 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLei Wu
Exploring Neural Network Landscapes: Star-Shaped and Geodesic Connectivity
Apr 09, 2024
One of the most intriguing findings in the structure of neural network landscape is the phenomenon of mode connectivity: For two typical global minima, there exists a path connecting them without barrier. This concept of mode connectivity has played a crucial role in understanding important phenomena in deep learning. In this paper, we conduct a fine-grained analysis of this connectivity phenomenon. First, we demonstrate that in the overparameterized case, the connecting path can be as simple as a two-piece linear path, and the path length can be nearly equal to the Euclidean distance. This finding suggests that the landscape should be nearly convex in a certain sense. Second, we uncover a surprising star-shaped connectivity: For a finite number of typical minima, there exists a center on minima manifold that connects all of them simultaneously via linear paths. These results are provably valid for linear networks and two-layer ReLU networks under a teacher-student setup, and are empirically supported by models trained on MNIST and CIFAR-10.
A Duality Analysis of Kernel Ridge Regression in the Noiseless Regime
Feb 24, 2024In this paper, we conduct a comprehensive analysis of generalization properties of Kernel Ridge Regression (KRR) in the noiseless regime, a scenario crucial to scientific computing, where data are often generated via computer simulations. We prove that KRR can attain the minimax optimal rate, which depends on both the eigenvalue decay of the associated kernel and the relative smoothness of target functions. Particularly, when the eigenvalue decays exponentially fast, KRR achieves the spectral accuracy, i.e., a convergence rate faster than any polynomial. Moreover, the numerical experiments well corroborate our theoretical findings. Our proof leverages a novel extension of the duality framework introduced by Chen et al. (2023), which could be useful in analyzing kernel-based methods beyond the scope of this work.
The Implicit Bias of Gradient Noise: A Symmetry Perspective
Feb 11, 2024We characterize the learning dynamics of stochastic gradient descent (SGD) when continuous symmetry exists in the loss function, where the divergence between SGD and gradient descent is dramatic. We show that depending on how the symmetry affects the learning dynamics, we can divide a family of symmetry into two classes. For one class of symmetry, SGD naturally converges to solutions that have a balanced and aligned gradient noise. For the other class of symmetry, SGD will almost always diverge. Then, we show that our result remains applicable and can help us understand the training dynamics even when the symmetry is not present in the loss function. Our main result is universal in the sense that it only depends on the existence of the symmetry and is independent of the details of the loss function. We demonstrate that the proposed theory offers an explanation of progressive sharpening and flattening and can be applied to common practical problems such as representation normalization, matrix factorization, and the use of warmup.
Achieving Margin Maximization Exponentially Fast via Progressive Norm Rescaling
Dec 08, 2023
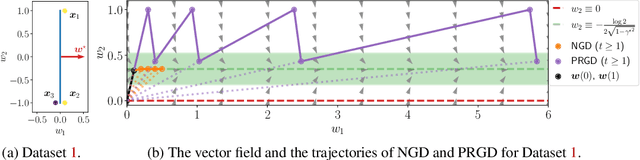
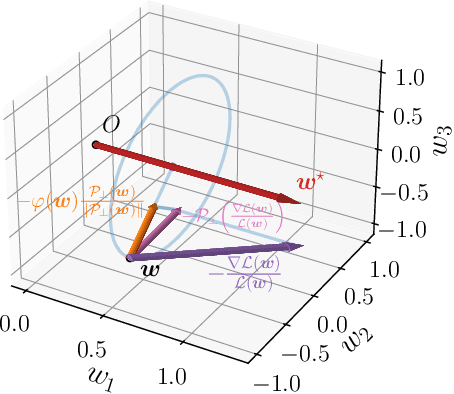

In this work, we investigate the margin-maximization bias exhibited by gradient-based algorithms in classifying linearly separable data. We present an in-depth analysis of the specific properties of the velocity field associated with (normalized) gradients, focusing on their role in margin maximization. Inspired by this analysis, we propose a novel algorithm called Progressive Rescaling Gradient Descent (PRGD) and show that PRGD can maximize the margin at an {\em exponential rate}. This stands in stark contrast to all existing algorithms, which maximize the margin at a slow {\em polynomial rate}. Specifically, we identify mild conditions on data distribution under which existing algorithms such as gradient descent (GD) and normalized gradient descent (NGD) {\em provably fail} in maximizing the margin efficiently. To validate our theoretical findings, we present both synthetic and real-world experiments. Notably, PRGD also shows promise in enhancing the generalization performance when applied to linearly non-separable datasets and deep neural networks.
The Local Landscape of Phase Retrieval Under Limited Samples
Nov 26, 2023In this paper, we provide a fine-grained analysis of the local landscape of phase retrieval under the regime with limited samples. Our aim is to ascertain the minimal sample size necessary to guarantee a benign local landscape surrounding global minima in high dimensions. Let $n$ and $d$ denote the sample size and input dimension, respectively. We first explore the local convexity and establish that when $n=o(d\log d)$, for almost every fixed point in the local ball, the Hessian matrix must have negative eigenvalues as long as $d$ is sufficiently large. Consequently, the local landscape is highly non-convex. We next consider the one-point strong convexity and show that as long as $n=\omega(d)$, with high probability, the landscape is one-point strongly convex in the local annulus: $\{w\in\mathbb{R}^d: o_d(1)\leqslant \|w-w^*\|\leqslant c\}$, where $w^*$ is the ground truth and $c$ is an absolute constant. This implies that gradient descent initialized from any point in this domain can converge to an $o_d(1)$-loss solution exponentially fast. Furthermore, we show that when $n=o(d\log d)$, there is a radius of $\widetilde\Theta\left(\sqrt{1/d}\right)$ such that one-point convexity breaks in the corresponding smaller local ball. This indicates an impossibility to establish a convergence to exact $w^*$ for gradient descent under limited samples by relying solely on one-point convexity.
The Noise Geometry of Stochastic Gradient Descent: A Quantitative and Analytical Characterization
Oct 01, 2023Empirical studies have demonstrated that the noise in stochastic gradient descent (SGD) aligns favorably with the local geometry of loss landscape. However, theoretical and quantitative explanations for this phenomenon remain sparse. In this paper, we offer a comprehensive theoretical investigation into the aforementioned {\em noise geometry} for over-parameterized linear (OLMs) models and two-layer neural networks. We scrutinize both average and directional alignments, paying special attention to how factors like sample size and input data degeneracy affect the alignment strength. As a specific application, we leverage our noise geometry characterizations to study how SGD escapes from sharp minima, revealing that the escape direction has significant components along flat directions. This is in stark contrast to GD, which escapes only along the sharpest directions. To substantiate our theoretical findings, both synthetic and real-world experiments are provided.
9DTact: A Compact Vision-Based Tactile Sensor for Accurate 3D Shape Reconstruction and Generalizable 6D Force Estimation
Aug 28, 2023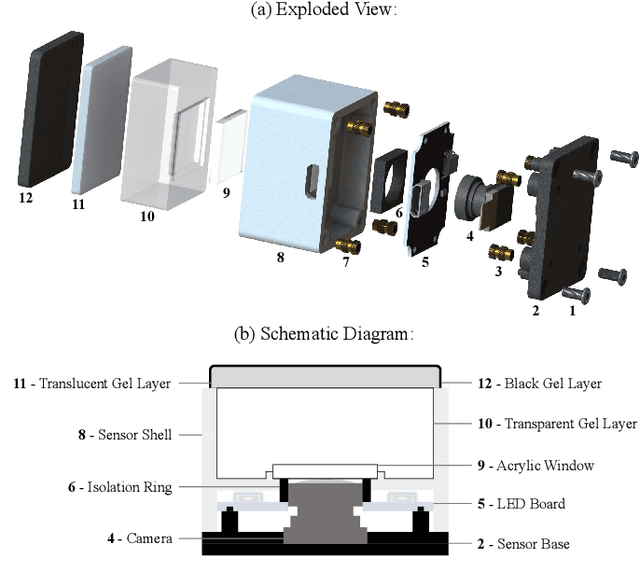

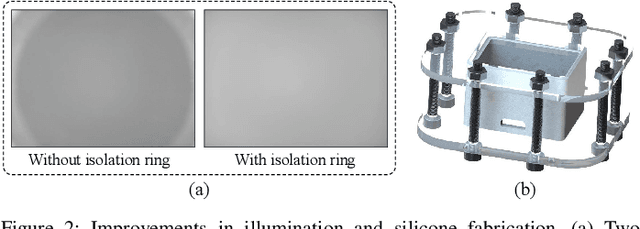
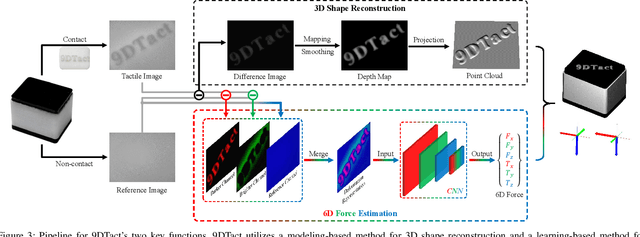
The advancements in vision-based tactile sensors have boosted the aptitude of robots to perform contact-rich manipulation, particularly when precise positioning and contact state of the manipulated objects are crucial for successful execution. In this work, we present 9DTact, a straightforward yet versatile tactile sensor that offers 3D shape reconstruction and 6D force estimation capabilities. Conceptually, 9DTact is designed to be highly compact, robust, and adaptable to various robotic platforms. Moreover, it is low-cost and DIY-friendly, requiring minimal assembly skills. Functionally, 9DTact builds upon the optical principles of DTact and is optimized to achieve 3D shape reconstruction with enhanced accuracy and efficiency. Remarkably, we leverage the optical and deformable properties of the translucent gel so that 9DTact can perform 6D force estimation without the participation of auxiliary markers or patterns on the gel surface. More specifically, we collect a dataset consisting of approximately 100,000 image-force pairs from 175 complex objects and train a neural network to regress the 6D force, which can generalize to unseen objects. To promote the development and applications of vision-based tactile sensors, we open-source both the hardware and software of 9DTact as well as present a 1-hour video tutorial.
The $L^\infty$ Learnability of Reproducing Kernel Hilbert Spaces
Jun 05, 2023In this work, we analyze the learnability of reproducing kernel Hilbert spaces (RKHS) under the $L^\infty$ norm, which is critical for understanding the performance of kernel methods and random feature models in safety- and security-critical applications. Specifically, we relate the $L^\infty$ learnability of a RKHS to the spectrum decay of the associate kernel and both lower bounds and upper bounds of the sample complexity are established. In particular, for dot-product kernels on the sphere, we identify conditions when the $L^\infty$ learning can be achieved with polynomial samples. Let $d$ denote the input dimension and assume the kernel spectrum roughly decays as $\lambda_k\sim k^{-1-\beta}$ with $\beta>0$. We prove that if $\beta$ is independent of the input dimension $d$, then functions in the RKHS can be learned efficiently under the $L^\infty$ norm, i.e., the sample complexity depends polynomially on $d$. In contrast, if $\beta=1/\mathrm{poly}(d)$, then the $L^\infty$ learning requires exponentially many samples.
The Implicit Regularization of Dynamical Stability in Stochastic Gradient Descent
Jun 01, 2023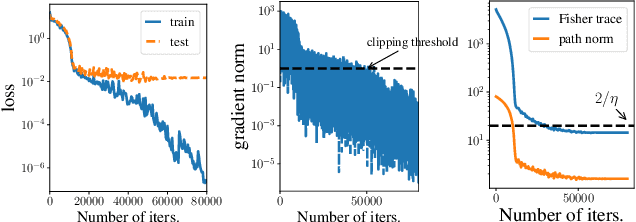
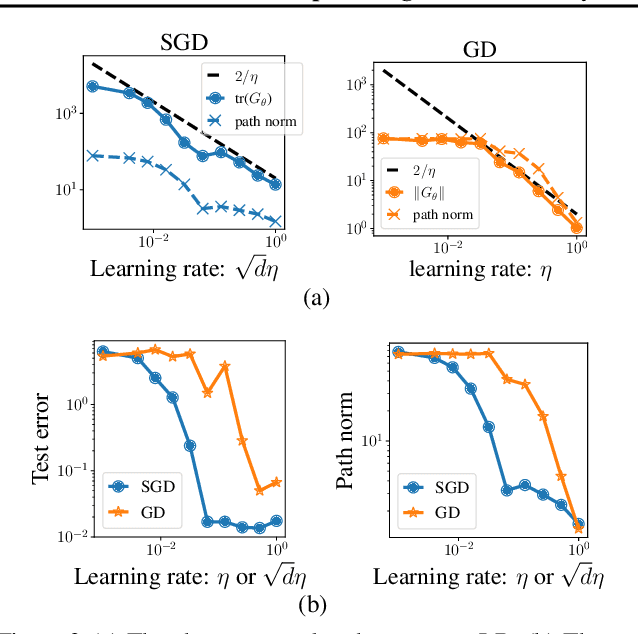

In this paper, we study the implicit regularization of stochastic gradient descent (SGD) through the lens of {\em dynamical stability} (Wu et al., 2018). We start by revising existing stability analyses of SGD, showing how the Frobenius norm and trace of Hessian relate to different notions of stability. Notably, if a global minimum is linearly stable for SGD, then the trace of Hessian must be less than or equal to $2/\eta$, where $\eta$ denotes the learning rate. By contrast, for gradient descent (GD), the stability imposes a similar constraint but only on the largest eigenvalue of Hessian. We then turn to analyze the generalization properties of these stable minima, focusing specifically on two-layer ReLU networks and diagonal linear networks. Notably, we establish the {\em equivalence} between these metrics of sharpness and certain parameter norms for the two models, which allows us to show that the stable minima of SGD provably generalize well. By contrast, the stability-induced regularization of GD is provably too weak to ensure satisfactory generalization. This discrepancy provides an explanation of why SGD often generalizes better than GD. Note that the learning rate (LR) plays a pivotal role in the strength of stability-induced regularization. As the LR increases, the regularization effect becomes more pronounced, elucidating why SGD with a larger LR consistently demonstrates superior generalization capabilities. Additionally, numerical experiments are provided to support our theoretical findings.
The Brain Tumor Segmentation (BraTS-METS) Challenge 2023: Brain Metastasis Segmentation on Pre-treatment MRI
Jun 01, 2023
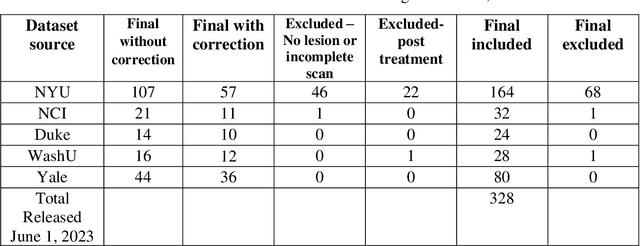
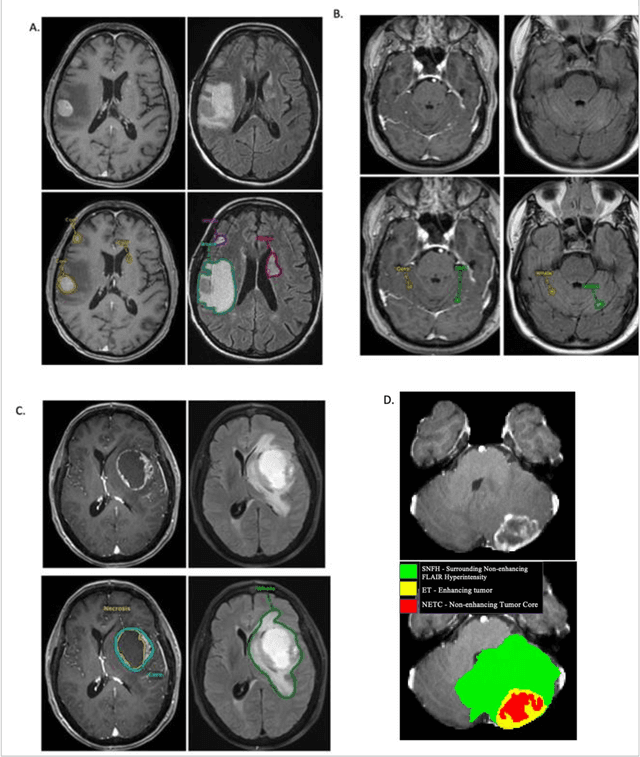
Clinical monitoring of metastatic disease to the brain can be a laborious and time-consuming process, especially in cases involving multiple metastases when the assessment is performed manually. The Response Assessment in Neuro-Oncology Brain Metastases (RANO-BM) guideline, which utilizes the unidimensional longest diameter, is commonly used in clinical and research settings to evaluate response to therapy in patients with brain metastases. However, accurate volumetric assessment of the lesion and surrounding peri-lesional edema holds significant importance in clinical decision-making and can greatly enhance outcome prediction. The unique challenge in performing segmentations of brain metastases lies in their common occurrence as small lesions. Detection and segmentation of lesions that are smaller than 10 mm in size has not demonstrated high accuracy in prior publications. The brain metastases challenge sets itself apart from previously conducted MICCAI challenges on glioma segmentation due to the significant variability in lesion size. Unlike gliomas, which tend to be larger on presentation scans, brain metastases exhibit a wide range of sizes and tend to include small lesions. We hope that the BraTS-METS dataset and challenge will advance the field of automated brain metastasis detection and segmentation.