 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDifan Zou
The Dog Walking Theory: Rethinking Convergence in Federated Learning
Apr 18, 2024
Federated learning (FL) is a collaborative learning paradigm that allows different clients to train one powerful global model without sharing their private data. Although FL has demonstrated promising results in various applications, it is known to suffer from convergence issues caused by the data distribution shift across different clients, especially on non-independent and identically distributed (non-IID) data. In this paper, we study the convergence of FL on non-IID data and propose a novel \emph{Dog Walking Theory} to formulate and identify the missing element in existing research. The Dog Walking Theory describes the process of a dog walker leash walking multiple dogs from one side of the park to the other. The goal of the dog walker is to arrive at the right destination while giving the dogs enough exercise (i.e., space exploration). In FL, the server is analogous to the dog walker while the clients are analogous to the dogs. This analogy allows us to identify one crucial yet missing element in existing FL algorithms: the leash that guides the exploration of the clients. To address this gap, we propose a novel FL algorithm \emph{FedWalk} that leverages an external easy-to-converge task at the server side as a \emph{leash task} to guide the local training of the clients. We theoretically analyze the convergence of FedWalk with respect to data heterogeneity (between server and clients) and task discrepancy (between the leash and the original tasks). Experiments on multiple benchmark datasets demonstrate the superiority of FedWalk over state-of-the-art FL methods under both IID and non-IID settings.
What Can Transformer Learn with Varying Depth? Case Studies on Sequence Learning Tasks
Apr 02, 2024We study the capabilities of the transformer architecture with varying depth. Specifically, we designed a novel set of sequence learning tasks to systematically evaluate and comprehend how the depth of transformer affects its ability to perform memorization, reasoning, generalization, and contextual generalization. We show a transformer with only one attention layer can excel in memorization but falls short in other tasks. Then, we show that exhibiting reasoning and generalization ability requires the transformer to have at least two attention layers, while context generalization ability may necessitate three attention layers. Additionally, we identify a class of simple operations that a single attention layer can execute, and show that the complex tasks can be approached as the combinations of these simple operations and thus can be resolved by stacking multiple attention layers. This sheds light on studying more practical and complex tasks beyond our design. Numerical experiments corroborate our theoretical findings.
Improving Implicit Regularization of SGD with Preconditioning for Least Square Problems
Mar 29, 2024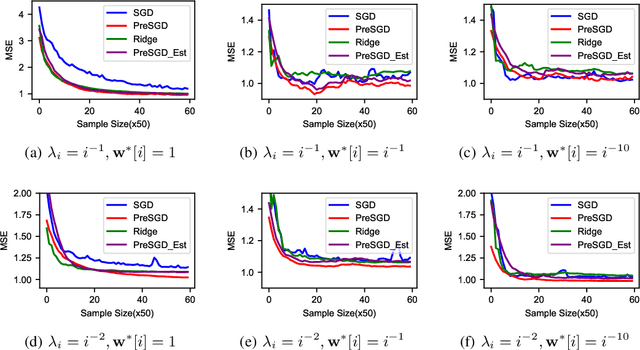
Stochastic gradient descent (SGD) exhibits strong algorithmic regularization effects in practice and plays an important role in the generalization of modern machine learning. However, prior research has revealed instances where the generalization performance of SGD is worse than ridge regression due to uneven optimization along different dimensions. Preconditioning offers a natural solution to this issue by rebalancing optimization across different directions. Yet, the extent to which preconditioning can enhance the generalization performance of SGD and whether it can bridge the existing gap with ridge regression remains uncertain. In this paper, we study the generalization performance of SGD with preconditioning for the least squared problem. We make a comprehensive comparison between preconditioned SGD and (standard \& preconditioned) ridge regression. Our study makes several key contributions toward understanding and improving SGD with preconditioning. First, we establish excess risk bounds (generalization performance) for preconditioned SGD and ridge regression under an arbitrary preconditions matrix. Second, leveraging the excessive risk characterization of preconditioned SGD and ridge regression, we show that (through construction) there exists a simple preconditioned matrix that can outperform (standard \& preconditioned) ridge regression. Finally, we show that our proposed preconditioning matrix is straightforward enough to allow robust estimation from finite samples while maintaining a theoretical advantage over ridge regression. Our empirical results align with our theoretical findings, collectively showcasing the enhanced regularization effect of preconditioned SGD.
On the Benefits of Over-parameterization for Out-of-Distribution Generalization
Mar 26, 2024In recent years, machine learning models have achieved success based on the independently and identically distributed assumption. However, this assumption can be easily violated in real-world applications, leading to the Out-of-Distribution (OOD) problem. Understanding how modern over-parameterized DNNs behave under non-trivial natural distributional shifts is essential, as current theoretical understanding is insufficient. Existing theoretical works often provide meaningless results for over-parameterized models in OOD scenarios or even contradict empirical findings. To this end, we are investigating the performance of the over-parameterized model in terms of OOD generalization under the general benign overfitting conditions. Our analysis focuses on a random feature model and examines non-trivial natural distributional shifts, where the benign overfitting estimators demonstrate a constant excess OOD loss, despite achieving zero excess in-distribution (ID) loss. We demonstrate that in this scenario, further increasing the model's parameterization can significantly reduce the OOD loss. Intuitively, the variance term of ID loss remains low due to orthogonality of long-tail features, meaning overfitting noise during training generally doesn't raise testing loss. However, in OOD cases, distributional shift increases the variance term. Thankfully, the inherent shift is unrelated to individual x, maintaining the orthogonality of long-tail features. Expanding the hidden dimension can additionally improve this orthogonality by mapping the features into higher-dimensional spaces, thereby reducing the variance term. We further show that model ensembles also improve OOD loss, akin to increasing model capacity. These insights explain the empirical phenomenon of enhanced OOD generalization through model ensembles, supported by consistent simulations with theoretical results.
An Improved Analysis of Langevin Algorithms with Prior Diffusion for Non-Log-Concave Sampling
Mar 10, 2024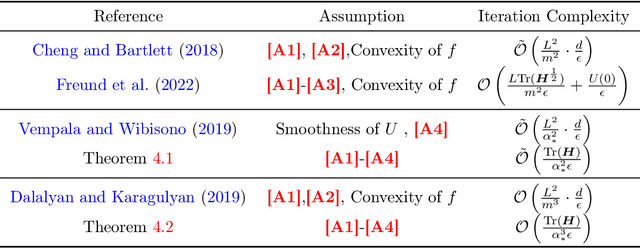
Understanding the dimension dependency of computational complexity in high-dimensional sampling problem is a fundamental problem, both from a practical and theoretical perspective. Compared with samplers with unbiased stationary distribution, e.g., Metropolis-adjusted Langevin algorithm (MALA), biased samplers, e.g., Underdamped Langevin Dynamics (ULD), perform better in low-accuracy cases just because a lower dimension dependency in their complexities. Along this line, Freund et al. (2022) suggest that the modified Langevin algorithm with prior diffusion is able to converge dimension independently for strongly log-concave target distributions. Nonetheless, it remains open whether such property establishes for more general cases. In this paper, we investigate the prior diffusion technique for the target distributions satisfying log-Sobolev inequality (LSI), which covers a much broader class of distributions compared to the strongly log-concave ones. In particular, we prove that the modified Langevin algorithm can also obtain the dimension-independent convergence of KL divergence with different step size schedules. The core of our proof technique is a novel construction of an interpolating SDE, which significantly helps to conduct a more accurate characterization of the discrete updates of the overdamped Langevin dynamics. Our theoretical analysis demonstrates the benefits of prior diffusion for a broader class of target distributions and provides new insights into developing faster sampling algorithms.
Towards Robust Graph Incremental Learning on Evolving Graphs
Feb 20, 2024Incremental learning is a machine learning approach that involves training a model on a sequence of tasks, rather than all tasks at once. This ability to learn incrementally from a stream of tasks is crucial for many real-world applications. However, incremental learning is a challenging problem on graph-structured data, as many graph-related problems involve prediction tasks for each individual node, known as Node-wise Graph Incremental Learning (NGIL). This introduces non-independent and non-identically distributed characteristics in the sample data generation process, making it difficult to maintain the performance of the model as new tasks are added. In this paper, we focus on the inductive NGIL problem, which accounts for the evolution of graph structure (structural shift) induced by emerging tasks. We provide a formal formulation and analysis of the problem, and propose a novel regularization-based technique called Structural-Shift-Risk-Mitigation (SSRM) to mitigate the impact of the structural shift on catastrophic forgetting of the inductive NGIL problem. We show that the structural shift can lead to a shift in the input distribution for the existing tasks, and further lead to an increased risk of catastrophic forgetting. Through comprehensive empirical studies with several benchmark datasets, we demonstrate that our proposed method, Structural-Shift-Risk-Mitigation (SSRM), is flexible and easy to adapt to improve the performance of state-of-the-art GNN incremental learning frameworks in the inductive setting.
PRES: Toward Scalable Memory-Based Dynamic Graph Neural Networks
Feb 06, 2024Memory-based Dynamic Graph Neural Networks (MDGNNs) are a family of dynamic graph neural networks that leverage a memory module to extract, distill, and memorize long-term temporal dependencies, leading to superior performance compared to memory-less counterparts. However, training MDGNNs faces the challenge of handling entangled temporal and structural dependencies, requiring sequential and chronological processing of data sequences to capture accurate temporal patterns. During the batch training, the temporal data points within the same batch will be processed in parallel, while their temporal dependencies are neglected. This issue is referred to as temporal discontinuity and restricts the effective temporal batch size, limiting data parallelism and reducing MDGNNs' flexibility in industrial applications. This paper studies the efficient training of MDGNNs at scale, focusing on the temporal discontinuity in training MDGNNs with large temporal batch sizes. We first conduct a theoretical study on the impact of temporal batch size on the convergence of MDGNN training. Based on the analysis, we propose PRES, an iterative prediction-correction scheme combined with a memory coherence learning objective to mitigate the effect of temporal discontinuity, enabling MDGNNs to be trained with significantly larger temporal batches without sacrificing generalization performance. Experimental results demonstrate that our approach enables up to a 4x larger temporal batch (3.4x speed-up) during MDGNN training.
Faster Sampling without Isoperimetry via Diffusion-based Monte Carlo
Jan 12, 2024To sample from a general target distribution $p_*\propto e^{-f_*}$ beyond the isoperimetric condition, Huang et al. (2023) proposed to perform sampling through reverse diffusion, giving rise to Diffusion-based Monte Carlo (DMC). Specifically, DMC follows the reverse SDE of a diffusion process that transforms the target distribution to the standard Gaussian, utilizing a non-parametric score estimation. However, the original DMC algorithm encountered high gradient complexity, resulting in an exponential dependency on the error tolerance $\epsilon$ of the obtained samples. In this paper, we demonstrate that the high complexity of DMC originates from its redundant design of score estimation, and proposed a more efficient algorithm, called RS-DMC, based on a novel recursive score estimation method. In particular, we first divide the entire diffusion process into multiple segments and then formulate the score estimation step (at any time step) as a series of interconnected mean estimation and sampling subproblems accordingly, which are correlated in a recursive manner. Importantly, we show that with a proper design of the segment decomposition, all sampling subproblems will only need to tackle a strongly log-concave distribution, which can be very efficient to solve using the Langevin-based samplers with a provably rapid convergence rate. As a result, we prove that the gradient complexity of RS-DMC only has a quasi-polynomial dependency on $\epsilon$, which significantly improves exponential gradient complexity in Huang et al. (2023). Furthermore, under commonly used dissipative conditions, our algorithm is provably much faster than the popular Langevin-based algorithms. Our algorithm design and theoretical framework illuminate a novel direction for addressing sampling problems, which could be of broader applicability in the community.
Benign Oscillation of Stochastic Gradient Descent with Large Learning Rates
Oct 26, 2023In this work, we theoretically investigate the generalization properties of neural networks (NN) trained by stochastic gradient descent (SGD) algorithm with large learning rates. Under such a training regime, our finding is that, the oscillation of the NN weights caused by the large learning rate SGD training turns out to be beneficial to the generalization of the NN, which potentially improves over the same NN trained by SGD with small learning rates that converges more smoothly. In view of this finding, we call such a phenomenon "benign oscillation". Our theory towards demystifying such a phenomenon builds upon the feature learning perspective of deep learning. Specifically, we consider a feature-noise data generation model that consists of (i) weak features which have a small $\ell_2$-norm and appear in each data point; (ii) strong features which have a larger $\ell_2$-norm but only appear in a certain fraction of all data points; and (iii) noise. We prove that NNs trained by oscillating SGD with a large learning rate can effectively learn the weak features in the presence of those strong features. In contrast, NNs trained by SGD with a small learning rate can only learn the strong features but makes little progress in learning the weak features. Consequently, when it comes to the new testing data which consist of only weak features, the NN trained by oscillating SGD with a large learning rate could still make correct predictions consistently, while the NN trained by small learning rate SGD fails. Our theory sheds light on how large learning rate training benefits the generalization of NNs. Experimental results demonstrate our finding on "benign oscillation".