 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYu-Gang Jiang
Eyes Can Deceive: Benchmarking Counterfactual Reasoning Abilities of Multi-modal Large Language Models
Apr 19, 2024
Counterfactual reasoning, as a crucial manifestation of human intelligence, refers to making presuppositions based on established facts and extrapolating potential outcomes. Existing multimodal large language models (MLLMs) have exhibited impressive cognitive and reasoning capabilities, which have been examined across a wide range of Visual Question Answering (VQA) benchmarks. Nevertheless, how will existing MLLMs perform when faced with counterfactual questions? To answer this question, we first curate a novel \textbf{C}ounter\textbf{F}actual \textbf{M}ulti\textbf{M}odal reasoning benchmark, abbreviated as \textbf{CFMM}, to systematically assess the counterfactual reasoning capabilities of MLLMs. Our CFMM comprises six challenging tasks, each including hundreds of carefully human-labeled counterfactual questions, to evaluate MLLM's counterfactual reasoning capabilities across diverse aspects. Through experiments, interestingly, we find that existing MLLMs prefer to believe what they see, but ignore the counterfactual presuppositions presented in the question, thereby leading to inaccurate responses. Furthermore, we evaluate a wide range of prevalent MLLMs on our proposed CFMM. The significant gap between their performance on our CFMM and that on several VQA benchmarks indicates that there is still considerable room for improvement in existing MLLMs toward approaching human-level intelligence. On the other hand, through boosting MLLMs performances on our CFMM in the future, potential avenues toward developing MLLMs with advanced intelligence can be explored.
The Dog Walking Theory: Rethinking Convergence in Federated Learning
Apr 18, 2024Federated learning (FL) is a collaborative learning paradigm that allows different clients to train one powerful global model without sharing their private data. Although FL has demonstrated promising results in various applications, it is known to suffer from convergence issues caused by the data distribution shift across different clients, especially on non-independent and identically distributed (non-IID) data. In this paper, we study the convergence of FL on non-IID data and propose a novel \emph{Dog Walking Theory} to formulate and identify the missing element in existing research. The Dog Walking Theory describes the process of a dog walker leash walking multiple dogs from one side of the park to the other. The goal of the dog walker is to arrive at the right destination while giving the dogs enough exercise (i.e., space exploration). In FL, the server is analogous to the dog walker while the clients are analogous to the dogs. This analogy allows us to identify one crucial yet missing element in existing FL algorithms: the leash that guides the exploration of the clients. To address this gap, we propose a novel FL algorithm \emph{FedWalk} that leverages an external easy-to-converge task at the server side as a \emph{leash task} to guide the local training of the clients. We theoretically analyze the convergence of FedWalk with respect to data heterogeneity (between server and clients) and task discrepancy (between the leash and the original tasks). Experiments on multiple benchmark datasets demonstrate the superiority of FedWalk over state-of-the-art FL methods under both IID and non-IID settings.
Learning to Rank Patches for Unbiased Image Redundancy Reduction
Mar 31, 2024Images suffer from heavy spatial redundancy because pixels in neighboring regions are spatially correlated. Existing approaches strive to overcome this limitation by reducing less meaningful image regions. However, current leading methods rely on supervisory signals. They may compel models to preserve content that aligns with labeled categories and discard content belonging to unlabeled categories. This categorical inductive bias makes these methods less effective in real-world scenarios. To address this issue, we propose a self-supervised framework for image redundancy reduction called Learning to Rank Patches (LTRP). We observe that image reconstruction of masked image modeling models is sensitive to the removal of visible patches when the masking ratio is high (e.g., 90\%). Building upon it, we implement LTRP via two steps: inferring the semantic density score of each patch by quantifying variation between reconstructions with and without this patch, and learning to rank the patches with the pseudo score. The entire process is self-supervised, thus getting out of the dilemma of categorical inductive bias. We design extensive experiments on different datasets and tasks. The results demonstrate that LTRP outperforms both supervised and other self-supervised methods due to the fair assessment of image content.
OmniVid: A Generative Framework for Universal Video Understanding
Mar 26, 2024The core of video understanding tasks, such as recognition, captioning, and tracking, is to automatically detect objects or actions in a video and analyze their temporal evolution. Despite sharing a common goal, different tasks often rely on distinct model architectures and annotation formats. In contrast, natural language processing benefits from a unified output space, i.e., text sequences, which simplifies the training of powerful foundational language models, such as GPT-3, with extensive training corpora. Inspired by this, we seek to unify the output space of video understanding tasks by using languages as labels and additionally introducing time and box tokens. In this way, a variety of video tasks could be formulated as video-grounded token generation. This enables us to address various types of video tasks, including classification (such as action recognition), captioning (covering clip captioning, video question answering, and dense video captioning), and localization tasks (such as visual object tracking) within a fully shared encoder-decoder architecture, following a generative framework. Through comprehensive experiments, we demonstrate such a simple and straightforward idea is quite effective and can achieve state-of-the-art or competitive results on seven video benchmarks, providing a novel perspective for more universal video understanding. Code is available at https://github.com/wangjk666/OmniVid.
FDGaussian: Fast Gaussian Splatting from Single Image via Geometric-aware Diffusion Model
Mar 15, 2024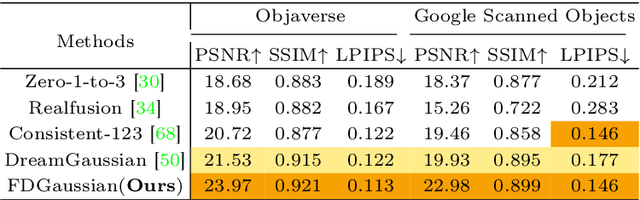
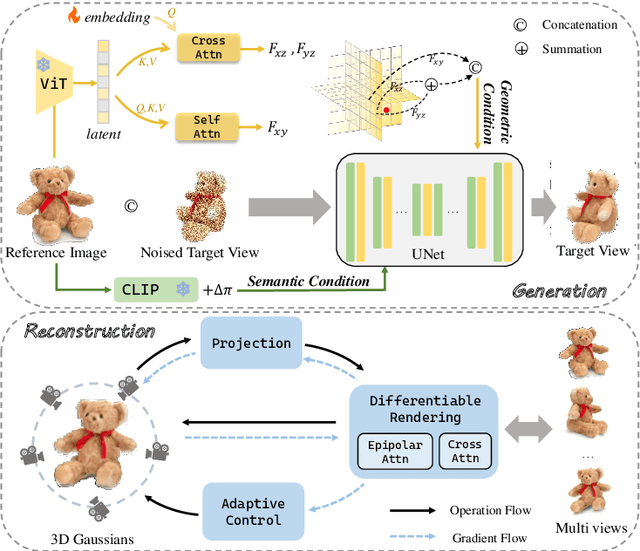
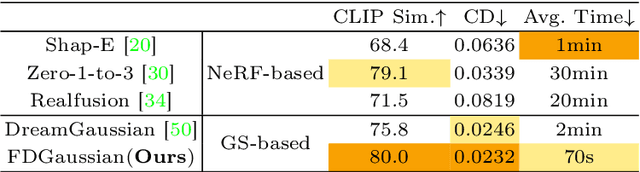
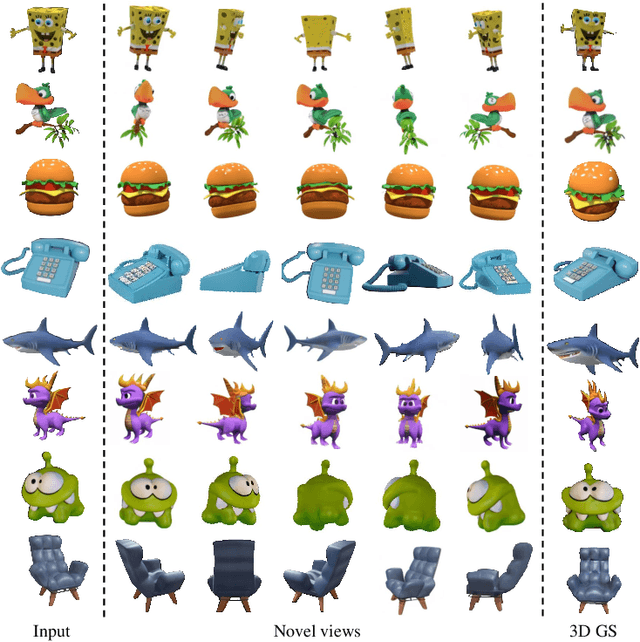
Reconstructing detailed 3D objects from single-view images remains a challenging task due to the limited information available. In this paper, we introduce FDGaussian, a novel two-stage framework for single-image 3D reconstruction. Recent methods typically utilize pre-trained 2D diffusion models to generate plausible novel views from the input image, yet they encounter issues with either multi-view inconsistency or lack of geometric fidelity. To overcome these challenges, we propose an orthogonal plane decomposition mechanism to extract 3D geometric features from the 2D input, enabling the generation of consistent multi-view images. Moreover, we further accelerate the state-of-the-art Gaussian Splatting incorporating epipolar attention to fuse images from different viewpoints. We demonstrate that FDGaussian generates images with high consistency across different views and reconstructs high-quality 3D objects, both qualitatively and quantitatively. More examples can be found at our website https://qjfeng.net/FDGaussian/.
Whose Side Are You On? Investigating the Political Stance of Large Language Models
Mar 15, 2024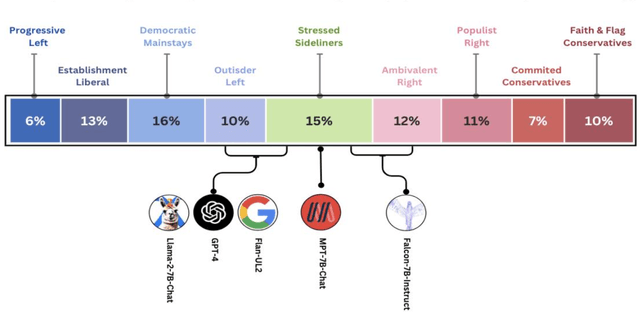
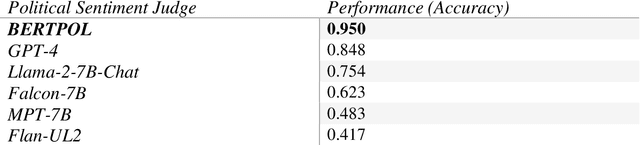
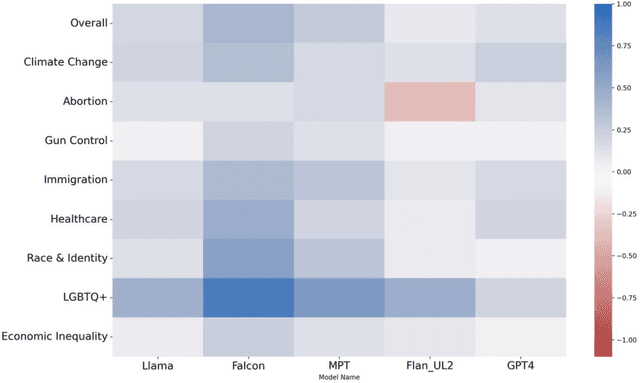

Large Language Models (LLMs) have gained significant popularity for their application in various everyday tasks such as text generation, summarization, and information retrieval. As the widespread adoption of LLMs continues to surge, it becomes increasingly crucial to ensure that these models yield responses that are politically impartial, with the aim of preventing information bubbles, upholding fairness in representation, and mitigating confirmation bias. In this paper, we propose a quantitative framework and pipeline designed to systematically investigate the political orientation of LLMs. Our investigation delves into the political alignment of LLMs across a spectrum of eight polarizing topics, spanning from abortion to LGBTQ issues. Across topics, the results indicate that LLMs exhibit a tendency to provide responses that closely align with liberal or left-leaning perspectives rather than conservative or right-leaning ones when user queries include details pertaining to occupation, race, or political affiliation. The findings presented in this study not only reaffirm earlier observations regarding the left-leaning characteristics of LLMs but also surface particular attributes, such as occupation, that are particularly susceptible to such inclinations even when directly steered towards conservatism. As a recommendation to avoid these models providing politicised responses, users should be mindful when crafting queries, and exercise caution in selecting neutral prompt language.
From Canteen Food to Daily Meals: Generalizing Food Recognition to More Practical Scenarios
Mar 12, 2024


The precise recognition of food categories plays a pivotal role for intelligent health management, attracting significant research attention in recent years. Prominent benchmarks, such as Food-101 and VIREO Food-172, provide abundant food image resources that catalyze the prosperity of research in this field. Nevertheless, these datasets are well-curated from canteen scenarios and thus deviate from food appearances in daily life. This discrepancy poses great challenges in effectively transferring classifiers trained on these canteen datasets to broader daily-life scenarios encountered by humans. Toward this end, we present two new benchmarks, namely DailyFood-172 and DailyFood-16, specifically designed to curate food images from everyday meals. These two datasets are used to evaluate the transferability of approaches from the well-curated food image domain to the everyday-life food image domain. In addition, we also propose a simple yet effective baseline method named Multi-Cluster Reference Learning (MCRL) to tackle the aforementioned domain gap. MCRL is motivated by the observation that food images in daily-life scenarios exhibit greater intra-class appearance variance compared with those in well-curated benchmarks. Notably, MCRL can be seamlessly coupled with existing approaches, yielding non-trivial performance enhancements. We hope our new benchmarks can inspire the community to explore the transferability of food recognition models trained on well-curated datasets toward practical real-life applications.
Lumen: Unleashing Versatile Vision-Centric Capabilities of Large Multimodal Models
Mar 12, 2024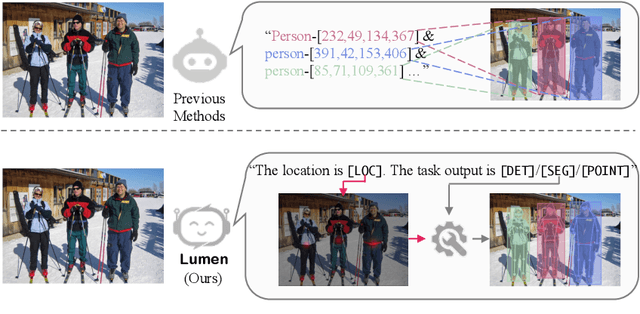
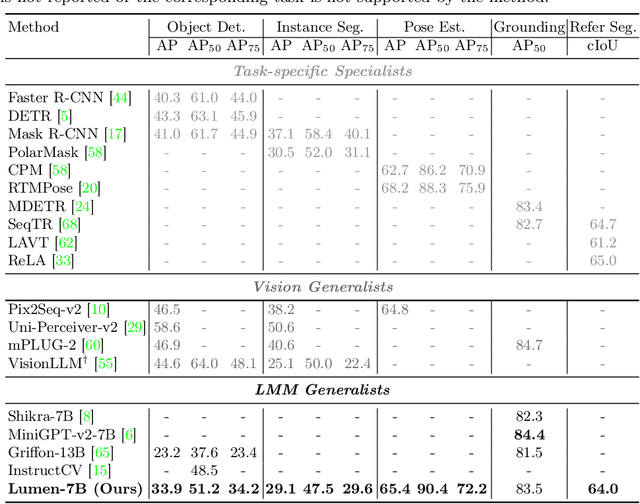
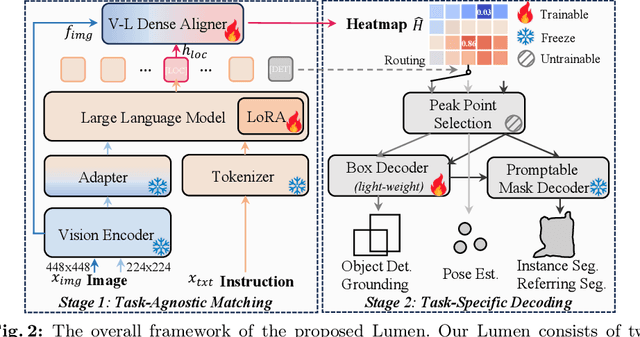

Large Multimodal Model (LMM) is a hot research topic in the computer vision area and has also demonstrated remarkable potential across multiple disciplinary fields. A recent trend is to further extend and enhance the perception capabilities of LMMs. The current methods follow the paradigm of adapting the visual task outputs to the format of the language model, which is the main component of a LMM. This adaptation leads to convenient development of such LMMs with minimal modifications, however, it overlooks the intrinsic characteristics of diverse visual tasks and hinders the learning of perception capabilities. To address this issue, we propose a novel LMM architecture named Lumen, a Large multimodal model with versatile vision-centric capability enhancement. We decouple the LMM's learning of perception capabilities into task-agnostic and task-specific stages. Lumen first promotes fine-grained vision-language concept alignment, which is the fundamental capability for various visual tasks. Thus the output of the task-agnostic stage is a shared representation for all the tasks we address in this paper. Then the task-specific decoding is carried out by flexibly routing the shared representation to lightweight task decoders with negligible training efforts. Benefiting from such a decoupled design, our Lumen surpasses existing LMM-based approaches on the COCO detection benchmark with a clear margin and exhibits seamless scalability to additional visual tasks. Furthermore, we also conduct comprehensive ablation studies and generalization evaluations for deeper insights. The code will be released at https://github.com/SxJyJay/Lumen.
Doubly Abductive Counterfactual Inference for Text-based Image Editing
Mar 05, 2024

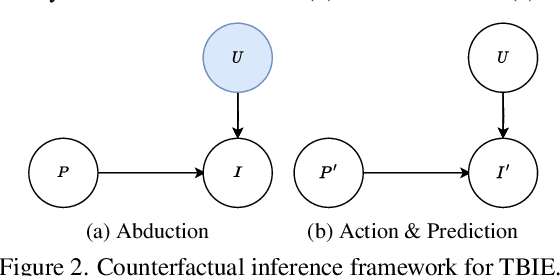

We study text-based image editing (TBIE) of a single image by counterfactual inference because it is an elegant formulation to precisely address the requirement: the edited image should retain the fidelity of the original one. Through the lens of the formulation, we find that the crux of TBIE is that existing techniques hardly achieve a good trade-off between editability and fidelity, mainly due to the overfitting of the single-image fine-tuning. To this end, we propose a Doubly Abductive Counterfactual inference framework (DAC). We first parameterize an exogenous variable as a UNet LoRA, whose abduction can encode all the image details. Second, we abduct another exogenous variable parameterized by a text encoder LoRA, which recovers the lost editability caused by the overfitted first abduction. Thanks to the second abduction, which exclusively encodes the visual transition from post-edit to pre-edit, its inversion -- subtracting the LoRA -- effectively reverts pre-edit back to post-edit, thereby accomplishing the edit. Through extensive experiments, our DAC achieves a good trade-off between editability and fidelity. Thus, we can support a wide spectrum of user editing intents, including addition, removal, manipulation, replacement, style transfer, and facial change, which are extensively validated in both qualitative and quantitative evaluations. Codes are in https://github.com/xuesong39/DAC.
Instruction-Guided Scene Text Recognition
Jan 31, 2024Multi-modal models have shown appealing performance in visual tasks recently, as instruction-guided training has evoked the ability to understand fine-grained visual content. However, current methods cannot be trivially applied to scene text recognition (STR) due to the gap between natural and text images. In this paper, we introduce a novel paradigm that formulates STR as an instruction learning problem, and propose instruction-guided scene text recognition (IGTR) to achieve effective cross-modal learning. IGTR first generates rich and diverse instruction triplets of <condition,question,answer>, serving as guidance for nuanced text image understanding. Then, we devise an architecture with dedicated cross-modal feature fusion module, and multi-task answer head to effectively fuse the required instruction and image features for answering questions. Built upon these designs, IGTR facilitates accurate text recognition by comprehending character attributes. Experiments on English and Chinese benchmarks show that IGTR outperforms existing models by significant margins. Furthermore, by adjusting the instructions, IGTR enables various recognition schemes. These include zero-shot prediction, where the model is trained based on instructions not explicitly targeting character recognition, and the recognition of rarely appearing and morphologically similar characters, which were previous challenges for existing models.