 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDingkang Yang
Multi-Scale Heterogeneity-Aware Hypergraph Representation for Histopathology Whole Slide Images
Apr 30, 2024
Survival prediction is a complex ordinal regression task that aims to predict the survival coefficient ranking among a cohort of patients, typically achieved by analyzing patients' whole slide images. Existing deep learning approaches mainly adopt multiple instance learning or graph neural networks under weak supervision. Most of them are unable to uncover the diverse interactions between different types of biological entities(\textit{e.g.}, cell cluster and tissue block) across multiple scales, while such interactions are crucial for patient survival prediction. In light of this, we propose a novel multi-scale heterogeneity-aware hypergraph representation framework. Specifically, our framework first constructs a multi-scale heterogeneity-aware hypergraph and assigns each node with its biological entity type. It then mines diverse interactions between nodes on the graph structure to obtain a global representation. Experimental results demonstrate that our method outperforms state-of-the-art approaches on three benchmark datasets. Code is publicly available at \href{https://github.com/Hanminghao/H2GT}{https://github.com/Hanminghao/H2GT}.
Efficiency in Focus: LayerNorm as a Catalyst for Fine-tuning Medical Visual Language Pre-trained Models
Apr 25, 2024In the realm of Medical Visual Language Models (Med-VLMs), the quest for universal efficient fine-tuning mechanisms remains paramount, especially given researchers in interdisciplinary fields are often extremely short of training resources, yet largely unexplored. Given the unique challenges in the medical domain, such as limited data scope and significant domain-specific requirements, evaluating and adapting Parameter-Efficient Fine-Tuning (PEFT) methods specifically for Med-VLMs is essential. Most of the current PEFT methods on Med-VLMs have yet to be comprehensively investigated but mainly focus on adding some components to the model's structure or input. However, fine-tuning intrinsic model components often yields better generality and consistency, and its impact on the ultimate performance of Med-VLMs has been widely overlooked and remains understudied. In this paper, we endeavour to explore an alternative to traditional PEFT methods, especially the impact of fine-tuning LayerNorm layers, FFNs and Attention layers on the Med-VLMs. Our comprehensive studies span both small-scale and large-scale Med-VLMs, evaluating their performance under various fine-tuning paradigms across tasks such as Medical Visual Question Answering and Medical Imaging Report Generation. The findings reveal unique insights into the effects of intrinsic parameter fine-tuning methods on fine-tuning Med-VLMs to downstream tasks and expose fine-tuning solely the LayerNorm layers not only surpasses the efficiency of traditional PEFT methods but also retains the model's accuracy and generalization capabilities across a spectrum of medical downstream tasks. The experiments show LayerNorm fine-tuning's superior adaptability and scalability, particularly in the context of large-scale Med-VLMs.
Correlation-Decoupled Knowledge Distillation for Multimodal Sentiment Analysis with Incomplete Modalities
Apr 25, 2024Multimodal sentiment analysis (MSA) aims to understand human sentiment through multimodal data. Most MSA efforts are based on the assumption of modality completeness. However, in real-world applications, some practical factors cause uncertain modality missingness, which drastically degrades the model's performance. To this end, we propose a Correlation-decoupled Knowledge Distillation (CorrKD) framework for the MSA task under uncertain missing modalities. Specifically, we present a sample-level contrastive distillation mechanism that transfers comprehensive knowledge containing cross-sample correlations to reconstruct missing semantics. Moreover, a category-guided prototype distillation mechanism is introduced to capture cross-category correlations using category prototypes to align feature distributions and generate favorable joint representations. Eventually, we design a response-disentangled consistency distillation strategy to optimize the sentiment decision boundaries of the student network through response disentanglement and mutual information maximization. Comprehensive experiments on three datasets indicate that our framework can achieve favorable improvements compared with several baselines.
De-confounded Data-free Knowledge Distillation for Handling Distribution Shifts
Mar 28, 2024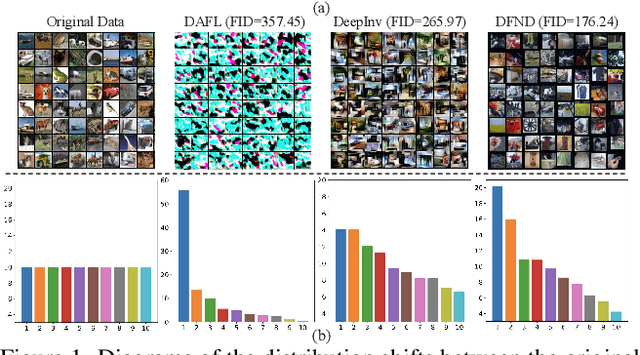
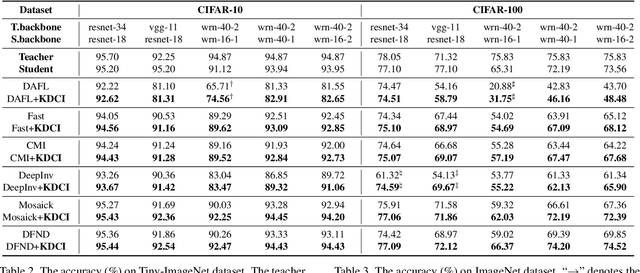
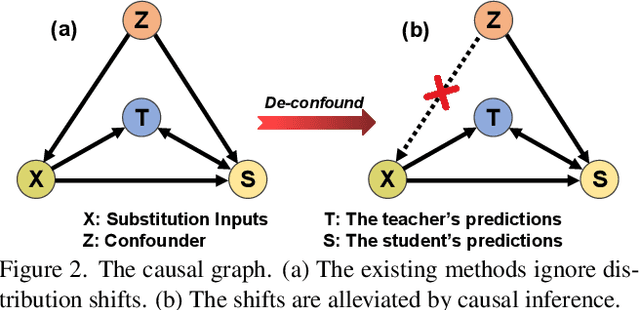
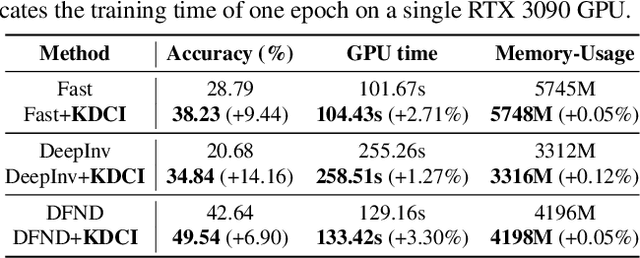
Data-Free Knowledge Distillation (DFKD) is a promising task to train high-performance small models to enhance actual deployment without relying on the original training data. Existing methods commonly avoid relying on private data by utilizing synthetic or sampled data. However, a long-overlooked issue is that the severe distribution shifts between their substitution and original data, which manifests as huge differences in the quality of images and class proportions. The harmful shifts are essentially the confounder that significantly causes performance bottlenecks. To tackle the issue, this paper proposes a novel perspective with causal inference to disentangle the student models from the impact of such shifts. By designing a customized causal graph, we first reveal the causalities among the variables in the DFKD task. Subsequently, we propose a Knowledge Distillation Causal Intervention (KDCI) framework based on the backdoor adjustment to de-confound the confounder. KDCI can be flexibly combined with most existing state-of-the-art baselines. Experiments in combination with six representative DFKD methods demonstrate the effectiveness of our KDCI, which can obviously help existing methods under almost all settings, \textit{e.g.}, improving the baseline by up to 15.54\% accuracy on the CIFAR-100 dataset.
Can LLMs' Tuning Methods Work in Medical Multimodal Domain?
Mar 11, 2024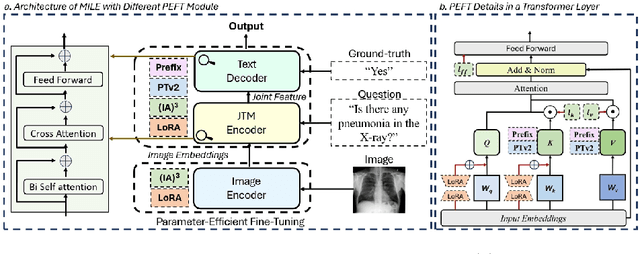
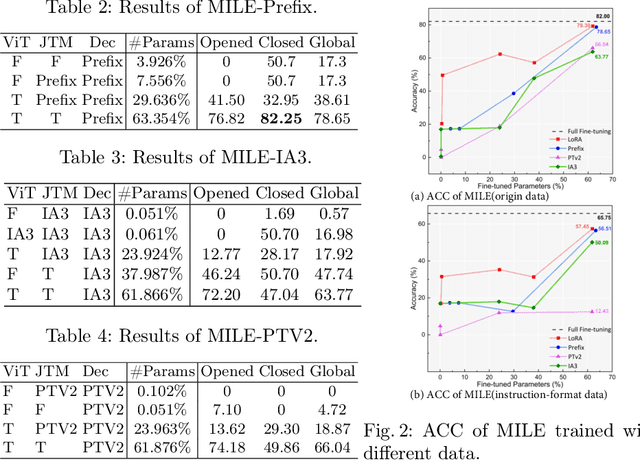
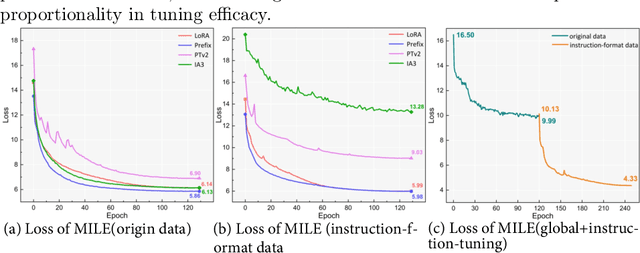
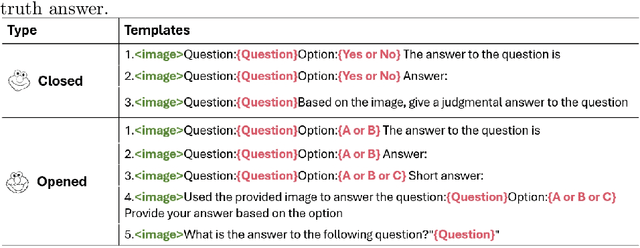
While large language models (LLMs) excel in world knowledge understanding, adapting them to specific subfields requires precise adjustments. Due to the model's vast scale, traditional global fine-tuning methods for large models can be computationally expensive and impact generalization. To address this challenge, a range of innovative Parameters-Efficient Fine-Tuning (PEFT) methods have emerged and achieved remarkable success in both LLMs and Large Vision-Language Models (LVLMs). In the medical domain, fine-tuning a medical Vision-Language Pretrained (VLP) model is essential for adapting it to specific tasks. Can the fine-tuning methods for large models be transferred to the medical field to enhance transfer learning efficiency? In this paper, we delve into the fine-tuning methods of LLMs and conduct extensive experiments to investigate the impact of fine-tuning methods for large models on existing multimodal models in the medical domain from the training data level and the model structure level. We show the different impacts of fine-tuning methods for large models on medical VLMs and develop the most efficient ways to fine-tune medical VLP models. We hope this research can guide medical domain researchers in optimizing VLMs' training costs, fostering the broader application of VLMs in healthcare fields. Code and dataset will be released upon acceptance.
Robust Emotion Recognition in Context Debiasing
Mar 09, 2024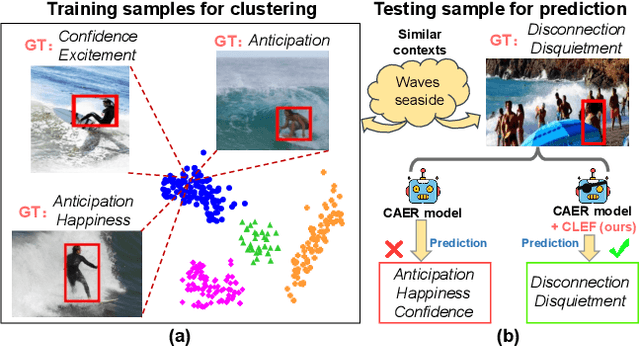
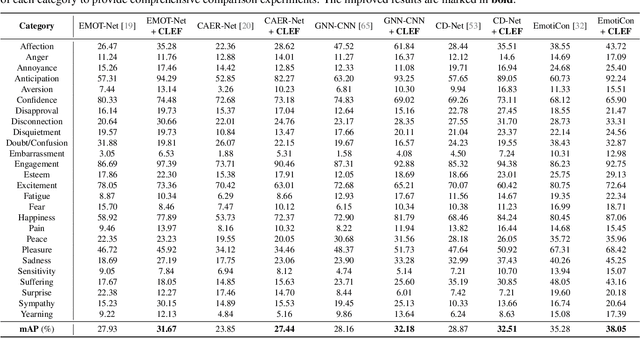
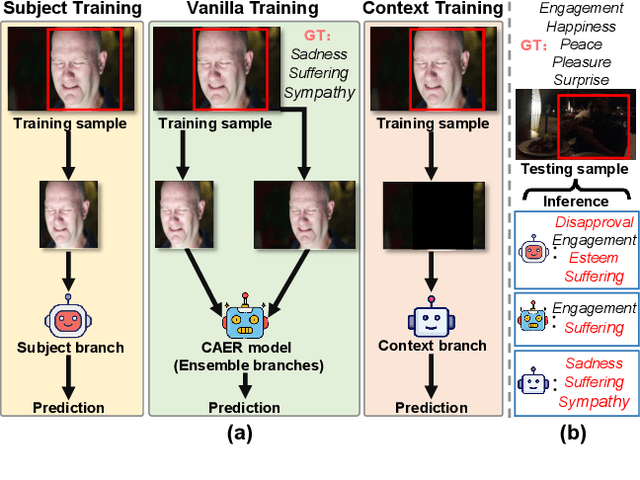
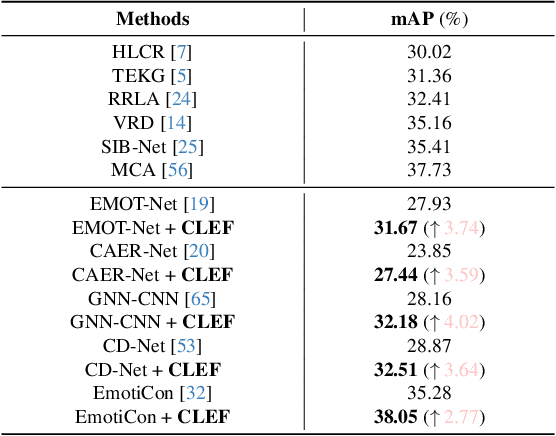
Context-aware emotion recognition (CAER) has recently boosted the practical applications of affective computing techniques in unconstrained environments. Mainstream CAER methods invariably extract ensemble representations from diverse contexts and subject-centred characteristics to perceive the target person's emotional state. Despite advancements, the biggest challenge remains due to context bias interference. The harmful bias forces the models to rely on spurious correlations between background contexts and emotion labels in likelihood estimation, causing severe performance bottlenecks and confounding valuable context priors. In this paper, we propose a counterfactual emotion inference (CLEF) framework to address the above issue. Specifically, we first formulate a generalized causal graph to decouple the causal relationships among the variables in CAER. Following the causal graph, CLEF introduces a non-invasive context branch to capture the adverse direct effect caused by the context bias. During the inference, we eliminate the direct context effect from the total causal effect by comparing factual and counterfactual outcomes, resulting in bias mitigation and robust prediction. As a model-agnostic framework, CLEF can be readily integrated into existing methods, bringing consistent performance gains.
Towards Multimodal Human Intention Understanding Debiasing via Subject-Deconfounding
Mar 08, 2024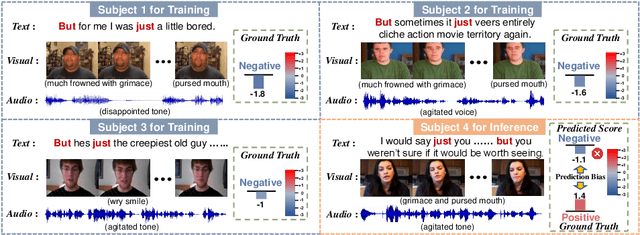
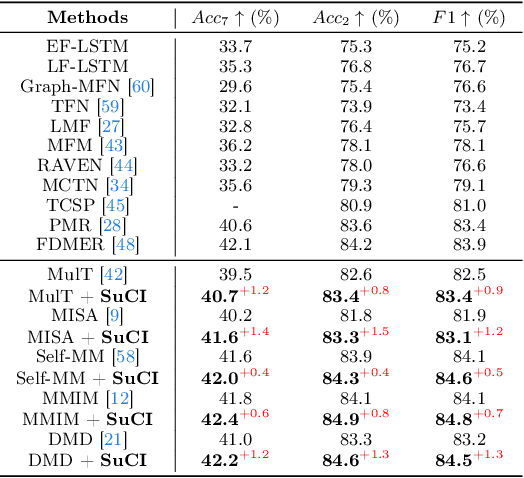
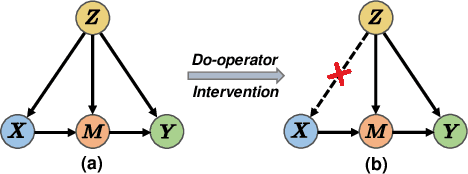
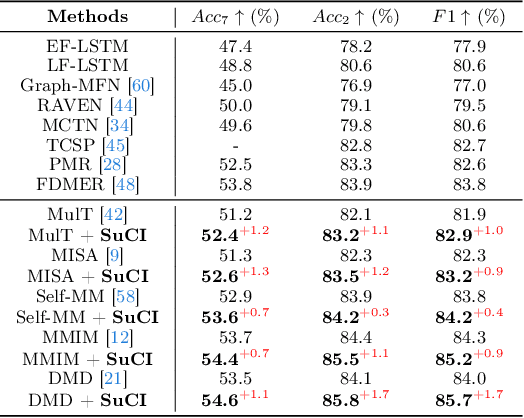
Multimodal intention understanding (MIU) is an indispensable component of human expression analysis (e.g., sentiment or humor) from heterogeneous modalities, including visual postures, linguistic contents, and acoustic behaviors. Existing works invariably focus on designing sophisticated structures or fusion strategies to achieve impressive improvements. Unfortunately, they all suffer from the subject variation problem due to data distribution discrepancies among subjects. Concretely, MIU models are easily misled by distinct subjects with different expression customs and characteristics in the training data to learn subject-specific spurious correlations, significantly limiting performance and generalizability across uninitiated subjects.Motivated by this observation, we introduce a recapitulative causal graph to formulate the MIU procedure and analyze the confounding effect of subjects. Then, we propose SuCI, a simple yet effective causal intervention module to disentangle the impact of subjects acting as unobserved confounders and achieve model training via true causal effects. As a plug-and-play component, SuCI can be widely applied to most methods that seek unbiased predictions. Comprehensive experiments on several MIU benchmarks clearly demonstrate the effectiveness of the proposed module.
Towards Multimodal Sentiment Analysis Debiasing via Bias Purification
Mar 08, 2024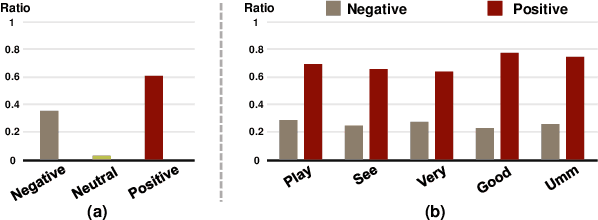
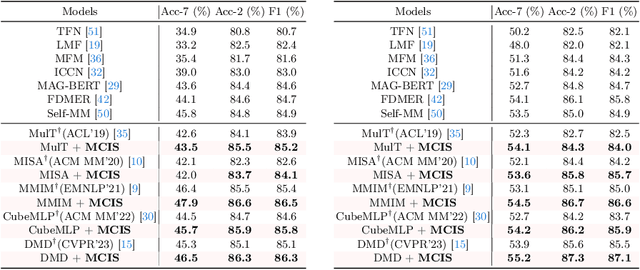
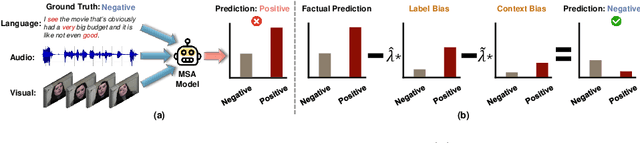
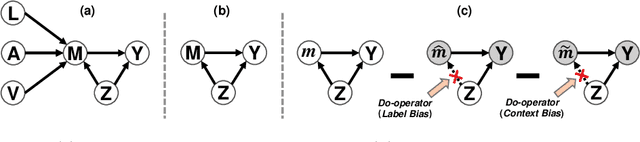
Multimodal Sentiment Analysis (MSA) aims to understand human intentions by integrating emotion-related clues from diverse modalities, such as visual, language, and audio. Unfortunately, the current MSA task invariably suffers from unplanned dataset biases, particularly multimodal utterance-level label bias and word-level context bias. These harmful biases potentially mislead models to focus on statistical shortcuts and spurious correlations, causing severe performance bottlenecks. To alleviate these issues, we present a Multimodal Counterfactual Inference Sentiment (MCIS) analysis framework based on causality rather than conventional likelihood. Concretely, we first formulate a causal graph to discover harmful biases from already-trained vanilla models. In the inference phase, given a factual multimodal input, MCIS imagines two counterfactual scenarios to purify and mitigate these biases. Then, MCIS can make unbiased decisions from biased observations by comparing factual and counterfactual outcomes. We conduct extensive experiments on several standard MSA benchmarks. Qualitative and quantitative results show the effectiveness of the proposed framework.
HandGCAT: Occlusion-Robust 3D Hand Mesh Reconstruction from Monocular Images
Feb 27, 2024
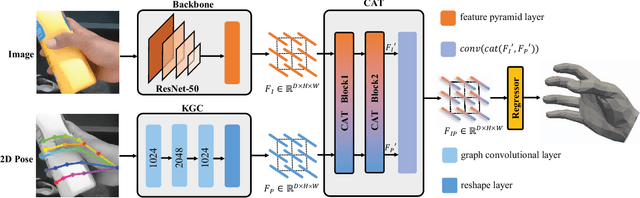
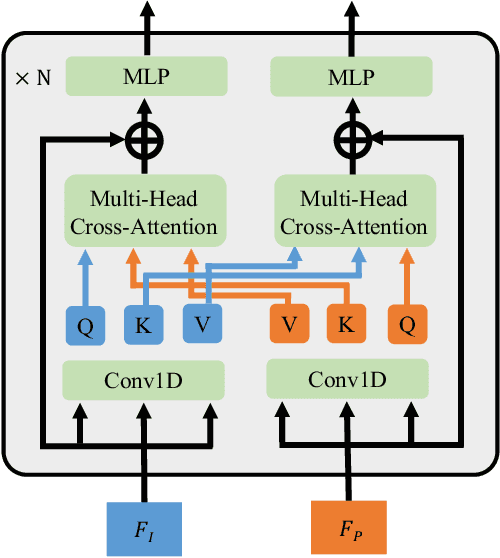

We propose a robust and accurate method for reconstructing 3D hand mesh from monocular images. This is a very challenging problem, as hands are often severely occluded by objects. Previous works often have disregarded 2D hand pose information, which contains hand prior knowledge that is strongly correlated with occluded regions. Thus, in this work, we propose a novel 3D hand mesh reconstruction network HandGCAT, that can fully exploit hand prior as compensation information to enhance occluded region features. Specifically, we designed the Knowledge-Guided Graph Convolution (KGC) module and the Cross-Attention Transformer (CAT) module. KGC extracts hand prior information from 2D hand pose by graph convolution. CAT fuses hand prior into occluded regions by considering their high correlation. Extensive experiments on popular datasets with challenging hand-object occlusions, such as HO3D v2, HO3D v3, and DexYCB demonstrate that our HandGCAT reaches state-of-the-art performance. The code is available at https://github.com/heartStrive/HandGCAT.
* 6 pages, 4 figures, ICME-2023 conference paper
Delving into Decision-based Black-box Attacks on Semantic Segmentation
Feb 02, 2024Semantic segmentation is a fundamental visual task that finds extensive deployment in applications with security-sensitive considerations. Nonetheless, recent work illustrates the adversarial vulnerability of semantic segmentation models to white-box attacks. However, its adversarial robustness against black-box attacks has not been fully explored. In this paper, we present the first exploration of black-box decision-based attacks on semantic segmentation. First, we analyze the challenges that semantic segmentation brings to decision-based attacks through the case study. Then, to address these challenges, we first propose a decision-based attack on semantic segmentation, called Discrete Linear Attack (DLA). Based on random search and proxy index, we utilize the discrete linear noises for perturbation exploration and calibration to achieve efficient attack efficiency. We conduct adversarial robustness evaluation on 5 models from Cityscapes and ADE20K under 8 attacks. DLA shows its formidable power on Cityscapes by dramatically reducing PSPNet's mIoU from an impressive 77.83% to a mere 2.14% with just 50 queries.