 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQiong Liu
LpQcM: Adaptable Lesion-Quantification-Consistent Modulation for Deep Learning Low-Count PET Image Denoising
Apr 27, 2024
Deep learning-based positron emission tomography (PET) image denoising offers the potential to reduce radiation exposure and scanning time by transforming low-count images into high-count equivalents. However, existing methods typically blur crucial details, leading to inaccurate lesion quantification. This paper proposes a lesion-perceived and quantification-consistent modulation (LpQcM) strategy for enhanced PET image denoising, via employing downstream lesion quantification analysis as auxiliary tools. The LpQcM is a plug-and-play design adaptable to a wide range of model architectures, modulating the sampling and optimization procedures of model training without adding any computational burden to the inference phase. Specifically, the LpQcM consists of two components, the lesion-perceived modulation (LpM) and the multiscale quantification-consistent modulation (QcM). The LpM enhances lesion contrast and visibility by allocating higher sampling weights and stricter loss criteria to lesion-present samples determined by an auxiliary segmentation network than lesion-absent ones. The QcM further emphasizes accuracy of quantification for both the mean and maximum standardized uptake value (SUVmean and SUVmax) across multiscale sub-regions throughout the entire image, thereby enhancing the overall image quality. Experiments conducted on large PET datasets from multiple centers and vendors, and varying noise levels demonstrated the LpQcM efficacy across various denoising frameworks. Compared to frameworks without LpQcM, the integration of LpQcM reduces the lesion SUVmean bias by 2.92% on average and increases the peak signal-to-noise ratio (PSNR) by 0.34 on average, for denoising images of extremely low-count levels below 10%.
Unified Scene Representation and Reconstruction for 3D Large Language Models
Apr 19, 2024Enabling Large Language Models (LLMs) to interact with 3D environments is challenging. Existing approaches extract point clouds either from ground truth (GT) geometry or 3D scenes reconstructed by auxiliary models. Text-image aligned 2D features from CLIP are then lifted to point clouds, which serve as inputs for LLMs. However, this solution lacks the establishment of 3D point-to-point connections, leading to a deficiency of spatial structure information. Concurrently, the absence of integration and unification between the geometric and semantic representations of the scene culminates in a diminished level of 3D scene understanding. In this paper, we demonstrate the importance of having a unified scene representation and reconstruction framework, which is essential for LLMs in 3D scenes. Specifically, we introduce Uni3DR^2 extracts 3D geometric and semantic aware representation features via the frozen pre-trained 2D foundation models (e.g., CLIP and SAM) and a multi-scale aggregate 3D decoder. Our learned 3D representations not only contribute to the reconstruction process but also provide valuable knowledge for LLMs. Experimental results validate that our Uni3DR^2 yields convincing gains over the baseline on the 3D reconstruction dataset ScanNet (increasing F-Score by +1.8\%). When applied to LLMs, our Uni3DR^2-LLM exhibits superior performance over the baseline on the 3D vision-language understanding dataset ScanQA (increasing BLEU-1 by +4.0\% and +4.2\% on the val set and test set, respectively). Furthermore, it outperforms the state-of-the-art method that uses additional GT point clouds on both ScanQA and 3DMV-VQA.
TAI-GAN: A Temporally and Anatomically Informed Generative Adversarial Network for early-to-late frame conversion in dynamic cardiac PET inter-frame motion correction
Feb 14, 2024Inter-frame motion in dynamic cardiac positron emission tomography (PET) using rubidium-82 (82-Rb) myocardial perfusion imaging impacts myocardial blood flow (MBF) quantification and the diagnosis accuracy of coronary artery diseases. However, the high cross-frame distribution variation due to rapid tracer kinetics poses a considerable challenge for inter-frame motion correction, especially for early frames where intensity-based image registration techniques often fail. To address this issue, we propose a novel method called Temporally and Anatomically Informed Generative Adversarial Network (TAI-GAN) that utilizes an all-to-one mapping to convert early frames into those with tracer distribution similar to the last reference frame. The TAI-GAN consists of a feature-wise linear modulation layer that encodes channel-wise parameters generated from temporal information and rough cardiac segmentation masks with local shifts that serve as anatomical information. Our proposed method was evaluated on a clinical 82-Rb PET dataset, and the results show that our TAI-GAN can produce converted early frames with high image quality, comparable to the real reference frames. After TAI-GAN conversion, the motion estimation accuracy and subsequent myocardial blood flow (MBF) quantification with both conventional and deep learning-based motion correction methods were improved compared to using the original frames.
POUR-Net: A Population-Prior-Aided Over-Under-Representation Network for Low-Count PET Attenuation Map Generation
Jan 25, 2024Low-dose PET offers a valuable means of minimizing radiation exposure in PET imaging. However, the prevalent practice of employing additional CT scans for generating attenuation maps (u-map) for PET attenuation correction significantly elevates radiation doses. To address this concern and further mitigate radiation exposure in low-dose PET exams, we propose POUR-Net - an innovative population-prior-aided over-under-representation network that aims for high-quality attenuation map generation from low-dose PET. First, POUR-Net incorporates an over-under-representation network (OUR-Net) to facilitate efficient feature extraction, encompassing both low-resolution abstracted and fine-detail features, for assisting deep generation on the full-resolution level. Second, complementing OUR-Net, a population prior generation machine (PPGM) utilizing a comprehensive CT-derived u-map dataset, provides additional prior information to aid OUR-Net generation. The integration of OUR-Net and PPGM within a cascade framework enables iterative refinement of $\mu$-map generation, resulting in the production of high-quality $\mu$-maps. Experimental results underscore the effectiveness of POUR-Net, showing it as a promising solution for accurate CT-free low-count PET attenuation correction, which also surpasses the performance of previous baseline methods.
Dual-Domain Coarse-to-Fine Progressive Estimation Network for Simultaneous Denoising, Limited-View Reconstruction, and Attenuation Correction of Cardiac SPECT
Jan 23, 2024Single-Photon Emission Computed Tomography (SPECT) is widely applied for the diagnosis of coronary artery diseases. Low-dose (LD) SPECT aims to minimize radiation exposure but leads to increased image noise. Limited-view (LV) SPECT, such as the latest GE MyoSPECT ES system, enables accelerated scanning and reduces hardware expenses but degrades reconstruction accuracy. Additionally, Computed Tomography (CT) is commonly used to derive attenuation maps ($\mu$-maps) for attenuation correction (AC) of cardiac SPECT, but it will introduce additional radiation exposure and SPECT-CT misalignments. Although various methods have been developed to solely focus on LD denoising, LV reconstruction, or CT-free AC in SPECT, the solution for simultaneously addressing these tasks remains challenging and under-explored. Furthermore, it is essential to explore the potential of fusing cross-domain and cross-modality information across these interrelated tasks to further enhance the accuracy of each task. Thus, we propose a Dual-Domain Coarse-to-Fine Progressive Network (DuDoCFNet), a multi-task learning method for simultaneous LD denoising, LV reconstruction, and CT-free $\mu$-map generation of cardiac SPECT. Paired dual-domain networks in DuDoCFNet are cascaded using a multi-layer fusion mechanism for cross-domain and cross-modality feature fusion. Two-stage progressive learning strategies are applied in both projection and image domains to achieve coarse-to-fine estimations of SPECT projections and CT-derived $\mu$-maps. Our experiments demonstrate DuDoCFNet's superior accuracy in estimating projections, generating $\mu$-maps, and AC reconstructions compared to existing single- or multi-task learning methods, under various iterations and LD levels. The source code of this work is available at https://github.com/XiongchaoChen/DuDoCFNet-MultiTask.
Dose-aware Diffusion Model for 3D Ultra Low-dose PET Imaging
Nov 07, 2023As PET imaging is accompanied by substantial radiation exposure and cancer risk, reducing radiation dose in PET scans is an important topic. Recently, diffusion models have emerged as the new state-of-the-art generative model to generate high-quality samples and have demonstrated strong potential for various tasks in medical imaging. However, it is difficult to extend diffusion models for 3D image reconstructions due to the memory burden. Directly stacking 2D slices together to create 3D image volumes would results in severe inconsistencies between slices. Previous works tried to either applying a penalty term along the z-axis to remove inconsistencies or reconstructing the 3D image volumes with 2 pre-trained perpendicular 2D diffusion models. Nonetheless, these previous methods failed to produce satisfactory results in challenging cases for PET image denoising. In addition to administered dose, the noise-levels in PET images are affected by several other factors in clinical settings, such as scan time, patient size, and weight, etc. Therefore, a method to simultaneously denoise PET images with different noise-levels is needed. Here, we proposed a dose-aware diffusion model for 3D low-dose PET imaging (DDPET) to address these challenges. The proposed DDPET method was tested on 295 patients from three different medical institutions globally with different low-dose levels. These patient data were acquired on three different commercial PET scanners, including Siemens Vision Quadra, Siemens mCT, and United Imaging Healthcare uExplorere. The proposed method demonstrated superior performance over previously proposed diffusion models for 3D imaging problems as well as models proposed for noise-aware medical image denoising. Code is available at: xxx.
TAI-GAN: Temporally and Anatomically Informed GAN for early-to-late frame conversion in dynamic cardiac PET motion correction
Aug 23, 2023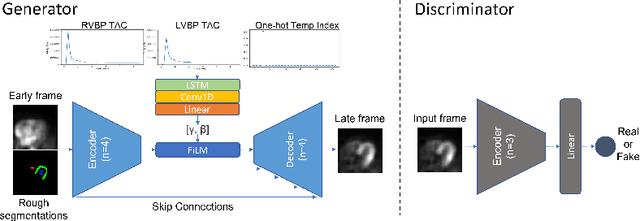
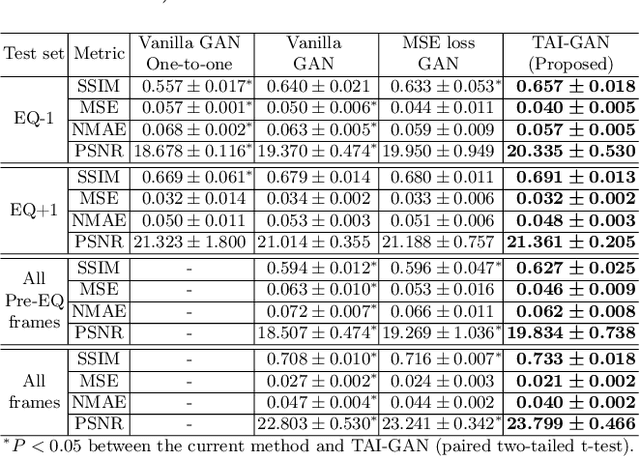
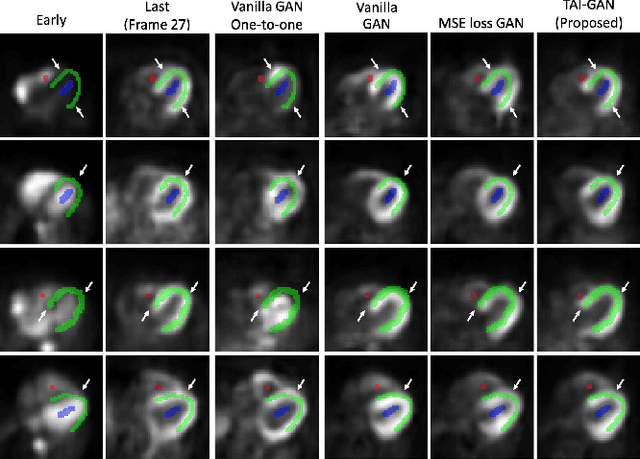
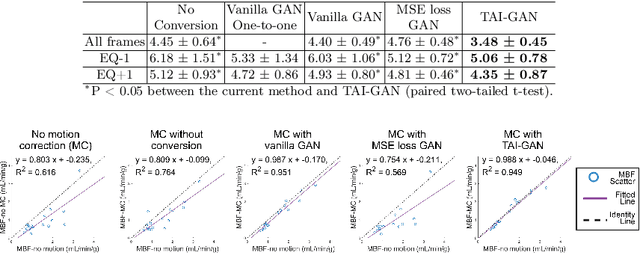
The rapid tracer kinetics of rubidium-82 ($^{82}$Rb) and high variation of cross-frame distribution in dynamic cardiac positron emission tomography (PET) raise significant challenges for inter-frame motion correction, particularly for the early frames where conventional intensity-based image registration techniques are not applicable. Alternatively, a promising approach utilizes generative methods to handle the tracer distribution changes to assist existing registration methods. To improve frame-wise registration and parametric quantification, we propose a Temporally and Anatomically Informed Generative Adversarial Network (TAI-GAN) to transform the early frames into the late reference frame using an all-to-one mapping. Specifically, a feature-wise linear modulation layer encodes channel-wise parameters generated from temporal tracer kinetics information, and rough cardiac segmentations with local shifts serve as the anatomical information. We validated our proposed method on a clinical $^{82}$Rb PET dataset and found that our TAI-GAN can produce converted early frames with high image quality, comparable to the real reference frames. After TAI-GAN conversion, motion estimation accuracy and clinical myocardial blood flow (MBF) quantification were improved compared to using the original frames. Our code is published at https://github.com/gxq1998/TAI-GAN.
Masked Spatio-Temporal Structure Prediction for Self-supervised Learning on Point Cloud Videos
Aug 18, 2023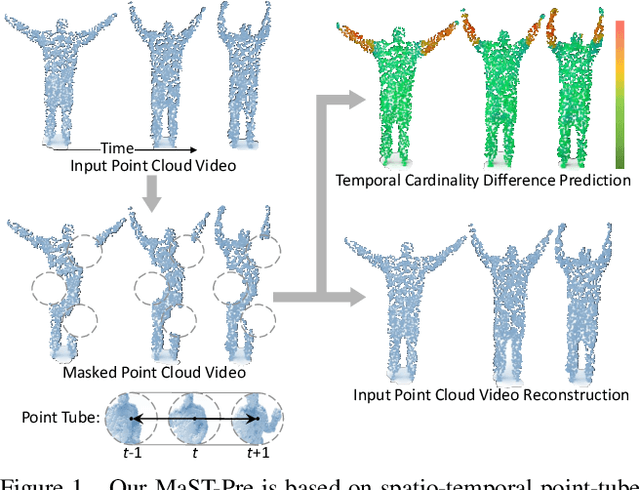
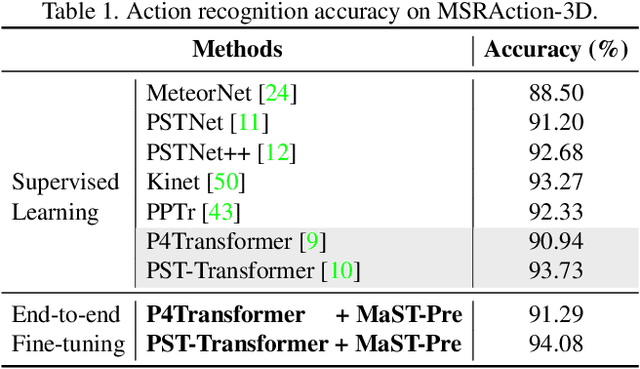
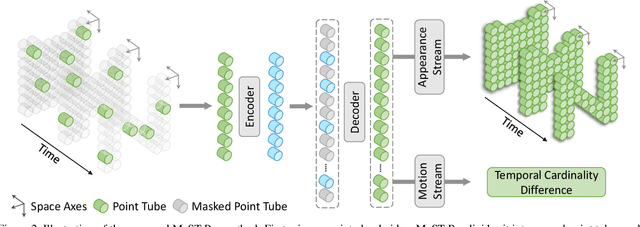

Recently, the community has made tremendous progress in developing effective methods for point cloud video understanding that learn from massive amounts of labeled data. However, annotating point cloud videos is usually notoriously expensive. Moreover, training via one or only a few traditional tasks (e.g., classification) may be insufficient to learn subtle details of the spatio-temporal structure existing in point cloud videos. In this paper, we propose a Masked Spatio-Temporal Structure Prediction (MaST-Pre) method to capture the structure of point cloud videos without human annotations. MaST-Pre is based on spatio-temporal point-tube masking and consists of two self-supervised learning tasks. First, by reconstructing masked point tubes, our method is able to capture the appearance information of point cloud videos. Second, to learn motion, we propose a temporal cardinality difference prediction task that estimates the change in the number of points within a point tube. In this way, MaST-Pre is forced to model the spatial and temporal structure in point cloud videos. Extensive experiments on MSRAction-3D, NTU-RGBD, NvGesture, and SHREC'17 demonstrate the effectiveness of the proposed method.
Distributed Decisions on Optimal Load Balancing in Loss Networks
Jul 17, 2023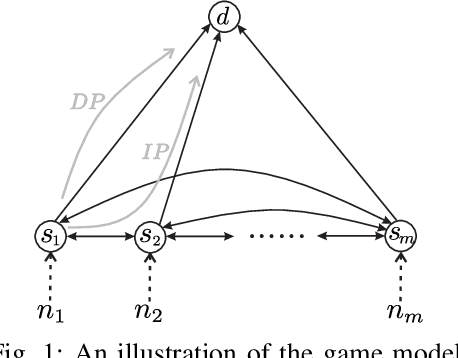
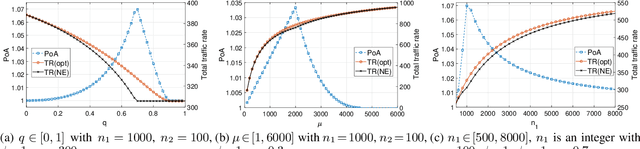

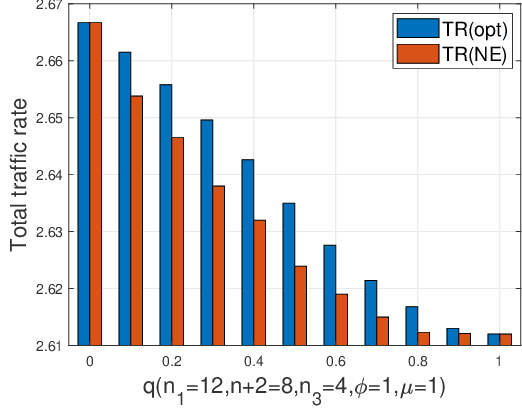
When multiple users share a common link in direct transmission, packet loss and network collision may occur due to the simultaneous arrival of traffics at the source node. To tackle this problem, users may resort to an indirect path: the packet flows are first relayed through a sidelink to another source node, then transmitted to the destination. This behavior brings the problems of packet routing or load balancing: (1) how to maximize the total traffic in a collaborative way; (2) how self-interested users choose routing strategies to minimize their individual packet loss independently. In this work, we propose a generalized mathematical framework to tackle the packet and load balancing issue in loss networks. In centralized scenarios with a planner, we provide a polynomial-time algorithm to compute the system optimum point where the total traffic rate is maximized. Conversely, in decentralized settings with autonomous users making distributed decisions, the system converges to an equilibrium where no user can reduce their loss probability through unilateral deviation. We thereby provide a full characterization of Nash equilibrium and examine the efficiency loss stemming from selfish behaviors, both theoretically and empirically. In general, the performance degradation caused by selfish behaviors is not catastrophic; however, this gap is not monotonic and can have extreme values in certain specific scenarios.
All in One: Exploring Unified Vision-Language Tracking with Multi-Modal Alignment
Jul 07, 2023
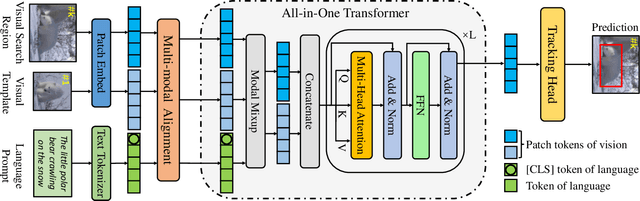
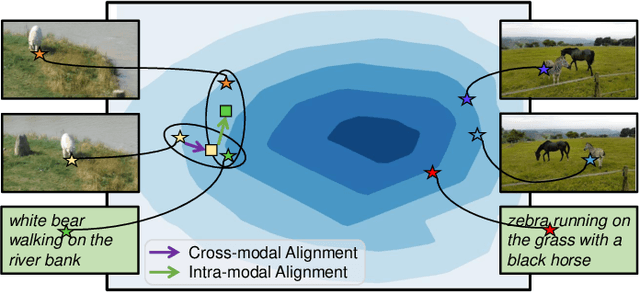
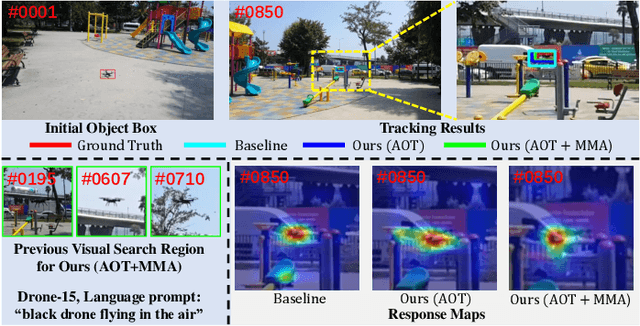
Current mainstream vision-language (VL) tracking framework consists of three parts, \ie a visual feature extractor, a language feature extractor, and a fusion model. To pursue better performance, a natural modus operandi for VL tracking is employing customized and heavier unimodal encoders, and multi-modal fusion models. Albeit effective, existing VL trackers separate feature extraction and feature integration, resulting in extracted features that lack semantic guidance and have limited target-aware capability in complex scenarios, \eg similar distractors and extreme illumination. In this work, inspired by the recent success of exploring foundation models with unified architecture for both natural language and computer vision tasks, we propose an All-in-One framework, which learns joint feature extraction and interaction by adopting a unified transformer backbone. Specifically, we mix raw vision and language signals to generate language-injected vision tokens, which we then concatenate before feeding into the unified backbone architecture. This approach achieves feature integration in a unified backbone, removing the need for carefully-designed fusion modules and resulting in a more effective and efficient VL tracking framework. To further improve the learning efficiency, we introduce a multi-modal alignment module based on cross-modal and intra-modal contrastive objectives, providing more reasonable representations for the unified All-in-One transformer backbone. Extensive experiments on five benchmarks, \ie OTB99-L, TNL2K, LaSOT, LaSOT$_{\rm Ext}$ and WebUAV-3M, demonstrate the superiority of the proposed tracker against existing state-of-the-arts on VL tracking. Codes will be made publicly available.