 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHai Jin
Harnessing the Power of Large Language Model for Uncertainty Aware Graph Processing
Apr 12, 2024
Handling graph data is one of the most difficult tasks. Traditional techniques, such as those based on geometry and matrix factorization, rely on assumptions about the data relations that become inadequate when handling large and complex graph data. On the other hand, deep learning approaches demonstrate promising results in handling large graph data, but they often fall short of providing interpretable explanations. To equip the graph processing with both high accuracy and explainability, we introduce a novel approach that harnesses the power of a large language model (LLM), enhanced by an uncertainty-aware module to provide a confidence score on the generated answer. We experiment with our approach on two graph processing tasks: few-shot knowledge graph completion and graph classification. Our results demonstrate that through parameter efficient fine-tuning, the LLM surpasses state-of-the-art algorithms by a substantial margin across ten diverse benchmark datasets. Moreover, to address the challenge of explainability, we propose an uncertainty estimation based on perturbation, along with a calibration scheme to quantify the confidence scores of the generated answers. Our confidence measure achieves an AUC of 0.8 or higher on seven out of the ten datasets in predicting the correctness of the answer generated by LLM.
Iterative Refinement of Project-Level Code Context for Precise Code Generation with Compiler Feedback
Apr 02, 2024Large language models (LLMs) have shown remarkable progress in automated code generation. Yet, incorporating LLM-based code generation into real-life software projects poses challenges, as the generated code may contain errors in API usage, class, data structure, or missing project-specific information. As much of this project-specific context cannot fit into the prompts of LLMs, we must find ways to allow the model to explore the project-level code context. To this end, this paper puts forward a novel approach, termed ProCoder, which iteratively refines the project-level code context for precise code generation, guided by the compiler feedback. In particular, ProCoder first leverages compiler techniques to identify a mismatch between the generated code and the project's context. It then iteratively aligns and fixes the identified errors using information extracted from the code repository. We integrate ProCoder with two representative LLMs, i.e., GPT-3.5-Turbo and Code Llama (13B), and apply it to Python code generation. Experimental results show that ProCoder significantly improves the vanilla LLMs by over 80% in generating code dependent on project context, and consistently outperforms the existing retrieval-based code generation baselines.
Securely Fine-tuning Pre-trained Encoders Against Adversarial Examples
Mar 19, 2024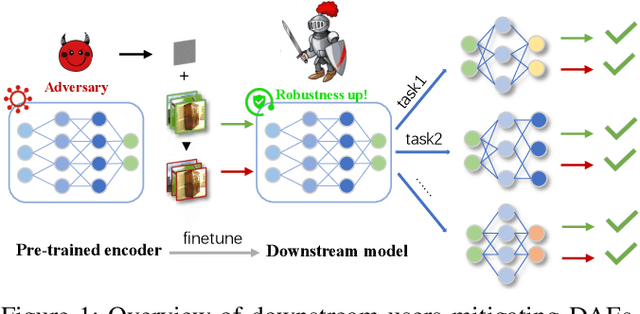
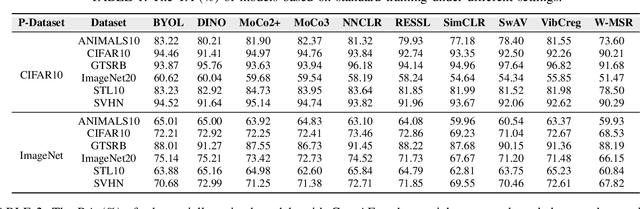
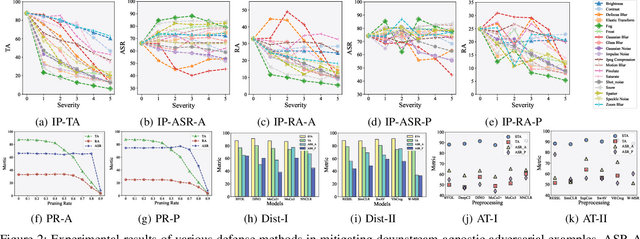
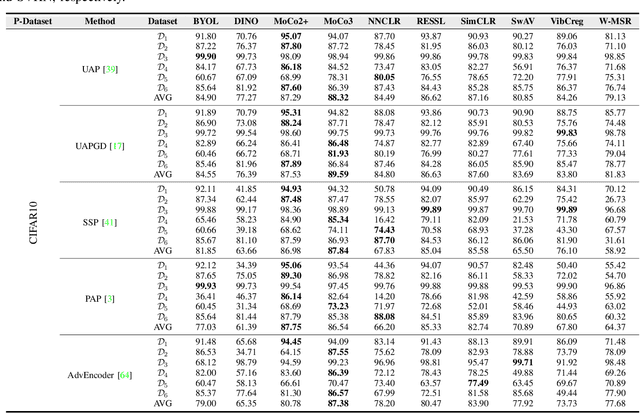
With the evolution of self-supervised learning, the pre-training paradigm has emerged as a predominant solution within the deep learning landscape. Model providers furnish pre-trained encoders designed to function as versatile feature extractors, enabling downstream users to harness the benefits of expansive models with minimal effort through fine-tuning. Nevertheless, recent works have exposed a vulnerability in pre-trained encoders, highlighting their susceptibility to downstream-agnostic adversarial examples (DAEs) meticulously crafted by attackers. The lingering question pertains to the feasibility of fortifying the robustness of downstream models against DAEs, particularly in scenarios where the pre-trained encoders are publicly accessible to the attackers. In this paper, we initially delve into existing defensive mechanisms against adversarial examples within the pre-training paradigm. Our findings reveal that the failure of current defenses stems from the domain shift between pre-training data and downstream tasks, as well as the sensitivity of encoder parameters. In response to these challenges, we propose Genetic Evolution-Nurtured Adversarial Fine-tuning (Gen-AF), a two-stage adversarial fine-tuning approach aimed at enhancing the robustness of downstream models. Our extensive experiments, conducted across ten self-supervised training methods and six datasets, demonstrate that Gen-AF attains high testing accuracy and robust testing accuracy against state-of-the-art DAEs.
GraphInstruct: Empowering Large Language Models with Graph Understanding and Reasoning Capability
Mar 07, 2024
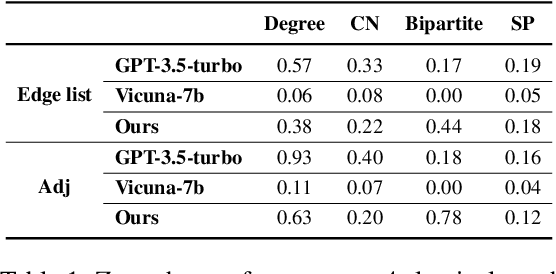
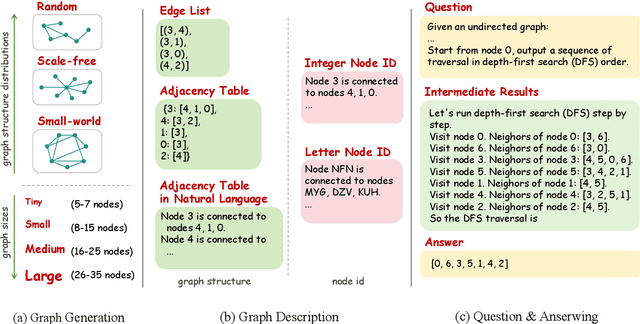
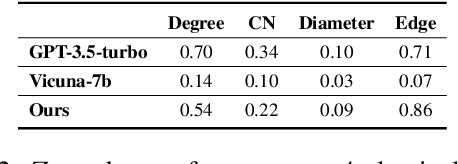
Evaluating and enhancing the general capabilities of large language models (LLMs) has been an important research topic. Graph is a common data structure in the real world, and understanding graph data is a crucial part for advancing general intelligence. To evaluate and enhance the graph understanding abilities of LLMs, in this paper, we propose a benchmark named GraphInstruct, which comprehensively includes 21 classical graph reasoning tasks, providing diverse graph generation pipelines and detailed reasoning steps. Based on GraphInstruct, we further construct GraphLM through efficient instruction-tuning, which shows prominent graph understanding capability. In order to enhance the LLM with graph reasoning capability as well, we propose a step mask training strategy, and construct a model named GraphLM+. As one of the pioneering efforts to enhance the graph understanding and reasoning abilities of LLMs, extensive experiments have demonstrated the superiority of GraphLM and GraphLM+ over other LLMs. We look forward to more researchers exploring the potential of LLMs in the graph data mining domain through GraphInstruct. Our code for generating GraphInstruct is released publicly at: https://github.com/CGCL-codes/GraphInstruct.
FedRKG: A Privacy-preserving Federated Recommendation Framework via Knowledge Graph Enhancement
Jan 20, 2024Federated Learning (FL) has emerged as a promising approach for preserving data privacy in recommendation systems by training models locally. Recently, Graph Neural Networks (GNN) have gained popularity in recommendation tasks due to their ability to capture high-order interactions between users and items. However, privacy concerns prevent the global sharing of the entire user-item graph. To address this limitation, some methods create pseudo-interacted items or users in the graph to compensate for missing information for each client. Unfortunately, these methods introduce random noise and raise privacy concerns. In this paper, we propose FedRKG, a novel federated recommendation system, where a global knowledge graph (KG) is constructed and maintained on the server using publicly available item information, enabling higher-order user-item interactions. On the client side, a relation-aware GNN model leverages diverse KG relationships. To protect local interaction items and obscure gradients, we employ pseudo-labeling and Local Differential Privacy (LDP). Extensive experiments conducted on three real-world datasets demonstrate the competitive performance of our approach compared to centralized algorithms while ensuring privacy preservation. Moreover, FedRKG achieves an average accuracy improvement of 4% compared to existing federated learning baselines.
Deep Learning for Code Intelligence: Survey, Benchmark and Toolkit
Dec 30, 2023Code intelligence leverages machine learning techniques to extract knowledge from extensive code corpora, with the aim of developing intelligent tools to improve the quality and productivity of computer programming. Currently, there is already a thriving research community focusing on code intelligence, with efforts ranging from software engineering, machine learning, data mining, natural language processing, and programming languages. In this paper, we conduct a comprehensive literature review on deep learning for code intelligence, from the aspects of code representation learning, deep learning techniques, and application tasks. We also benchmark several state-of-the-art neural models for code intelligence, and provide an open-source toolkit tailored for the rapid prototyping of deep-learning-based code intelligence models. In particular, we inspect the existing code intelligence models under the basis of code representation learning, and provide a comprehensive overview to enhance comprehension of the present state of code intelligence. Furthermore, we publicly release the source code and data resources to provide the community with a ready-to-use benchmark, which can facilitate the evaluation and comparison of existing and future code intelligence models (https://xcodemind.github.io). At last, we also point out several challenging and promising directions for future research.
MISA: Unveiling the Vulnerabilities in Split Federated Learning
Dec 19, 2023\textit{Federated learning} (FL) and \textit{split learning} (SL) are prevailing distributed paradigms in recent years. They both enable shared global model training while keeping data localized on users' devices. The former excels in parallel execution capabilities, while the latter enjoys low dependence on edge computing resources and strong privacy protection. \textit{Split federated learning} (SFL) combines the strengths of both FL and SL, making it one of the most popular distributed architectures. Furthermore, a recent study has claimed that SFL exhibits robustness against poisoning attacks, with a fivefold improvement compared to FL in terms of robustness. In this paper, we present a novel poisoning attack known as MISA. It poisons both the top and bottom models, causing a \textbf{\underline{misa}}lignment in the global model, ultimately leading to a drastic accuracy collapse. This attack unveils the vulnerabilities in SFL, challenging the conventional belief that SFL is robust against poisoning attacks. Extensive experiments demonstrate that our proposed MISA poses a significant threat to the availability of SFL, underscoring the imperative for academia and industry to accord this matter due attention.
Corrupting Convolution-based Unlearnable Datasets with Pixel-based Image Transformations
Nov 30, 2023Unlearnable datasets lead to a drastic drop in the generalization performance of models trained on them by introducing elaborate and imperceptible perturbations into clean training sets. Many existing defenses, e.g., JPEG compression and adversarial training, effectively counter UDs based on norm-constrained additive noise. However, a fire-new type of convolution-based UDs have been proposed and render existing defenses all ineffective, presenting a greater challenge to defenders. To address this, we express the convolution-based unlearnable sample as the result of multiplying a matrix by a clean sample in a simplified scenario, and formalize the intra-class matrix inconsistency as $\Theta_{imi}$, inter-class matrix consistency as $\Theta_{imc}$ to investigate the working mechanism of the convolution-based UDs. We conjecture that increasing both of these metrics will mitigate the unlearnability effect. Through validation experiments that commendably support our hypothesis, we further design a random matrix to boost both $\Theta_{imi}$ and $\Theta_{imc}$, achieving a notable degree of defense effect. Hence, by building upon and extending these facts, we first propose a brand-new image COrruption that employs randomly multiplicative transformation via INterpolation operation to successfully defend against convolution-based UDs. Our approach leverages global pixel random interpolations, effectively suppressing the impact of multiplicative noise in convolution-based UDs. Additionally, we have also designed two new forms of convolution-based UDs, and find that our defense is the most effective against them.
An Extensive Study on Adversarial Attack against Pre-trained Models of Code
Nov 23, 2023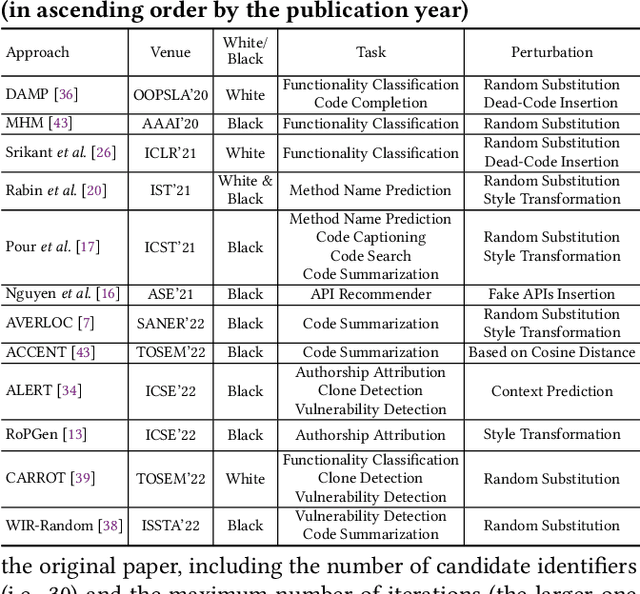
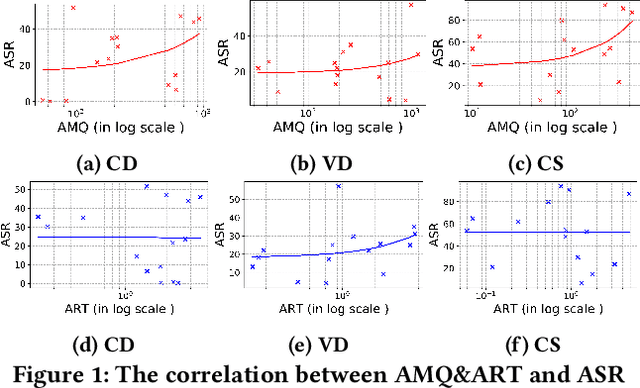
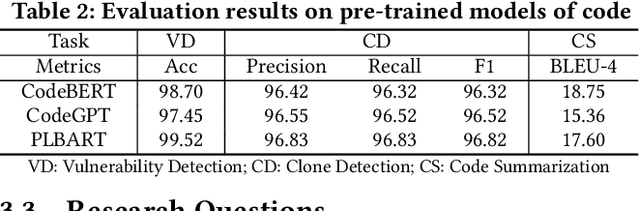
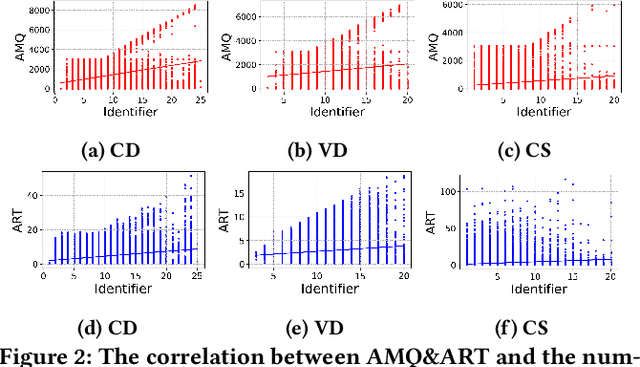
Transformer-based pre-trained models of code (PTMC) have been widely utilized and have achieved state-of-the-art performance in many mission-critical applications. However, they can be vulnerable to adversarial attacks through identifier substitution or coding style transformation, which can significantly degrade accuracy and may further incur security concerns. Although several approaches have been proposed to generate adversarial examples for PTMC, the effectiveness and efficiency of such approaches, especially on different code intelligence tasks, has not been well understood. To bridge this gap, this study systematically analyzes five state-of-the-art adversarial attack approaches from three perspectives: effectiveness, efficiency, and the quality of generated examples. The results show that none of the five approaches balances all these perspectives. Particularly, approaches with a high attack success rate tend to be time-consuming; the adversarial code they generate often lack naturalness, and vice versa. To address this limitation, we explore the impact of perturbing identifiers under different contexts and find that identifier substitution within for and if statements is the most effective. Based on these findings, we propose a new approach that prioritizes different types of statements for various tasks and further utilizes beam search to generate adversarial examples. Evaluation results show that it outperforms the state-of-the-art ALERT in terms of both effectiveness and efficiency while preserving the naturalness of the generated adversarial examples.
AdvCLIP: Downstream-agnostic Adversarial Examples in Multimodal Contrastive Learning
Aug 14, 2023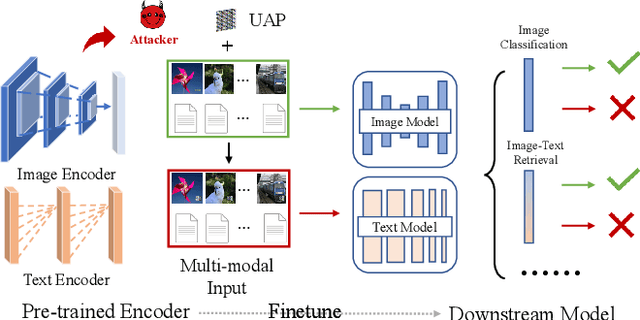
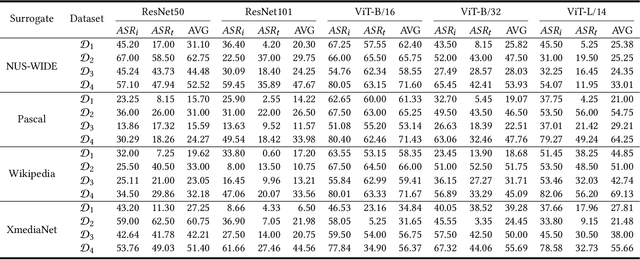
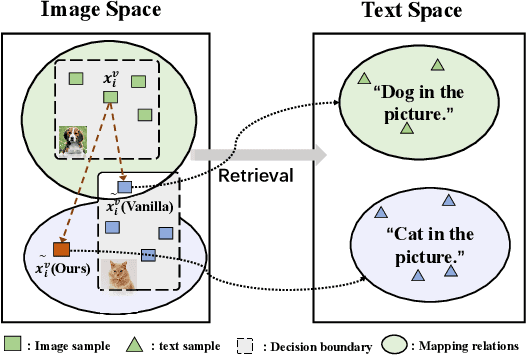
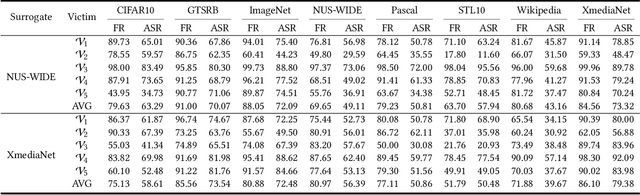
Multimodal contrastive learning aims to train a general-purpose feature extractor, such as CLIP, on vast amounts of raw, unlabeled paired image-text data. This can greatly benefit various complex downstream tasks, including cross-modal image-text retrieval and image classification. Despite its promising prospect, the security issue of cross-modal pre-trained encoder has not been fully explored yet, especially when the pre-trained encoder is publicly available for commercial use. In this work, we propose AdvCLIP, the first attack framework for generating downstream-agnostic adversarial examples based on cross-modal pre-trained encoders. AdvCLIP aims to construct a universal adversarial patch for a set of natural images that can fool all the downstream tasks inheriting the victim cross-modal pre-trained encoder. To address the challenges of heterogeneity between different modalities and unknown downstream tasks, we first build a topological graph structure to capture the relevant positions between target samples and their neighbors. Then, we design a topology-deviation based generative adversarial network to generate a universal adversarial patch. By adding the patch to images, we minimize their embeddings similarity to different modality and perturb the sample distribution in the feature space, achieving unviersal non-targeted attacks. Our results demonstrate the excellent attack performance of AdvCLIP on two types of downstream tasks across eight datasets. We also tailor three popular defenses to mitigate AdvCLIP, highlighting the need for new defense mechanisms to defend cross-modal pre-trained encoders.