 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYingchun Wang
From GPT-4 to Gemini and Beyond: Assessing the Landscape of MLLMs on Generalizability, Trustworthiness and Causality through Four Modalities
Jan 29, 2024




Multi-modal Large Language Models (MLLMs) have shown impressive abilities in generating reasonable responses with respect to multi-modal contents. However, there is still a wide gap between the performance of recent MLLM-based applications and the expectation of the broad public, even though the most powerful OpenAI's GPT-4 and Google's Gemini have been deployed. This paper strives to enhance understanding of the gap through the lens of a qualitative study on the generalizability, trustworthiness, and causal reasoning capabilities of recent proprietary and open-source MLLMs across four modalities: ie, text, code, image, and video, ultimately aiming to improve the transparency of MLLMs. We believe these properties are several representative factors that define the reliability of MLLMs, in supporting various downstream applications. To be specific, we evaluate the closed-source GPT-4 and Gemini and 6 open-source LLMs and MLLMs. Overall we evaluate 230 manually designed cases, where the qualitative results are then summarized into 12 scores (ie, 4 modalities times 3 properties). In total, we uncover 14 empirical findings that are useful to understand the capabilities and limitations of both proprietary and open-source MLLMs, towards more reliable downstream multi-modal applications.
Fake Alignment: Are LLMs Really Aligned Well?
Nov 14, 2023The growing awareness of safety concerns in large language models (LLMs) has sparked considerable interest in the evaluation of safety within current research endeavors. This study investigates an interesting issue pertaining to the evaluation of LLMs, namely the substantial discrepancy in performance between multiple-choice questions and open-ended questions. Inspired by research on jailbreak attack patterns, we argue this is caused by mismatched generalization. That is, the LLM does not have a comprehensive understanding of the complex concept of safety. Instead, it only remembers what to answer for open-ended safety questions, which makes it unable to solve other forms of safety tests. We refer to this phenomenon as fake alignment and construct a comparative benchmark to empirically verify its existence in LLMs. Such fake alignment renders previous evaluation protocols unreliable. To address this, we introduce the Fake alIgNment Evaluation (FINE) framework and two novel metrics--Consistency Score (CS) and Consistent Safety Score (CSS), which jointly assess two complementary forms of evaluation to quantify fake alignment and obtain corrected performance estimates. Applying FINE to 14 widely-used LLMs reveals several models with purported safety are poorly aligned in practice. Our work highlights potential limitations in prevailing alignment methodologies.
Flames: Benchmarking Value Alignment of Chinese Large Language Models
Nov 12, 2023The widespread adoption of large language models (LLMs) across various regions underscores the urgent need to evaluate their alignment with human values. Current benchmarks, however, fall short of effectively uncovering safety vulnerabilities in LLMs. Despite numerous models achieving high scores and 'topping the chart' in these evaluations, there is still a significant gap in LLMs' deeper alignment with human values and achieving genuine harmlessness. To this end, this paper proposes the first highly adversarial benchmark named Flames, consisting of 2,251 manually crafted prompts, ~18.7K model responses with fine-grained annotations, and a specified scorer. Our framework encompasses both common harmlessness principles, such as fairness, safety, legality, and data protection, and a unique morality dimension that integrates specific Chinese values such as harmony. Based on the framework, we carefully design adversarial prompts that incorporate complex scenarios and jailbreaking methods, mostly with implicit malice. By prompting mainstream LLMs with such adversarially constructed prompts, we obtain model responses, which are then rigorously annotated for evaluation. Our findings indicate that all the evaluated LLMs demonstrate relatively poor performance on Flames, particularly in the safety and fairness dimensions. Claude emerges as the best-performing model overall, but with its harmless rate being only 63.08% while GPT-4 only scores 39.04%. The complexity of Flames has far exceeded existing benchmarks, setting a new challenge for contemporary LLMs and highlighting the need for further alignment of LLMs. To efficiently evaluate new models on the benchmark, we develop a specified scorer capable of scoring LLMs across multiple dimensions, achieving an accuracy of 77.4%. The Flames Benchmark is publicly available on https://github.com/AIFlames/Flames.
Towards Fairer and More Efficient Federated Learning via Multidimensional Personalized Edge Models
Feb 09, 2023



Federated learning (FL) is an emerging technique that trains massive and geographically distributed edge data while maintaining privacy. However, FL has inherent challenges in terms of fairness and computational efficiency due to the rising heterogeneity of edges, and thus usually result in sub-optimal performance in recent state-of-the-art (SOTA) solutions. In this paper, we propose a Customized Federated Learning (CFL) system to eliminate FL heterogeneity from multiple dimensions. Specifically, CFL tailors personalized models from the specially designed global model for each client, jointly guided an online trained model-search helper and a novel aggregation algorithm. Extensive experiments demonstrate that CFL has full-stack advantages for both FL training and edge reasoning and significantly improves the SOTA performance w.r.t. model accuracy (up to 7.2% in the non-heterogeneous environment and up to 21.8% in the heterogeneous environment), efficiency, and FL fairness.
Data Quality-aware Mixed-precision Quantization via Hybrid Reinforcement Learning
Feb 09, 2023



Mixed-precision quantization mostly predetermines the model bit-width settings before actual training due to the non-differential bit-width sampling process, obtaining sub-optimal performance. Worse still, the conventional static quality-consistent training setting, i.e., all data is assumed to be of the same quality across training and inference, overlooks data quality changes in real-world applications which may lead to poor robustness of the quantized models. In this paper, we propose a novel Data Quality-aware Mixed-precision Quantization framework, dubbed DQMQ, to dynamically adapt quantization bit-widths to different data qualities. The adaption is based on a bit-width decision policy that can be learned jointly with the quantization training. Concretely, DQMQ is modeled as a hybrid reinforcement learning (RL) task that combines model-based policy optimization with supervised quantization training. By relaxing the discrete bit-width sampling to a continuous probability distribution that is encoded with few learnable parameters, DQMQ is differentiable and can be directly optimized end-to-end with a hybrid optimization target considering both task performance and quantization benefits. Trained on mixed-quality image datasets, DQMQ can implicitly select the most proper bit-width for each layer when facing uneven input qualities. Extensive experiments on various benchmark datasets and networks demonstrate the superiority of DQMQ against existing fixed/mixed-precision quantization methods.
Exploring Optimal Substructure for Out-of-distribution Generalization via Feature-targeted Model Pruning
Dec 19, 2022



Recent studies show that even highly biased dense networks contain an unbiased substructure that can achieve better out-of-distribution (OOD) generalization than the original model. Existing works usually search the invariant subnetwork using modular risk minimization (MRM) with out-domain data. Such a paradigm may bring about two potential weaknesses: 1) Unfairness, due to the insufficient observation of out-domain data during training; and 2) Sub-optimal OOD generalization, due to the feature-untargeted model pruning on the whole data distribution. In this paper, we propose a novel Spurious Feature-targeted model Pruning framework, dubbed SFP, to automatically explore invariant substructures without referring to the above weaknesses. Specifically, SFP identifies in-distribution (ID) features during training using our theoretically verified task loss, upon which, SFP can perform ID targeted-model pruning that removes branches with strong dependencies on ID features. Notably, by attenuating the projections of spurious features into model space, SFP can push the model learning toward invariant features and pull that out of environmental features, devising optimal OOD generalization. Moreover, we also conduct detailed theoretical analysis to provide the rationality guarantee and a proof framework for OOD structures via model sparsity, and for the first time, reveal how a highly biased data distribution affects the model's OOD generalization. Extensive experiments on various OOD datasets show that SFP can significantly outperform both structure-based and non-structure OOD generalization SOTAs, with accuracy improvement up to 4.72% and 23.35%, respectively.
Efficient Stein Variational Inference for Reliable Distribution-lossless Network Pruning
Dec 07, 2022



Network pruning is a promising way to generate light but accurate models and enable their deployment on resource-limited edge devices. However, the current state-of-the-art assumes that the effective sub-network and the other superfluous parameters in the given network share the same distribution, where pruning inevitably involves a distribution truncation operation. They usually eliminate values near zero. While simple, it may not be the most appropriate method, as effective models may naturally have many small values associated with them. Removing near-zero values already embedded in model space may significantly reduce model accuracy. Another line of work has proposed to assign discrete prior over all possible sub-structures that still rely on human-crafted prior hypotheses. Worse still, existing methods use regularized point estimates, namely Hard Pruning, that can not provide error estimations and fail reliability justification for the pruned networks. In this paper, we propose a novel distribution-lossless pruning method, named DLLP, to theoretically find the pruned lottery within Bayesian treatment. Specifically, DLLP remodels the vanilla networks as discrete priors for the latent pruned model and the other redundancy. More importantly, DLLP uses Stein Variational Inference to approach the latent prior and effectively bypasses calculating KL divergence with unknown distribution. Extensive experiments based on small Cifar-10 and large-scaled ImageNet demonstrate that our method can obtain sparser networks with great generalization performance while providing quantified reliability for the pruned model.
Feature Correlation-guided Knowledge Transfer for Federated Self-supervised Learning
Nov 14, 2022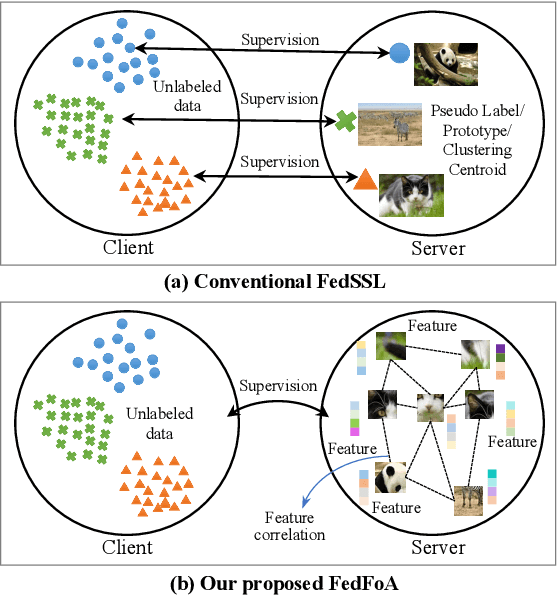
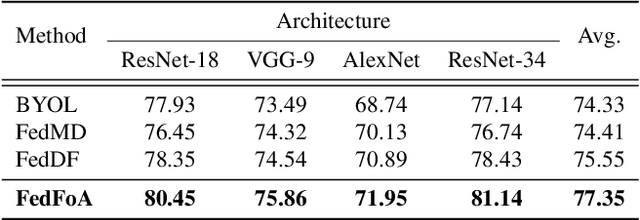
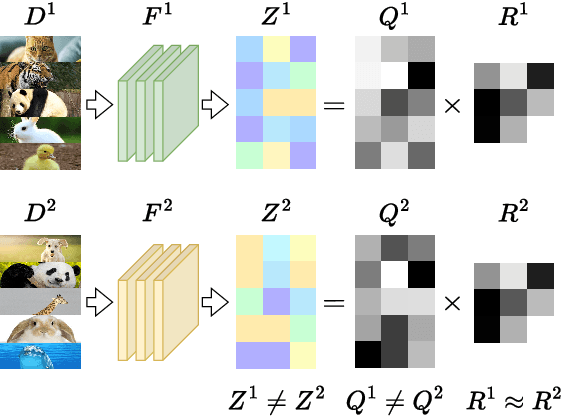
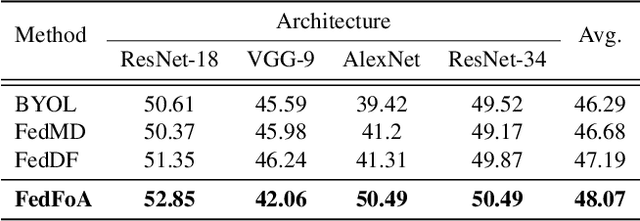
To eliminate the requirement of fully-labeled data for supervised model training in traditional Federated Learning (FL), extensive attention has been paid to the application of Self-supervised Learning (SSL) approaches on FL to tackle the label scarcity problem. Previous works on Federated SSL generally fall into two categories: parameter-based model aggregation (i.e., FedAvg, applicable to homogeneous cases) or data-based feature sharing (i.e., knowledge distillation, applicable to heterogeneous cases) to achieve knowledge transfer among multiple unlabeled clients. Despite the progress, all of them inevitably rely on some assumptions, such as homogeneous models or the existence of an additional public dataset, which hinder the universality of the training frameworks for more general scenarios. Therefore, in this paper, we propose a novel and general method named Federated Self-supervised Learning with Feature-correlation based Aggregation (FedFoA) to tackle the above limitations in a communication-efficient and privacy-preserving manner. Our insight is to utilize feature correlation to align the feature mappings and calibrate the local model updates across clients during their local training process. More specifically, we design a factorization-based method to extract the cross-feature relation matrix from the local representations. Then, the relation matrix can be regarded as a carrier of semantic information to perform the aggregation phase. We prove that FedFoA is a model-agnostic training framework and can be easily compatible with state-of-the-art unsupervised FL methods. Extensive empirical experiments demonstrate that our proposed approach outperforms the state-of-the-art methods by a significant margin.
Towards the Objective Speech Assessment of Smoking Status based on Voice Features: A Review of the Literature
Jun 15, 2021
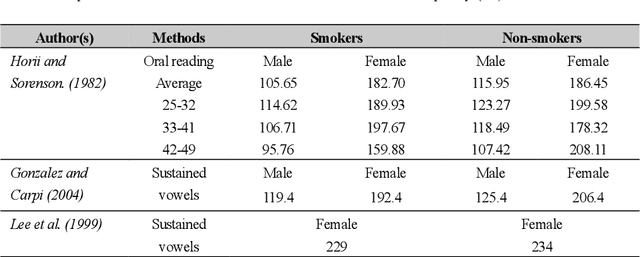
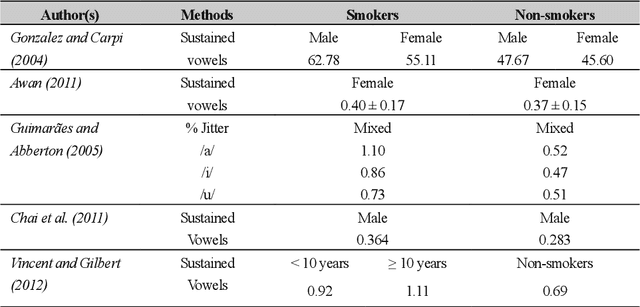
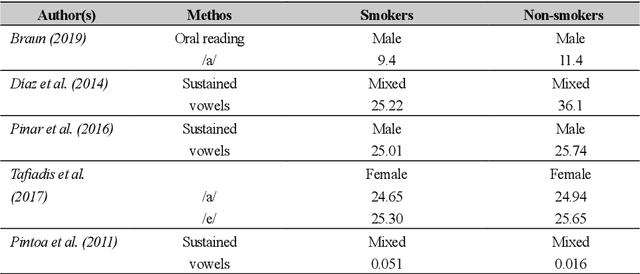
In smoking cessation clinical research and practice, objective validation of self-reported smoking status is crucial for ensuring the reliability of the primary outcome, that is, smoking abstinence. Speech signals convey important information about a speaker, such as age, gender, body size, emotional state, and health state. We investigated (1) if smoking could measurably alter voice features, (2) if smoking cessation could lead to changes in voice, and therefore (3) if the voice-based smoking status assessment has the potential to be used as an objective smoking cessation validation method.