 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKun Yang
High-Speed Interception Multicopter Control by Image-based Visual Servoing
Apr 12, 2024
In recent years, reports of illegal drones threatening public safety have increased. For the invasion of fully autonomous drones, traditional methods such as radio frequency interference and GPS shielding may fail. This paper proposes a scheme that uses an autonomous multicopter with a strapdown camera to intercept a maneuvering intruder UAV. The interceptor multicopter can autonomously detect and intercept intruders moving at high speed in the air. The strapdown camera avoids the complex mechanical structure of the electro-optical pod, making the interceptor multicopter compact. However, the coupling of the camera and multicopter motion makes interception tasks difficult. To solve this problem, an Image-Based Visual Servoing (IBVS) controller is proposed to make the interception fast and accurate. Then, in response to the time delay of sensor imaging and image processing relative to attitude changes in high-speed scenarios, a Delayed Kalman Filter (DKF) observer is generalized to predict the current image position and increase the update frequency. Finally, Hardware-in-the-Loop (HITL) simulations and outdoor flight experiments verify that this method has a high interception accuracy and success rate. In the flight experiments, a high-speed interception is achieved with a terminal speed of 20 m/s.
Large Generative Model Assisted 3D Semantic Communication
Mar 09, 2024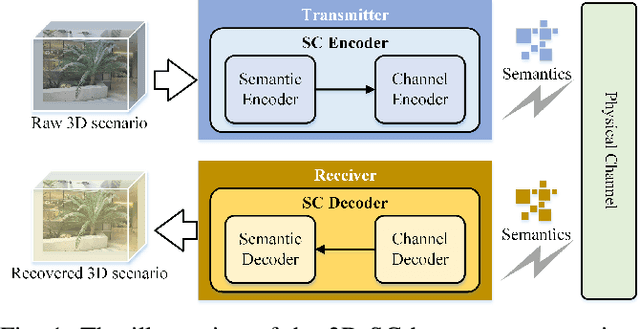
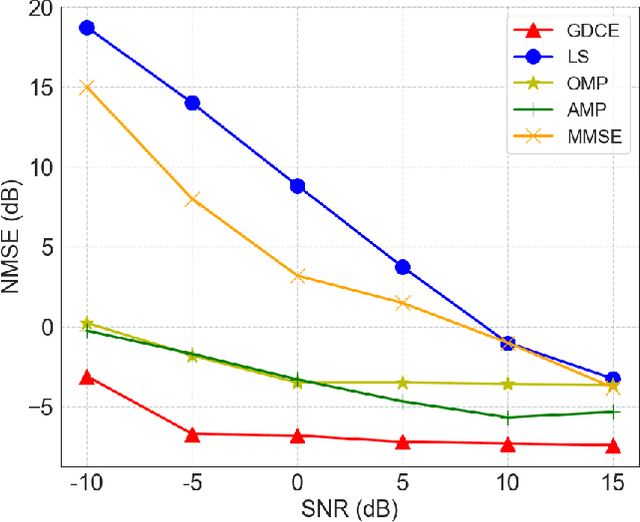
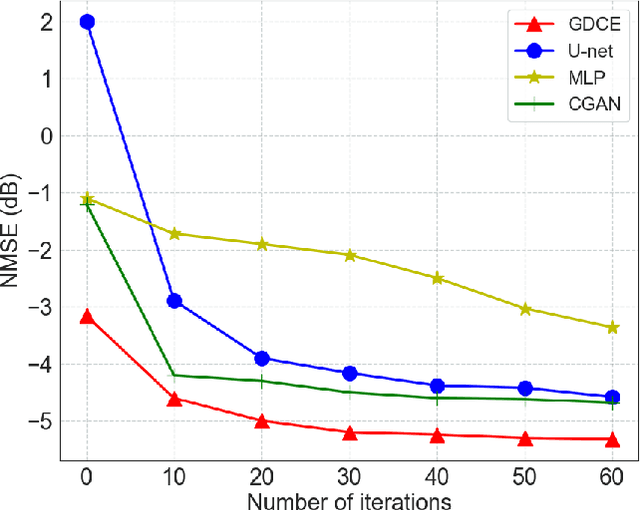
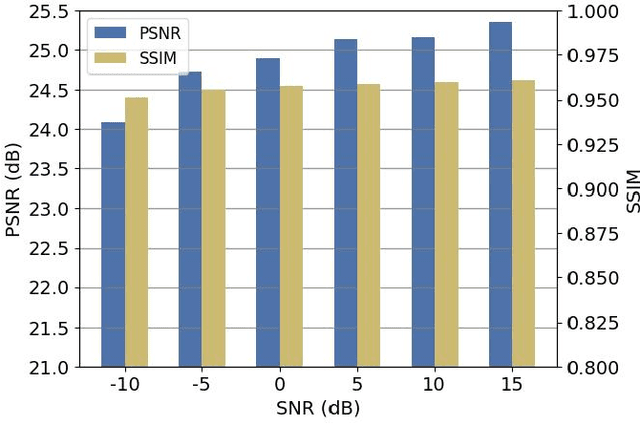
Semantic Communication (SC) is a novel paradigm for data transmission in 6G. However, there are several challenges posed when performing SC in 3D scenarios: 1) 3D semantic extraction; 2) Latent semantic redundancy; and 3) Uncertain channel estimation. To address these issues, we propose a Generative AI Model assisted 3D SC (GAM-3DSC) system. Firstly, we introduce a 3D Semantic Extractor (3DSE), which employs generative AI models, including Segment Anything Model (SAM) and Neural Radiance Field (NeRF), to extract key semantics from a 3D scenario based on user requirements. The extracted 3D semantics are represented as multi-perspective images of the goal-oriented 3D object. Then, we present an Adaptive Semantic Compression Model (ASCM) for encoding these multi-perspective images, in which we use a semantic encoder with two output heads to perform semantic encoding and mask redundant semantics in the latent semantic space, respectively. Next, we design a conditional Generative adversarial network and Diffusion model aided-Channel Estimation (GDCE) to estimate and refine the Channel State Information (CSI) of physical channels. Finally, simulation results demonstrate the advantages of the proposed GAM-3DSC system in effectively transmitting the goal-oriented 3D scenario.
Robust Emotion Recognition in Context Debiasing
Mar 09, 2024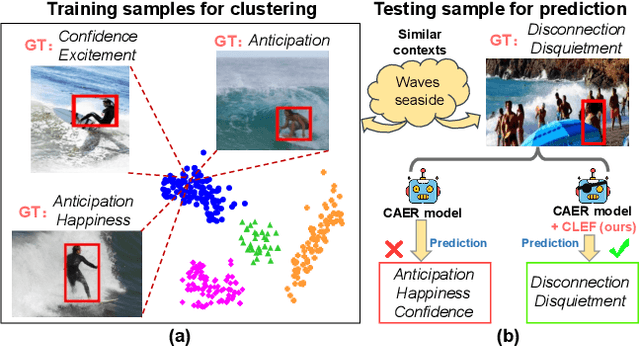
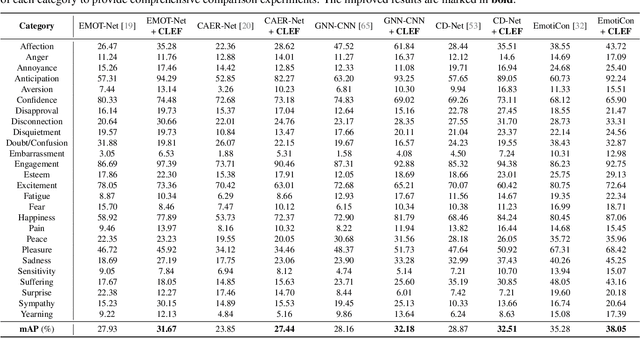
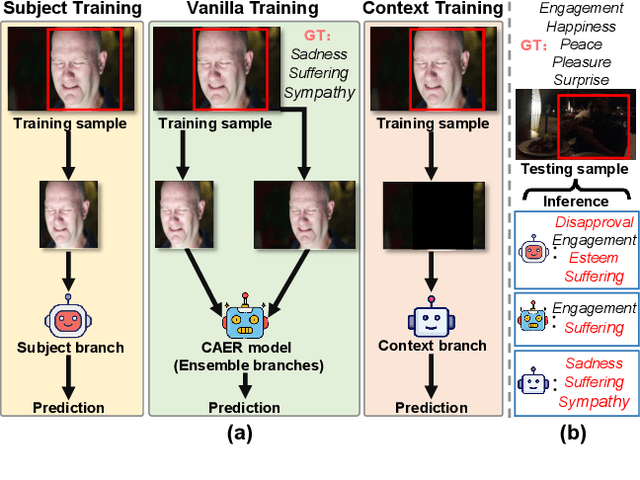
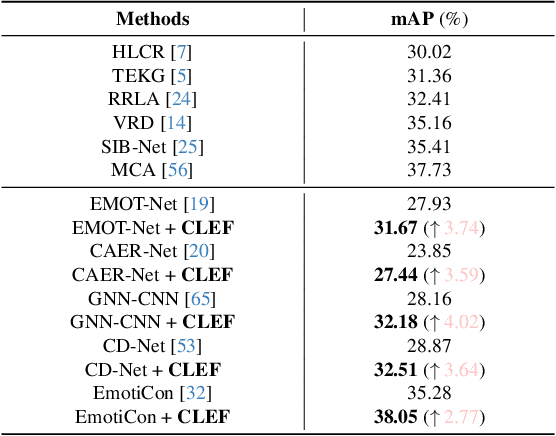
Context-aware emotion recognition (CAER) has recently boosted the practical applications of affective computing techniques in unconstrained environments. Mainstream CAER methods invariably extract ensemble representations from diverse contexts and subject-centred characteristics to perceive the target person's emotional state. Despite advancements, the biggest challenge remains due to context bias interference. The harmful bias forces the models to rely on spurious correlations between background contexts and emotion labels in likelihood estimation, causing severe performance bottlenecks and confounding valuable context priors. In this paper, we propose a counterfactual emotion inference (CLEF) framework to address the above issue. Specifically, we first formulate a generalized causal graph to decouple the causal relationships among the variables in CAER. Following the causal graph, CLEF introduces a non-invasive context branch to capture the adverse direct effect caused by the context bias. During the inference, we eliminate the direct context effect from the total causal effect by comparing factual and counterfactual outcomes, resulting in bias mitigation and robust prediction. As a model-agnostic framework, CLEF can be readily integrated into existing methods, bringing consistent performance gains.
Towards Multimodal Sentiment Analysis Debiasing via Bias Purification
Mar 08, 2024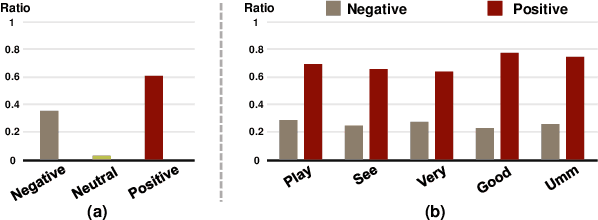
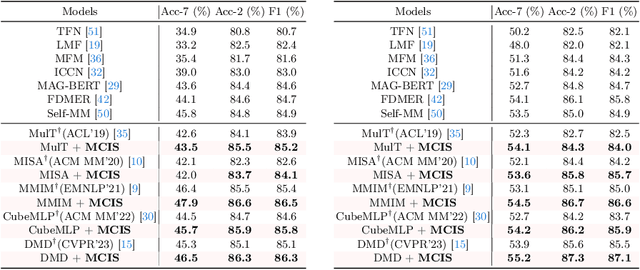
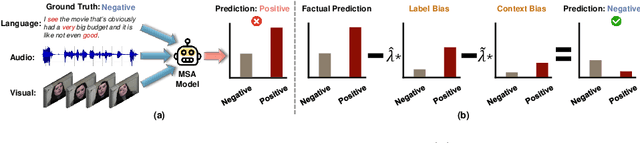
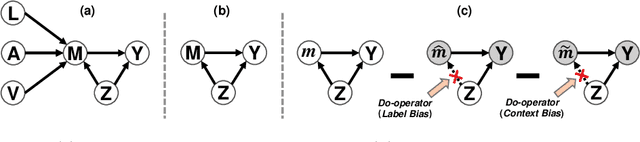
Multimodal Sentiment Analysis (MSA) aims to understand human intentions by integrating emotion-related clues from diverse modalities, such as visual, language, and audio. Unfortunately, the current MSA task invariably suffers from unplanned dataset biases, particularly multimodal utterance-level label bias and word-level context bias. These harmful biases potentially mislead models to focus on statistical shortcuts and spurious correlations, causing severe performance bottlenecks. To alleviate these issues, we present a Multimodal Counterfactual Inference Sentiment (MCIS) analysis framework based on causality rather than conventional likelihood. Concretely, we first formulate a causal graph to discover harmful biases from already-trained vanilla models. In the inference phase, given a factual multimodal input, MCIS imagines two counterfactual scenarios to purify and mitigate these biases. Then, MCIS can make unbiased decisions from biased observations by comparing factual and counterfactual outcomes. We conduct extensive experiments on several standard MSA benchmarks. Qualitative and quantitative results show the effectiveness of the proposed framework.
Best Arm Identification for Prompt Learning under a Limited Budget
Feb 20, 2024The remarkable instruction-following capability of large language models (LLMs) has sparked a growing interest in automatically learning suitable prompts. However, while many effective methods have been proposed, the cost incurred during the learning process (e.g., accessing LLM and evaluating the responses) has not been considered. To overcome this limitation, this work explicitly incorporates a finite budget constraint into prompt learning. Towards developing principled solutions, a novel connection is established between prompt learning and fixed-budget best arm identification (BAI-FB) in multi-armed bandits (MAB). Based on this connection, a general framework TRIPLE (besT aRm Identification for Prompt LEarning) is proposed to harness the power of BAI-FB in prompt learning systematically. Unique characteristics of prompt learning further lead to two embedding-based enhancements of TRIPLE by exploiting the ideas of clustering and function approximation. Extensive experiments on multiple well-adopted tasks using both GPT 3.5 and Llama2 demonstrate the significant performance improvement of TRIPLE over the previous baselines while satisfying the limited budget constraints.
STAR-RIS Enhanced UAV-Enabled MEC Networks with Bi-Directional Task Offloading
Jan 11, 2024A simultaneously transmitting and reflecting reconfigurable intelligent surface (STAR-RIS) enhanced unnamed aerial vehicle (UAV)-enabled multi-user mobile edge computing (MEC) scheme is proposed in this paper. Different from the existing MEC works, the proposed scheme allows bi-directional offloading where users can simultaneously offload their computing tasks to the MEC servers situated at the ground base station (BS) and aerial UAV with the assistance of the STARRIS. Specifically, we formulate an optimization problem aiming at maximizing the energy efficiency of the system while ensuring the quality of service (QoS) constraint by jointly optimizing the resource allocation, user scheduling, passive beamforming of the STAR-RIS, and the UAV trajectory. An iterative algorithm designed with the Dinkelbach's algorithm and the successive convex approximation (SCA) is proposed to effectively handle the formulated non-convex optimization problem. Simulation results indicate that the proposed STAR-RIS enhanced UAV-enabled MEC scheme possesses significant advantages in enhancing the system energy efficiency over other baseline schemes including the conventional RIS-aided scheme.
Harnessing the Power of Federated Learning in Federated Contextual Bandits
Dec 26, 2023Federated learning (FL) has demonstrated great potential in revolutionizing distributed machine learning, and tremendous efforts have been made to extend it beyond the original focus on supervised learning. Among many directions, federated contextual bandits (FCB), a pivotal integration of FL and sequential decision-making, has garnered significant attention in recent years. Despite substantial progress, existing FCB approaches have largely employed their tailored FL components, often deviating from the canonical FL framework. Consequently, even renowned algorithms like FedAvg remain under-utilized in FCB, let alone other FL advancements. Motivated by this disconnection, this work takes one step towards building a tighter relationship between the canonical FL study and the investigations on FCB. In particular, a novel FCB design, termed FedIGW, is proposed to leverage a regression-based CB algorithm, i.e., inverse gap weighting. Compared with existing FCB approaches, the proposed FedIGW design can better harness the entire spectrum of FL innovations, which is concretely reflected as (1) flexible incorporation of (both existing and forthcoming) FL protocols; (2) modularized plug-in of FL analyses in performance guarantees; (3) seamless integration of FL appendages (such as personalization, robustness, and privacy). We substantiate these claims through rigorous theoretical analyses and empirical evaluations.
Advancing RAN Slicing with Offline Reinforcement Learning
Dec 16, 2023Dynamic radio resource management (RRM) in wireless networks presents significant challenges, particularly in the context of Radio Access Network (RAN) slicing. This technology, crucial for catering to varying user requirements, often grapples with complex optimization scenarios. Existing Reinforcement Learning (RL) approaches, while achieving good performance in RAN slicing, typically rely on online algorithms or behavior cloning. These methods necessitate either continuous environmental interactions or access to high-quality datasets, hindering their practical deployment. Towards addressing these limitations, this paper introduces offline RL to solving the RAN slicing problem, marking a significant shift towards more feasible and adaptive RRM methods. We demonstrate how offline RL can effectively learn near-optimal policies from sub-optimal datasets, a notable advancement over existing practices. Our research highlights the inherent flexibility of offline RL, showcasing its ability to adjust policy criteria without the need for additional environmental interactions. Furthermore, we present empirical evidence of the efficacy of offline RL in adapting to various service-level requirements, illustrating its potential in diverse RAN slicing scenarios.
Large Language Model Enhanced Multi-Agent Systems for 6G Communications
Dec 13, 2023The rapid development of the Large Language Model (LLM) presents huge opportunities for 6G communications, e.g., network optimization and management by allowing users to input task requirements to LLMs by nature language. However, directly applying native LLMs in 6G encounters various challenges, such as a lack of private communication data and knowledge, limited logical reasoning, evaluation, and refinement abilities. Integrating LLMs with the capabilities of retrieval, planning, memory, evaluation and reflection in agents can greatly enhance the potential of LLMs for 6G communications. To this end, we propose a multi-agent system with customized communication knowledge and tools for solving communication related tasks using natural language, comprising three components: (1) Multi-agent Data Retrieval (MDR), which employs the condensate and inference agents to refine and summarize communication knowledge from the knowledge base, expanding the knowledge boundaries of LLMs in 6G communications; (2) Multi-agent Collaborative Planning (MCP), which utilizes multiple planning agents to generate feasible solutions for the communication related task from different perspectives based on the retrieved knowledge; (3) Multi-agent Evaluation and Reflecxion (MER), which utilizes the evaluation agent to assess the solutions, and applies the reflexion agent and refinement agent to provide improvement suggestions for current solutions. Finally, we validate the effectiveness of the proposed multi-agent system by designing a semantic communication system, as a case study of 6G communications.
A Multilevel Guidance-Exploration Network and Behavior-Scene Matching Method for Human Behavior Anomaly Detection
Dec 07, 2023Human behavior anomaly detection aims to identify unusual human actions, playing a crucial role in intelligent surveillance and other areas. The current mainstream methods still adopt reconstruction or future frame prediction techniques. However, reconstructing or predicting low-level pixel features easily enables the network to achieve overly strong generalization ability, allowing anomalies to be reconstructed or predicted as effectively as normal data. Different from their methods, inspired by the Student-Teacher Network, we propose a novel framework called the Multilevel Guidance-Exploration Network(MGENet), which detects anomalies through the difference in high-level representation between the Guidance and Exploration network. Specifically, we first utilize the pre-trained Normalizing Flow that takes skeletal keypoints as input to guide an RGB encoder, which takes unmasked RGB frames as input, to explore motion latent features. Then, the RGB encoder guides the mask encoder, which takes masked RGB frames as input, to explore the latent appearance feature. Additionally, we design a Behavior-Scene Matching Module(BSMM) to detect scene-related behavioral anomalies. Extensive experiments demonstrate that our proposed method achieves state-of-the-art performance on ShanghaiTech and UBnormal datasets, with AUC of 86.9 % and 73.5 %, respectively. The code will be available on https://github.com/molu-ggg/GENet.