 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXiaoyan Hu
Maximizing Energy Charging for UAV-assisted MEC Systems with SWIPT
Mar 06, 2024
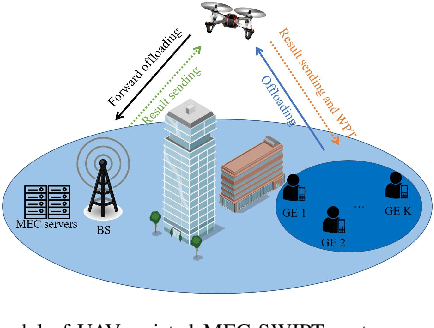
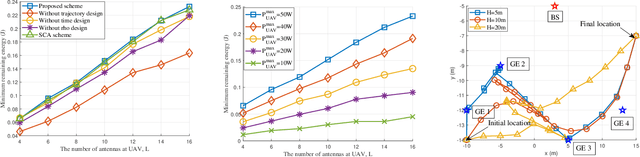
A Unmanned aerial vehicle (UAV)-assisted mobile edge computing (MEC) scheme with simultaneous wireless information and power transfer (SWIPT) is proposed in this paper. Unlike existing MEC-WPT schemes that disregard the downlink period for returning computing results to the ground equipment (GEs), our proposed scheme actively considers and capitalizes on this period. By leveraging the SWIPT technique, the UAV can simultaneously transmit energy and the computing results during the downlink period. In this scheme, our objective is to maximize the remaining energy among all GEs by jointly optimizing computing task scheduling, UAV transmit and receive beamforming, BS receive beamforming, GEs' transmit power and power splitting ratio for information decoding, time scheduling, and UAV trajectory. We propose an alternating optimization algorithm that utilizes the semidefinite relaxation (SDR), singular value decomposition (SVD), and fractional programming (FP) methods to effectively solve the nonconvex problem. Numerous experiments validate the effectiveness of the proposed scheme.
STAR-RIS Enhanced UAV-Enabled MEC Networks with Bi-Directional Task Offloading
Jan 11, 2024A simultaneously transmitting and reflecting reconfigurable intelligent surface (STAR-RIS) enhanced unnamed aerial vehicle (UAV)-enabled multi-user mobile edge computing (MEC) scheme is proposed in this paper. Different from the existing MEC works, the proposed scheme allows bi-directional offloading where users can simultaneously offload their computing tasks to the MEC servers situated at the ground base station (BS) and aerial UAV with the assistance of the STARRIS. Specifically, we formulate an optimization problem aiming at maximizing the energy efficiency of the system while ensuring the quality of service (QoS) constraint by jointly optimizing the resource allocation, user scheduling, passive beamforming of the STAR-RIS, and the UAV trajectory. An iterative algorithm designed with the Dinkelbach's algorithm and the successive convex approximation (SCA) is proposed to effectively handle the formulated non-convex optimization problem. Simulation results indicate that the proposed STAR-RIS enhanced UAV-enabled MEC scheme possesses significant advantages in enhancing the system energy efficiency over other baseline schemes including the conventional RIS-aided scheme.
An Information Theoretic Approach to Interaction-Grounded Learning
Jan 10, 2024Reinforcement learning (RL) problems where the learner attempts to infer an unobserved reward from some feedback variables have been studied in several recent papers. The setting of Interaction-Grounded Learning (IGL) is an example of such feedback-based reinforcement learning tasks where the learner optimizes the return by inferring latent binary rewards from the interaction with the environment. In the IGL setting, a relevant assumption used in the RL literature is that the feedback variable $Y$ is conditionally independent of the context-action $(X,A)$ given the latent reward $R$. In this work, we propose Variational Information-based IGL (VI-IGL) as an information-theoretic method to enforce the conditional independence assumption in the IGL-based RL problem. The VI-IGL framework learns a reward decoder using an information-based objective based on the conditional mutual information (MI) between the context-action $(X,A)$ and the feedback variable $Y$ observed from the environment. To estimate and optimize the information-based terms for the continuous random variables in the RL problem, VI-IGL leverages the variational representation of mutual information and results in a min-max optimization problem. Furthermore, we extend the VI-IGL framework to general $f$-Information measures in the information theory literature, leading to the generalized $f$-VI-IGL framework to address the RL problem under the IGL condition. Finally, we provide the empirical results of applying the VI-IGL method to several reinforcement learning settings, which indicate an improved performance in comparison to the previous IGL-based RL algorithm.
Provably Efficient CVaR RL in Low-rank MDPs
Nov 20, 2023We study risk-sensitive Reinforcement Learning (RL), where we aim to maximize the Conditional Value at Risk (CVaR) with a fixed risk tolerance $\tau$. Prior theoretical work studying risk-sensitive RL focuses on the tabular Markov Decision Processes (MDPs) setting. To extend CVaR RL to settings where state space is large, function approximation must be deployed. We study CVaR RL in low-rank MDPs with nonlinear function approximation. Low-rank MDPs assume the underlying transition kernel admits a low-rank decomposition, but unlike prior linear models, low-rank MDPs do not assume the feature or state-action representation is known. We propose a novel Upper Confidence Bound (UCB) bonus-driven algorithm to carefully balance the interplay between exploration, exploitation, and representation learning in CVaR RL. We prove that our algorithm achieves a sample complexity of $\tilde{O}\left(\frac{H^7 A^2 d^4}{\tau^2 \epsilon^2}\right)$ to yield an $\epsilon$-optimal CVaR, where $H$ is the length of each episode, $A$ is the capacity of action space, and $d$ is the dimension of representations. Computational-wise, we design a novel discretized Least-Squares Value Iteration (LSVI) algorithm for the CVaR objective as the planning oracle and show that we can find the near-optimal policy in a polynomial running time with a Maximum Likelihood Estimation oracle. To our knowledge, this is the first provably efficient CVaR RL algorithm in low-rank MDPs.
Block-Level Interference Exploitation Precoding for MU-MISO: An ADMM Approach
Aug 30, 2023We study constructive interference based block-level precoding (CI-BLP) in the downlink of multi-user multiple-input single-output (MU-MISO) systems. Specifically, our aim is to extend the analysis on CI-BLP to the case where the considered number of symbol slots is smaller than that of the users. To this end, we mathematically prove the feasibility of using the pseudo-inverse to obtain the optimal CI-BLP precoding matrix in a closed form. Similar to the case when the number of users is small, we show that a quadratic programming (QP) optimization on simplex can be constructed. We also design a low-complexity algorithm based on the alternating direction method of multipliers (ADMM) framework, which can efficiently solve large-scale QP problems. We further analyze the convergence and complexity of the proposed algorithm. Numerical results validate our analysis and the optimality of the proposed algorithm, and further show that the proposed algorithm offers a flexible performance-complexity tradeoff by limiting the maximum number of iterations, which motivates the use of CI-BLP in practical wireless systems.
On the Generalization and Advancement of Half-Sine-Based Pulse Shaping Filters for Constant Envelope OQPSK Modulation
Jun 14, 2023



The offset quadrature phase-shift keying (OQPSK) modulation is a key factor for the technique of ZigBee, which has been adopted in IEEE 802.15.4 for wireless communications of Internet of Things (IoT) and Internet of Vehicles (IoV), etc. In this paper, we propose the general conditions of pulse shaping filters (PSFs) with constant envelope (CE) property for OQPSK modulation, which can be easily leveraged to design the PSFs with CE property. Based on these conditions, we further design an advanced PSF called $\alpha$-half-sine PSF. It is verified that the newly designed $\alpha$-half-sine PSF can not only keep the CE property for OQPSK but also achieve better performance than the traditional PSFs in certain scenarios. Moreover, the $\alpha$-half-sine PSF can be simply adjusted to achieve a flexible performance tradeoff between the transition roll-off speed and out-of-band leakage.
STAR-RIS Assisted Covert Communications in NOMA Systems
Jun 12, 2023


Covert communications assisted by simultaneously transmitting and reflecting reconfigurable intelligent surface (STAR-RIS) in non-orthogonal multiple access (NOMA) systems have been explored in this paper. In particular, the access point (AP) transmitter adopts NOMA to serve a downlink covert user and a public user. The minimum detection error probability (DEP) at the warden is derived considering the uncertainty of its background noise, which is used as a covertness constraint. We aim at maximizing the covert rate of the system by jointly optimizing APs transmit power and passive beamforming of STAR-RIS, under the covertness and quality of service (QoS) constraints. An iterative algorithm is proposed to effectively solve the non-convex optimization problem. Simulation results show that the proposed scheme significantly outperforms the conventional RIS-based scheme in ensuring system covert performance.
STAR-RIS Aided Covert Communication
May 11, 2023

This paper investigates the multi-antenna covert communications assisted by a simultaneously transmitting and reflecting reconfigurable intelligent surface (STAR-RIS). In particular, to shelter the existence of communications between transmitter and receiver from a warden, a friendly full-duplex receiver with two antennas is leveraged to make contributions to confuse the warden. Considering the worst case, the closed-form expression of the minimum detection error probability (DEP) at the warden is derived and utilized as a covert constraint. Then, we formulate an optimization problem maximizing the covert rate of the system under the covertness constraint and quality of service (QoS) constraint with communication outage analysis. To jointly design the active and passive beamforming of the transmitter and STAR-RIS, an iterative algorithm based on globally convergent version of method of moving asymptotes (GCMMA) is proposed to effectively solve the non-convex optimization problem. Simulation results show that the proposed STAR-RIS-assisted scheme highly outperforms the case with conventional RIS.
MIMO-OFDM Dual-Functional Radar-Communication Systems: Low-PAPR Waveform Design
Sep 27, 2021



In this paper, we explore a dual-functional radar-communication (DFRC) system for achieving integrated sensing and communications (ISAC). The technique of orthogonal frequency division multiplexing (OFDM) is leveraged to overcome the frequency-selective fading of the wideband multiple-input multiple-output (MIMO) systems with one multi-antenna DFRC base station (BS) and multiple single-antenna user equipment (UEs). In order to restrain the high peak-to-average power ratio (PAPR) of OFDM signals, we aim to jointly design low-PAPR DFRC MIMO-OFDM waveforms. This is done by utilizing a weighted objective function on both communication and radar performance metrics under power and PAPR constraints. The formulated optimization problems can be equivalently transformed into standard semi-definite programming (SDP) and can be effectively solved by semi-definite relaxation (SDR) method, where we prove that globally optimal rank-1 solution can be obtained in general. We further develop a low-complexity method to solve the problems with much reduced overheads. Moreover, the practical scenario with oversampling on OFDM signals is further considered, which has a significant effect on the resulting PAPR levels. The feasibility, effectiveness, and flexibility of the proposed low- PAPR DFRC MIMO-OFDM waveform design methods are demonstrated by a range of simulations on communication sum rate, symbol error rate as well as radar beampattern and detection probability.
Reconfigurable Intelligent Surface Aided Mobile Edge Computing: From Optimization-Based to Location-Only Learning-Based Solutions
Feb 15, 2021



In this paper, we explore optimization-based and data-driven solutions in a reconfigurable intelligent surface (RIS)-aided multi-user mobile edge computing (MEC) system, where the user equipment (UEs) can partially offload their computation tasks to the access point (AP). We aim at maximizing the total completed task-input bits (TCTB) of all UEs with limited energy budgets during a given time slot, through jointly optimizing the RIS reflecting coefficients, the AP's receive beamforming vectors, and the UEs' energy partition strategies for local computing and offloading. A three-step block coordinate descending (BCD) algorithm is first proposed to effectively solve the non-convex TCTB maximization problem with guaranteed convergence. In order to reduce the computational complexity and facilitate lightweight online implementation of the optimization algorithm, we further construct two deep learning architectures. The first one takes channel state information (CSI) as input, while the second one exploits the UEs' locations only for online inference. The two data-driven approaches are trained using data samples generated by the BCD algorithm via supervised learning. Our simulation results reveal a close match between the performance of the optimization-based BCD algorithm and the low-complexity learning-based architectures, all with superior performance to existing schemes in both cases with perfect and imperfect input features. Importantly, the location-only deep learning method is shown to offer a particularly practical and robust solution alleviating the need for CSI estimation and feedback when line-of-sight (LoS) direct links exist between UEs and the AP.