 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShaozi Li
Selective Domain-Invariant Feature for Generalizable Deepfake Detection
Mar 19, 2024
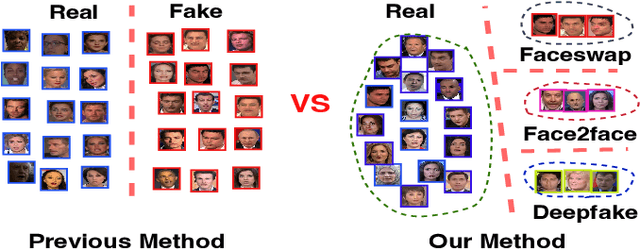
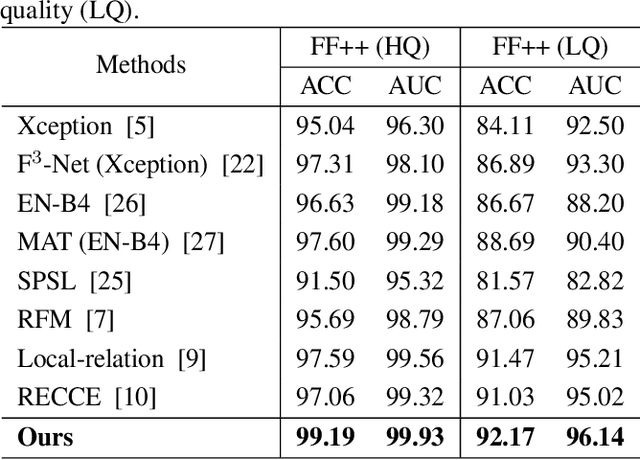
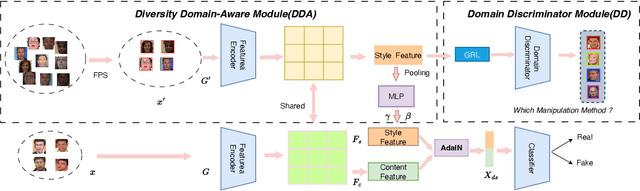

With diverse presentation forgery methods emerging continually, detecting the authenticity of images has drawn growing attention. Although existing methods have achieved impressive accuracy in training dataset detection, they still perform poorly in the unseen domain and suffer from forgery of irrelevant information such as background and identity, affecting generalizability. To solve this problem, we proposed a novel framework Selective Domain-Invariant Feature (SDIF), which reduces the sensitivity to face forgery by fusing content features and styles. Specifically, we first use a Farthest-Point Sampling (FPS) training strategy to construct a task-relevant style sample representation space for fusing with content features. Then, we propose a dynamic feature extraction module to generate features with diverse styles to improve the performance and effectiveness of the feature extractor. Finally, a domain separation strategy is used to retain domain-related features to help distinguish between real and fake faces. Both qualitative and quantitative results in existing benchmarks and proposals demonstrate the effectiveness of our approach.
A Multilevel Guidance-Exploration Network and Behavior-Scene Matching Method for Human Behavior Anomaly Detection
Dec 07, 2023Human behavior anomaly detection aims to identify unusual human actions, playing a crucial role in intelligent surveillance and other areas. The current mainstream methods still adopt reconstruction or future frame prediction techniques. However, reconstructing or predicting low-level pixel features easily enables the network to achieve overly strong generalization ability, allowing anomalies to be reconstructed or predicted as effectively as normal data. Different from their methods, inspired by the Student-Teacher Network, we propose a novel framework called the Multilevel Guidance-Exploration Network(MGENet), which detects anomalies through the difference in high-level representation between the Guidance and Exploration network. Specifically, we first utilize the pre-trained Normalizing Flow that takes skeletal keypoints as input to guide an RGB encoder, which takes unmasked RGB frames as input, to explore motion latent features. Then, the RGB encoder guides the mask encoder, which takes masked RGB frames as input, to explore the latent appearance feature. Additionally, we design a Behavior-Scene Matching Module(BSMM) to detect scene-related behavioral anomalies. Extensive experiments demonstrate that our proposed method achieves state-of-the-art performance on ShanghaiTech and UBnormal datasets, with AUC of 86.9 % and 73.5 %, respectively. The code will be available on https://github.com/molu-ggg/GENet.
Zero-Shot Co-salient Object Detection Framework
Sep 14, 2023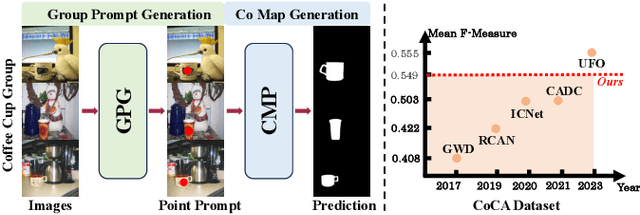
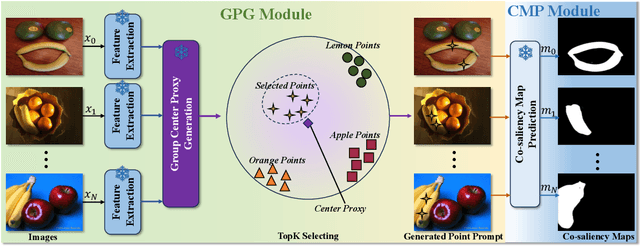
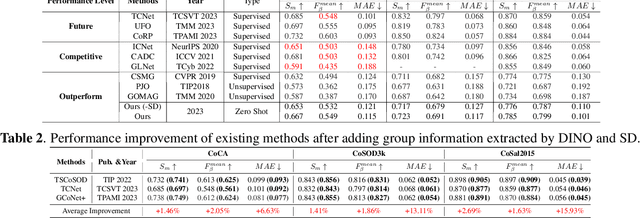

Co-salient Object Detection (CoSOD) endeavors to replicate the human visual system's capacity to recognize common and salient objects within a collection of images. Despite recent advancements in deep learning models, these models still rely on training with well-annotated CoSOD datasets. The exploration of training-free zero-shot CoSOD frameworks has been limited. In this paper, taking inspiration from the zero-shot transfer capabilities of foundational computer vision models, we introduce the first zero-shot CoSOD framework that harnesses these models without any training process. To achieve this, we introduce two novel components in our proposed framework: the group prompt generation (GPG) module and the co-saliency map generation (CMP) module. We evaluate the framework's performance on widely-used datasets and observe impressive results. Our approach surpasses existing unsupervised methods and even outperforms fully supervised methods developed before 2020, while remaining competitive with some fully supervised methods developed before 2022.
Boundary Difference Over Union Loss For Medical Image Segmentation
Aug 01, 2023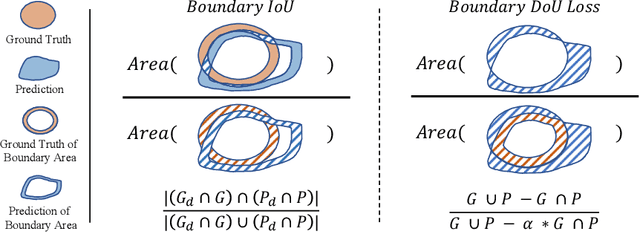
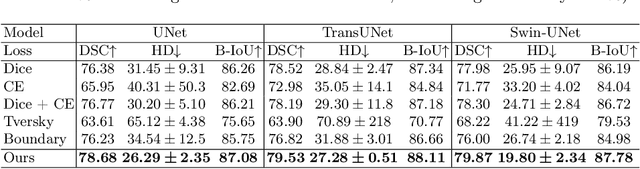
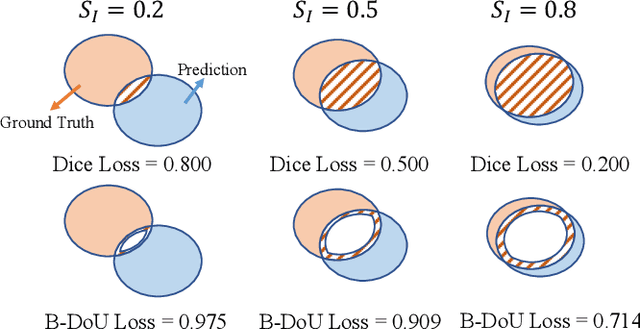
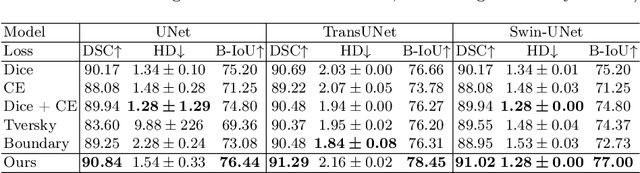
Medical image segmentation is crucial for clinical diagnosis. However, current losses for medical image segmentation mainly focus on overall segmentation results, with fewer losses proposed to guide boundary segmentation. Those that do exist often need to be used in combination with other losses and produce ineffective results. To address this issue, we have developed a simple and effective loss called the Boundary Difference over Union Loss (Boundary DoU Loss) to guide boundary region segmentation. It is obtained by calculating the ratio of the difference set of prediction and ground truth to the union of the difference set and the partial intersection set. Our loss only relies on region calculation, making it easy to implement and training stable without needing any additional losses. Additionally, we use the target size to adaptively adjust attention applied to the boundary regions. Experimental results using UNet, TransUNet, and Swin-UNet on two datasets (ACDC and Synapse) demonstrate the effectiveness of our proposed loss function. Code is available at https://github.com/sunfan-bvb/BoundaryDoULoss.
Comparative Evaluation of Recent Universal Adversarial Perturbations in Image Classification
Jun 20, 2023The vulnerability of Convolutional Neural Networks (CNNs) to adversarial samples has recently garnered significant attention in the machine learning community. Furthermore, recent studies have unveiled the existence of universal adversarial perturbations (UAPs) that are image-agnostic and highly transferable across different CNN models. In this survey, our primary focus revolves around the recent advancements in UAPs specifically within the image classification task. We categorize UAPs into two distinct categories, i.e., noise-based attacks and generator-based attacks, thereby providing a comprehensive overview of representative methods within each category. By presenting the computational details of these methods, we summarize various loss functions employed for learning UAPs. Furthermore, we conduct a comprehensive evaluation of different loss functions within consistent training frameworks, including noise-based and generator-based. The evaluation covers a wide range of attack settings, including black-box and white-box attacks, targeted and untargeted attacks, as well as the examination of defense mechanisms. Our quantitative evaluation results yield several important findings pertaining to the effectiveness of different loss functions, the selection of surrogate CNN models, the impact of training data and data size, and the training frameworks involved in crafting universal attackers. Finally, to further promote future research on universal adversarial attacks, we provide some visualizations of the perturbations and discuss the potential research directions.
Boosting Adversarial Transferability via Fusing Logits of Top-1 Decomposed Feature
May 05, 2023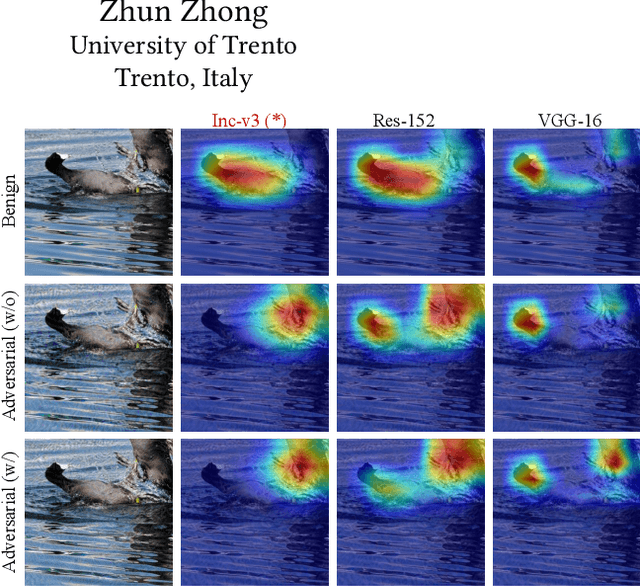

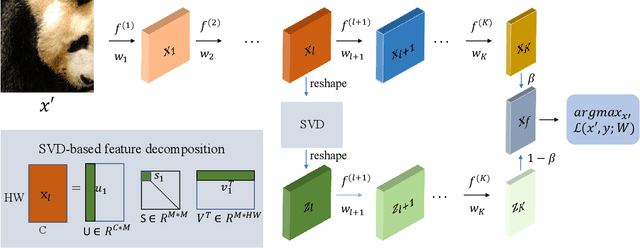

Recent research has shown that Deep Neural Networks (DNNs) are highly vulnerable to adversarial samples, which are highly transferable and can be used to attack other unknown black-box models. To improve the transferability of adversarial samples, several feature-based adversarial attack methods have been proposed to disrupt neuron activation in the middle layers. However, current state-of-the-art feature-based attack methods typically require additional computation costs for estimating the importance of neurons. To address this challenge, we propose a Singular Value Decomposition (SVD)-based feature-level attack method. Our approach is inspired by the discovery that eigenvectors associated with the larger singular values decomposed from the middle layer features exhibit superior generalization and attention properties. Specifically, we conduct the attack by retaining the decomposed Top-1 singular value-associated feature for computing the output logits, which are then combined with the original logits to optimize adversarial examples. Our extensive experimental results verify the effectiveness of our proposed method, which can be easily integrated into various baselines to significantly enhance the transferability of adversarial samples for disturbing normally trained CNNs and advanced defense strategies. The source code of this study is available at \textcolor{blue}{\href{https://anonymous.4open.science/r/SVD-SSA-13BF/README.md}{Link}}.
Logit Margin Matters: Improving Transferable Targeted Adversarial Attack by Logit Calibration
Mar 07, 2023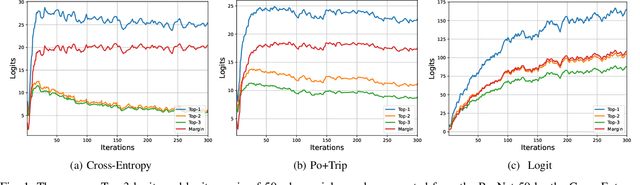
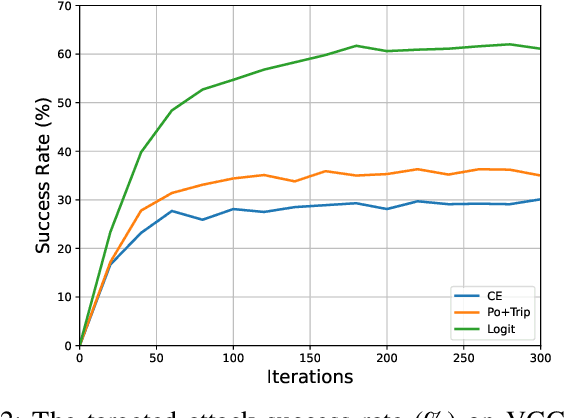
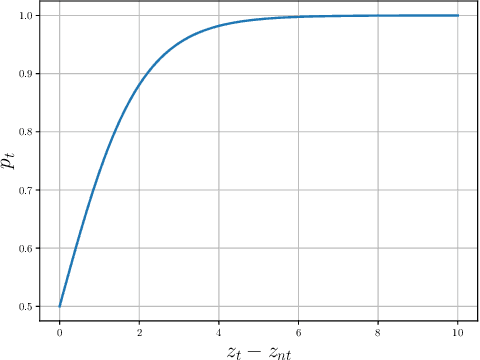
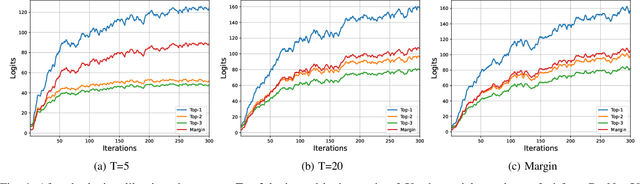
Previous works have extensively studied the transferability of adversarial samples in untargeted black-box scenarios. However, it still remains challenging to craft targeted adversarial examples with higher transferability than non-targeted ones. Recent studies reveal that the traditional Cross-Entropy (CE) loss function is insufficient to learn transferable targeted adversarial examples due to the issue of vanishing gradient. In this work, we provide a comprehensive investigation of the CE loss function and find that the logit margin between the targeted and untargeted classes will quickly obtain saturation in CE, which largely limits the transferability. Therefore, in this paper, we devote to the goal of continually increasing the logit margin along the optimization to deal with the saturation issue and propose two simple and effective logit calibration methods, which are achieved by downscaling the logits with a temperature factor and an adaptive margin, respectively. Both of them can effectively encourage optimization to produce a larger logit margin and lead to higher transferability. Besides, we show that minimizing the cosine distance between the adversarial examples and the classifier weights of the target class can further improve the transferability, which is benefited from downscaling logits via L2-normalization. Experiments conducted on the ImageNet dataset validate the effectiveness of the proposed methods, which outperform the state-of-the-art methods in black-box targeted attacks. The source code is available at \href{https://github.com/WJJLL/Target-Attack/}{Link}
Federated and Generalized Person Re-identification through Domain and Feature Hallucinating
Mar 08, 2022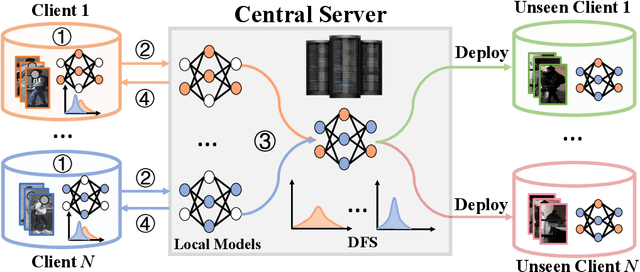
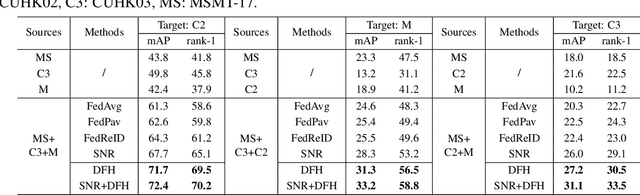
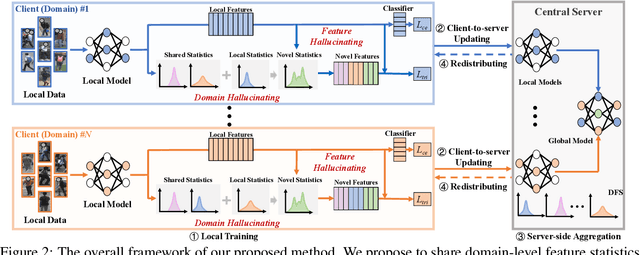

In this paper, we study the problem of federated domain generalization (FedDG) for person re-identification (re-ID), which aims to learn a generalized model with multiple decentralized labeled source domains. An empirical method (FedAvg) trains local models individually and averages them to obtain the global model for further local fine-tuning or deploying in unseen target domains. One drawback of FedAvg is neglecting the data distributions of other clients during local training, making the local model overfit local data and producing a poorly-generalized global model. To solve this problem, we propose a novel method, called "Domain and Feature Hallucinating (DFH)", to produce diverse features for learning generalized local and global models. Specifically, after each model aggregation process, we share the Domain-level Feature Statistics (DFS) among different clients without violating data privacy. During local training, the DFS are used to synthesize novel domain statistics with the proposed domain hallucinating, which is achieved by re-weighting DFS with random weights. Then, we propose feature hallucinating to diversify local features by scaling and shifting them to the distribution of the obtained novel domain. The synthesized novel features retain the original pair-wise similarities, enabling us to utilize them to optimize the model in a supervised manner. Extensive experiments verify that the proposed DFH can effectively improve the generalization ability of the global model. Our method achieves the state-of-the-art performance for FedDG on four large-scale re-ID benchmarks.
Cross-Modality Earth Mover's Distance for Visible Thermal Person Re-Identification
Mar 03, 2022
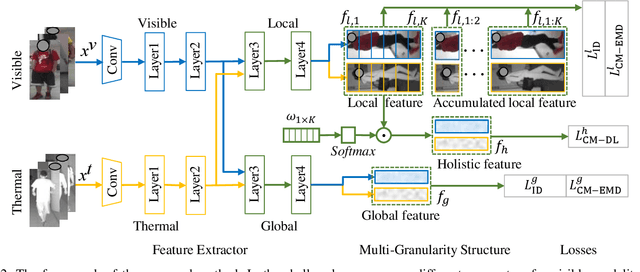
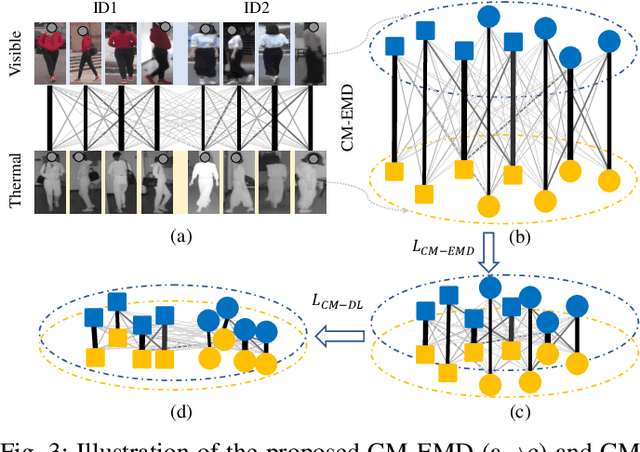

Visible thermal person re-identification (VT-ReID) suffers from the inter-modality discrepancy and intra-identity variations. Distribution alignment is a popular solution for VT-ReID, which, however, is usually restricted to the influence of the intra-identity variations. In this paper, we propose the Cross-Modality Earth Mover's Distance (CM-EMD) that can alleviate the impact of the intra-identity variations during modality alignment. CM-EMD selects an optimal transport strategy and assigns high weights to pairs that have a smaller intra-identity variation. In this manner, the model will focus on reducing the inter-modality discrepancy while paying less attention to intra-identity variations, leading to a more effective modality alignment. Moreover, we introduce two techniques to improve the advantage of CM-EMD. First, the Cross-Modality Discrimination Learning (CM-DL) is designed to overcome the discrimination degradation problem caused by modality alignment. By reducing the ratio between intra-identity and inter-identity variances, CM-DL leads the model to learn more discriminative representations. Second, we construct the Multi-Granularity Structure (MGS), enabling us to align modalities from both coarse- and fine-grained levels with the proposed CM-EMD. Extensive experiments show the benefits of the proposed CM-EMD and its auxiliary techniques (CM-DL and MGS). Our method achieves state-of-the-art performance on two VT-ReID benchmarks.
Joint Noise-Tolerant Learning and Meta Camera Shift Adaptation for Unsupervised Person Re-Identification
Mar 08, 2021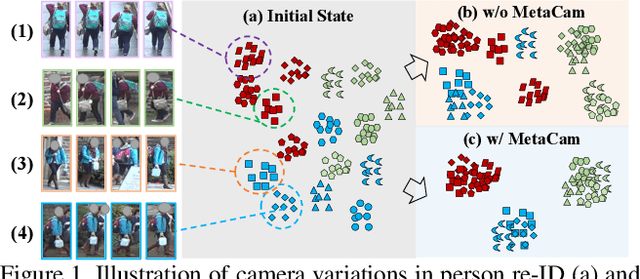

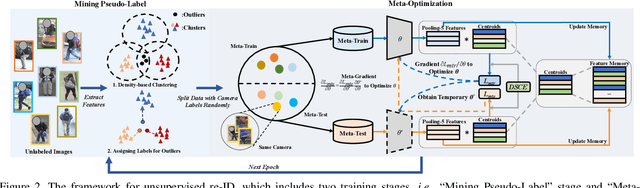
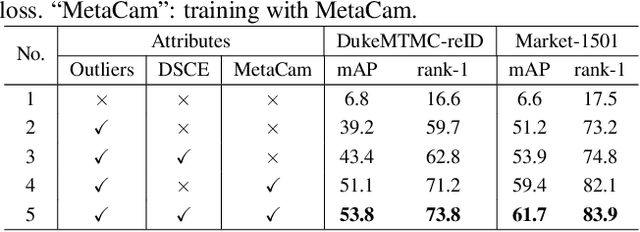
This paper considers the problem of unsupervised person re-identification (re-ID), which aims to learn discriminative models with unlabeled data. One popular method is to obtain pseudo-label by clustering and use them to optimize the model. Although this kind of approach has shown promising accuracy, it is hampered by 1) noisy labels produced by clustering and 2) feature variations caused by camera shift. The former will lead to incorrect optimization and thus hinders the model accuracy. The latter will result in assigning the intra-class samples of different cameras to different pseudo-label, making the model sensitive to camera variations. In this paper, we propose a unified framework to solve both problems. Concretely, we propose a Dynamic and Symmetric Cross-Entropy loss (DSCE) to deal with noisy samples and a camera-aware meta-learning algorithm (MetaCam) to adapt camera shift. DSCE can alleviate the negative effects of noisy samples and accommodate the change of clusters after each clustering step. MetaCam simulates cross-camera constraint by splitting the training data into meta-train and meta-test based on camera IDs. With the interacted gradient from meta-train and meta-test, the model is enforced to learn camera-invariant features. Extensive experiments on three re-ID benchmarks show the effectiveness and the complementary of the proposed DSCE and MetaCam. Our method outperforms the state-of-the-art methods on both fully unsupervised re-ID and unsupervised domain adaptive re-ID.