 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYuzheng Wang
De-confounded Data-free Knowledge Distillation for Handling Distribution Shifts
Mar 28, 2024
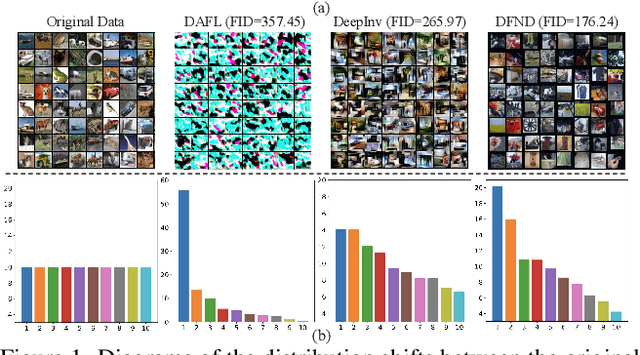
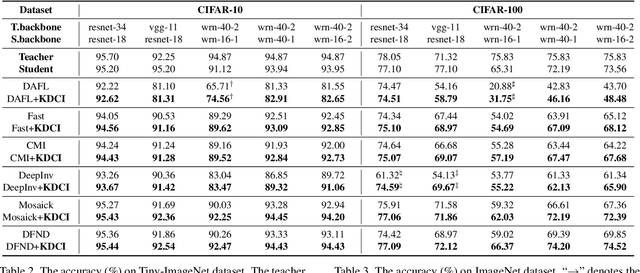
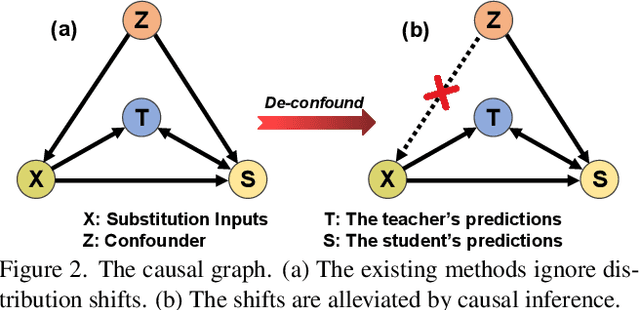
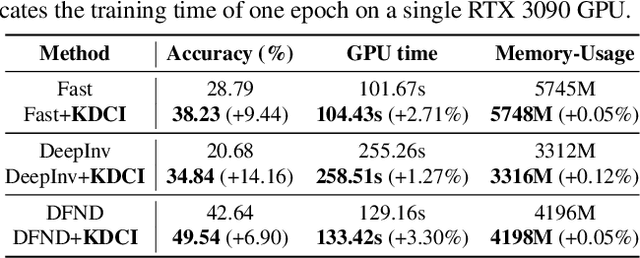
Data-Free Knowledge Distillation (DFKD) is a promising task to train high-performance small models to enhance actual deployment without relying on the original training data. Existing methods commonly avoid relying on private data by utilizing synthetic or sampled data. However, a long-overlooked issue is that the severe distribution shifts between their substitution and original data, which manifests as huge differences in the quality of images and class proportions. The harmful shifts are essentially the confounder that significantly causes performance bottlenecks. To tackle the issue, this paper proposes a novel perspective with causal inference to disentangle the student models from the impact of such shifts. By designing a customized causal graph, we first reveal the causalities among the variables in the DFKD task. Subsequently, we propose a Knowledge Distillation Causal Intervention (KDCI) framework based on the backdoor adjustment to de-confound the confounder. KDCI can be flexibly combined with most existing state-of-the-art baselines. Experiments in combination with six representative DFKD methods demonstrate the effectiveness of our KDCI, which can obviously help existing methods under almost all settings, \textit{e.g.}, improving the baseline by up to 15.54\% accuracy on the CIFAR-100 dataset.
Towards Multimodal Human Intention Understanding Debiasing via Subject-Deconfounding
Mar 08, 2024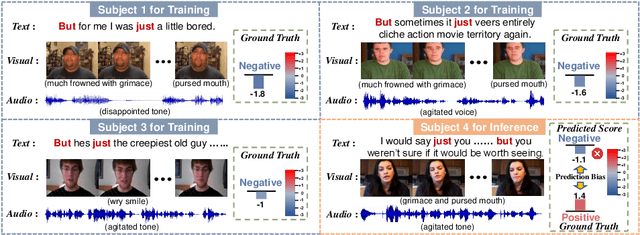
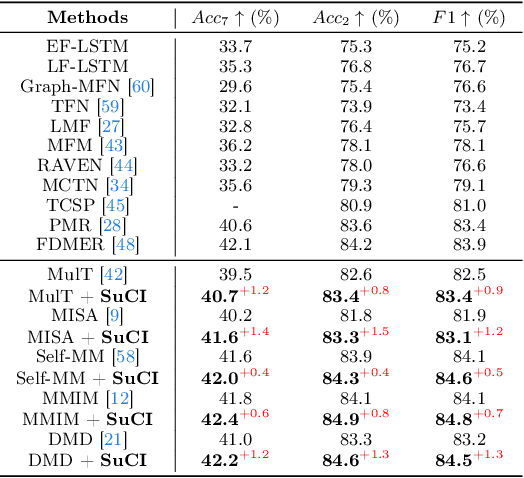
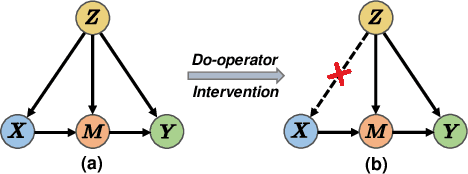
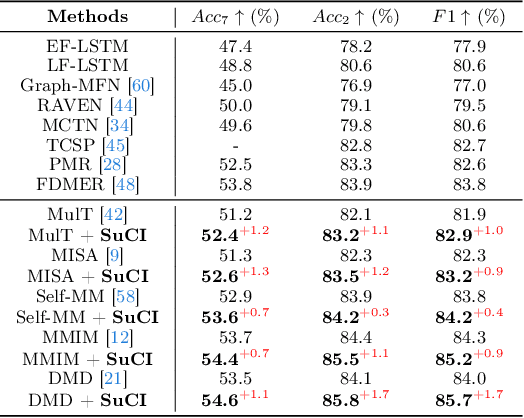
Multimodal intention understanding (MIU) is an indispensable component of human expression analysis (e.g., sentiment or humor) from heterogeneous modalities, including visual postures, linguistic contents, and acoustic behaviors. Existing works invariably focus on designing sophisticated structures or fusion strategies to achieve impressive improvements. Unfortunately, they all suffer from the subject variation problem due to data distribution discrepancies among subjects. Concretely, MIU models are easily misled by distinct subjects with different expression customs and characteristics in the training data to learn subject-specific spurious correlations, significantly limiting performance and generalizability across uninitiated subjects.Motivated by this observation, we introduce a recapitulative causal graph to formulate the MIU procedure and analyze the confounding effect of subjects. Then, we propose SuCI, a simple yet effective causal intervention module to disentangle the impact of subjects acting as unobserved confounders and achieve model training via true causal effects. As a plug-and-play component, SuCI can be widely applied to most methods that seek unbiased predictions. Comprehensive experiments on several MIU benchmarks clearly demonstrate the effectiveness of the proposed module.
Towards Multimodal Sentiment Analysis Debiasing via Bias Purification
Mar 08, 2024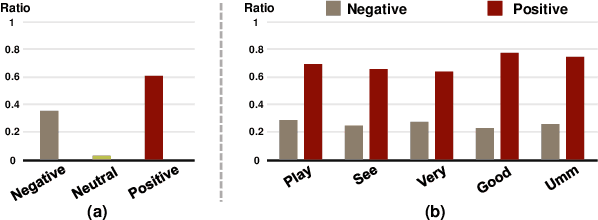
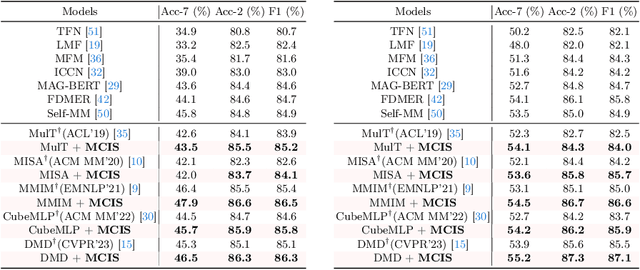
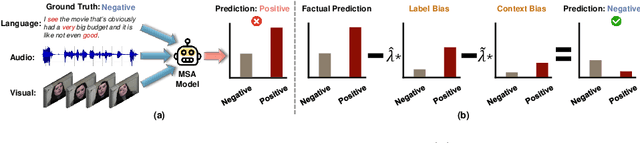
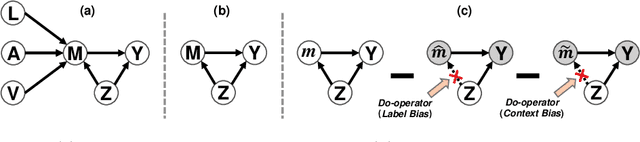
Multimodal Sentiment Analysis (MSA) aims to understand human intentions by integrating emotion-related clues from diverse modalities, such as visual, language, and audio. Unfortunately, the current MSA task invariably suffers from unplanned dataset biases, particularly multimodal utterance-level label bias and word-level context bias. These harmful biases potentially mislead models to focus on statistical shortcuts and spurious correlations, causing severe performance bottlenecks. To alleviate these issues, we present a Multimodal Counterfactual Inference Sentiment (MCIS) analysis framework based on causality rather than conventional likelihood. Concretely, we first formulate a causal graph to discover harmful biases from already-trained vanilla models. In the inference phase, given a factual multimodal input, MCIS imagines two counterfactual scenarios to purify and mitigate these biases. Then, MCIS can make unbiased decisions from biased observations by comparing factual and counterfactual outcomes. We conduct extensive experiments on several standard MSA benchmarks. Qualitative and quantitative results show the effectiveness of the proposed framework.
Improving Generalization in Visual Reinforcement Learning via Conflict-aware Gradient Agreement Augmentation
Aug 02, 2023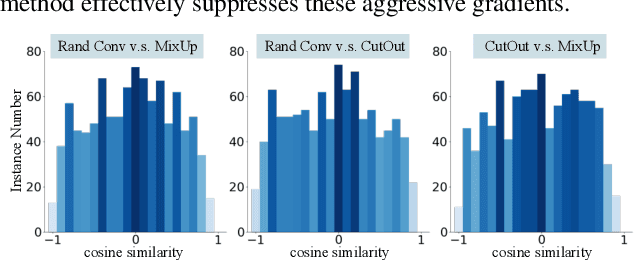

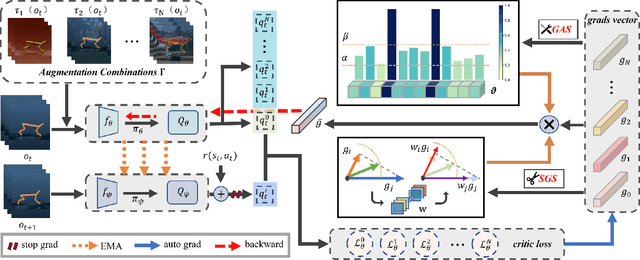
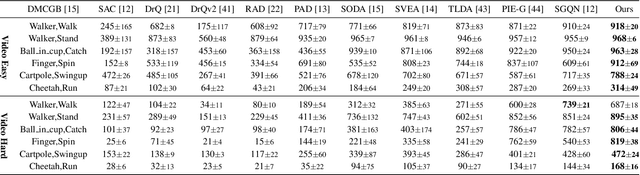
Learning a policy with great generalization to unseen environments remains challenging but critical in visual reinforcement learning. Despite the success of augmentation combination in the supervised learning generalization, naively applying it to visual RL algorithms may damage the training efficiency, suffering from serve performance degradation. In this paper, we first conduct qualitative analysis and illuminate the main causes: (i) high-variance gradient magnitudes and (ii) gradient conflicts existed in various augmentation methods. To alleviate these issues, we propose a general policy gradient optimization framework, named Conflict-aware Gradient Agreement Augmentation (CG2A), and better integrate augmentation combination into visual RL algorithms to address the generalization bias. In particular, CG2A develops a Gradient Agreement Solver to adaptively balance the varying gradient magnitudes, and introduces a Soft Gradient Surgery strategy to alleviate the gradient conflicts. Extensive experiments demonstrate that CG2A significantly improves the generalization performance and sample efficiency of visual RL algorithms.
AIDE: A Vision-Driven Multi-View, Multi-Modal, Multi-Tasking Dataset for Assistive Driving Perception
Aug 01, 2023
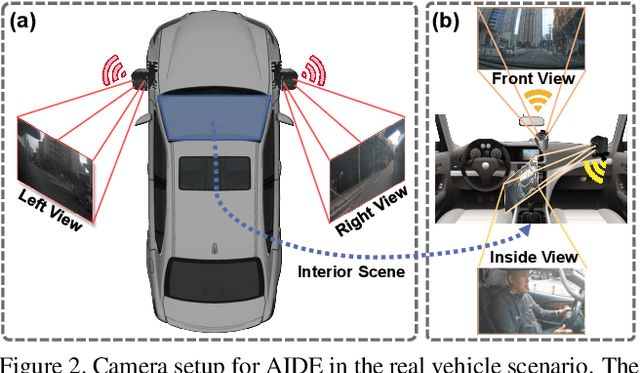

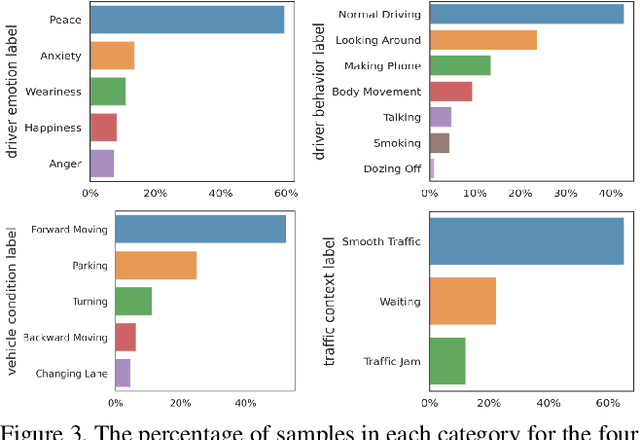
Driver distraction has become a significant cause of severe traffic accidents over the past decade. Despite the growing development of vision-driven driver monitoring systems, the lack of comprehensive perception datasets restricts road safety and traffic security. In this paper, we present an AssIstive Driving pErception dataset (AIDE) that considers context information both inside and outside the vehicle in naturalistic scenarios. AIDE facilitates holistic driver monitoring through three distinctive characteristics, including multi-view settings of driver and scene, multi-modal annotations of face, body, posture, and gesture, and four pragmatic task designs for driving understanding. To thoroughly explore AIDE, we provide experimental benchmarks on three kinds of baseline frameworks via extensive methods. Moreover, two fusion strategies are introduced to give new insights into learning effective multi-stream/modal representations. We also systematically investigate the importance and rationality of the key components in AIDE and benchmarks. The project link is https://github.com/ydk122024/AIDE.
Sampling to Distill: Knowledge Transfer from Open-World Data
Jul 31, 2023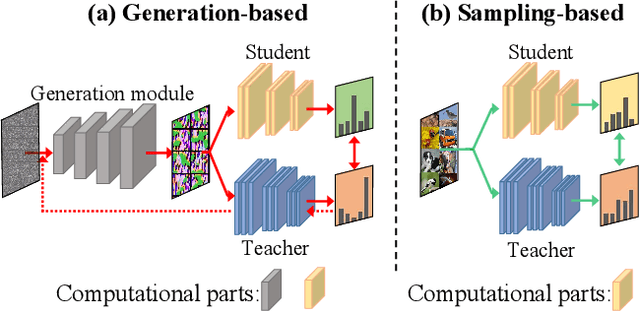

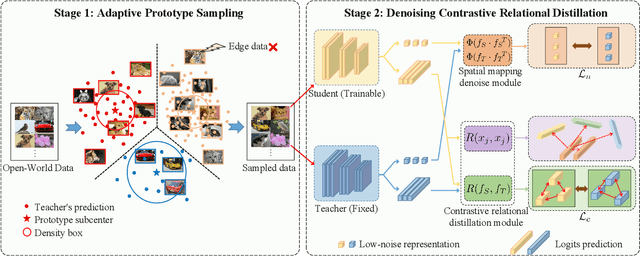
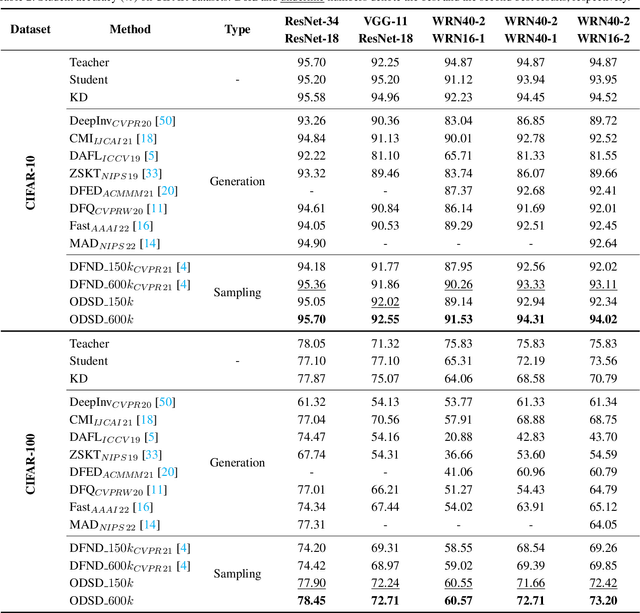
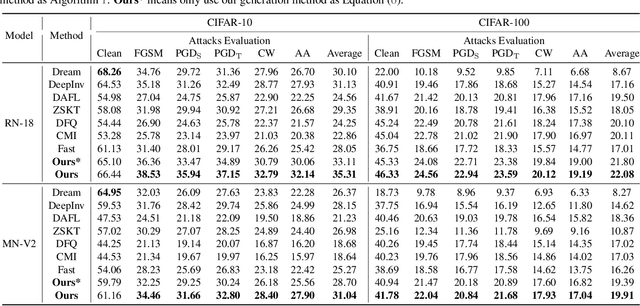
Data-Free Knowledge Distillation (DFKD) is a novel task that aims to train high-performance student models using only the teacher network without original training data. Despite encouraging results, existing DFKD methods rely heavily on generation modules with high computational costs. Meanwhile, they ignore the fact that the generated and original data exist domain shifts due to the lack of supervision information. Moreover, knowledge is transferred through each example, ignoring the implicit relationship among multiple examples. To this end, we propose a novel Open-world Data Sampling Distillation (ODSD) method without a redundant generation process. First, we try to sample open-world data close to the original data's distribution by an adaptive sampling module. Then, we introduce a low-noise representation to alleviate the domain shifts and build a structured relationship of multiple data examples to exploit data knowledge. Extensive experiments on CIFAR-10, CIFAR-100, NYUv2, and ImageNet show that our ODSD method achieves state-of-the-art performance. Especially, we improve 1.50\%-9.59\% accuracy on the ImageNet dataset compared with the existing results.
Context De-confounded Emotion Recognition
Mar 26, 2023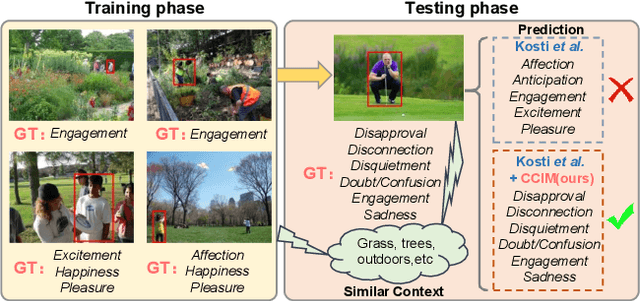
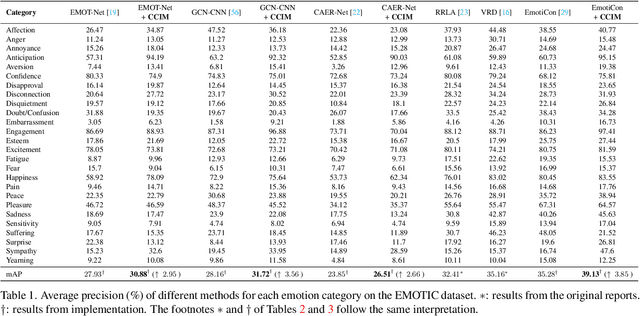
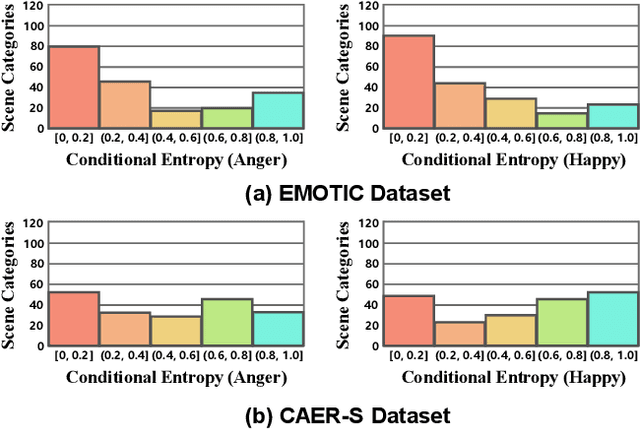

Context-Aware Emotion Recognition (CAER) is a crucial and challenging task that aims to perceive the emotional states of the target person with contextual information. Recent approaches invariably focus on designing sophisticated architectures or mechanisms to extract seemingly meaningful representations from subjects and contexts. However, a long-overlooked issue is that a context bias in existing datasets leads to a significantly unbalanced distribution of emotional states among different context scenarios. Concretely, the harmful bias is a confounder that misleads existing models to learn spurious correlations based on conventional likelihood estimation, significantly limiting the models' performance. To tackle the issue, this paper provides a causality-based perspective to disentangle the models from the impact of such bias, and formulate the causalities among variables in the CAER task via a tailored causal graph. Then, we propose a Contextual Causal Intervention Module (CCIM) based on the backdoor adjustment to de-confound the confounder and exploit the true causal effect for model training. CCIM is plug-in and model-agnostic, which improves diverse state-of-the-art approaches by considerable margins. Extensive experiments on three benchmark datasets demonstrate the effectiveness of our CCIM and the significance of causal insight.
Model Robustness Meets Data Privacy: Adversarial Robustness Distillation without Original Data
Mar 21, 2023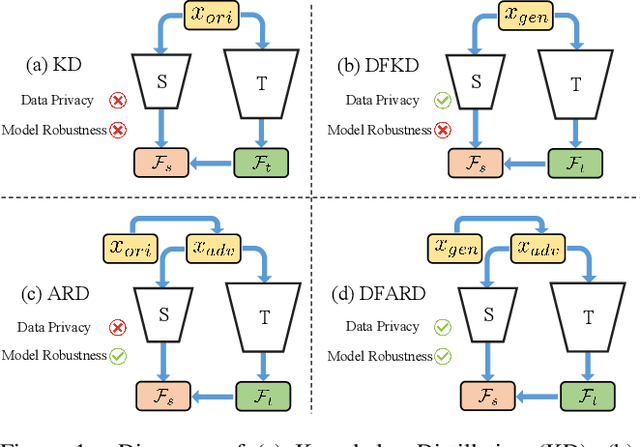


Large-scale deep learning models have achieved great performance based on large-scale datasets. Moreover, the existing Adversarial Training (AT) can further improve the robustness of these large models. However, these large models are difficult to deploy to mobile devices, and the effect of AT on small models is very limited. In addition, the data privacy issue (e.g., face data and diagnosis report) may lead to the original data being unavailable, which relies on data-free knowledge distillation technology for training. To tackle these issues, we propose a challenging novel task called Data-Free Adversarial Robustness Distillation (DFARD), which tries to train small, easily deployable, robust models without relying on the original data. We find the combination of existing techniques resulted in degraded model performance due to fixed training objectives and scarce information content. First, an interactive strategy is designed for more efficient knowledge transfer to find more suitable training objectives at each epoch. Then, we explore an adaptive balance method to suppress information loss and obtain more data information than previous methods. Experiments show that our method improves baseline performance on the novel task.
Explicit and Implicit Knowledge Distillation via Unlabeled Data
Feb 23, 2023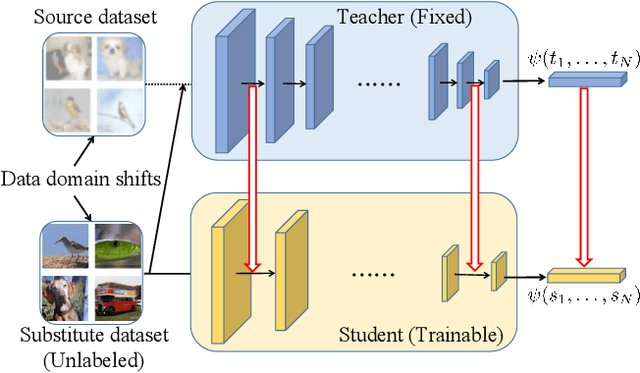
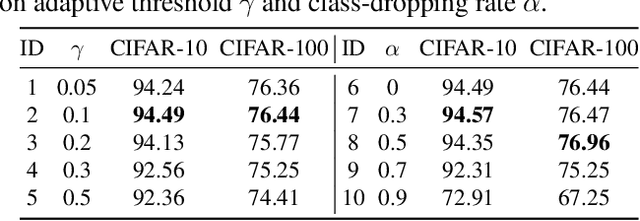
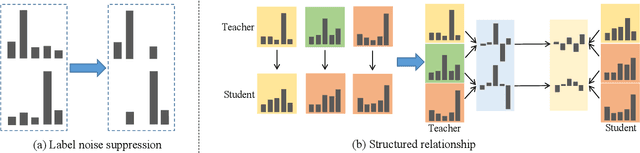
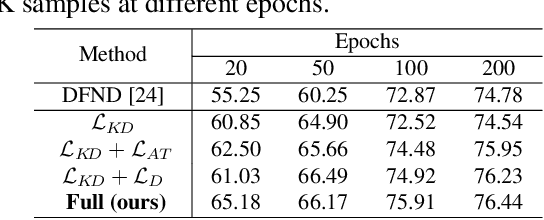
Data-free knowledge distillation is a challenging model lightweight task for scenarios in which the original dataset is not available. Previous methods require a lot of extra computational costs to update one or more generators and their naive imitate-learning lead to lower distillation efficiency. Based on these observations, we first propose an efficient unlabeled sample selection method to replace high computational generators and focus on improving the training efficiency of the selected samples. Then, a class-dropping mechanism is designed to suppress the label noise caused by the data domain shifts. Finally, we propose a distillation method that incorporates explicit features and implicit structured relations to improve the effect of distillation. Experimental results show that our method can quickly converge and obtain higher accuracy than other state-of-the-art methods.
Adversarial Contrastive Distillation with Adaptive Denoising
Feb 23, 2023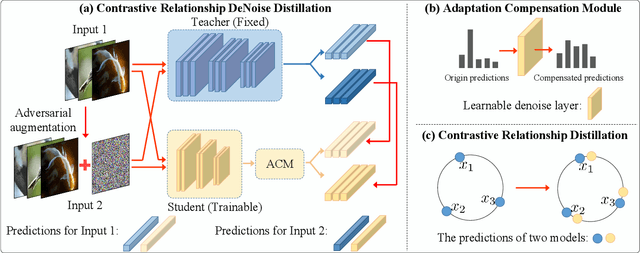
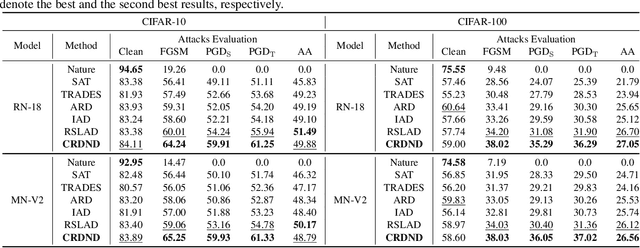
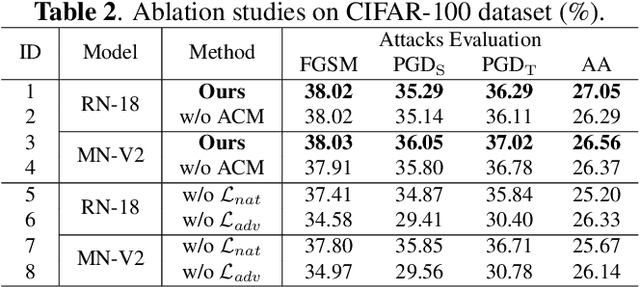
Adversarial Robustness Distillation (ARD) is a novel method to boost the robustness of small models. Unlike general adversarial training, its robust knowledge transfer can be less easily restricted by the model capacity. However, the teacher model that provides the robustness of knowledge does not always make correct predictions, interfering with the student's robust performances. Besides, in the previous ARD methods, the robustness comes entirely from one-to-one imitation, ignoring the relationship between examples. To this end, we propose a novel structured ARD method called Contrastive Relationship DeNoise Distillation (CRDND). We design an adaptive compensation module to model the instability of the teacher. Moreover, we utilize the contrastive relationship to explore implicit robustness knowledge among multiple examples. Experimental results on multiple attack benchmarks show CRDND can transfer robust knowledge efficiently and achieves state-of-the-art performances.