 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYang Luo
How Does the Textual Information Affect the Retrieval of Multimodal In-Context Learning?
Apr 19, 2024
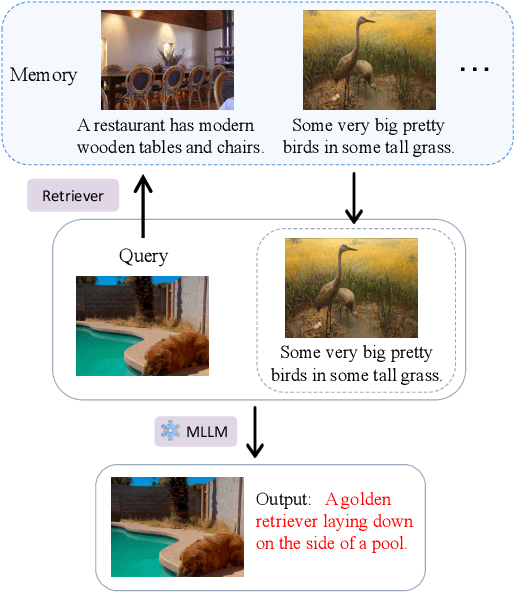

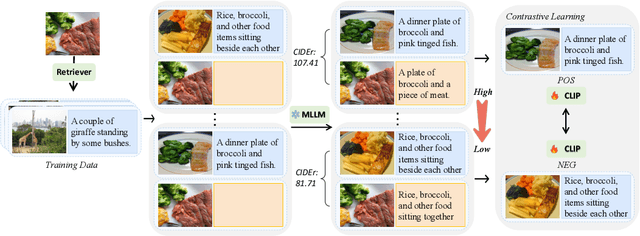

The increase in parameter size of multimodal large language models (MLLMs) introduces significant capabilities, particularly in-context learning, where MLLMs enhance task performance without updating pre-trained parameters. This effectiveness, however, hinges on the appropriate selection of in-context examples, a process that is currently biased towards visual data, overlooking textual information. Furthermore, the area of supervised retrievers for MLLMs, crucial for optimal in-context example selection, continues to be uninvestigated. Our study offers an in-depth evaluation of the impact of textual information on the unsupervised selection of in-context examples in multimodal contexts, uncovering a notable sensitivity of retriever performance to the employed modalities. Responding to this, we introduce a novel supervised MLLM-retriever MSIER that employs a neural network to select examples that enhance multimodal in-context learning efficiency. This approach is validated through extensive testing across three distinct tasks, demonstrating the method's effectiveness. Additionally, we investigate the influence of modalities on our supervised retrieval method's training and pinpoint factors contributing to our model's success. This exploration paves the way for future advancements, highlighting the potential for refined in-context learning in MLLMs through the strategic use of multimodal data.
From Two-Stream to One-Stream: Efficient RGB-T Tracking via Mutual Prompt Learning and Knowledge Distillation
Apr 07, 2024Due to the complementary nature of visible light and thermal infrared modalities, object tracking based on the fusion of visible light images and thermal images (referred to as RGB-T tracking) has received increasing attention from researchers in recent years. How to achieve more comprehensive fusion of information from the two modalities at a lower cost has been an issue that researchers have been exploring. Inspired by visual prompt learning, we designed a novel two-stream RGB-T tracking architecture based on cross-modal mutual prompt learning, and used this model as a teacher to guide a one-stream student model for rapid learning through knowledge distillation techniques. Extensive experiments have shown that, compared to similar RGB-T trackers, our designed teacher model achieved the highest precision rate, while the student model, with comparable precision rate to the teacher model, realized an inference speed more than three times faster than the teacher model.(Codes will be available if accepted.)
Learning to Rank Patches for Unbiased Image Redundancy Reduction
Mar 31, 2024Images suffer from heavy spatial redundancy because pixels in neighboring regions are spatially correlated. Existing approaches strive to overcome this limitation by reducing less meaningful image regions. However, current leading methods rely on supervisory signals. They may compel models to preserve content that aligns with labeled categories and discard content belonging to unlabeled categories. This categorical inductive bias makes these methods less effective in real-world scenarios. To address this issue, we propose a self-supervised framework for image redundancy reduction called Learning to Rank Patches (LTRP). We observe that image reconstruction of masked image modeling models is sensitive to the removal of visible patches when the masking ratio is high (e.g., 90\%). Building upon it, we implement LTRP via two steps: inferring the semantic density score of each patch by quantifying variation between reconstructions with and without this patch, and learning to rank the patches with the pseudo score. The entire process is self-supervised, thus getting out of the dilemma of categorical inductive bias. We design extensive experiments on different datasets and tasks. The results demonstrate that LTRP outperforms both supervised and other self-supervised methods due to the fair assessment of image content.
MCformer: Multivariate Time Series Forecasting with Mixed-Channels Transformer
Mar 14, 2024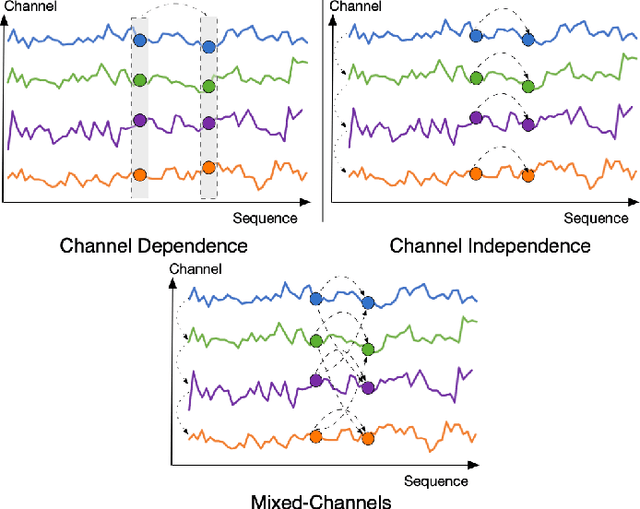

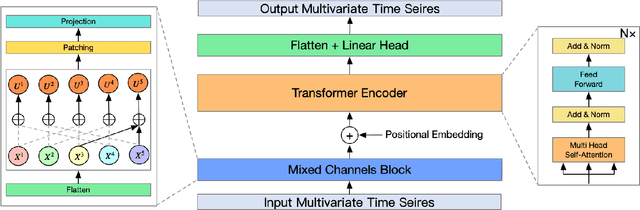

The massive generation of time-series data by largescale Internet of Things (IoT) devices necessitates the exploration of more effective models for multivariate time-series forecasting. In previous models, there was a predominant use of the Channel Dependence (CD) strategy (where each channel represents a univariate sequence). Current state-of-the-art (SOTA) models primarily rely on the Channel Independence (CI) strategy. The CI strategy treats all channels as a single channel, expanding the dataset to improve generalization performance and avoiding inter-channel correlation that disrupts long-term features. However, the CI strategy faces the challenge of interchannel correlation forgetting. To address this issue, we propose an innovative Mixed Channels strategy, combining the data expansion advantages of the CI strategy with the ability to counteract inter-channel correlation forgetting. Based on this strategy, we introduce MCformer, a multivariate time-series forecasting model with mixed channel features. The model blends a specific number of channels, leveraging an attention mechanism to effectively capture inter-channel correlation information when modeling long-term features. Experimental results demonstrate that the Mixed Channels strategy outperforms pure CI strategy in multivariate time-series forecasting tasks.
Intelligent Reflecting Surfaces vs. Full-Duplex Relays: A Comparison in the Air
Mar 14, 2024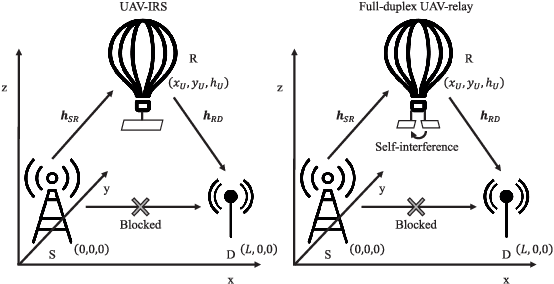
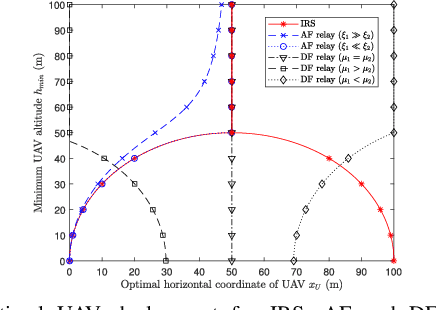
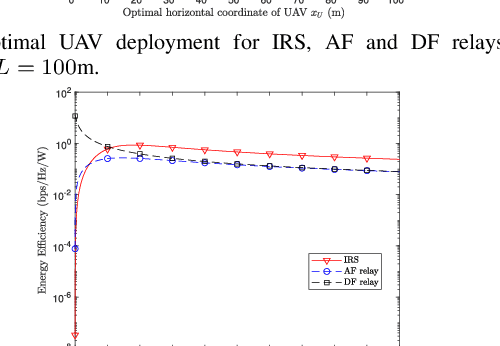
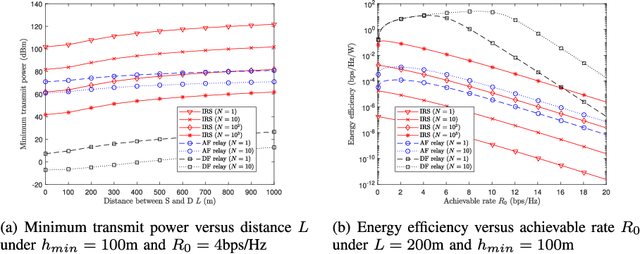
This letter aims to provide a fundamental analytical comparison for the two major types of relaying methods: intelligent reflecting surfaces and full-duplex relays, particularly focusing on unmanned aerial vehicle communication scenarios. Both amplify-and-forward and decode-and-forward relaying schemes are included in the comparison. In addition, optimal 3D UAV deployment and minimum transmit power under the quality of service constraint are derived. Our numerical results show that IRSs of medium size exhibit comparable performance to AF relays, meanwhile outperforming DF relays under extremely large surface size and high data rates.
One-stage Modality Distillation for Incomplete Multimodal Learning
Sep 15, 2023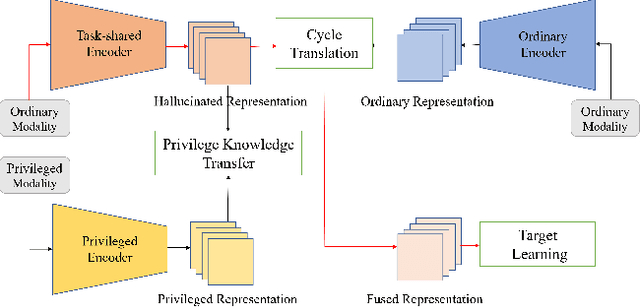
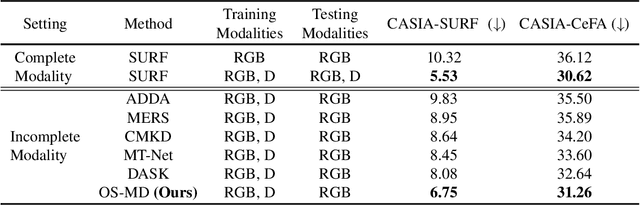
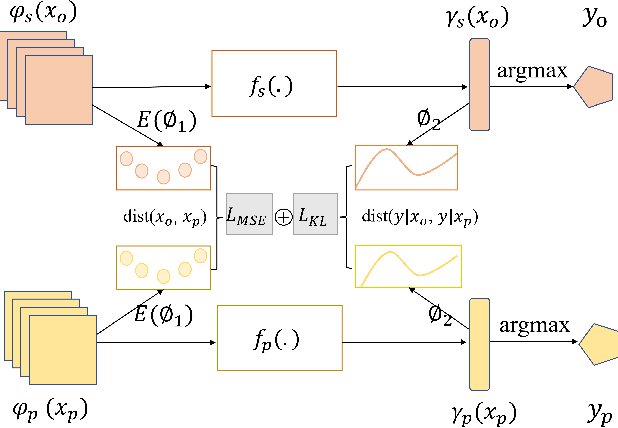
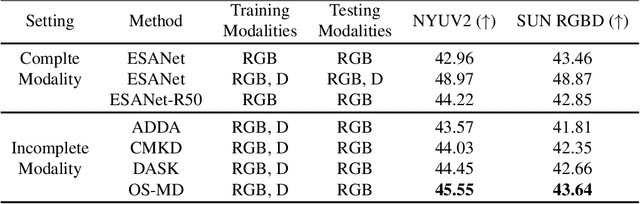
Learning based on multimodal data has attracted increasing interest recently. While a variety of sensory modalities can be collected for training, not all of them are always available in development scenarios, which raises the challenge to infer with incomplete modality. To address this issue, this paper presents a one-stage modality distillation framework that unifies the privileged knowledge transfer and modality information fusion into a single optimization procedure via multi-task learning. Compared with the conventional modality distillation that performs them independently, this helps to capture the valuable representation that can assist the final model inference directly. Specifically, we propose the joint adaptation network for the modality transfer task to preserve the privileged information. This addresses the representation heterogeneity caused by input discrepancy via the joint distribution adaptation. Then, we introduce the cross translation network for the modality fusion task to aggregate the restored and available modality features. It leverages the parameters-sharing strategy to capture the cross-modal cues explicitly. Extensive experiments on RGB-D classification and segmentation tasks demonstrate the proposed multimodal inheritance framework can overcome the problem of incomplete modality input in various scenes and achieve state-of-the-art performance.
RGB-T Tracking via Multi-Modal Mutual Prompt Learning
Aug 31, 2023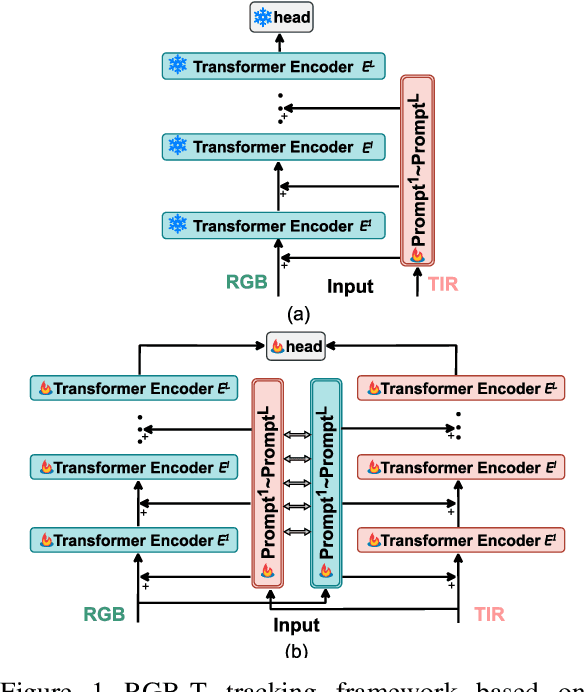
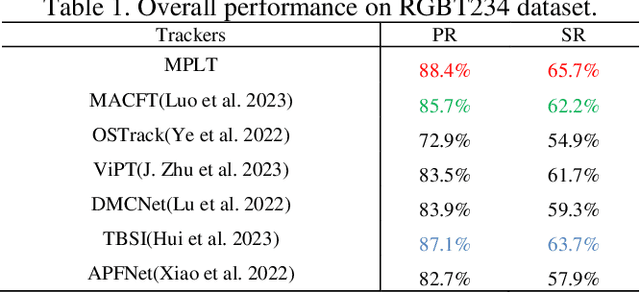
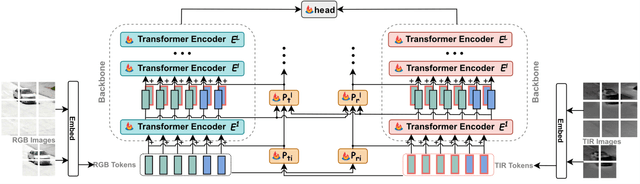
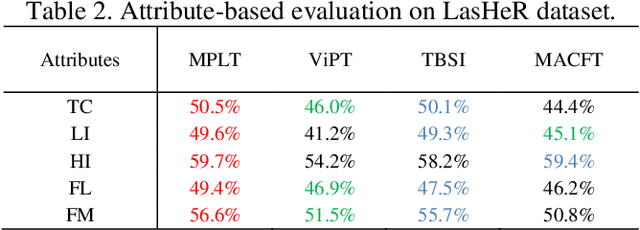
Object tracking based on the fusion of visible and thermal im-ages, known as RGB-T tracking, has gained increasing atten-tion from researchers in recent years. How to achieve a more comprehensive fusion of information from the two modalities with fewer computational costs has been a problem that re-searchers have been exploring. Recently, with the rise of prompt learning in computer vision, we can better transfer knowledge from visual large models to downstream tasks. Considering the strong complementarity between visible and thermal modalities, we propose a tracking architecture based on mutual prompt learning between the two modalities. We also design a lightweight prompter that incorporates attention mechanisms in two dimensions to transfer information from one modality to the other with lower computational costs, embedding it into each layer of the backbone. Extensive ex-periments have demonstrated that our proposed tracking ar-chitecture is effective and efficient, achieving state-of-the-art performance while maintaining high running speeds.
CAME: Confidence-guided Adaptive Memory Efficient Optimization
Jul 05, 2023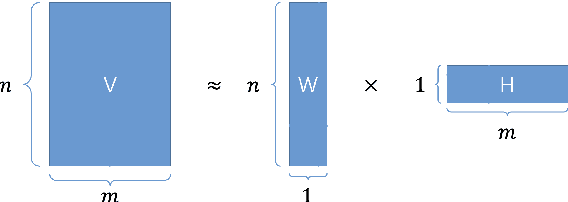
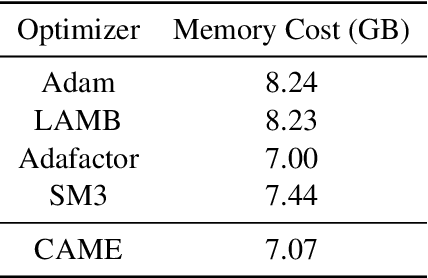
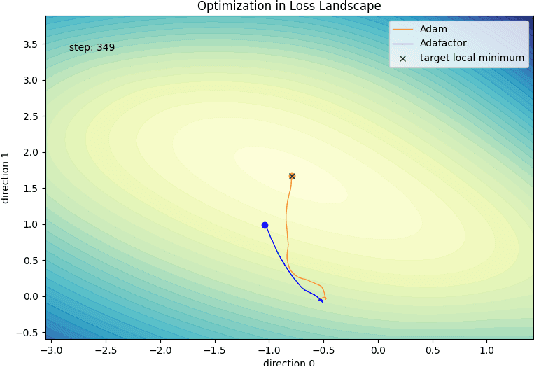

Adaptive gradient methods, such as Adam and LAMB, have demonstrated excellent performance in the training of large language models. Nevertheless, the need for adaptivity requires maintaining second-moment estimates of the per-parameter gradients, which entails a high cost of extra memory overheads. To solve this problem, several memory-efficient optimizers (e.g., Adafactor) have been proposed to obtain a drastic reduction in auxiliary memory usage, but with a performance penalty. In this paper, we first study a confidence-guided strategy to reduce the instability of existing memory efficient optimizers. Based on this strategy, we propose CAME to simultaneously achieve two goals: fast convergence as in traditional adaptive methods, and low memory usage as in memory-efficient methods. Extensive experiments demonstrate the training stability and superior performance of CAME across various NLP tasks such as BERT and GPT-2 training. Notably, for BERT pre-training on the large batch size of 32,768, our proposed optimizer attains faster convergence and higher accuracy compared with the Adam optimizer. The implementation of CAME is publicly available.
Response Length Perception and Sequence Scheduling: An LLM-Empowered LLM Inference Pipeline
May 22, 2023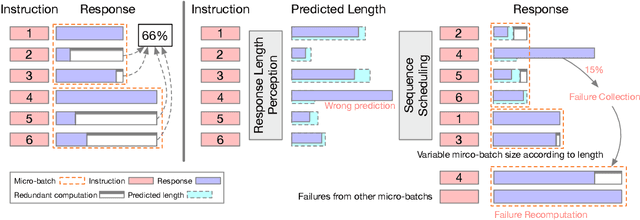

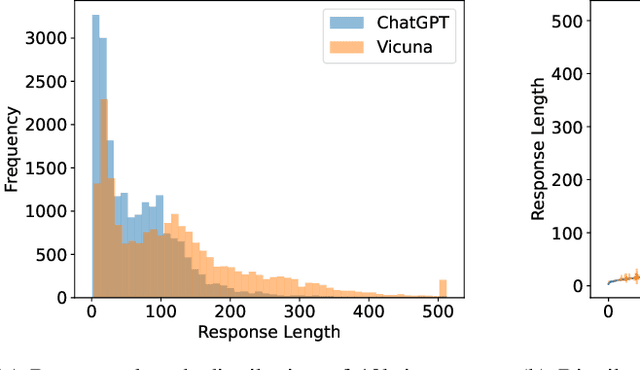
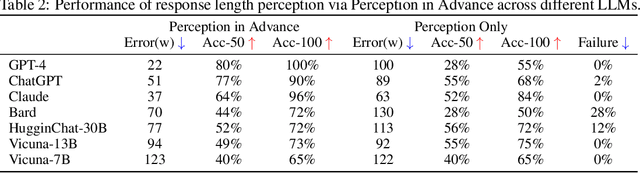
Large language models (LLMs) have revolutionized the field of AI, demonstrating unprecedented capacity across various tasks. However, the inference process for LLMs comes with significant computational costs. In this paper, we propose an efficient LLM inference pipeline that harnesses the power of LLMs. Our approach begins by tapping into the potential of LLMs to accurately perceive and predict the response length with minimal overhead. By leveraging this information, we introduce an efficient sequence scheduling technique that groups queries with similar response lengths into micro-batches. We evaluate our approach on real-world instruction datasets using the LLaMA-based model, and our results demonstrate an impressive 86% improvement in inference throughput without compromising effectiveness. Notably, our method is orthogonal to other inference acceleration techniques, making it a valuable addition to many existing toolkits (e.g., FlashAttention, Quantization) for LLM inference.
RGB-T Tracking Based on Mixed Attention
Apr 18, 2023
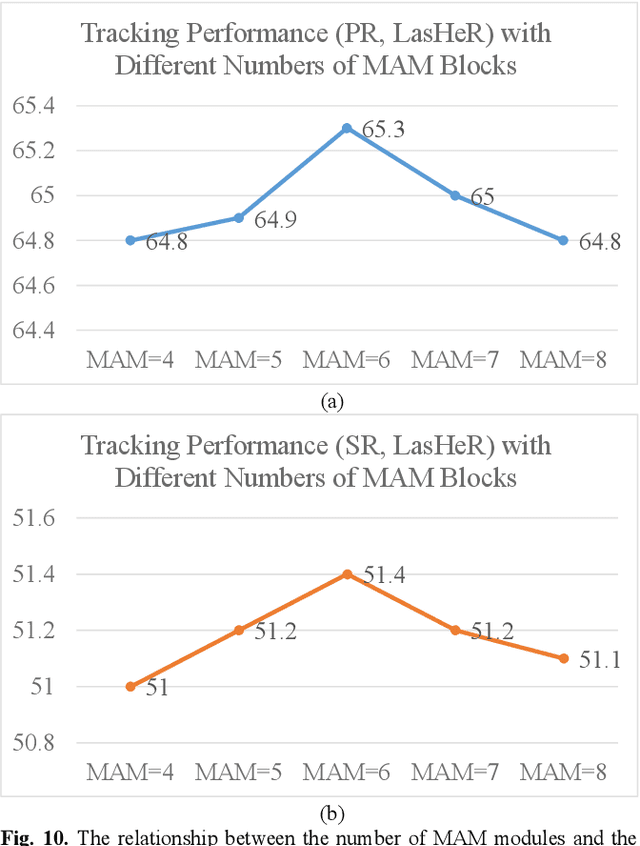
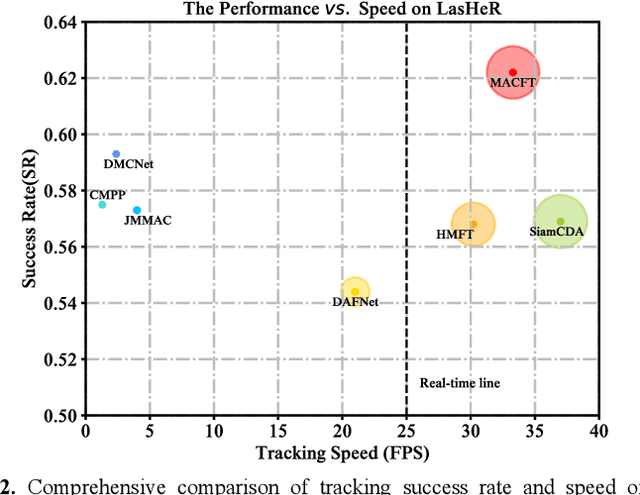
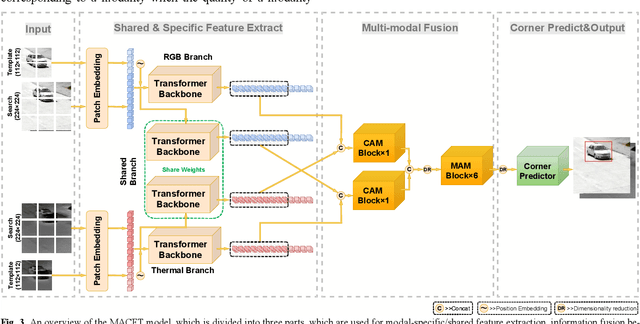
RGB-T tracking involves the use of images from both visible and thermal modalities. The primary objective is to adaptively leverage the relatively dominant modality in varying conditions to achieve more robust tracking compared to single-modality tracking. An RGB-T tracker based on mixed attention mechanism to achieve complementary fusion of modalities (referred to as MACFT) is proposed in this paper. In the feature extraction stage, we utilize different transformer backbone branches to extract specific and shared information from different modalities. By performing mixed attention operations in the backbone to enable information interaction and self-enhancement between the template and search images, it constructs a robust feature representation that better understands the high-level semantic features of the target. Then, in the feature fusion stage, a modality-adaptive fusion is achieved through a mixed attention-based modality fusion network, which suppresses the low-quality modality noise while enhancing the information of the dominant modality. Evaluation on multiple RGB-T public datasets demonstrates that our proposed tracker outperforms other RGB-T trackers on general evaluation metrics while also being able to adapt to longterm tracking scenarios.