 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHan Lin
MMT-Bench: A Comprehensive Multimodal Benchmark for Evaluating Large Vision-Language Models Towards Multitask AGI
Apr 24, 2024
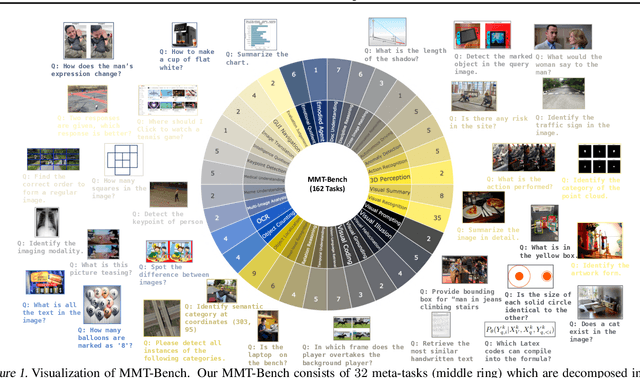

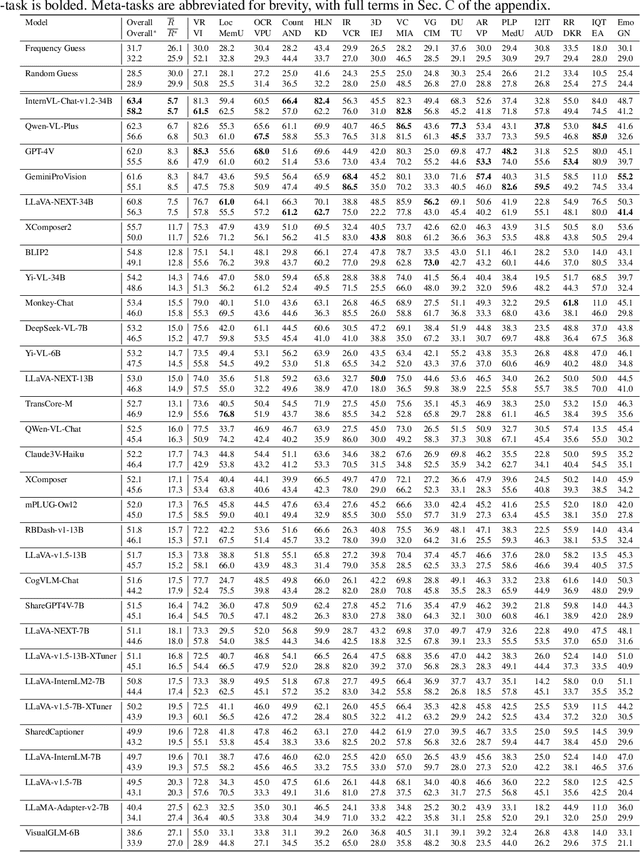
Large Vision-Language Models (LVLMs) show significant strides in general-purpose multimodal applications such as visual dialogue and embodied navigation. However, existing multimodal evaluation benchmarks cover a limited number of multimodal tasks testing rudimentary capabilities, falling short in tracking LVLM development. In this study, we present MMT-Bench, a comprehensive benchmark designed to assess LVLMs across massive multimodal tasks requiring expert knowledge and deliberate visual recognition, localization, reasoning, and planning. MMT-Bench comprises $31,325$ meticulously curated multi-choice visual questions from various multimodal scenarios such as vehicle driving and embodied navigation, covering $32$ core meta-tasks and $162$ subtasks in multimodal understanding. Due to its extensive task coverage, MMT-Bench enables the evaluation of LVLMs using a task map, facilitating the discovery of in- and out-of-domain tasks. Evaluation results involving $30$ LVLMs such as the proprietary GPT-4V, GeminiProVision, and open-sourced InternVL-Chat, underscore the significant challenges posed by MMT-Bench. We anticipate that MMT-Bench will inspire the community to develop next-generation multimodal foundation models aimed at achieving general-purpose multimodal intelligence.
Ctrl-Adapter: An Efficient and Versatile Framework for Adapting Diverse Controls to Any Diffusion Model
Apr 15, 2024ControlNets are widely used for adding spatial control in image generation with different conditions, such as depth maps, canny edges, and human poses. However, there are several challenges when leveraging the pretrained image ControlNets for controlled video generation. First, pretrained ControlNet cannot be directly plugged into new backbone models due to the mismatch of feature spaces, and the cost of training ControlNets for new backbones is a big burden. Second, ControlNet features for different frames might not effectively handle the temporal consistency. To address these challenges, we introduce Ctrl-Adapter, an efficient and versatile framework that adds diverse controls to any image/video diffusion models, by adapting pretrained ControlNets (and improving temporal alignment for videos). Ctrl-Adapter provides diverse capabilities including image control, video control, video control with sparse frames, multi-condition control, compatibility with different backbones, adaptation to unseen control conditions, and video editing. In Ctrl-Adapter, we train adapter layers that fuse pretrained ControlNet features to different image/video diffusion models, while keeping the parameters of the ControlNets and the diffusion models frozen. Ctrl-Adapter consists of temporal and spatial modules so that it can effectively handle the temporal consistency of videos. We also propose latent skipping and inverse timestep sampling for robust adaptation and sparse control. Moreover, Ctrl-Adapter enables control from multiple conditions by simply taking the (weighted) average of ControlNet outputs. With diverse image/video diffusion backbones (SDXL, Hotshot-XL, I2VGen-XL, and SVD), Ctrl-Adapter matches ControlNet for image control and outperforms all baselines for video control (achieving the SOTA accuracy on the DAVIS 2017 dataset) with significantly lower computational costs (less than 10 GPU hours).
EnvGen: Generating and Adapting Environments via LLMs for Training Embodied Agents
Mar 18, 2024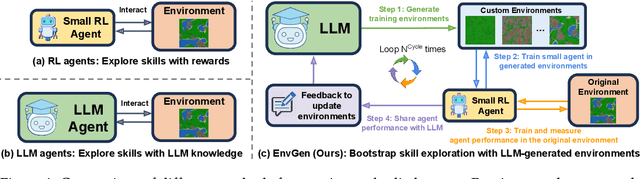

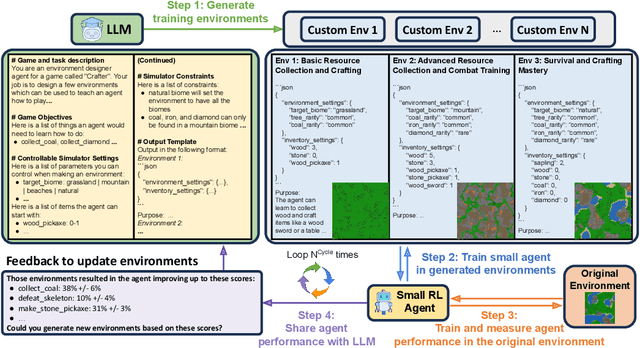

Recent SOTA approaches for embodied learning via interaction directly employ large language models (LLMs) as agents to determine the next steps in an environment. Due to their world knowledge and reasoning capabilities, LLM agents achieve stronger performance than previous smaller agents based on reinforcement learning (RL); however, frequently calling LLMs is slow and expensive. Instead of directly employing LLMs as agents, can we use LLMs' reasoning capabilities to adaptively create training environments to help smaller embodied RL agents learn useful skills that they are weak at? We propose EnvGen, a novel framework to address this question. First, we prompt an LLM to generate training environments that allow agents to quickly learn different tasks in parallel. Concretely, the LLM is given the task description and simulator objectives that the agents should learn and is then asked to generate a set of environment configurations (e.g., different terrains, items given to agents, etc.). Next, we train a small RL agent in a mixture of the original and LLM-generated environments. Then, we enable the LLM to continuously adapt the generated environments to progressively improve the skills that the agent is weak at, by providing feedback to the LLM in the form of the agent's performance. We demonstrate the usefulness of EnvGen with comprehensive experiments in Crafter and Heist environments. We find that a small RL agent trained with EnvGen can outperform SOTA methods, including a GPT-4 agent, and learns long-horizon tasks significantly faster. We show qualitatively how the LLM adapts training environments to help improve RL agents' weaker skills over time. Additionally, EnvGen is substantially more efficient as it only uses a small number of LLM calls (e.g., 4 in total), whereas LLM agents require thousands of LLM calls. Lastly, we present detailed ablation studies for our design choices.
DiagrammerGPT: Generating Open-Domain, Open-Platform Diagrams via LLM Planning
Oct 18, 2023Text-to-image (T2I) generation has seen significant growth over the past few years. Despite this, there has been little work on generating diagrams with T2I models. A diagram is a symbolic/schematic representation that explains information using structurally rich and spatially complex visualizations (e.g., a dense combination of related objects, text labels, directional arrows, connection lines, etc.). Existing state-of-the-art T2I models often fail at diagram generation because they lack fine-grained object layout control when many objects are densely connected via complex relations such as arrows/lines and also often fail to render comprehensible text labels. To address this gap, we present DiagrammerGPT, a novel two-stage text-to-diagram generation framework that leverages the layout guidance capabilities of LLMs (e.g., GPT-4) to generate more accurate open-domain, open-platform diagrams. In the first stage, we use LLMs to generate and iteratively refine 'diagram plans' (in a planner-auditor feedback loop) which describe all the entities (objects and text labels), their relationships (arrows or lines), and their bounding box layouts. In the second stage, we use a diagram generator, DiagramGLIGEN, and a text label rendering module to generate diagrams following the diagram plans. To benchmark the text-to-diagram generation task, we introduce AI2D-Caption, a densely annotated diagram dataset built on top of the AI2D dataset. We show quantitatively and qualitatively that our DiagrammerGPT framework produces more accurate diagrams, outperforming existing T2I models. We also provide comprehensive analysis including open-domain diagram generation, vector graphic diagram generation in different platforms, human-in-the-loop diagram plan editing, and multimodal planner/auditor LLMs (e.g., GPT-4Vision). We hope our work can inspire further research on diagram generation via T2I models and LLMs.
VideoDirectorGPT: Consistent Multi-scene Video Generation via LLM-Guided Planning
Sep 26, 2023

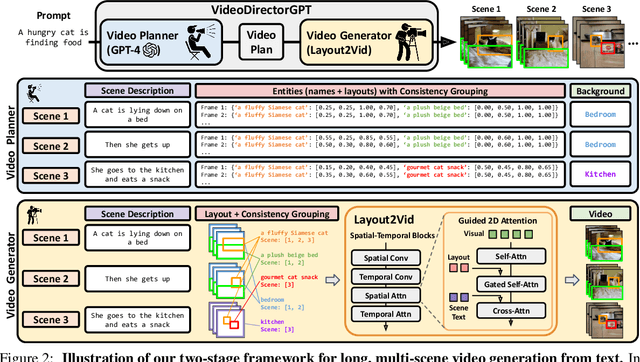
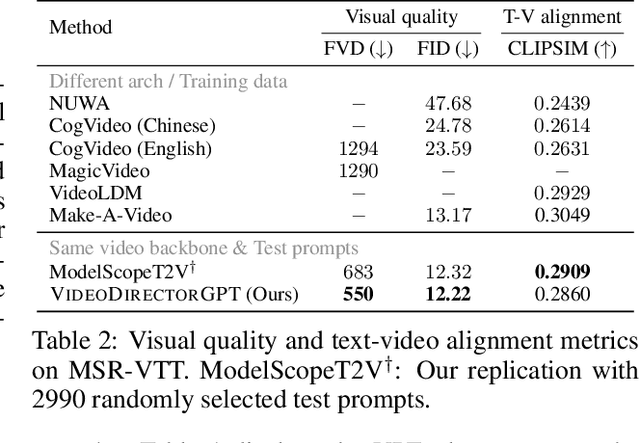
Although recent text-to-video (T2V) generation methods have seen significant advancements, most of these works focus on producing short video clips of a single event with a single background (i.e., single-scene videos). Meanwhile, recent large language models (LLMs) have demonstrated their capability in generating layouts and programs to control downstream visual modules such as image generation models. This raises an important question: can we leverage the knowledge embedded in these LLMs for temporally consistent long video generation? In this paper, we propose VideoDirectorGPT, a novel framework for consistent multi-scene video generation that uses the knowledge of LLMs for video content planning and grounded video generation. Specifically, given a single text prompt, we first ask our video planner LLM (GPT-4) to expand it into a 'video plan', which involves generating the scene descriptions, the entities with their respective layouts, the background for each scene, and consistency groupings of the entities and backgrounds. Next, guided by this output from the video planner, our video generator, Layout2Vid, has explicit control over spatial layouts and can maintain temporal consistency of entities/backgrounds across scenes, while only trained with image-level annotations. Our experiments demonstrate that VideoDirectorGPT framework substantially improves layout and movement control in both single- and multi-scene video generation and can generate multi-scene videos with visual consistency across scenes, while achieving competitive performance with SOTAs in open-domain single-scene T2V generation. We also demonstrate that our framework can dynamically control the strength for layout guidance and can also generate videos with user-provided images. We hope our framework can inspire future work on better integrating the planning ability of LLMs into consistent long video generation.
Supervised Masked Knowledge Distillation for Few-Shot Transformers
Mar 29, 2023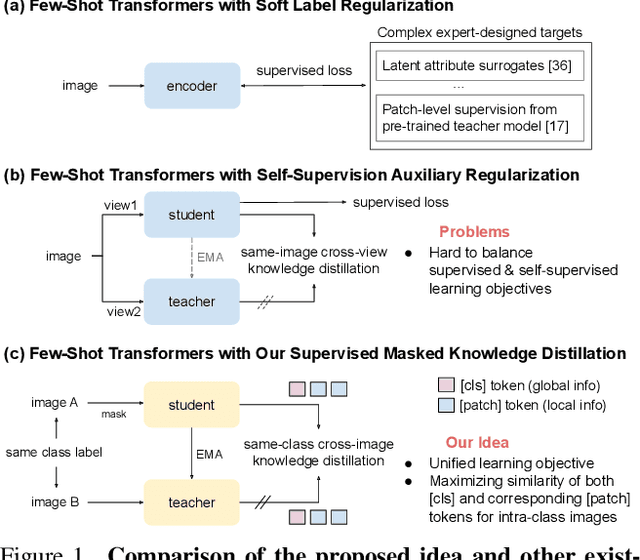
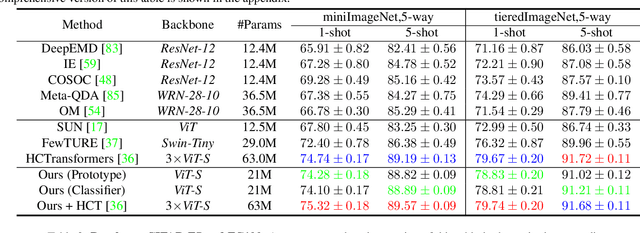

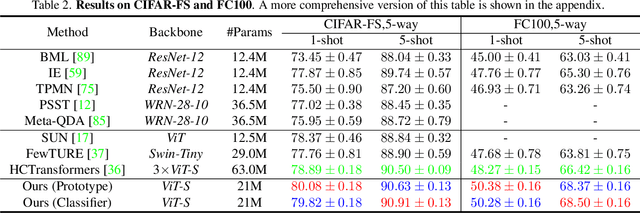
Vision Transformers (ViTs) emerge to achieve impressive performance on many data-abundant computer vision tasks by capturing long-range dependencies among local features. However, under few-shot learning (FSL) settings on small datasets with only a few labeled data, ViT tends to overfit and suffers from severe performance degradation due to its absence of CNN-alike inductive bias. Previous works in FSL avoid such problem either through the help of self-supervised auxiliary losses, or through the dextile uses of label information under supervised settings. But the gap between self-supervised and supervised few-shot Transformers is still unfilled. Inspired by recent advances in self-supervised knowledge distillation and masked image modeling (MIM), we propose a novel Supervised Masked Knowledge Distillation model (SMKD) for few-shot Transformers which incorporates label information into self-distillation frameworks. Compared with previous self-supervised methods, we allow intra-class knowledge distillation on both class and patch tokens, and introduce the challenging task of masked patch tokens reconstruction across intra-class images. Experimental results on four few-shot classification benchmark datasets show that our method with simple design outperforms previous methods by a large margin and achieves a new start-of-the-art. Detailed ablation studies confirm the effectiveness of each component of our model. Code for this paper is available here: https://github.com/HL-hanlin/SMKD.
Efficient Graph Field Integrators Meet Point Clouds
Feb 05, 2023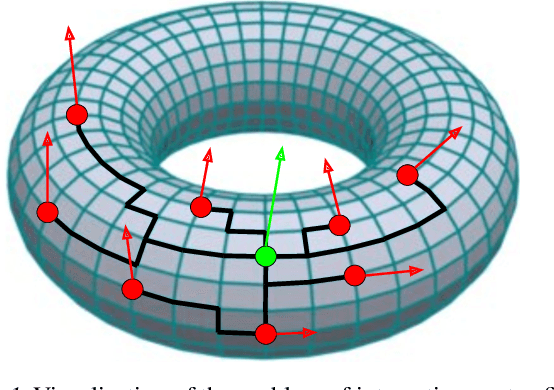

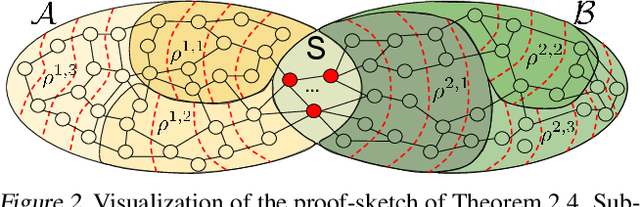
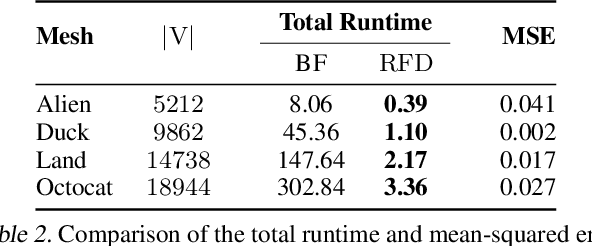
We present two new classes of algorithms for efficient field integration on graphs encoding point clouds. The first class, SeparatorFactorization(SF), leverages the bounded genus of point cloud mesh graphs, while the second class, RFDiffusion(RFD), uses popular epsilon-nearest-neighbor graph representations for point clouds. Both can be viewed as providing the functionality of Fast Multipole Methods (FMMs), which have had a tremendous impact on efficient integration, but for non-Euclidean spaces. We focus on geometries induced by distributions of walk lengths between points (e.g., shortest-path distance). We provide an extensive theoretical analysis of our algorithms, obtaining new results in structural graph theory as a byproduct. We also perform exhaustive empirical evaluation, including on-surface interpolation for rigid and deformable objects (particularly for mesh-dynamics modeling), Wasserstein distance computations for point clouds, and the Gromov-Wasserstein variant.
Self-supervised Learning for Segmentation and Quantification of Dopamine Neurons in $\text{Parkinson's Disease}$
Jan 11, 2023



$\text{Parkinson's Disease}$ (PD) is the second most common neurodegenerative disease in humans. PD is characterized by the gradual loss of dopaminergic neurons in the Substantia Nigra (a part of the mid-brain). Counting the number of dopaminergic neurons in the Substantia Nigra is one of the most important indexes in evaluating drug efficacy in PD animal models. Currently, analyzing and quantifying dopaminergic neurons is conducted manually by experts through analysis of digital pathology images which is laborious, time-consuming, and highly subjective. As such, a reliable and unbiased automated system is demanded for the quantification of dopaminergic neurons in digital pathology images. We propose an end-to-end deep learning framework for the segmentation and quantification of dopaminergic neurons in PD animal models. To the best of knowledge, this is the first machine learning model that detects the cell body of dopaminergic neurons, counts the number of dopaminergic neurons and provides the phenotypic characteristics of individual dopaminergic neurons as a numerical output. Extensive experiments demonstrate the effectiveness of our model in quantifying neurons with a high precision, which can provide quicker turnaround for drug efficacy studies, better understanding of dopaminergic neuronal health status and unbiased results in PD pre-clinical research.
TANDEM3D: Active Tactile Exploration for 3D Object Recognition
Sep 19, 2022



Tactile recognition of 3D objects remains a challenging task. Compared to 2D shapes, the complex geometry of 3D surfaces requires richer tactile signals, more dexterous actions, and more advanced encoding techniques. In this work, we propose TANDEM3D, a method that applies a co-training framework for exploration and decision making to 3D object recognition with tactile signals. Starting with our previous work, which introduced a co-training paradigm for 2D recognition problems, we introduce a number of advances that enable us to scale up to 3D. TANDEM3D is based on a novel encoder that builds 3D object representation from contact positions and normals using PointNet++. Furthermore, by enabling 6DOF movement, TANDEM3D explores and collects discriminative touch information with high efficiency. Our method is trained entirely in simulation and validated with real-world experiments. Compared to state-of-the-art baselines, TANDEM3D achieves higher accuracy and a lower number of actions in recognizing 3D objects and is also shown to be more robust to different types and amounts of sensor noise. Video is available at https://jxu.ai/tandem3d.
Hybrid Random Features
Oct 13, 2021
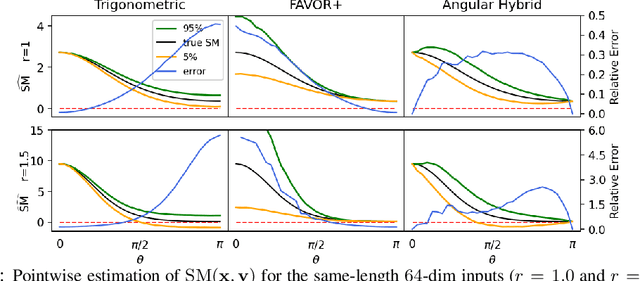
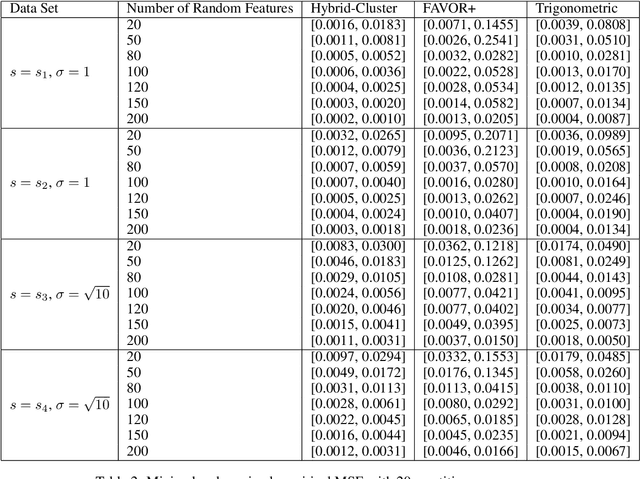
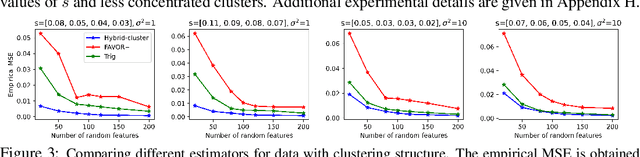
We propose a new class of random feature methods for linearizing softmax and Gaussian kernels called hybrid random features (HRFs) that automatically adapt the quality of kernel estimation to provide most accurate approximation in the defined regions of interest. Special instantiations of HRFs lead to well-known methods such as trigonometric (Rahimi and Recht, 2007) or (recently introduced in the context of linear-attention Transformers) positive random features (Choromanski et al., 2021). By generalizing Bochner's Theorem for softmax/Gaussian kernels and leveraging random features for compositional kernels, the HRF-mechanism provides strong theoretical guarantees - unbiased approximation and strictly smaller worst-case relative errors than its counterparts. We conduct exhaustive empirical evaluation of HRF ranging from pointwise kernel estimation experiments, through tests on data admitting clustering structure to benchmarking implicit-attention Transformers (also for downstream Robotics applications), demonstrating its quality in a wide spectrum of machine learning problems.