 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKai Hu
Detect-Order-Construct: A Tree Construction based Approach for Hierarchical Document Structure Analysis
Jan 22, 2024
Document structure analysis (aka document layout analysis) is crucial for understanding the physical layout and logical structure of documents, with applications in information retrieval, document summarization, knowledge extraction, etc. In this paper, we concentrate on Hierarchical Document Structure Analysis (HDSA) to explore hierarchical relationships within structured documents created using authoring software employing hierarchical schemas, such as LaTeX, Microsoft Word, and HTML. To comprehensively analyze hierarchical document structures, we propose a tree construction based approach that addresses multiple subtasks concurrently, including page object detection (Detect), reading order prediction of identified objects (Order), and the construction of intended hierarchical structure (Construct). We present an effective end-to-end solution based on this framework to demonstrate its performance. To assess our approach, we develop a comprehensive benchmark called Comp-HRDoc, which evaluates the above subtasks simultaneously. Our end-to-end system achieves state-of-the-art performance on two large-scale document layout analysis datasets (PubLayNet and DocLayNet), a high-quality hierarchical document structure reconstruction dataset (HRDoc), and our Comp-HRDoc benchmark. The Comp-HRDoc benchmark will be released to facilitate further research in this field.
UniVIE: A Unified Label Space Approach to Visual Information Extraction from Form-like Documents
Jan 17, 2024Existing methods for Visual Information Extraction (VIE) from form-like documents typically fragment the process into separate subtasks, such as key information extraction, key-value pair extraction, and choice group extraction. However, these approaches often overlook the hierarchical structure of form documents, including hierarchical key-value pairs and hierarchical choice groups. To address these limitations, we present a new perspective, reframing VIE as a relation prediction problem and unifying labels of different tasks into a single label space. This unified approach allows for the definition of various relation types and effectively tackles hierarchical relationships in form-like documents. In line with this perspective, we present UniVIE, a unified model that addresses the VIE problem comprehensively. UniVIE functions using a coarse-to-fine strategy. It initially generates tree proposals through a tree proposal network, which are subsequently refined into hierarchical trees by a relation decoder module. To enhance the relation prediction capabilities of UniVIE, we incorporate two novel tree constraints into the relation decoder: a tree attention mask and a tree level embedding. Extensive experimental evaluations on both our in-house dataset HierForms and a publicly available dataset SIBR, substantiate that our method achieves state-of-the-art results, underscoring the effectiveness and potential of our unified approach in advancing the field of VIE.
Dynamic Relation Transformer for Contextual Text Block Detection
Jan 17, 2024Contextual Text Block Detection (CTBD) is the task of identifying coherent text blocks within the complexity of natural scenes. Previous methodologies have treated CTBD as either a visual relation extraction challenge within computer vision or as a sequence modeling problem from the perspective of natural language processing. We introduce a new framework that frames CTBD as a graph generation problem. This methodology consists of two essential procedures: identifying individual text units as graph nodes and discerning the sequential reading order relationships among these units as graph edges. Leveraging the cutting-edge capabilities of DQ-DETR for node detection, our framework innovates further by integrating a novel mechanism, a Dynamic Relation Transformer (DRFormer), dedicated to edge generation. DRFormer incorporates a dual interactive transformer decoder that deftly manages a dynamic graph structure refinement process. Through this iterative process, the model systematically enhances the graph's fidelity, ultimately resulting in improved precision in detecting contextual text blocks. Comprehensive experimental evaluations conducted on both SCUT-CTW-Context and ReCTS-Context datasets substantiate that our method achieves state-of-the-art results, underscoring the effectiveness and potential of our graph generation framework in advancing the field of CTBD.
Is Certifying $\ell_p$ Robustness Still Worthwhile?
Oct 13, 2023Over the years, researchers have developed myriad attacks that exploit the ubiquity of adversarial examples, as well as defenses that aim to guard against the security vulnerabilities posed by such attacks. Of particular interest to this paper are defenses that provide provable guarantees against the class of $\ell_p$-bounded attacks. Certified defenses have made significant progress, taking robustness certification from toy models and datasets to large-scale problems like ImageNet classification. While this is undoubtedly an interesting academic problem, as the field has matured, its impact in practice remains unclear, thus we find it useful to revisit the motivation for continuing this line of research. There are three layers to this inquiry, which we address in this paper: (1) why do we care about robustness research? (2) why do we care about the $\ell_p$-bounded threat model? And (3) why do we care about certification as opposed to empirical defenses? In brief, we take the position that local robustness certification indeed confers practical value to the field of machine learning. We focus especially on the latter two questions from above. With respect to the first of the two, we argue that the $\ell_p$-bounded threat model acts as a minimal requirement for safe application of models in security-critical domains, while at the same time, evidence has mounted suggesting that local robustness may lead to downstream external benefits not immediately related to robustness. As for the second, we argue that (i) certification provides a resolution to the cat-and-mouse game of adversarial attacks; and furthermore, that (ii) perhaps contrary to popular belief, there may not exist a fundamental trade-off between accuracy, robustness, and certifiability, while moreover, certified training techniques constitute a particularly promising way for learning robust models.
LauraGPT: Listen, Attend, Understand, and Regenerate Audio with GPT
Oct 11, 2023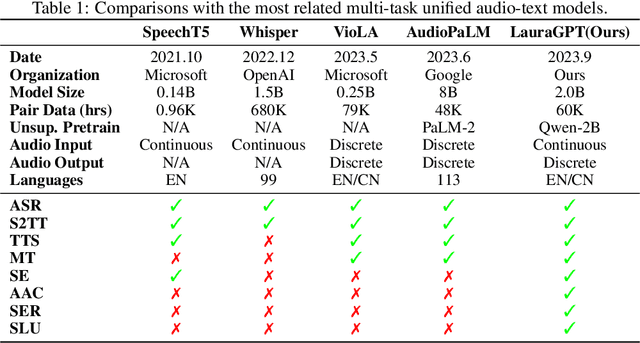
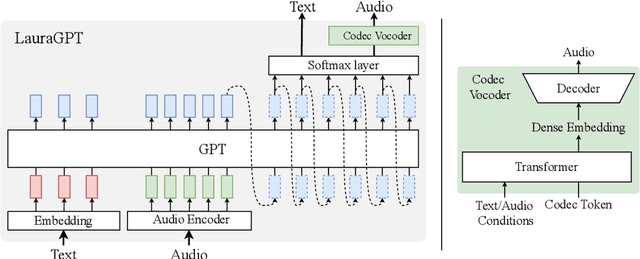
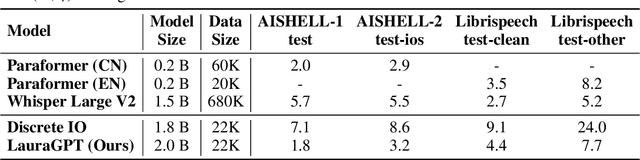

Generative Pre-trained Transformer (GPT) models have achieved remarkable performance on various natural language processing tasks. However, there has been limited research on applying similar frameworks to audio tasks. Previously proposed large language models for audio tasks either lack sufficient quantitative evaluations, or are limited to tasks for recognizing and understanding audio content, or significantly underperform existing state-of-the-art (SOTA) models. In this paper, we propose LauraGPT, a unified GPT model for audio recognition, understanding, and generation. LauraGPT is a versatile language model that can process both audio and text inputs and generate outputs in either modalities. It can perform a wide range of tasks related to content, semantics, paralinguistics, and audio-signal analysis. Some of its noteworthy tasks include automatic speech recognition, speech-to-text translation, text-to-speech synthesis, machine translation, speech enhancement, automated audio captioning, speech emotion recognition, and spoken language understanding. To achieve this goal, we use a combination of continuous and discrete features for audio. We encode input audio into continuous representations using an audio encoder and decode output audio from discrete codec codes. We then fine-tune a large decoder-only Transformer-based language model on multiple audio-to-text, text-to-audio, audio-to-audio, and text-to-text tasks using a supervised multitask learning approach. Extensive experiments show that LauraGPT achieves competitive or superior performance compared to existing SOTA models on various audio processing benchmarks.
A Recipe for Improved Certifiable Robustness: Capacity and Data
Oct 04, 2023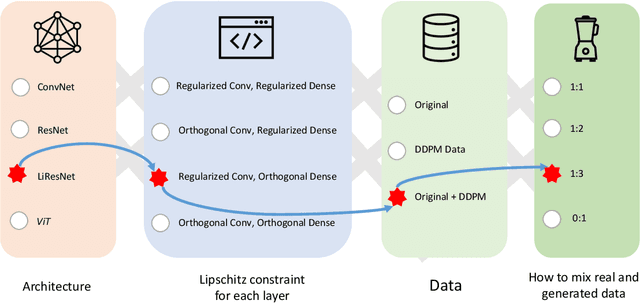
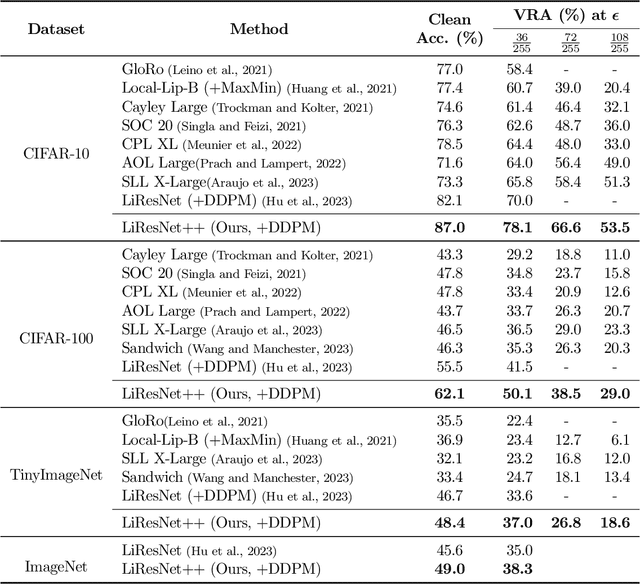

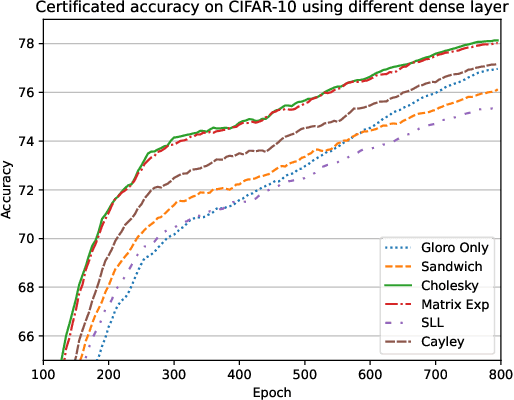
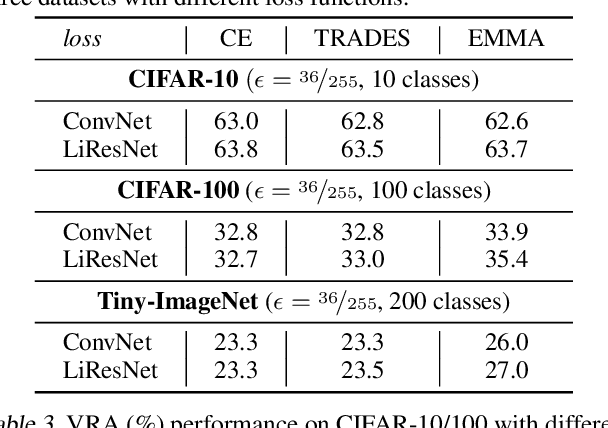
A key challenge, supported both theoretically and empirically, is that robustness demands greater network capacity and more data than standard training. However, effectively adding capacity under stringent Lipschitz constraints has proven more difficult than it may seem, evident by the fact that state-of-the-art approach tend more towards \emph{underfitting} than overfitting. Moreover, we posit that a lack of careful exploration of the design space for Lipshitz-based approaches has left potential performance gains on the table. In this work, we provide a more comprehensive evaluation to better uncover the potential of Lipschitz-based certification methods. Using a combination of novel techniques, design optimizations, and synthesis of prior work, we are able to significantly improve the state-of-the-art \emph{verified robust accuracy} (VRA) for deterministic certification on a variety of benchmark datasets, and over a range of perturbation sizes. Of particular note, we discover that the addition of large "Cholesky-orthogonalized residual dense" layers to the end of existing state-of-the-art Lipschitz-controlled ResNet architectures is especially effective for increasing network capacity and performance. Combined with filtered generative data augmentation, our final results further the state of the art deterministic VRA by up to 8.5 percentage points. Code is available at \url{https://github.com/hukkai/liresnet}.
FunCodec: A Fundamental, Reproducible and Integrable Open-source Toolkit for Neural Speech Codec
Sep 14, 2023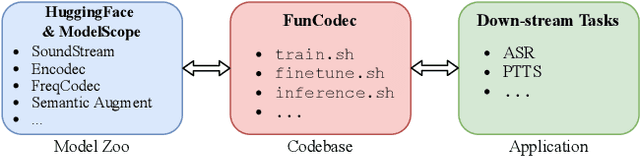
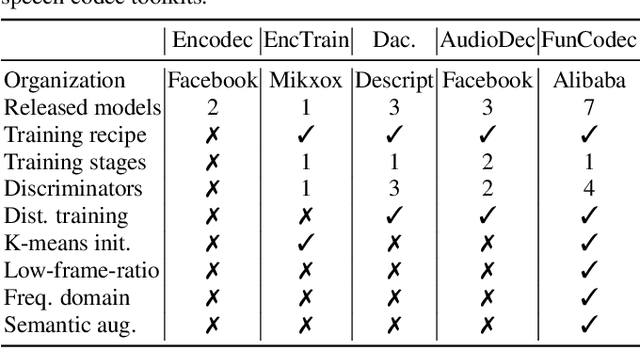
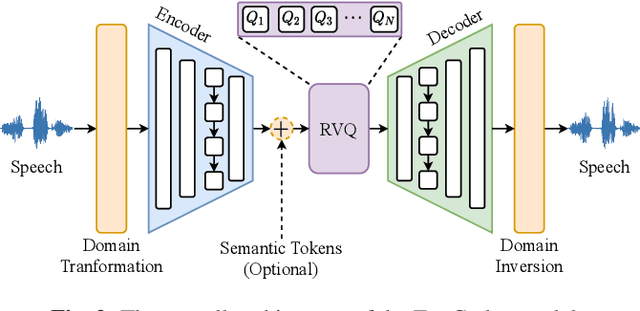
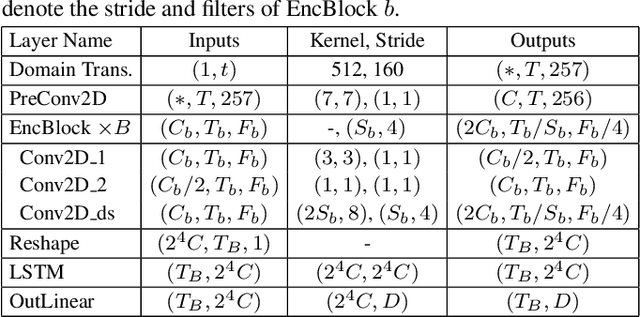
This paper presents FunCodec, a fundamental neural speech codec toolkit, which is an extension of the open-source speech processing toolkit FunASR. FunCodec provides reproducible training recipes and inference scripts for the latest neural speech codec models, such as SoundStream and Encodec. Thanks to the unified design with FunASR, FunCodec can be easily integrated into downstream tasks, such as speech recognition. Along with FunCodec, pre-trained models are also provided, which can be used for academic or generalized purposes. Based on the toolkit, we further propose the frequency-domain codec models, FreqCodec, which can achieve comparable speech quality with much lower computation and parameter complexity. Experimental results show that, under the same compression ratio, FunCodec can achieve better reconstruction quality compared with other toolkits and released models. We also demonstrate that the pre-trained models are suitable for downstream tasks, including automatic speech recognition and personalized text-to-speech synthesis. This toolkit is publicly available at https://github.com/alibaba-damo-academy/FunCodec.
A Question-Answering Approach to Key Value Pair Extraction from Form-like Document Images
Apr 17, 2023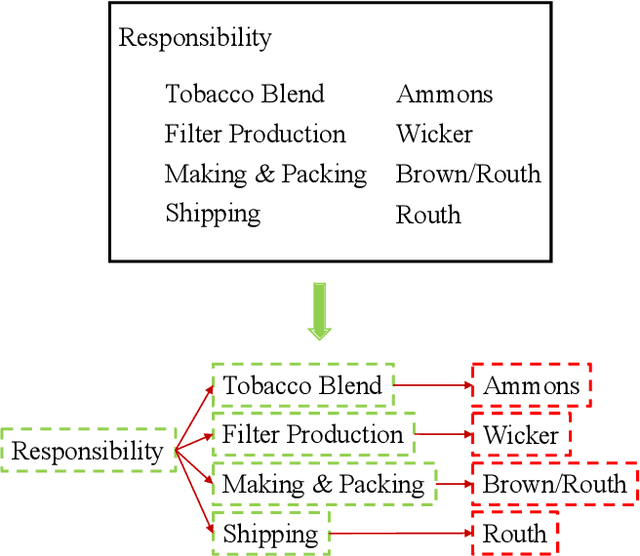
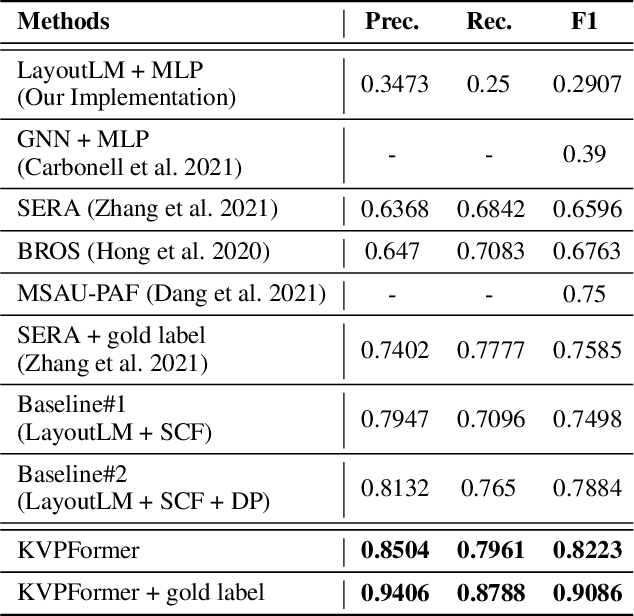
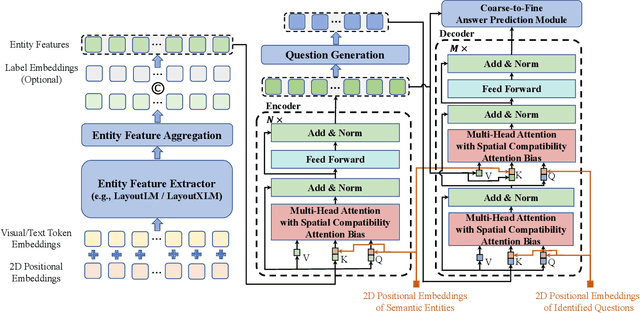
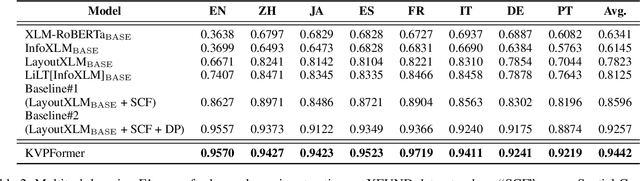
In this paper, we present a new question-answering (QA) based key-value pair extraction approach, called KVPFormer, to robustly extracting key-value relationships between entities from form-like document images. Specifically, KVPFormer first identifies key entities from all entities in an image with a Transformer encoder, then takes these key entities as \textbf{questions} and feeds them into a Transformer decoder to predict their corresponding \textbf{answers} (i.e., value entities) in parallel. To achieve higher answer prediction accuracy, we propose a coarse-to-fine answer prediction approach further, which first extracts multiple answer candidates for each identified question in the coarse stage and then selects the most likely one among these candidates in the fine stage. In this way, the learning difficulty of answer prediction can be effectively reduced so that the prediction accuracy can be improved. Moreover, we introduce a spatial compatibility attention bias into the self-attention/cross-attention mechanism for \Ours{} to better model the spatial interactions between entities. With these new techniques, our proposed \Ours{} achieves state-of-the-art results on FUNSD and XFUND datasets, outperforming the previous best-performing method by 7.2\% and 13.2\% in F1 score, respectively.
Scaling in Depth: Unlocking Robustness Certification on ImageNet
Jan 29, 2023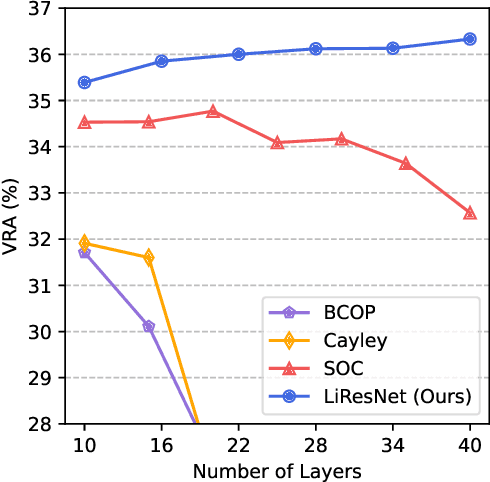
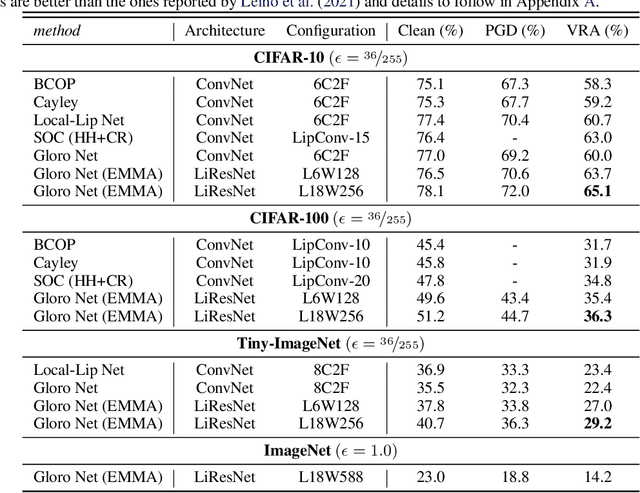
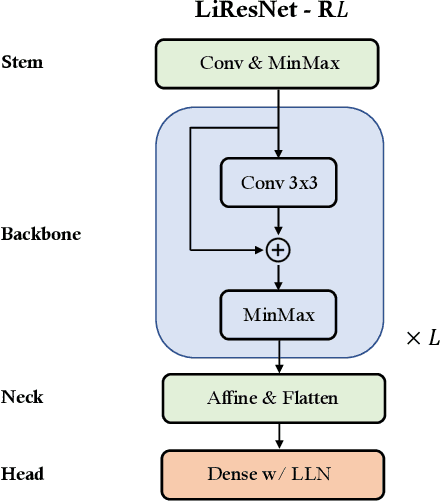
Notwithstanding the promise of Lipschitz-based approaches to \emph{deterministically} train and certify robust deep networks, the state-of-the-art results only make successful use of feed-forward Convolutional Networks (ConvNets) on low-dimensional data, e.g. CIFAR-10. Because ConvNets often suffer from vanishing gradients when going deep, large-scale datasets with many classes, e.g., ImageNet, have remained out of practical reach. This paper investigates ways to scale up certifiably robust training to Residual Networks (ResNets). First, we introduce the \emph{Linear ResNet} (LiResNet) architecture, which utilizes a new residual block designed to facilitate \emph{tighter} Lipschitz bounds compared to a conventional residual block. Second, we introduce Efficient Margin MAximization (EMMA), a loss function that stabilizes robust training by simultaneously penalizing worst-case adversarial examples from \emph{all} classes. Combining LiResNet and EMMA, we achieve new \emph{state-of-the-art} robust accuracy on CIFAR-10/100 and Tiny-ImageNet under $\ell_2$-norm-bounded perturbations. Moreover, for the first time, we are able to scale up deterministic robustness guarantees to ImageNet, bringing hope to the possibility of applying deterministic certification to real-world applications.
Enhanced Training of Query-Based Object Detection via Selective Query Recollection
Dec 15, 2022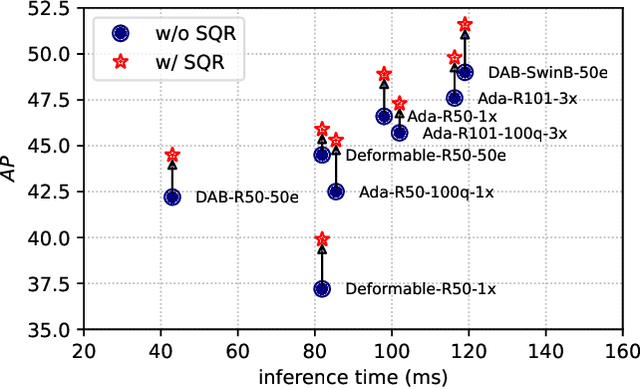


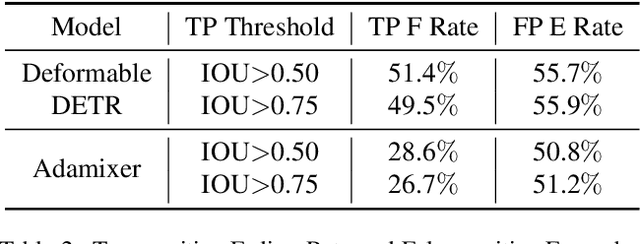
This paper investigates a phenomenon where query-based object detectors mispredict at the last decoding stage while predicting correctly at an intermediate stage. We review the training process and attribute the overlooked phenomenon to two limitations: lack of training emphasis and cascading errors from decoding sequence. We design and present Selective Query Recollection (SQR), a simple and effective training strategy for query-based object detectors. It cumulatively collects intermediate queries as decoding stages go deeper and selectively forwards the queries to the downstream stages aside from the sequential structure. Such-wise, SQR places training emphasis on later stages and allows later stages to work with intermediate queries from earlier stages directly. SQR can be easily plugged into various query-based object detectors and significantly enhances their performance while leaving the inference pipeline unchanged. As a result, we apply SQR on Adamixer, DAB-DETR, and Deformable-DETR across various settings (backbone, number of queries, schedule) and consistently brings 1.4-2.8 AP improvement.