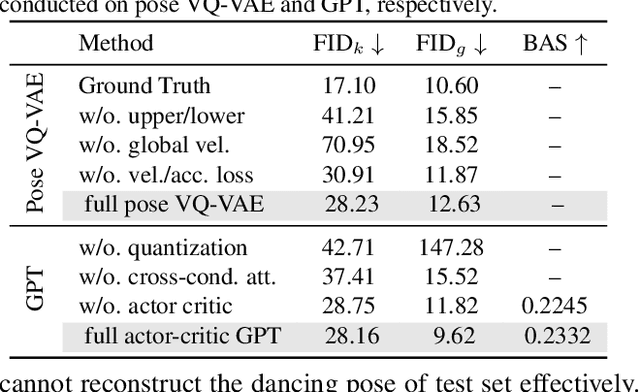
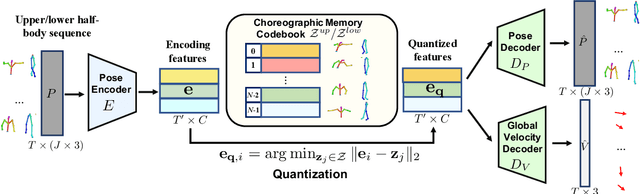
Driving 3D characters to dance following a piece of music is highly challenging due to the spatial constraints applied to poses by choreography norms. In addition, the generated dance sequence also needs to maintain temporal coherency with different music genres. To tackle these challenges, we propose a novel music-to-dance framework, Bailando, with two powerful components: 1) a choreographic memory that learns to summarize meaningful dancing units from 3D pose sequence to a quantized codebook, 2) an actor-critic Generative Pre-trained Transformer (GPT) that composes these units to a fluent dance coherent to the music. With the learned choreographic memory, dance generation is realized on the quantized units that meet high choreography standards, such that the generated dancing sequences are confined within the spatial constraints. To achieve synchronized alignment between diverse motion tempos and music beats, we introduce an actor-critic-based reinforcement learning scheme to the GPT with a newly-designed beat-align reward function. Extensive experiments on the standard benchmark demonstrate that our proposed framework achieves state-of-the-art performance both qualitatively and quantitatively. Notably, the learned choreographic memory is shown to discover human-interpretable dancing-style poses in an unsupervised manner.