 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXieping Gao
Learning to Rank Patches for Unbiased Image Redundancy Reduction
Mar 31, 2024
Images suffer from heavy spatial redundancy because pixels in neighboring regions are spatially correlated. Existing approaches strive to overcome this limitation by reducing less meaningful image regions. However, current leading methods rely on supervisory signals. They may compel models to preserve content that aligns with labeled categories and discard content belonging to unlabeled categories. This categorical inductive bias makes these methods less effective in real-world scenarios. To address this issue, we propose a self-supervised framework for image redundancy reduction called Learning to Rank Patches (LTRP). We observe that image reconstruction of masked image modeling models is sensitive to the removal of visible patches when the masking ratio is high (e.g., 90\%). Building upon it, we implement LTRP via two steps: inferring the semantic density score of each patch by quantifying variation between reconstructions with and without this patch, and learning to rank the patches with the pseudo score. The entire process is self-supervised, thus getting out of the dilemma of categorical inductive bias. We design extensive experiments on different datasets and tasks. The results demonstrate that LTRP outperforms both supervised and other self-supervised methods due to the fair assessment of image content.
Self-distillation Augmented Masked Autoencoders for Histopathological Image Classification
Mar 31, 2022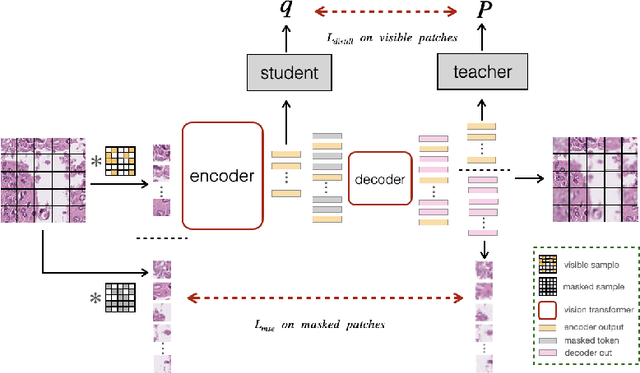
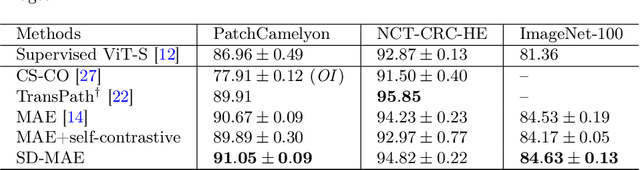
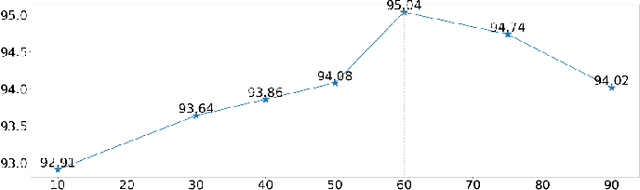

Self-supervised learning (SSL) has drawn increasing attention in pathological image analysis in recent years. However, the prevalent contrastive SSL is suboptimal in feature representation under this scenario due to the homogeneous visual appearance. Alternatively, masked autoencoders (MAE) build SSL from a generative paradigm. They are more friendly to pathological image modeling. In this paper, we firstly introduce MAE to pathological image analysis. A novel SD-MAE model is proposed to enable a self-distillation augmented SSL on top of the raw MAE. Besides the reconstruction loss on masked image patches, SD-MAE further imposes the self-distillation loss on visible patches. It guides the encoder to perceive high-level semantics that benefit downstream tasks. We apply SD-MAE to the image classification task on two pathological and one natural image datasets. Experiments demonstrate that SD-MAE performs highly competitive when compared with leading contrastive SSL methods. The results, which are pre-trained using a moderate size of pathological images, are also comparable to the method pre-trained with two orders of magnitude more images. Our code will be released soon.
MSDNN: Multi-Scale Deep Neural Network for Salient Object Detection
Jan 12, 2018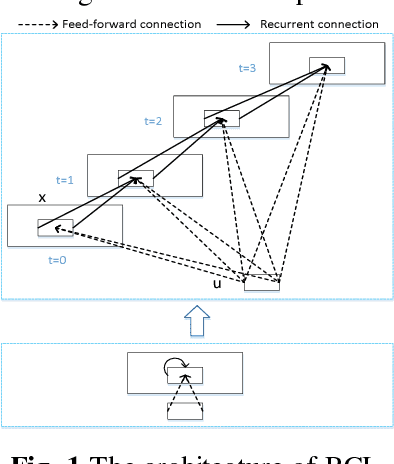
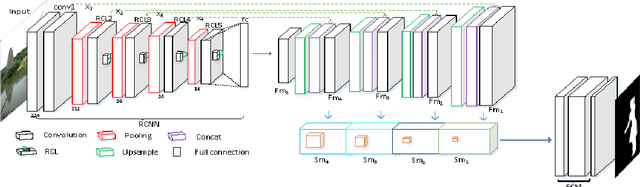
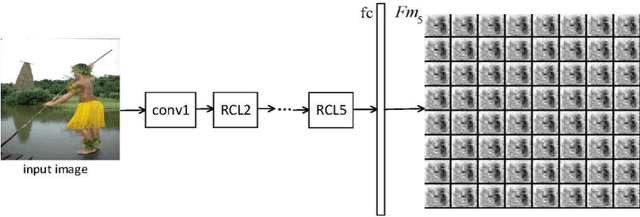

Salient object detection is a fundamental problem and has been received a great deal of attentions in computer vision. Recently deep learning model became a powerful tool for image feature extraction. In this paper, we propose a multi-scale deep neural network (MSDNN) for salient object detection. The proposed model first extracts global high-level features and context information over the whole source image with recurrent convolutional neural network (RCNN). Then several stacked deconvolutional layers are adopted to get the multi-scale feature representation and obtain a series of saliency maps. Finally, we investigate a fusion convolution module (FCM) to build a final pixel level saliency map. The proposed model is extensively evaluated on four salient object detection benchmark datasets. Results show that our deep model significantly outperforms other 12 state-of-the-art approaches.