 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJingnan Gao
A Comparative Study of Perceptual Quality Metrics for Audio-driven Talking Head Videos
Mar 11, 2024
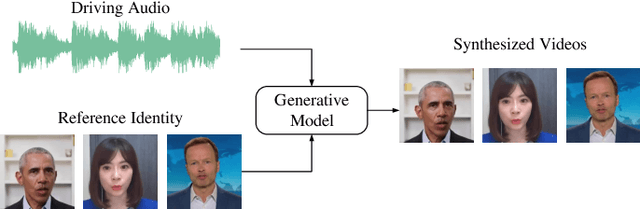
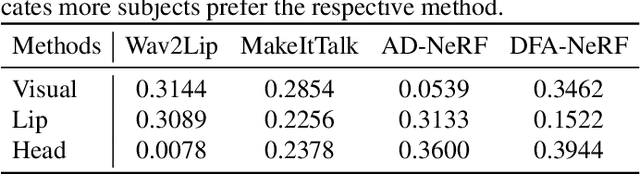

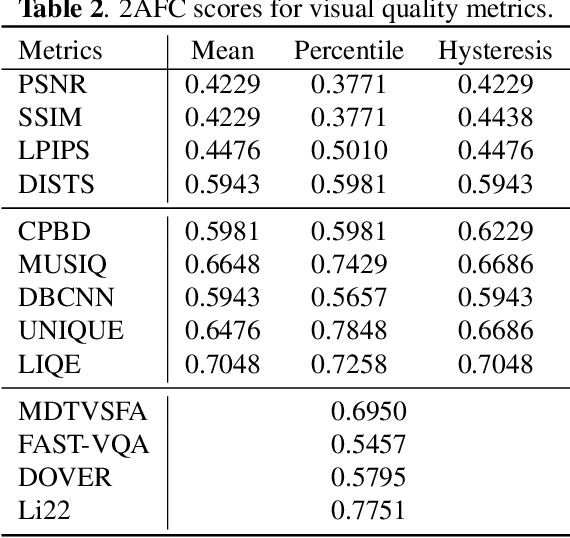
The rapid advancement of Artificial Intelligence Generated Content (AIGC) technology has propelled audio-driven talking head generation, gaining considerable research attention for practical applications. However, performance evaluation research lags behind the development of talking head generation techniques. Existing literature relies on heuristic quantitative metrics without human validation, hindering accurate progress assessment. To address this gap, we collect talking head videos generated from four generative methods and conduct controlled psychophysical experiments on visual quality, lip-audio synchronization, and head movement naturalness. Our experiments validate consistency between model predictions and human annotations, identifying metrics that align better with human opinions than widely-used measures. We believe our work will facilitate performance evaluation and model development, providing insights into AIGC in a broader context. Code and data will be made available at https://github.com/zwx8981/ADTH-QA.
EvaSurf: Efficient View-Aware Implicit Textured Surface Reconstruction on Mobile Devices
Nov 18, 2023Reconstructing real-world 3D objects has numerous applications in computer vision, such as virtual reality, video games, and animations. Ideally, 3D reconstruction methods should generate high-fidelity results with 3D consistency in real-time. Traditional methods match pixels between images using photo-consistency constraints or learned features, while differentiable rendering methods like Neural Radiance Fields (NeRF) use differentiable volume rendering or surface-based representation to generate high-fidelity scenes. However, these methods require excessive runtime for rendering, making them impractical for daily applications. To address these challenges, we present $\textbf{EvaSurf}$, an $\textbf{E}$fficient $\textbf{V}$iew-$\textbf{A}$ware implicit textured $\textbf{Surf}$ace reconstruction method on mobile devices. In our method, we first employ an efficient surface-based model with a multi-view supervision module to ensure accurate mesh reconstruction. To enable high-fidelity rendering, we learn an implicit texture embedded with a set of Gaussian lobes to capture view-dependent information. Furthermore, with the explicit geometry and the implicit texture, we can employ a lightweight neural shader to reduce the expense of computation and further support real-time rendering on common mobile devices. Extensive experiments demonstrate that our method can reconstruct high-quality appearance and accurate mesh on both synthetic and real-world datasets. Moreover, our method can be trained in just 1-2 hours using a single GPU and run on mobile devices at over 40 FPS (Frames Per Second), with a final package required for rendering taking up only 40-50 MB.
ITEM3D: Illumination-Aware Directional Texture Editing for 3D Models
Sep 27, 2023Texture editing is a crucial task in 3D modeling that allows users to automatically manipulate the surface materials of 3D models. However, the inherent complexity of 3D models and the ambiguous text description lead to the challenge in this task. To address this challenge, we propose ITEM3D, an illumination-aware model for automatic 3D object editing according to the text prompts. Leveraging the diffusion models and the differentiable rendering, ITEM3D takes the rendered images as the bridge of text and 3D representation, and further optimizes the disentangled texture and environment map. Previous methods adopt the absolute editing direction namely score distillation sampling (SDS) as the optimization objective, which unfortunately results in the noisy appearance and text inconsistency. To solve the problem caused by the ambiguous text, we introduce a relative editing direction, an optimization objective defined by the noise difference between the source and target texts, to release the semantic ambiguity between the texts and images. Additionally, we gradually adjust the direction during optimization to further address the unexpected deviation in the texture domain. Qualitative and quantitative experiments show that our ITEM3D outperforms the state-of-the-art methods on various 3D objects. We also perform text-guided relighting to show explicit control over lighting.