 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNicholas Evans
A Comparison of Differential Performance Metrics for the Evaluation of Automatic Speaker Verification Fairness
Apr 27, 2024
When decisions are made and when personal data is treated by automated processes, there is an expectation of fairness -- that members of different demographic groups receive equitable treatment. This expectation applies to biometric systems such as automatic speaker verification (ASV). We present a comparison of three candidate fairness metrics and extend previous work performed for face recognition, by examining differential performance across a range of different ASV operating points. Results show that the Gini Aggregation Rate for Biometric Equitability (GARBE) is the only one which meets three functional fairness measure criteria. Furthermore, a comprehensive evaluation of the fairness and verification performance of five state-of-the-art ASV systems is also presented. Our findings reveal a nuanced trade-off between fairness and verification accuracy underscoring the complex interplay between system design, demographic inclusiveness, and verification reliability.
The VoicePrivacy 2024 Challenge Evaluation Plan
Apr 03, 2024The task of the challenge is to develop a voice anonymization system for speech data which conceals the speaker's voice identity while protecting linguistic content and emotional states. The organizers provide development and evaluation datasets and evaluation scripts, as well as baseline anonymization systems and a list of training resources formed on the basis of the participants' requests. Participants apply their developed anonymization systems, run evaluation scripts and submit evaluation results and anonymized speech data to the organizers. Results will be presented at a workshop held in conjunction with Interspeech 2024 to which all participants are invited to present their challenge systems and to submit additional workshop papers.
a-DCF: an architecture agnostic metric with application to spoofing-robust speaker verification
Mar 03, 2024

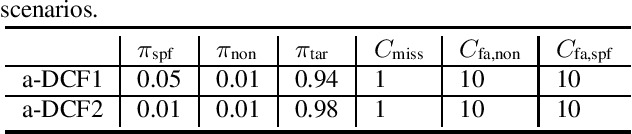
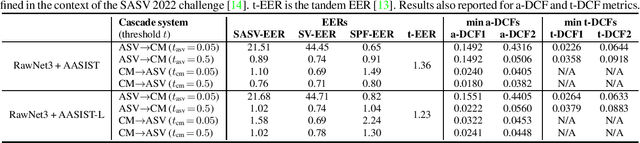
Spoofing detection is today a mainstream research topic. Standard metrics can be applied to evaluate the performance of isolated spoofing detection solutions and others have been proposed to support their evaluation when they are combined with speaker detection. These either have well-known deficiencies or restrict the architectural approach to combine speaker and spoof detectors. In this paper, we propose an architecture-agnostic detection cost function (a-DCF). A generalisation of the original DCF used widely for the assessment of automatic speaker verification (ASV), the a-DCF is designed for the evaluation of spoofing-robust ASV. Like the DCF, the a-DCF reflects the cost of decisions in a Bayes risk sense, with explicitly defined class priors and detection cost model. We demonstrate the merit of the a-DCF through the benchmarking evaluation of architecturally-heterogeneous spoofing-robust ASV solutions.
Speaker anonymization using neural audio codec language models
Sep 28, 2023The vast majority of approaches to speaker anonymization involve the extraction of fundamental frequency estimates, linguistic features and a speaker embedding which is perturbed to obfuscate the speaker identity before an anonymized speech waveform is resynthesized using a vocoder. Recent work has shown that x-vector transformations are difficult to control consistently: other sources of speaker information contained within fundamental frequency and linguistic features are re-entangled upon vocoding, meaning that anonymized speech signals still contain speaker information. We propose an approach based upon neural audio codecs (NACs), which are known to generate high-quality synthetic speech when combined with language models. NACs use quantized codes, which are known to effectively bottleneck speaker-related information: we demonstrate the potential of speaker anonymization systems based on NAC language modeling by applying the evaluation framework of the Voice Privacy Challenge 2022.
t-EER: Parameter-Free Tandem Evaluation of Countermeasures and Biometric Comparators
Sep 21, 2023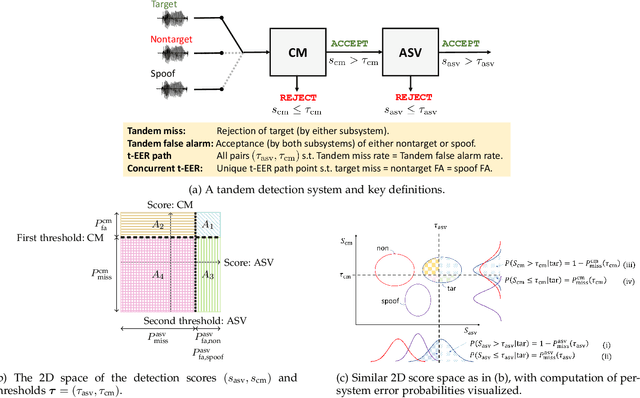

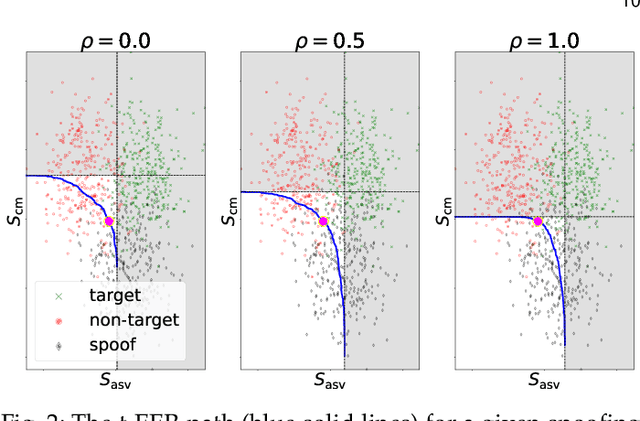

Presentation attack (spoofing) detection (PAD) typically operates alongside biometric verification to improve reliablity in the face of spoofing attacks. Even though the two sub-systems operate in tandem to solve the single task of reliable biometric verification, they address different detection tasks and are hence typically evaluated separately. Evidence shows that this approach is suboptimal. We introduce a new metric for the joint evaluation of PAD solutions operating in situ with biometric verification. In contrast to the tandem detection cost function proposed recently, the new tandem equal error rate (t-EER) is parameter free. The combination of two classifiers nonetheless leads to a \emph{set} of operating points at which false alarm and miss rates are equal and also dependent upon the prevalence of attacks. We therefore introduce the \emph{concurrent} t-EER, a unique operating point which is invariable to the prevalence of attacks. Using both modality (and even application) agnostic simulated scores, as well as real scores for a voice biometrics application, we demonstrate application of the t-EER to a wide range of biometric system evaluations under attack. The proposed approach is a strong candidate metric for the tandem evaluation of PAD systems and biometric comparators.
Spoofing attack augmentation: can differently-trained attack models improve generalisation?
Sep 18, 2023A reliable deepfake detector or spoofing countermeasure (CM) should be robust in the face of unpredictable spoofing attacks. To encourage the learning of more generaliseable artefacts, rather than those specific only to known attacks, CMs are usually exposed to a broad variety of different attacks during training. Even so, the performance of deep-learning-based CM solutions are known to vary, sometimes substantially, when they are retrained with different initialisations, hyper-parameters or training data partitions. We show in this paper that the potency of spoofing attacks, also deep-learning-based, can similarly vary according to training conditions, sometimes resulting in substantial degradations to detection performance. Nevertheless, while a RawNet2 CM model is vulnerable when only modest adjustments are made to the attack algorithm, those based upon graph attention networks and self-supervised learning are reassuringly robust. The focus upon training data generated with different attack algorithms might not be sufficient on its own to ensure generaliability; some form of spoofing attack augmentation at the algorithm level can be complementary.
SynVox2: Towards a privacy-friendly VoxCeleb2 dataset
Sep 12, 2023
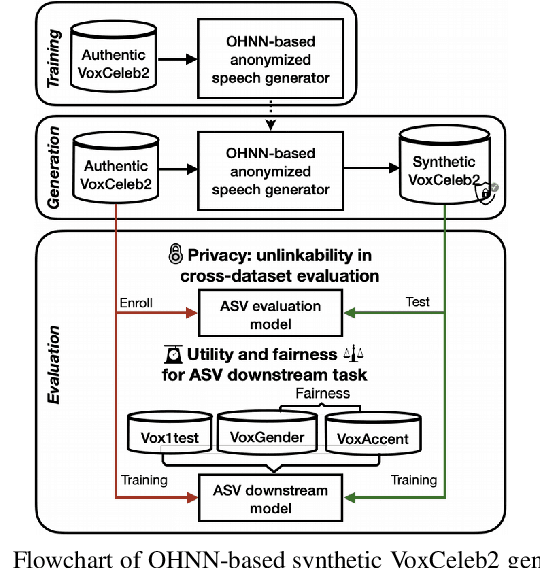
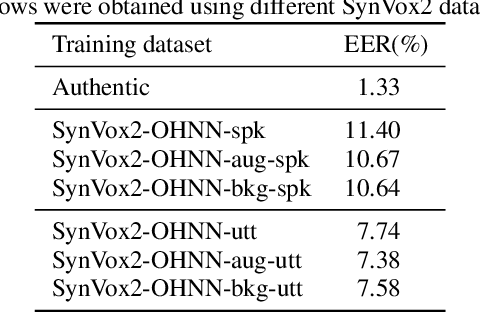
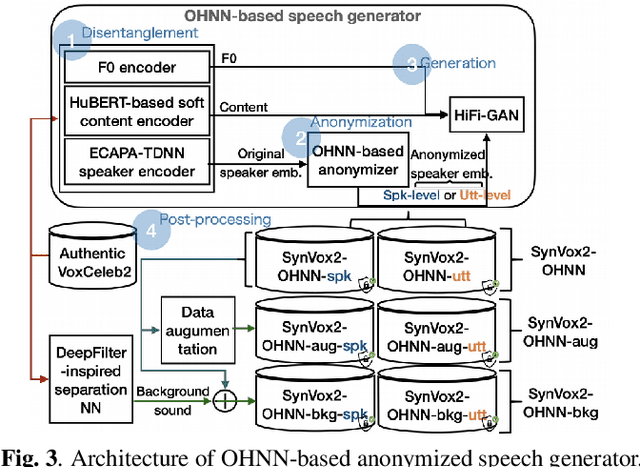
The success of deep learning in speaker recognition relies heavily on the use of large datasets. However, the data-hungry nature of deep learning methods has already being questioned on account the ethical, privacy, and legal concerns that arise when using large-scale datasets of natural speech collected from real human speakers. For example, the widely-used VoxCeleb2 dataset for speaker recognition is no longer accessible from the official website. To mitigate these concerns, this work presents an initiative to generate a privacy-friendly synthetic VoxCeleb2 dataset that ensures the quality of the generated speech in terms of privacy, utility, and fairness. We also discuss the challenges of using synthetic data for the downstream task of speaker verification.
Fairness and Privacy in Voice Biometrics:A Study of Gender Influences Using wav2vec 2.0
Aug 27, 2023This study investigates the impact of gender information on utility, privacy, and fairness in voice biometric systems, guided by the General Data Protection Regulation (GDPR) mandates, which underscore the need for minimizing the processing and storage of private and sensitive data, and ensuring fairness in automated decision-making systems. We adopt an approach that involves the fine-tuning of the wav2vec 2.0 model for speaker verification tasks, evaluating potential gender-related privacy vulnerabilities in the process. Gender influences during the fine-tuning process were employed to enhance fairness and privacy in order to emphasise or obscure gender information within the speakers' embeddings. Results from VoxCeleb datasets indicate our adversarial model increases privacy against uninformed attacks, yet slightly diminishes speaker verification performance compared to the non-adversarial model. However, the model's efficacy reduces against informed attacks. Analysis of system performance was conducted to identify potential gender biases, thus highlighting the need for further research to understand and improve the delicate interplay between utility, privacy, and equity in voice biometric systems.
Vocoder drift compensation by x-vector alignment in speaker anonymisation
Jul 17, 2023



For the most popular x-vector-based approaches to speaker anonymisation, the bulk of the anonymisation can stem from vocoding rather than from the core anonymisation function which is used to substitute an original speaker x-vector with that of a fictitious pseudo-speaker. This phenomenon can impede the design of better anonymisation systems since there is a lack of fine-grained control over the x-vector space. The work reported in this paper explores the origin of so-called vocoder drift and shows that it is due to the mismatch between the substituted x-vector and the original representations of the linguistic content, intonation and prosody. Also reported is an original approach to vocoder drift compensation. While anonymisation performance degrades as expected, compensation reduces vocoder drift substantially, offers improved control over the x-vector space and lays a foundation for the design of better anonymisation functions in the future.
Malafide: a novel adversarial convolutive noise attack against deepfake and spoofing detection systems
Jun 13, 2023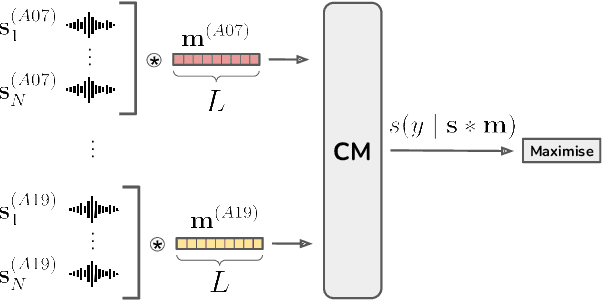
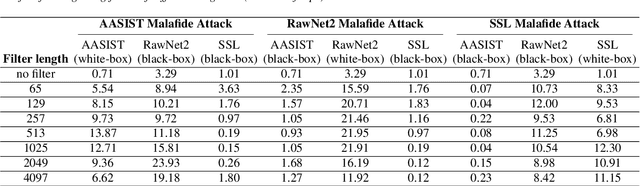
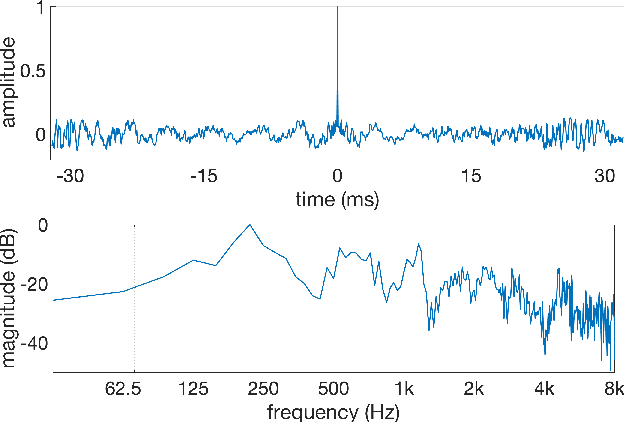

We present Malafide, a universal adversarial attack against automatic speaker verification (ASV) spoofing countermeasures (CMs). By introducing convolutional noise using an optimised linear time-invariant filter, Malafide attacks can be used to compromise CM reliability while preserving other speech attributes such as quality and the speaker's voice. In contrast to other adversarial attacks proposed recently, Malafide filters are optimised independently of the input utterance and duration, are tuned instead to the underlying spoofing attack, and require the optimisation of only a small number of filter coefficients. Even so, they degrade CM performance estimates by an order of magnitude, even in black-box settings, and can also be configured to overcome integrated CM and ASV subsystems. Integrated solutions that use self-supervised learning CMs, however, are more robust, under both black-box and white-box settings.