 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYu Kong
Facial Affective Behavior Analysis with Instruction Tuning
Apr 07, 2024
Facial affective behavior analysis (FABA) is crucial for understanding human mental states from images. However, traditional approaches primarily deploy models to discriminate among discrete emotion categories, and lack the fine granularity and reasoning capability for complex facial behaviors. The advent of Multi-modal Large Language Models (MLLMs) has been proven successful in general visual understanding tasks. However, directly harnessing MLLMs for FABA is challenging due to the scarcity of datasets and benchmarks, neglecting facial prior knowledge, and low training efficiency. To address these challenges, we introduce (i) an instruction-following dataset for two FABA tasks, e.g., emotion and action unit recognition, (ii) a benchmark FABA-Bench with a new metric considering both recognition and generation ability, and (iii) a new MLLM "EmoLA" as a strong baseline to the community. Our initiative on the dataset and benchmarks reveal the nature and rationale of facial affective behaviors, i.e., fine-grained facial movement, interpretability, and reasoning. Moreover, to build an effective and efficient FABA MLLM, we introduce a facial prior expert module with face structure knowledge and a low-rank adaptation module into pre-trained MLLM. We conduct extensive experiments on FABA-Bench and four commonly-used FABA datasets. The results demonstrate that the proposed facial prior expert can boost the performance and EmoLA achieves the best results on our FABA-Bench. On commonly-used FABA datasets, EmoLA is competitive rivaling task-specific state-of-the-art models.
The Wolf Within: Covert Injection of Malice into MLLM Societies via an MLLM Operative
Feb 20, 2024Due to their unprecedented ability to process and respond to various types of data, Multimodal Large Language Models (MLLMs) are constantly defining the new boundary of Artificial General Intelligence (AGI). As these advanced generative models increasingly form collaborative networks for complex tasks, the integrity and security of these systems are crucial. Our paper, ``The Wolf Within'', explores a novel vulnerability in MLLM societies - the indirect propagation of malicious content. Unlike direct harmful output generation for MLLMs, our research demonstrates how a single MLLM agent can be subtly influenced to generate prompts that, in turn, induce other MLLM agents in the society to output malicious content. This subtle, yet potent method of indirect influence marks a significant escalation in the security risks associated with MLLMs. Our findings reveal that, with minimal or even no access to MLLMs' parameters, an MLLM agent, when manipulated to produce specific prompts or instructions, can effectively ``infect'' other agents within a society of MLLMs. This infection leads to the generation and circulation of harmful outputs, such as dangerous instructions or misinformation, across the society. We also show the transferability of these indirectly generated prompts, highlighting their possibility in propagating malice through inter-agent communication. This research provides a critical insight into a new dimension of threat posed by MLLMs, where a single agent can act as a catalyst for widespread malevolent influence. Our work underscores the urgent need for developing robust mechanisms to detect and mitigate such covert manipulations within MLLM societies, ensuring their safe and ethical utilization in societal applications. Our implementation is released at \url{https://github.com/ChengshuaiZhao0/The-Wolf-Within.git}.
CSGNN: Conquering Noisy Node labels via Dynamic Class-wise Selection
Nov 20, 2023Graph Neural Networks (GNNs) have emerged as a powerful tool for representation learning on graphs, but they often suffer from overfitting and label noise issues, especially when the data is scarce or imbalanced. Different from the paradigm of previous methods that rely on single-node confidence, in this paper, we introduce a novel Class-wise Selection for Graph Neural Networks, dubbed CSGNN, which employs a neighbor-aggregated latent space to adaptively select reliable nodes across different classes. Specifically, 1) to tackle the class imbalance issue, we introduce a dynamic class-wise selection mechanism, leveraging the clustering technique to identify clean nodes based on the neighbor-aggregated confidences. In this way, our approach can avoid the pitfalls of biased sampling which is common with global threshold techniques. 2) To alleviate the problem of noisy labels, built on the concept of the memorization effect, CSGNN prioritizes learning from clean nodes before noisy ones, thereby iteratively enhancing model performance while mitigating label noise. Through extensive experiments, we demonstrate that CSGNN outperforms state-of-the-art methods in terms of both effectiveness and robustness.
Latent Space Energy-based Model for Fine-grained Open Set Recognition
Sep 19, 2023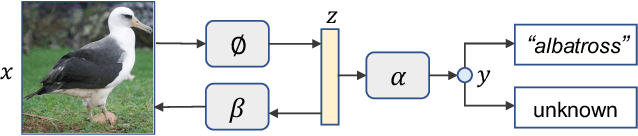
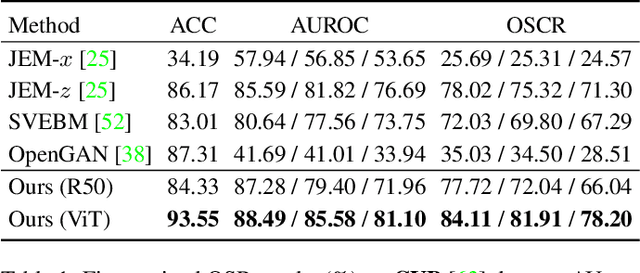
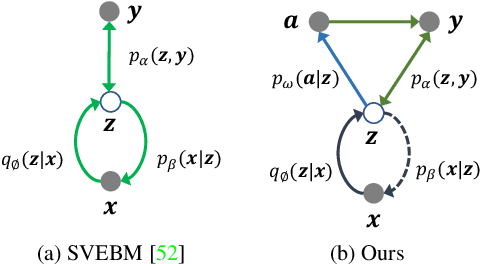
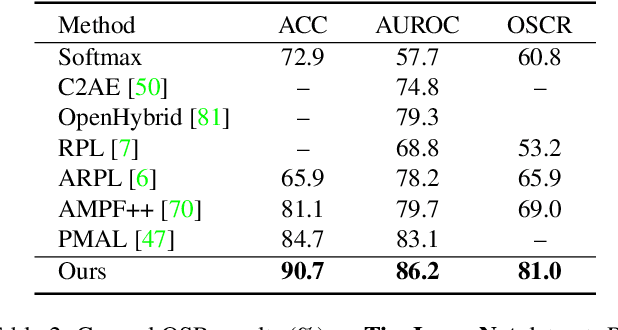
Fine-grained open-set recognition (FineOSR) aims to recognize images belonging to classes with subtle appearance differences while rejecting images of unknown classes. A recent trend in OSR shows the benefit of generative models to discriminative unknown detection. As a type of generative model, energy-based models (EBM) are the potential for hybrid modeling of generative and discriminative tasks. However, most existing EBMs suffer from density estimation in high-dimensional space, which is critical to recognizing images from fine-grained classes. In this paper, we explore the low-dimensional latent space with energy-based prior distribution for OSR in a fine-grained visual world. Specifically, based on the latent space EBM, we propose an attribute-aware information bottleneck (AIB), a residual attribute feature aggregation (RAFA) module, and an uncertainty-based virtual outlier synthesis (UVOS) module to improve the expressivity, granularity, and density of the samples in fine-grained classes, respectively. Our method is flexible to take advantage of recent vision transformers for powerful visual classification and generation. The method is validated on both fine-grained and general visual classification datasets while preserving the capability of generating photo-realistic fake images with high resolution.
On Model Explanations with Transferable Neural Pathways
Sep 18, 2023Neural pathways as model explanations consist of a sparse set of neurons that provide the same level of prediction performance as the whole model. Existing methods primarily focus on accuracy and sparsity but the generated pathways may offer limited interpretability thus fall short in explaining the model behavior. In this paper, we suggest two interpretability criteria of neural pathways: (i) same-class neural pathways should primarily consist of class-relevant neurons; (ii) each instance's neural pathway sparsity should be optimally determined. To this end, we propose a Generative Class-relevant Neural Pathway (GEN-CNP) model that learns to predict the neural pathways from the target model's feature maps. We propose to learn class-relevant information from features of deep and shallow layers such that same-class neural pathways exhibit high similarity. We further impose a faithfulness criterion for GEN-CNP to generate pathways with instance-specific sparsity. We propose to transfer the class-relevant neural pathways to explain samples of the same class and show experimentally and qualitatively their faithfulness and interpretability.
ATM: Action Temporality Modeling for Video Question Answering
Sep 05, 2023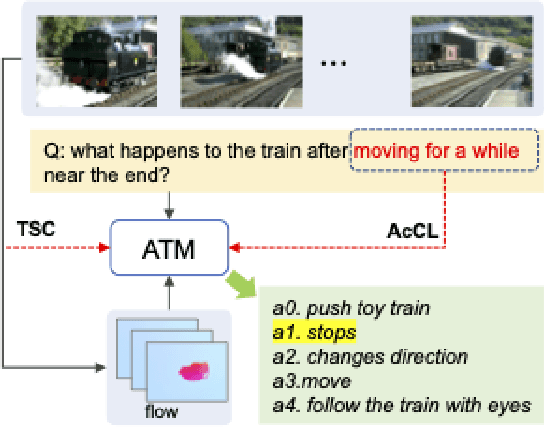
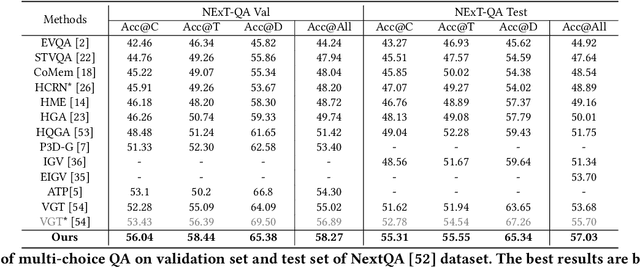
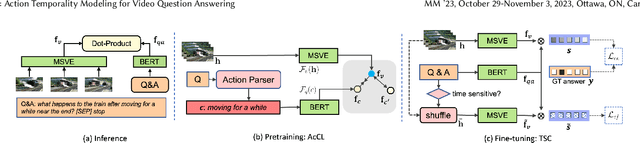
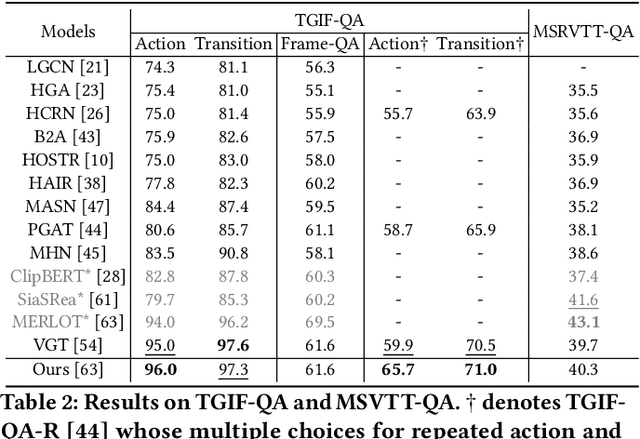
Despite significant progress in video question answering (VideoQA), existing methods fall short of questions that require causal/temporal reasoning across frames. This can be attributed to imprecise motion representations. We introduce Action Temporality Modeling (ATM) for temporality reasoning via three-fold uniqueness: (1) rethinking the optical flow and realizing that optical flow is effective in capturing the long horizon temporality reasoning; (2) training the visual-text embedding by contrastive learning in an action-centric manner, leading to better action representations in both vision and text modalities; and (3) preventing the model from answering the question given the shuffled video in the fine-tuning stage, to avoid spurious correlation between appearance and motion and hence ensure faithful temporality reasoning. In the experiments, we show that ATM outperforms previous approaches in terms of the accuracy on multiple VideoQAs and exhibits better true temporality reasoning ability.
Uncertainty-aware State Space Transformer for Egocentric 3D Hand Trajectory Forecasting
Jul 17, 2023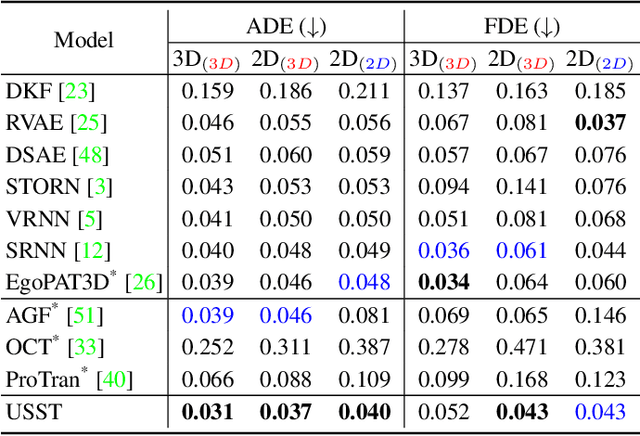
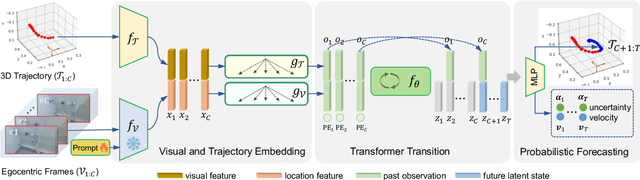
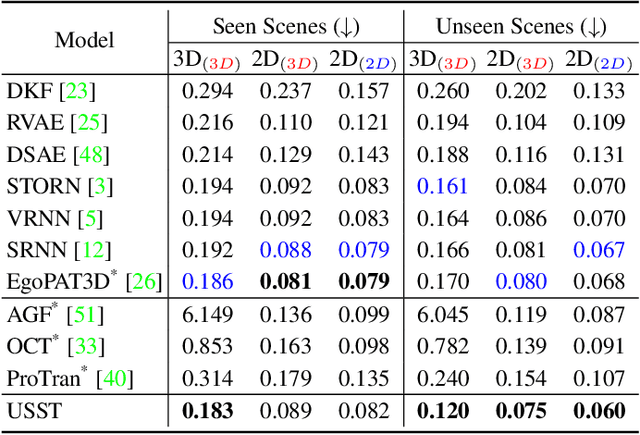
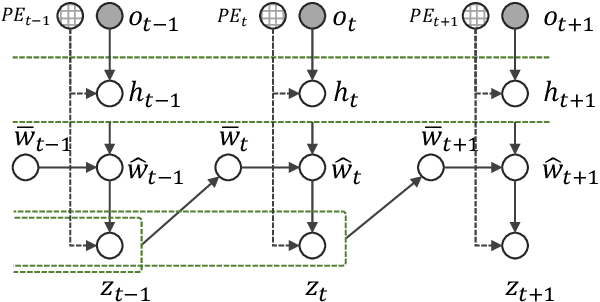
Hand trajectory forecasting from egocentric views is crucial for enabling a prompt understanding of human intentions when interacting with AR/VR systems. However, existing methods handle this problem in a 2D image space which is inadequate for 3D real-world applications. In this paper, we set up an egocentric 3D hand trajectory forecasting task that aims to predict hand trajectories in a 3D space from early observed RGB videos in a first-person view. To fulfill this goal, we propose an uncertainty-aware state space Transformer (USST) that takes the merits of the attention mechanism and aleatoric uncertainty within the framework of the classical state-space model. The model can be further enhanced by the velocity constraint and visual prompt tuning (VPT) on large vision transformers. Moreover, we develop an annotation workflow to collect 3D hand trajectories with high quality. Experimental results on H2O and EgoPAT3D datasets demonstrate the superiority of USST for both 2D and 3D trajectory forecasting. The code and datasets are publicly released: https://github.com/Cogito2012/USST.
Prompting Language-Informed Distribution for Compositional Zero-Shot Learning
May 23, 2023
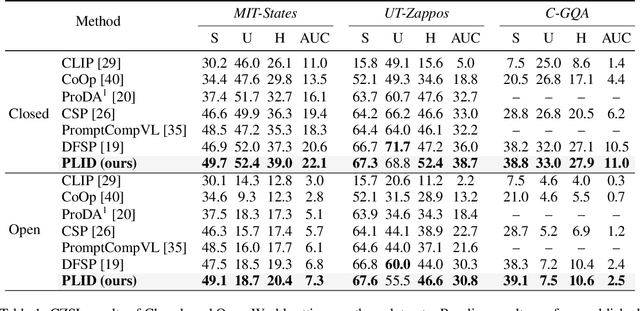
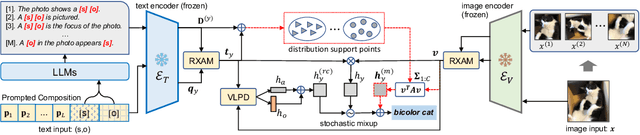
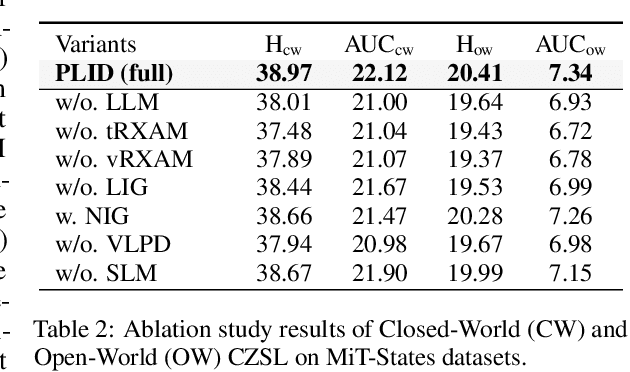
The compositional zero-shot learning (CZSL) task aims to recognize unseen compositional visual concepts (i.e., sliced tomatoes), where the models are learned only from the seen compositions (i.e., sliced potatoes and red tomatoes). Thanks to the prompt tuning on large pre-trained visual language models such as CLIP, recent literature shows impressively better CZSL performance than traditional vision-based methods. However, the key aspects that impact the generalization to unseen compositions, including the diversity and informativeness of class context, and the entanglement between visual primitives (i.e., states and objects), are not properly addressed in existing CLIP-based CZSL literature. In this paper, we propose a model by prompting the language-informed distribution, aka., PLID, for the CZSL task. Specifically, the PLID leverages pre-trained large language models (LLM) to 1) formulate the language-informed class distribution, and 2) enhance the compositionality of the softly prompted class embedding. Moreover, a stochastic logit mixup strategy is proposed to dynamically fuse the decisions from the predictions in the compositional and the primitive logit space. Orthogonal to the existing literature of soft, hard, or distributional prompts, our method advocates prompting the LLM-supported class distribution that leads to a better compositional zero-shot generalization. Experimental results on MIT-States, UT-Zappos, and C-GQA datasets show the superior performance of the PLID to the prior arts. The code and models will be publicly released.
Catch Missing Details: Image Reconstruction with Frequency Augmented Variational Autoencoder
May 04, 2023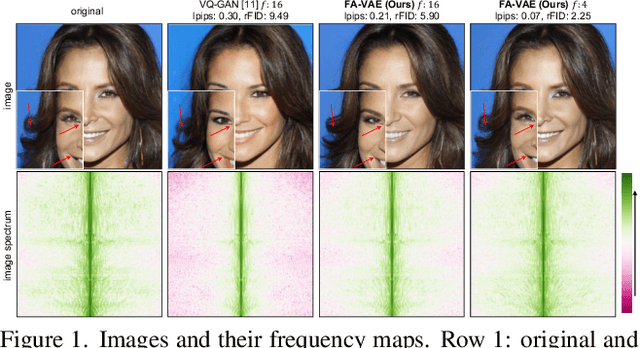
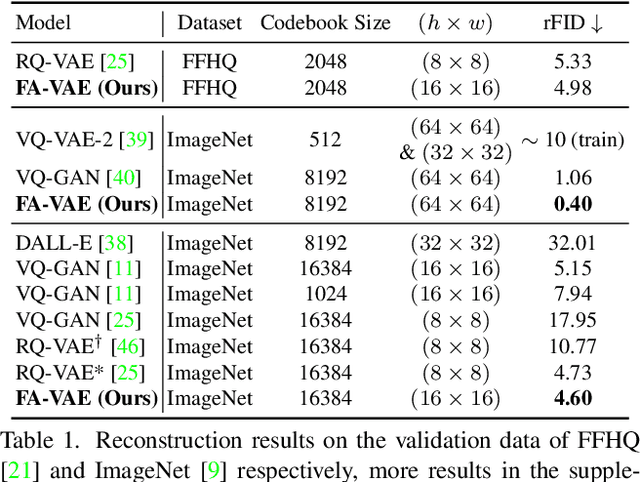
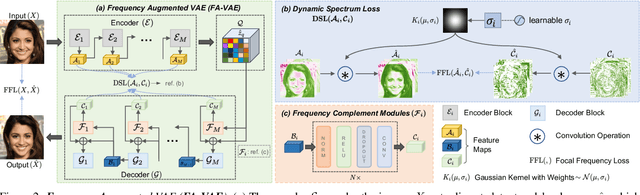
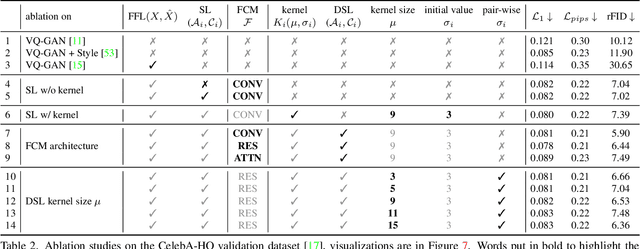
The popular VQ-VAE models reconstruct images through learning a discrete codebook but suffer from a significant issue in the rapid quality degradation of image reconstruction as the compression rate rises. One major reason is that a higher compression rate induces more loss of visual signals on the higher frequency spectrum which reflect the details on pixel space. In this paper, a Frequency Complement Module (FCM) architecture is proposed to capture the missing frequency information for enhancing reconstruction quality. The FCM can be easily incorporated into the VQ-VAE structure, and we refer to the new model as Frequency Augmented VAE (FA-VAE). In addition, a Dynamic Spectrum Loss (DSL) is introduced to guide the FCMs to balance between various frequencies dynamically for optimal reconstruction. FA-VAE is further extended to the text-to-image synthesis task, and a Cross-attention Autoregressive Transformer (CAT) is proposed to obtain more precise semantic attributes in texts. Extensive reconstruction experiments with different compression rates are conducted on several benchmark datasets, and the results demonstrate that the proposed FA-VAE is able to restore more faithfully the details compared to SOTA methods. CAT also shows improved generation quality with better image-text semantic alignment.
GateHUB: Gated History Unit with Background Suppression for Online Action Detection
Jun 09, 2022
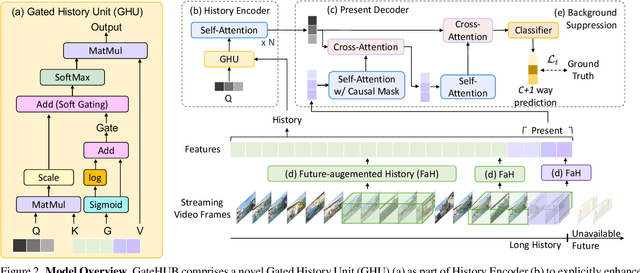
Online action detection is the task of predicting the action as soon as it happens in a streaming video. A major challenge is that the model does not have access to the future and has to solely rely on the history, i.e., the frames observed so far, to make predictions. It is therefore important to accentuate parts of the history that are more informative to the prediction of the current frame. We present GateHUB, Gated History Unit with Background Suppression, that comprises a novel position-guided gated cross-attention mechanism to enhance or suppress parts of the history as per how informative they are for current frame prediction. GateHUB further proposes Future-augmented History (FaH) to make history features more informative by using subsequently observed frames when available. In a single unified framework, GateHUB integrates the transformer's ability of long-range temporal modeling and the recurrent model's capacity to selectively encode relevant information. GateHUB also introduces a background suppression objective to further mitigate false positive background frames that closely resemble the action frames. Extensive validation on three benchmark datasets, THUMOS, TVSeries, and HDD, demonstrates that GateHUB significantly outperforms all existing methods and is also more efficient than the existing best work. Furthermore, a flow-free version of GateHUB is able to achieve higher or close accuracy at 2.8x higher frame rate compared to all existing methods that require both RGB and optical flow information for prediction.