 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXi Lu
TheaterGen: Character Management with LLM for Consistent Multi-turn Image Generation
Apr 29, 2024




Recent advances in diffusion models can generate high-quality and stunning images from text. However, multi-turn image generation, which is of high demand in real-world scenarios, still faces challenges in maintaining semantic consistency between images and texts, as well as contextual consistency of the same subject across multiple interactive turns. To address this issue, we introduce TheaterGen, a training-free framework that integrates large language models (LLMs) and text-to-image (T2I) models to provide the capability of multi-turn image generation. Within this framework, LLMs, acting as a "Screenwriter", engage in multi-turn interaction, generating and managing a standardized prompt book that encompasses prompts and layout designs for each character in the target image. Based on these, Theatergen generate a list of character images and extract guidance information, akin to the "Rehearsal". Subsequently, through incorporating the prompt book and guidance information into the reverse denoising process of T2I diffusion models, Theatergen generate the final image, as conducting the "Final Performance". With the effective management of prompt books and character images, TheaterGen significantly improves semantic and contextual consistency in synthesized images. Furthermore, we introduce a dedicated benchmark, CMIGBench (Consistent Multi-turn Image Generation Benchmark) with 8000 multi-turn instructions. Different from previous multi-turn benchmarks, CMIGBench does not define characters in advance. Both the tasks of story generation and multi-turn editing are included on CMIGBench for comprehensive evaluation. Extensive experimental results show that TheaterGen outperforms state-of-the-art methods significantly. It raises the performance bar of the cutting-edge Mini DALLE 3 model by 21% in average character-character similarity and 19% in average text-image similarity.
Deep Learning Based Multi-Node ISAC 4D Environmental Reconstruction with Uplink- Downlink Cooperation
Apr 23, 2024Utilizing widely distributed communication nodes to achieve environmental reconstruction is one of the significant scenarios for Integrated Sensing and Communication (ISAC) and a crucial technology for 6G. To achieve this crucial functionality, we propose a deep learning based multi-node ISAC 4D environment reconstruction method with Uplink-Downlink (UL-DL) cooperation, which employs virtual aperture technology, Constant False Alarm Rate (CFAR) detection, and Mutiple Signal Classification (MUSIC) algorithm to maximize the sensing capabilities of single sensing nodes. Simultaneously, it introduces a cooperative environmental reconstruction scheme involving multi-node cooperation and Uplink-Downlink (UL-DL) cooperation to overcome the limitations of single-node sensing caused by occlusion and limited viewpoints. Furthermore, the deep learning models Attention Gate Gridding Residual Neural Network (AGGRNN) and Multi-View Sensing Fusion Network (MVSFNet) to enhance the density of sparsely reconstructed point clouds are proposed, aiming to restore as many original environmental details as possible while preserving the spatial structure of the point cloud. Additionally, we propose a multi-level fusion strategy incorporating both data-level and feature-level fusion to fully leverage the advantages of multi-node cooperation. Experimental results demonstrate that the environmental reconstruction performance of this method significantly outperforms other comparative method, enabling high-precision environmental reconstruction using ISAC system.
Ligandformer: A Graph Neural Network for Predicting Compound Property with Robust Interpretation
Feb 24, 2022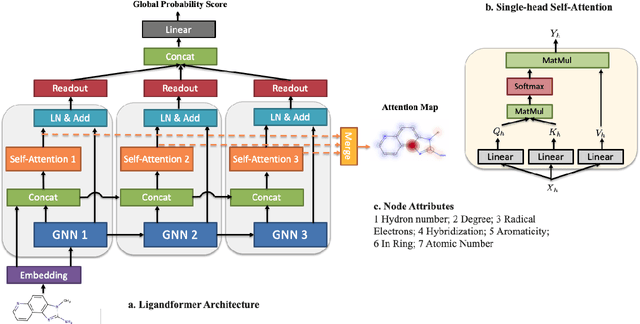

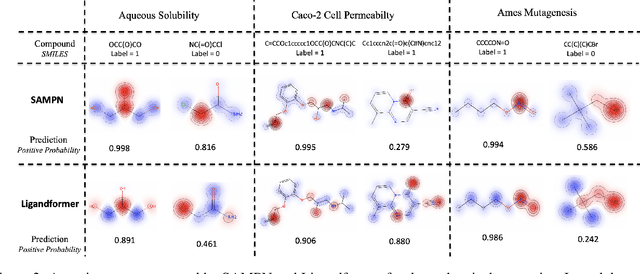
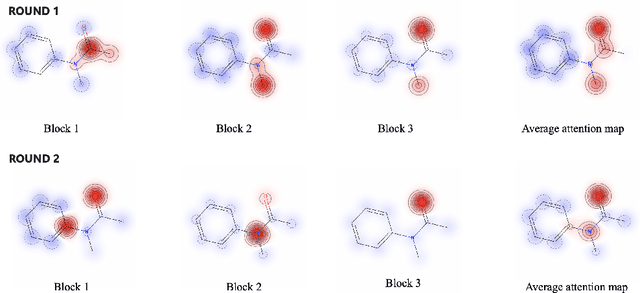
Robust and efficient interpretation of QSAR methods is quite useful to validate AI prediction rationales with subjective opinion (chemist or biologist expertise), understand sophisticated chemical or biological process mechanisms, and provide heuristic ideas for structure optimization in pharmaceutical industry. For this purpose, we construct a multi-layer self-attention based Graph Neural Network framework, namely Ligandformer, for predicting compound property with interpretation. Ligandformer integrates attention maps on compound structure from different network blocks. The integrated attention map reflects the machine's local interest on compound structure, and indicates the relationship between predicted compound property and its structure. This work mainly contributes to three aspects: 1. Ligandformer directly opens the black-box of deep learning methods, providing local prediction rationales on chemical structures. 2. Ligandformer gives robust prediction in different experimental rounds, overcoming the ubiquitous prediction instability of deep learning methods. 3. Ligandformer can be generalized to predict different chemical or biological properties with high performance. Furthermore, Ligandformer can simultaneously output specific property score and visible attention map on structure, which can support researchers to investigate chemical or biological property and optimize structure efficiently. Our framework outperforms over counterparts in terms of accuracy, robustness and generalization, and can be applied in complex system study.