 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGuangyao Dou
Towards Safer Large Language Models through Machine Unlearning
Feb 15, 2024
The rapid advancement of Large Language Models (LLMs) has demonstrated their vast potential across various domains, attributed to their extensive pretraining knowledge and exceptional generalizability. However, LLMs often encounter challenges in generating harmful content when faced with problematic prompts. To address this problem, existing work attempted to implement a gradient ascent based approach to prevent LLMs from producing harmful output. While these methods can be effective, they frequently impact the model utility in responding to normal prompts. To address this gap, we introduce Selective Knowledge negation Unlearning (SKU), a novel unlearning framework for LLMs, designed to eliminate harmful knowledge while preserving utility on normal prompts. Specifically, SKU is consisted of two stages: harmful knowledge acquisition stage and knowledge negation stage. The first stage aims to identify and acquire harmful knowledge within the model, whereas the second is dedicated to remove this knowledge. SKU selectively isolates and removes harmful knowledge in model parameters, ensuring the model's performance remains robust on normal prompts. Our experiments conducted across various LLM architectures demonstrate that SKU identifies a good balance point between removing harmful information and preserving utility.
Breaking the Trilemma of Privacy, Utility, Efficiency via Controllable Machine Unlearning
Oct 28, 2023Machine Unlearning (MU) algorithms have become increasingly critical due to the imperative adherence to data privacy regulations. The primary objective of MU is to erase the influence of specific data samples on a given model without the need to retrain it from scratch. Accordingly, existing methods focus on maximizing user privacy protection. However, there are different degrees of privacy regulations for each real-world web-based application. Exploring the full spectrum of trade-offs between privacy, model utility, and runtime efficiency is critical for practical unlearning scenarios. Furthermore, designing the MU algorithm with simple control of the aforementioned trade-off is desirable but challenging due to the inherent complex interaction. To address the challenges, we present Controllable Machine Unlearning (ConMU), a novel framework designed to facilitate the calibration of MU. The ConMU framework contains three integral modules: an important data selection module that reconciles the runtime efficiency and model generalization, a progressive Gaussian mechanism module that balances privacy and model generalization, and an unlearning proxy that controls the trade-offs between privacy and runtime efficiency. Comprehensive experiments on various benchmark datasets have demonstrated the robust adaptability of our control mechanism and its superiority over established unlearning methods. ConMU explores the full spectrum of the Privacy-Utility-Efficiency trade-off and allows practitioners to account for different real-world regulations. Source code available at: https://github.com/guangyaodou/ConMU.
EEG4Students: An Experimental Design for EEG Data Collection and Machine Learning Analysis
Aug 24, 2022

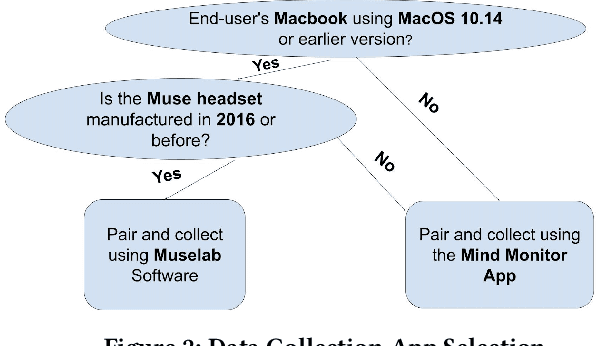

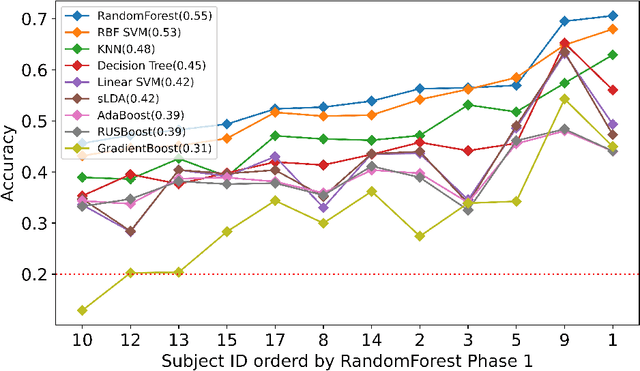
Using Machine Learning and Deep Learning to predict cognitive tasks from electroencephalography (EEG) signals has been a fast-developing area in Brain-Computer Interfaces (BCI). However, during the COVID-19 pandemic, data collection and analysis could be more challenging. The remote experiment during the pandemic yields several challenges, and we discuss the possible solutions. This paper explores machine learning algorithms that can run efficiently on personal computers for BCI classification tasks. The results show that Random Forest and RBF SVM perform well for EEG classification tasks. Furthermore, we investigate how to conduct such BCI experiments using affordable consumer-grade devices to collect EEG-based BCI data. In addition, we have developed the data collection protocol, EEG4Students, that grants non-experts who are interested in a guideline for such data collection. Our code and data can be found at https://github.com/GuangyaoDou/EEG4Students.
Time Majority Voting, a PC-based EEG Classifier for Non-expert Users
Jul 26, 2022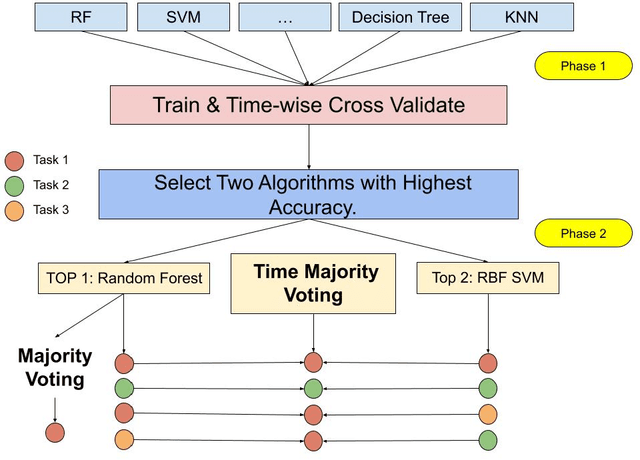
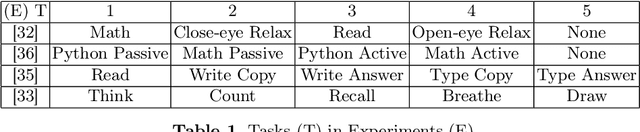
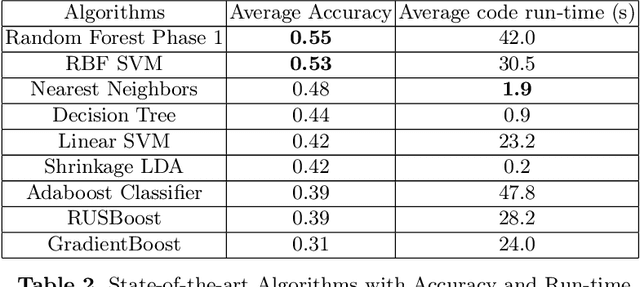
Using Machine Learning and Deep Learning to predict cognitive tasks from electroencephalography (EEG) signals is a rapidly advancing field in Brain-Computer Interfaces (BCI). In contrast to the fields of computer vision and natural language processing, the data amount of these trials is still rather tiny. Developing a PC-based machine learning technique to increase the participation of non-expert end-users could help solve this data collection issue. We created a novel algorithm for machine learning called Time Majority Voting (TMV). In our experiment, TMV performed better than cutting-edge algorithms. It can operate efficiently on personal computers for classification tasks involving the BCI. These interpretable data also assisted end-users and researchers in comprehending EEG tests better.