 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSirui Chen
Causal Evaluation of Language Models
May 01, 2024
Causal reasoning is viewed as crucial for achieving human-level machine intelligence. Recent advances in language models have expanded the horizons of artificial intelligence across various domains, sparking inquiries into their potential for causal reasoning. In this work, we introduce Causal evaluation of Language Models (CaLM), which, to the best of our knowledge, is the first comprehensive benchmark for evaluating the causal reasoning capabilities of language models. First, we propose the CaLM framework, which establishes a foundational taxonomy consisting of four modules: causal target (i.e., what to evaluate), adaptation (i.e., how to obtain the results), metric (i.e., how to measure the results), and error (i.e., how to analyze the bad results). This taxonomy defines a broad evaluation design space while systematically selecting criteria and priorities. Second, we compose the CaLM dataset, comprising 126,334 data samples, to provide curated sets of causal targets, adaptations, metrics, and errors, offering extensive coverage for diverse research pursuits. Third, we conduct an extensive evaluation of 28 leading language models on a core set of 92 causal targets, 9 adaptations, 7 metrics, and 12 error types. Fourth, we perform detailed analyses of the evaluation results across various dimensions (e.g., adaptation, scale). Fifth, we present 50 high-level empirical findings across 9 dimensions (e.g., model), providing valuable guidance for future language model development. Finally, we develop a multifaceted platform, including a website, leaderboards, datasets, and toolkits, to support scalable and adaptable assessments. We envision CaLM as an ever-evolving benchmark for the community, systematically updated with new causal targets, adaptations, models, metrics, and error types to reflect ongoing research advancements. Project website is at https://opencausalab.github.io/CaLM.
SpringGrasp: Synthesizing Compliant, Dexterous Grasps under Shape Uncertainty
Apr 25, 2024Generating stable and robust grasps on arbitrary objects is critical for dexterous robotic hands, marking a significant step towards advanced dexterous manipulation. Previous studies have mostly focused on improving differentiable grasping metrics with the assumption of precisely known object geometry. However, shape uncertainty is ubiquitous due to noisy and partial shape observations, which introduce challenges in grasp planning. We propose, SpringGrasp planner, a planner that considers uncertain observations of the object surface for synthesizing compliant dexterous grasps. A compliant dexterous grasp could minimize the effect of unexpected contact with the object, leading to more stable grasp with shape-uncertain objects. We introduce an analytical and differentiable metric, SpringGrasp metric, that evaluates the dynamic behavior of the entire compliant grasping process. Planning with SpringGrasp planner, our method achieves a grasp success rate of 89% from two viewpoints and 84% from a single viewpoints in experiment with a real robot on 14 common objects. Compared with a force-closure based planner, our method achieves at least 18% higher grasp success rate.
SIGformer: Sign-aware Graph Transformer for Recommendation
Apr 18, 2024In recommender systems, most graph-based methods focus on positive user feedback, while overlooking the valuable negative feedback. Integrating both positive and negative feedback to form a signed graph can lead to a more comprehensive understanding of user preferences. However, the existing efforts to incorporate both types of feedback are sparse and face two main limitations: 1) They process positive and negative feedback separately, which fails to holistically leverage the collaborative information within the signed graph; 2) They rely on MLPs or GNNs for information extraction from negative feedback, which may not be effective. To overcome these limitations, we introduce SIGformer, a new method that employs the transformer architecture to sign-aware graph-based recommendation. SIGformer incorporates two innovative positional encodings that capture the spectral properties and path patterns of the signed graph, enabling the full exploitation of the entire graph. Our extensive experiments across five real-world datasets demonstrate the superiority of SIGformer over state-of-the-art methods. The code is available at https://github.com/StupidThree/SIGformer.
One-Shot Transfer of Long-Horizon Extrinsic Manipulation Through Contact Retargeting
Apr 11, 2024Extrinsic manipulation, the use of environment contacts to achieve manipulation objectives, enables strategies that are otherwise impossible with a parallel jaw gripper. However, orchestrating a long-horizon sequence of contact interactions between the robot, object, and environment is notoriously challenging due to the scene diversity, large action space, and difficult contact dynamics. We observe that most extrinsic manipulation are combinations of short-horizon primitives, each of which depend strongly on initializing from a desirable contact configuration to succeed. Therefore, we propose to generalize one extrinsic manipulation trajectory to diverse objects and environments by retargeting contact requirements. We prepare a single library of robust short-horizon, goal-conditioned primitive policies, and design a framework to compose state constraints stemming from contacts specifications of each primitive. Given a test scene and a single demo prescribing the primitive sequence, our method enforces the state constraints on the test scene and find intermediate goal states using inverse kinematics. The goals are then tracked by the primitive policies. Using a 7+1 DoF robotic arm-gripper system, we achieved an overall success rate of 80.5% on hardware over 4 long-horizon extrinsic manipulation tasks, each with up to 4 primitives. Our experiments cover 10 objects and 6 environment configurations. We further show empirically that our method admits a wide range of demonstrations, and that contact retargeting is indeed the key to successfully combining primitives for long-horizon extrinsic manipulation. Code and additional details are available at stanford-tml.github.io/extrinsic-manipulation.
From GPT-4 to Gemini and Beyond: Assessing the Landscape of MLLMs on Generalizability, Trustworthiness and Causality through Four Modalities
Jan 29, 2024



Multi-modal Large Language Models (MLLMs) have shown impressive abilities in generating reasonable responses with respect to multi-modal contents. However, there is still a wide gap between the performance of recent MLLM-based applications and the expectation of the broad public, even though the most powerful OpenAI's GPT-4 and Google's Gemini have been deployed. This paper strives to enhance understanding of the gap through the lens of a qualitative study on the generalizability, trustworthiness, and causal reasoning capabilities of recent proprietary and open-source MLLMs across four modalities: ie, text, code, image, and video, ultimately aiming to improve the transparency of MLLMs. We believe these properties are several representative factors that define the reliability of MLLMs, in supporting various downstream applications. To be specific, we evaluate the closed-source GPT-4 and Gemini and 6 open-source LLMs and MLLMs. Overall we evaluate 230 manually designed cases, where the qualitative results are then summarized into 12 scores (ie, 4 modalities times 3 properties). In total, we uncover 14 empirical findings that are useful to understand the capabilities and limitations of both proprietary and open-source MLLMs, towards more reliable downstream multi-modal applications.
UOEP: User-Oriented Exploration Policy for Enhancing Long-Term User Experiences in Recommender Systems
Jan 17, 2024Reinforcement learning (RL) has gained traction for enhancing user long-term experiences in recommender systems by effectively exploring users' interests. However, modern recommender systems exhibit distinct user behavioral patterns among tens of millions of items, which increases the difficulty of exploration. For example, user behaviors with different activity levels require varying intensity of exploration, while previous studies often overlook this aspect and apply a uniform exploration strategy to all users, which ultimately hurts user experiences in the long run. To address these challenges, we propose User-Oriented Exploration Policy (UOEP), a novel approach facilitating fine-grained exploration among user groups. We first construct a distributional critic which allows policy optimization under varying quantile levels of cumulative reward feedbacks from users, representing user groups with varying activity levels. Guided by this critic, we devise a population of distinct actors aimed at effective and fine-grained exploration within its respective user group. To simultaneously enhance diversity and stability during the exploration process, we further introduce a population-level diversity regularization term and a supervision module. Experimental results on public recommendation datasets demonstrate that our approach outperforms all other baselines in terms of long-term performance, validating its user-oriented exploration effectiveness. Meanwhile, further analyses reveal our approach's benefits of improved performance for low-activity users as well as increased fairness among users.
Incorporating Judgment Prediction into Legal Case Retrieval via Law-aware Generative Retrieval
Dec 15, 2023Legal case retrieval and judgment prediction are crucial components in intelligent legal systems. In practice, determining whether two cases share the same charges through legal judgment prediction is essential for establishing their relevance in case retrieval. However, current studies on legal case retrieval merely focus on the semantic similarity between paired cases, ignoring their charge-level consistency. This separation leads to a lack of context and potential inaccuracies in the case retrieval that can undermine trust in the system's decision-making process. Given the guidance role of laws to both tasks and inspired by the success of generative retrieval, in this work, we propose to incorporate judgment prediction into legal case retrieval, achieving a novel law-aware Generative legal case retrieval method called Gear. Specifically, Gear first extracts rationales (key circumstances and key elements) for legal cases according to the definition of charges in laws, ensuring a shared and informative representation for both tasks. Then in accordance with the inherent hierarchy of laws, we construct a law structure constraint tree and assign law-aware semantic identifier(s) to each case based on this tree. These designs enable a unified traversal from the root, through intermediate charge nodes, to case-specific leaf nodes, which respectively correspond to two tasks. Additionally, in the training, we also introduce a revision loss that jointly minimizes the discrepancy between the identifiers of predicted and labeled charges as well as retrieved cases, improving the accuracy and consistency for both tasks. Extensive experiments on two datasets demonstrate that Gear consistently outperforms state-of-the-art methods in legal case retrieval while maintaining competitive judgment prediction performance.
Controllable Multi-Objective Re-ranking with Policy Hypernetworks
Jun 13, 2023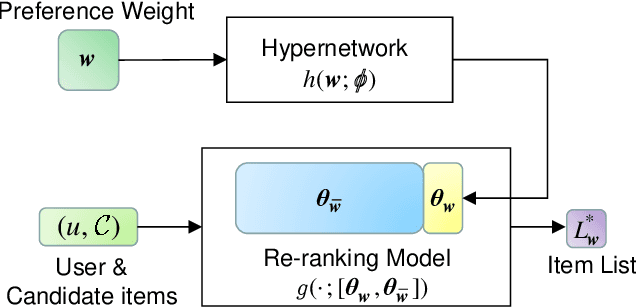
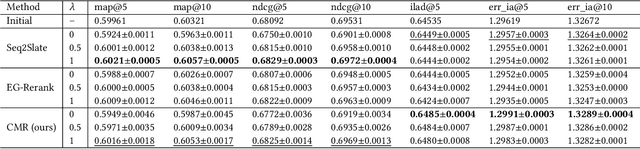
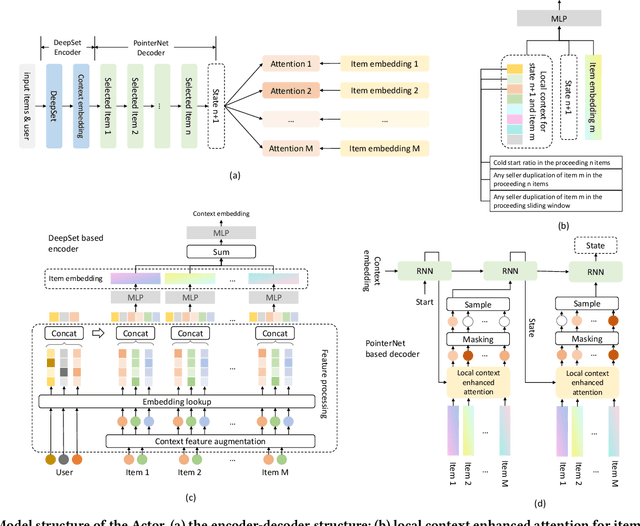
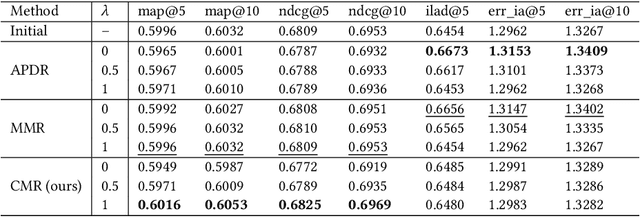
Multi-stage ranking pipelines have become widely used strategies in modern recommender systems, where the final stage aims to return a ranked list of items that balances a number of requirements such as user preference, diversity, novelty etc. Linear scalarization is arguably the most widely used technique to merge multiple requirements into one optimization objective, by summing up the requirements with certain preference weights. Existing final-stage ranking methods often adopt a static model where the preference weights are determined during offline training and kept unchanged during online serving. Whenever a modification of the preference weights is needed, the model has to be re-trained, which is time and resources inefficient. Meanwhile, the most appropriate weights may vary greatly for different groups of targeting users or at different time periods (e.g., during holiday promotions). In this paper, we propose a framework called controllable multi-objective re-ranking (CMR) which incorporates a hypernetwork to generate parameters for a re-ranking model according to different preference weights. In this way, CMR is enabled to adapt the preference weights according to the environment changes in an online manner, without retraining the models. Moreover, we classify practical business-oriented tasks into four main categories and seamlessly incorporate them in a new proposed re-ranking model based on an Actor-Evaluator framework, which serves as a reliable real-world testbed for CMR. Offline experiments based on the dataset collected from Taobao App showed that CMR improved several popular re-ranking models by using them as underlying models. Online A/B tests also demonstrated the effectiveness and trustworthiness of CMR.
Synthesize Dexterous Nonprehensile Pregrasp for Ungraspable Objects
May 08, 2023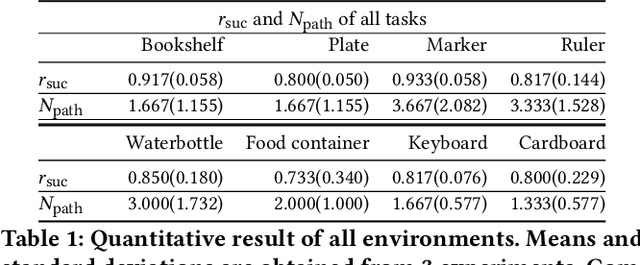
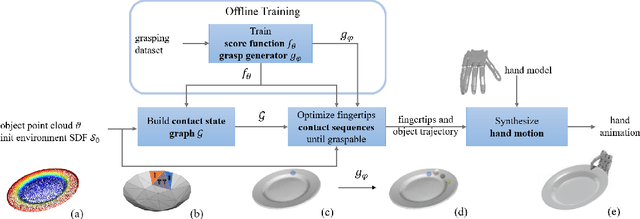
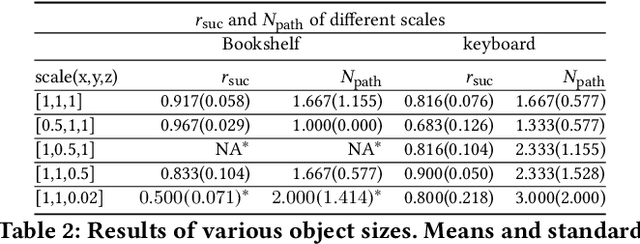

Daily objects embedded in a contextual environment are often ungraspable initially. Whether it is a book sandwiched by other books on a fully packed bookshelf or a piece of paper lying flat on the desk, a series of nonprehensile pregrasp maneuvers is required to manipulate the object into a graspable state. Humans are proficient at utilizing environmental contacts to achieve manipulation tasks that are otherwise impossible, but synthesizing such nonprehensile pregrasp behaviors is challenging to existing methods. We present a novel method that combines graph search, optimal control, and a learning-based objective function to synthesize physically realistic and diverse nonprehensile pre-grasp motions that leverage the external contacts. Since the ``graspability'' of an object in context with its surrounding is difficult to define, we utilize a dataset of dexterous grasps to learn a metric which implicitly takes into account the exposed surface of the object and the finger tip locations. Our method can efficiently discover hand and object trajectories that are certified to be physically feasible by the simulation and kinematically achievable by the dexterous hand. We evaluate our method on eight challenging scenarios where nonprehensile pre-grasps are required to succeed. We also show that our method can be applied to unseen objects different from those in the training dataset. Finally, we report quantitative analyses on generalization and robustness of our method, as well as an ablation study.
* 11 pages, 9 figures, SIGGRAPH Conference Proceedings 2023
STAS: Spatial-Temporal Return Decomposition for Multi-agent Reinforcement Learning
Apr 15, 2023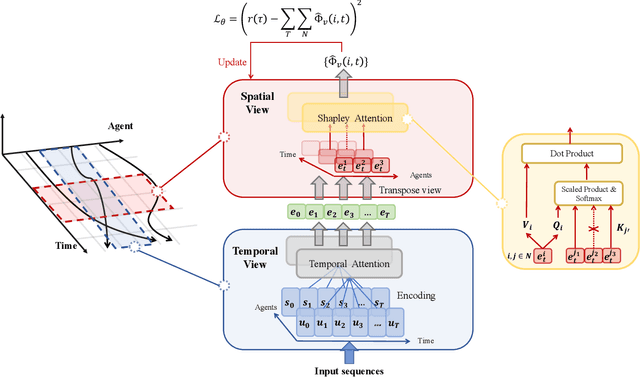
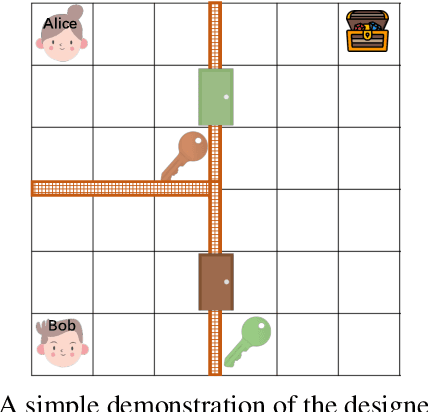
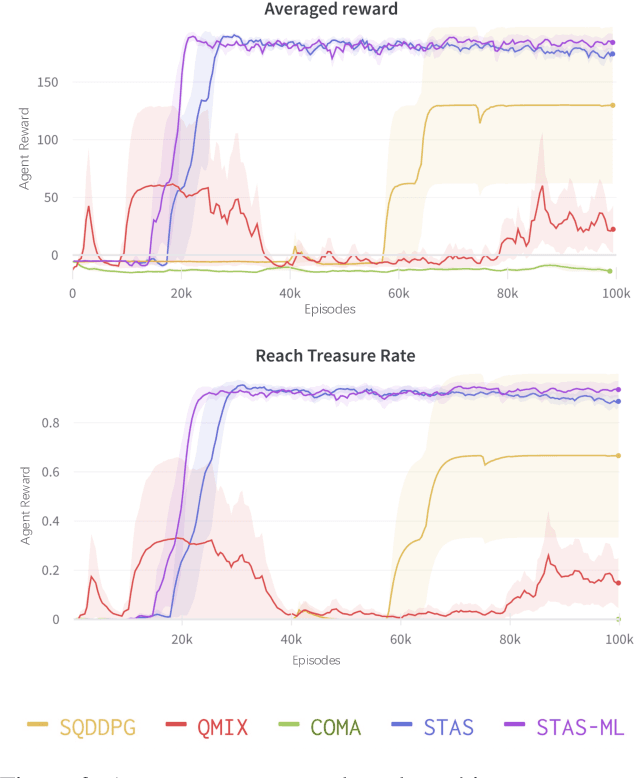
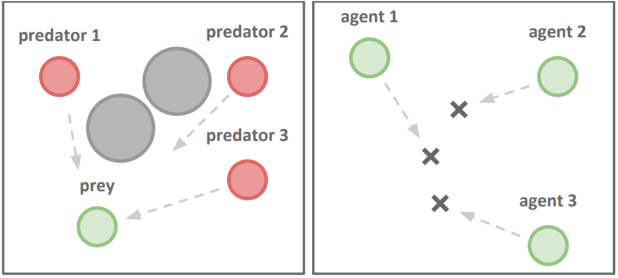
Centralized Training with Decentralized Execution (CTDE) has been proven to be an effective paradigm in cooperative multi-agent reinforcement learning (MARL). One of the major challenges is yet credit assignment, which aims to credit agents by their contributions. Prior studies focus on either implicitly decomposing the joint value function or explicitly computing the payoff distribution of all agents. However, in episodic reinforcement learning settings where global rewards can only be revealed at the end of the episode, existing methods usually fail to work. They lack the functionality of modeling complicated relations of the delayed global reward in the temporal dimension and suffer from large variance and bias. We propose a novel method named Spatial-Temporal Attention with Shapley (STAS) for return decomposition; STAS learns credit assignment in both the temporal and the spatial dimension. It first decomposes the global return back to each time step, then utilizes Shapley Value to redistribute the individual payoff from the decomposed global reward. To mitigate the computational complexity of Shapley Value, we introduce an approximation of marginal contribution and utilize Monte Carlo sampling to estimate Shapley Value. We evaluate our method on the classical Alice & Bob example and Multi-agent Particle Environments benchmarks across different scenarios, and we show our methods achieve an effective spatial-temporal credit assignment and outperform all state-of-art baselines.