 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZezhou Cheng
Machine Unlearning of Pre-trained Large Language Models
Feb 27, 2024
This study investigates the concept of the `right to be forgotten' within the context of large language models (LLMs). We explore machine unlearning as a pivotal solution, with a focus on pre-trained models--a notably under-researched area. Our research delineates a comprehensive framework for machine unlearning in pre-trained LLMs, encompassing a critical analysis of seven diverse unlearning methods. Through rigorous evaluation using curated datasets from arXiv, books, and GitHub, we establish a robust benchmark for unlearning performance, demonstrating that these methods are over $10^5$ times more computationally efficient than retraining. Our results show that integrating gradient ascent with gradient descent on in-distribution data improves hyperparameter robustness. We also provide detailed guidelines for efficient hyperparameter tuning in the unlearning process. Our findings advance the discourse on ethical AI practices, offering substantive insights into the mechanics of machine unlearning for pre-trained LLMs and underscoring the potential for responsible AI development.
LU-NeRF: Scene and Pose Estimation by Synchronizing Local Unposed NeRFs
Jun 08, 2023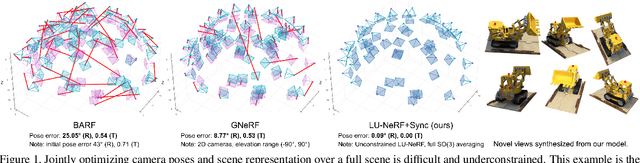
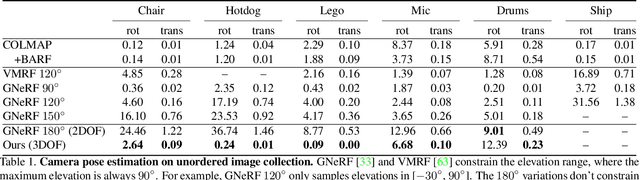
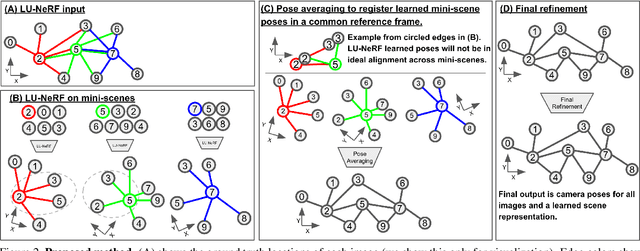
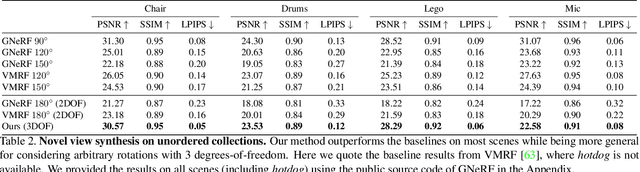
A critical obstacle preventing NeRF models from being deployed broadly in the wild is their reliance on accurate camera poses. Consequently, there is growing interest in extending NeRF models to jointly optimize camera poses and scene representation, which offers an alternative to off-the-shelf SfM pipelines which have well-understood failure modes. Existing approaches for unposed NeRF operate under limited assumptions, such as a prior pose distribution or coarse pose initialization, making them less effective in a general setting. In this work, we propose a novel approach, LU-NeRF, that jointly estimates camera poses and neural radiance fields with relaxed assumptions on pose configuration. Our approach operates in a local-to-global manner, where we first optimize over local subsets of the data, dubbed mini-scenes. LU-NeRF estimates local pose and geometry for this challenging few-shot task. The mini-scene poses are brought into a global reference frame through a robust pose synchronization step, where a final global optimization of pose and scene can be performed. We show our LU-NeRF pipeline outperforms prior attempts at unposed NeRF without making restrictive assumptions on the pose prior. This allows us to operate in the general SE(3) pose setting, unlike the baselines. Our results also indicate our model can be complementary to feature-based SfM pipelines as it compares favorably to COLMAP on low-texture and low-resolution images.
Accidental Turntables: Learning 3D Pose by Watching Objects Turn
Dec 13, 2022
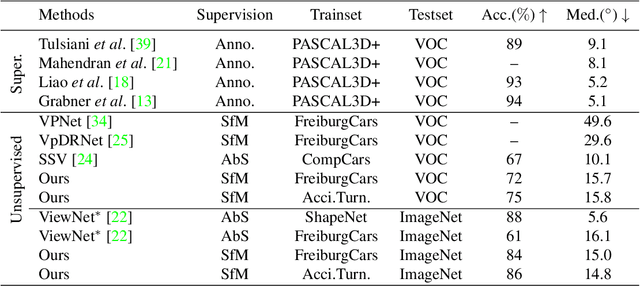

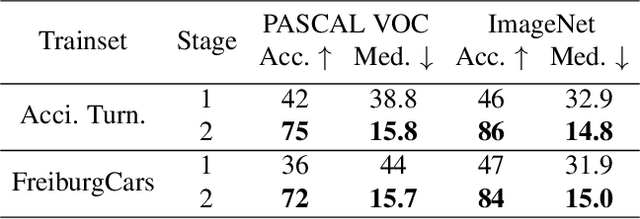
We propose a technique for learning single-view 3D object pose estimation models by utilizing a new source of data -- in-the-wild videos where objects turn. Such videos are prevalent in practice (e.g., cars in roundabouts, airplanes near runways) and easy to collect. We show that classical structure-from-motion algorithms, coupled with the recent advances in instance detection and feature matching, provides surprisingly accurate relative 3D pose estimation on such videos. We propose a multi-stage training scheme that first learns a canonical pose across a collection of videos and then supervises a model for single-view pose estimation. The proposed technique achieves competitive performance with respect to existing state-of-the-art on standard benchmarks for 3D pose estimation, without requiring any pose labels during training. We also contribute an Accidental Turntables Dataset, containing a challenging set of 41,212 images of cars in cluttered backgrounds, motion blur and illumination changes that serves as a benchmark for 3D pose estimation.
Cross-Modal 3D Shape Generation and Manipulation
Jul 24, 2022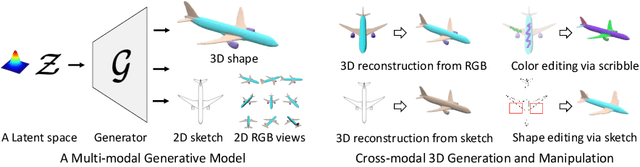

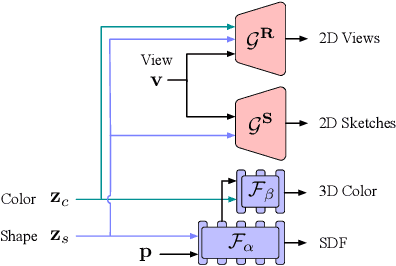
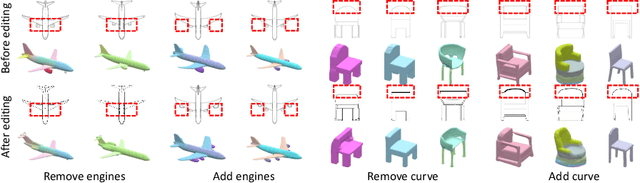
Creating and editing the shape and color of 3D objects require tremendous human effort and expertise. Compared to direct manipulation in 3D interfaces, 2D interactions such as sketches and scribbles are usually much more natural and intuitive for the users. In this paper, we propose a generic multi-modal generative model that couples the 2D modalities and implicit 3D representations through shared latent spaces. With the proposed model, versatile 3D generation and manipulation are enabled by simply propagating the editing from a specific 2D controlling modality through the latent spaces. For example, editing the 3D shape by drawing a sketch, re-colorizing the 3D surface via painting color scribbles on the 2D rendering, or generating 3D shapes of a certain category given one or a few reference images. Unlike prior works, our model does not require re-training or fine-tuning per editing task and is also conceptually simple, easy to implement, robust to input domain shifts, and flexible to diverse reconstruction on partial 2D inputs. We evaluate our framework on two representative 2D modalities of grayscale line sketches and rendered color images, and demonstrate that our method enables various shape manipulation and generation tasks with these 2D modalities.
Improving Few-Shot Part Segmentation using Coarse Supervision
Apr 11, 2022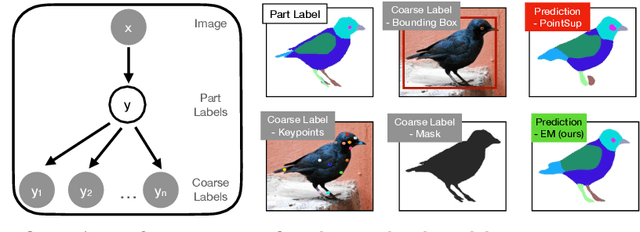

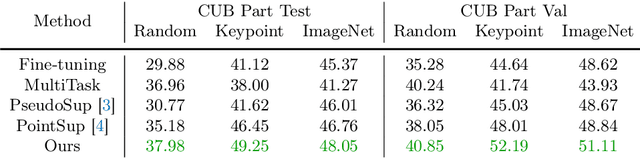

A significant bottleneck in training deep networks for part segmentation is the cost of obtaining detailed annotations. We propose a framework to exploit coarse labels such as figure-ground masks and keypoint locations that are readily available for some categories to improve part segmentation models. A key challenge is that these annotations were collected for different tasks and with different labeling styles and cannot be readily mapped to the part labels. To this end, we propose to jointly learn the dependencies between labeling styles and the part segmentation model, allowing us to utilize supervision from diverse labels. To evaluate our approach we develop a benchmark on the Caltech-UCSD birds and OID Aircraft dataset. Our approach outperforms baselines based on multi-task learning, semi-supervised learning, and competitive methods relying on loss functions manually designed to exploit sparse-supervision.
GANORCON: Are Generative Models Useful for Few-shot Segmentation?
Dec 01, 2021


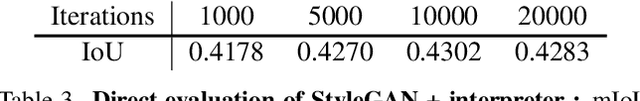
Advances in generative modeling based on GANs has motivated the community to find their use beyond image generation and editing tasks. In particular, several recent works have shown that GAN representations can be re-purposed for discriminative tasks such as part segmentation, especially when training data is limited. But how do these improvements stack-up against recent advances in self-supervised learning? Motivated by this we present an alternative approach based on contrastive learning and compare their performance on standard few-shot part segmentation benchmarks. Our experiments reveal that not only do the GAN-based approach offer no significant performance advantage, their multi-step training is complex, nearly an order-of-magnitude slower, and can introduce additional bias. These experiments suggest that the inductive biases of generative models, such as their ability to disentangle shape and texture, are well captured by standard feed-forward networks trained using contrastive learning. These experiments suggest that the inductive biases present in current generative models, such as their ability to disentangle shape and texture, are well captured by standard feed-forward networks trained using contrastive learning.
A Realistic Evaluation of Semi-Supervised Learning for Fine-Grained Classification
Apr 01, 2021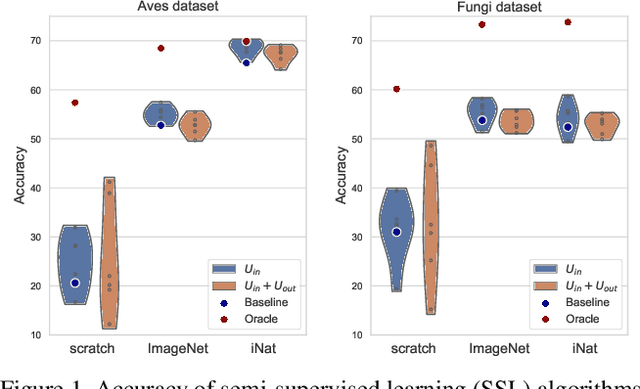
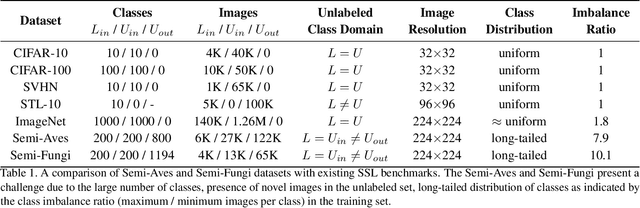
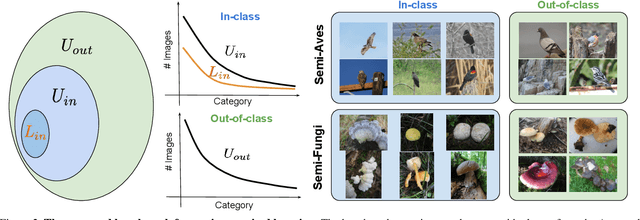
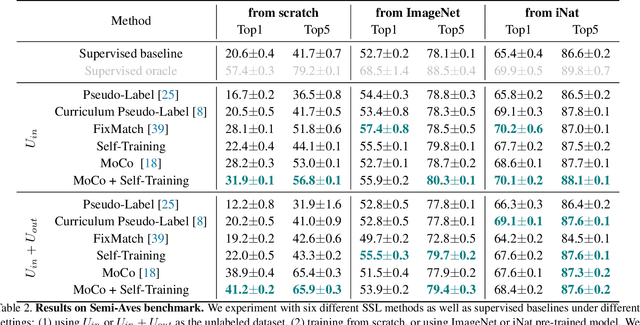
We evaluate the effectiveness of semi-supervised learning (SSL) on a realistic benchmark where data exhibits considerable class imbalance and contains images from novel classes. Our benchmark consists of two fine-grained classification datasets obtained by sampling classes from the Aves and Fungi taxonomy. We find that recently proposed SSL methods provide significant benefits, and can effectively use out-of-class data to improve performance when deep networks are trained from scratch. Yet their performance pales in comparison to a transfer learning baseline, an alternative approach for learning from a few examples. Furthermore, in the transfer setting, while existing SSL methods provide improvements, the presence of out-of-class is often detrimental. In this setting, standard fine-tuning followed by distillation-based self-training is the most robust. Our work suggests that semi-supervised learning with experts on realistic datasets may require different strategies than those currently prevalent in the literature.
Unsupervised Discovery of Object Landmarks via Contrastive Learning
Jun 26, 2020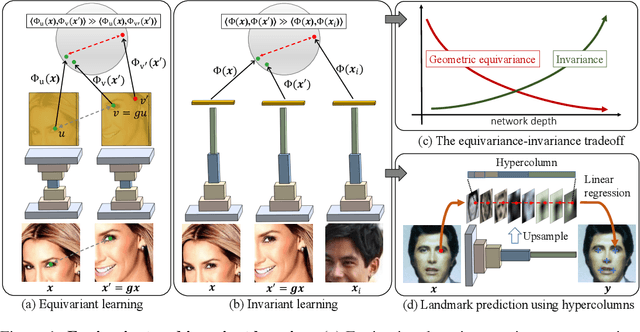
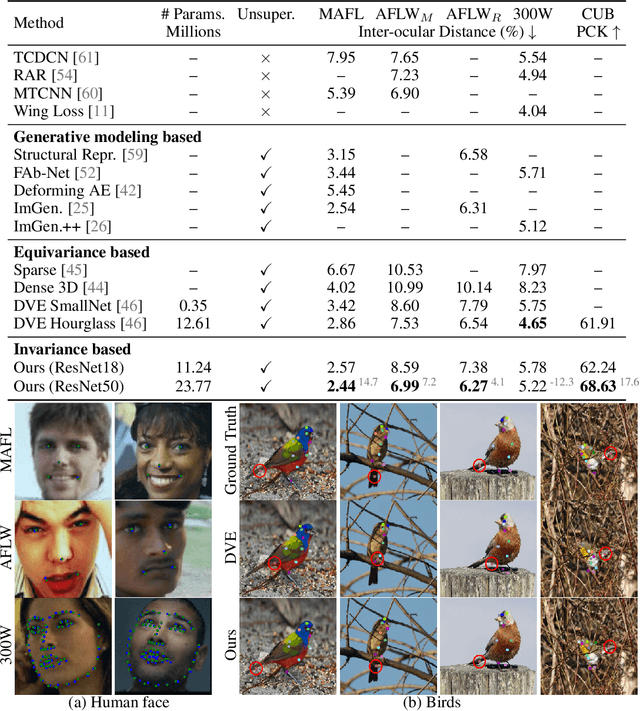
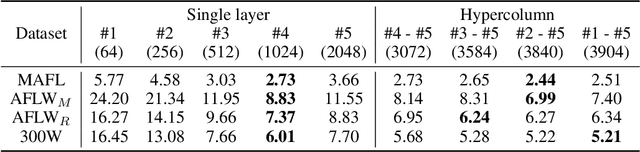
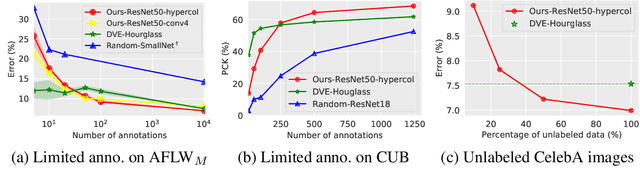
Given a collection of images, humans are able to discover landmarks of the depicted objects by modeling the shared geometric structure across instances. This idea of geometric equivariance has been widely used for unsupervised discovery of object landmark representations. In this paper, we develop a simple and effective approach based on contrastive learning of invariant representations. We show that when a deep network is trained to be invariant to geometric and photometric transformations, representations from its intermediate layers are highly predictive of object landmarks. Furthermore, by stacking representations across layers in a hypercolumn their effectiveness can be improved. Our approach is motivated by the phenomenon of the gradual emergence of invariance in the representation hierarchy of a deep network. We also present a unified view of existing equivariant and invariant representation learning approaches through the lens of contrastive learning, shedding light on the nature of invariances learned. Experiments on standard benchmarks for landmark discovery, as well as a challenging one we propose, show that the proposed approach surpasses prior state-of-the-art.
Detecting and Tracking Communal Bird Roosts in Weather Radar Data
Apr 24, 2020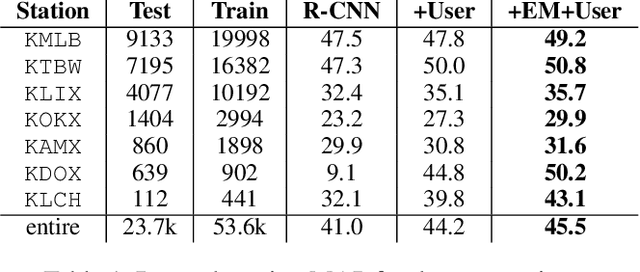



The US weather radar archive holds detailed information about biological phenomena in the atmosphere over the last 20 years. Communally roosting birds congregate in large numbers at nighttime roosting locations, and their morning exodus from the roost is often visible as a distinctive pattern in radar images. This paper describes a machine learning system to detect and track roost signatures in weather radar data. A significant challenge is that labels were collected opportunistically from previous research studies and there are systematic differences in labeling style. We contribute a latent variable model and EM algorithm to learn a detection model together with models of labeling styles for individual annotators. By properly accounting for these variations we learn a significantly more accurate detector. The resulting system detects previously unknown roosting locations and provides comprehensive spatio-temporal data about roosts across the US. This data will provide biologists important information about the poorly understood phenomena of broad-scale habitat use and movements of communally roosting birds during the non-breeding season.
A Bayesian Perspective on the Deep Image Prior
Apr 16, 2019
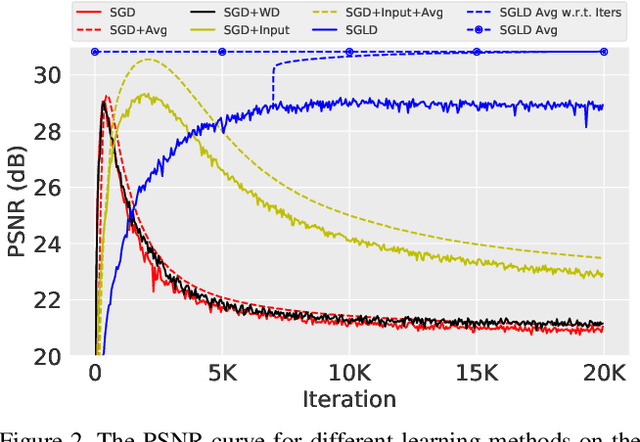

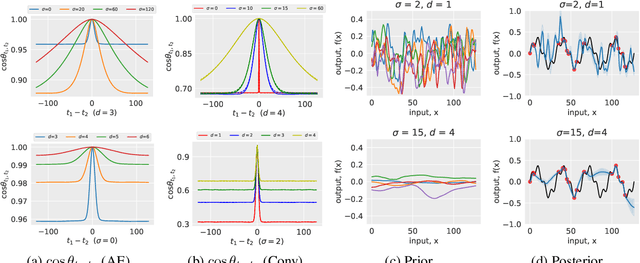
The deep image prior was recently introduced as a prior for natural images. It represents images as the output of a convolutional network with random inputs. For "inference", gradient descent is performed to adjust network parameters to make the output match observations. This approach yields good performance on a range of image reconstruction tasks. We show that the deep image prior is asymptotically equivalent to a stationary Gaussian process prior in the limit as the number of channels in each layer of the network goes to infinity, and derive the corresponding kernel. This informs a Bayesian approach to inference. We show that by conducting posterior inference using stochastic gradient Langevin we avoid the need for early stopping, which is a drawback of the current approach, and improve results for denoising and impainting tasks. We illustrate these intuitions on a number of 1D and 2D signal reconstruction tasks.