 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLuo Mai
MoE-Infinity: Activation-Aware Expert Offloading for Efficient MoE Serving
Jan 25, 2024
This paper presents MoE-Infinity, a cost-efficient mixture-of-expert (MoE) serving system that realizes activation-aware expert offloading. MoE-Infinity features sequence-level expert activation tracing, a new approach adept at identifying sparse activations and capturing the temporal locality of MoE inference. By analyzing these traces, MoE-Infinity performs novel activation-aware expert prefetching and caching, substantially reducing the latency overheads usually associated with offloading experts for improved cost performance. Extensive experiments in a cluster show that MoE-Infinity outperforms numerous existing systems and approaches, reducing latency by 4 - 20X and decreasing deployment costs by over 8X for various MoEs. MoE-Infinity's source code is publicly available at https://github.com/TorchMoE/MoE-Infinity
ServerlessLLM: Locality-Enhanced Serverless Inference for Large Language Models
Jan 25, 2024This paper presents ServerlessLLM, a locality-enhanced serverless inference system for Large Language Models (LLMs). ServerlessLLM exploits the substantial capacity and bandwidth of storage and memory devices available on GPU servers, thereby reducing costly remote checkpoint downloads and achieving efficient checkpoint loading. ServerlessLLM achieves this through three main contributions: (i) fast LLM checkpoint loading via a novel loading-optimized checkpoint format design, coupled with an efficient multi-tier checkpoint loading system; (ii) locality-driven LLM inference with live migration, which allows ServerlessLLM to effectively achieve locality-driven server allocation while preserving the low latency of ongoing LLM inference; and (iii) locality-aware server allocation, enabling ServerlessLLM to evaluate the status of each server in a cluster and effectively schedule model startup time to capitalize on local checkpoint placement. Our comprehensive experiments, which include microbenchmarks and real-world traces, show that ServerlessLLM surpasses state-of-the-art systems by 10 - 200X in latency performance when running various LLM inference workloads.
TENPLEX: Changing Resources of Deep Learning Jobs using Parallelizable Tensor Collections
Dec 08, 2023
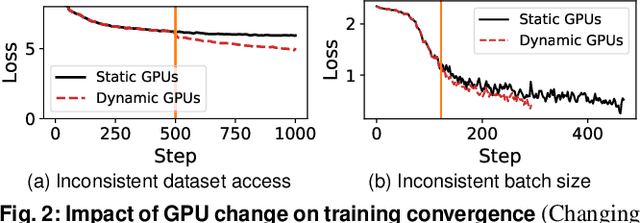
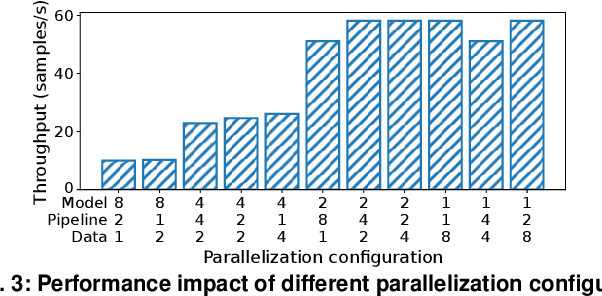
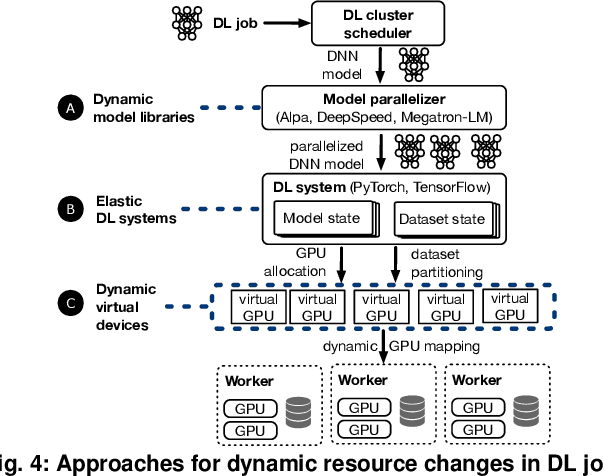
Deep learning (DL) jobs use multi-dimensional parallelism, i.e they combine data, model, and pipeline parallelism, to use large GPU clusters efficiently. This couples jobs tightly to a set of GPU devices, but jobs may experience changes to the device allocation: (i) resource elasticity during training adds or removes devices; (ii) hardware maintenance may require redeployment on different devices; and (iii) device failures force jobs to run with fewer devices. Current DL frameworks lack support for these scenarios, as they cannot change the multi-dimensional parallelism of an already-running job in an efficient and model-independent way. We describe Tenplex, a state management library for DL frameworks that enables jobs to change the GPU allocation and job parallelism at runtime. Tenplex achieves this by externalizing the DL job state during training as a parallelizable tensor collection (PTC). When the GPU allocation for the DL job changes, Tenplex uses the PTC to transform the DL job state: for the dataset state, Tenplex repartitions it under data parallelism and exposes it to workers through a virtual file system; for the model state, Tenplex obtains it as partitioned checkpoints and transforms them to reflect the new parallelization configuration. For efficiency, these PTC transformations are executed in parallel with a minimum amount of data movement between devices and workers. Our experiments show that Tenplex enables DL jobs to support dynamic parallelization with low overhead.
GEAR: A GPU-Centric Experience Replay System for Large Reinforcement Learning Models
Oct 08, 2023



This paper introduces a distributed, GPU-centric experience replay system, GEAR, designed to perform scalable reinforcement learning (RL) with large sequence models (such as transformers). With such models, existing systems such as Reverb face considerable bottlenecks in memory, computation, and communication. GEAR, however, optimizes memory efficiency by enabling the memory resources on GPU servers (including host memory and device memory) to manage trajectory data. Furthermore, it facilitates decentralized GPU devices to expedite various trajectory selection strategies, circumventing computational bottlenecks. GEAR is equipped with GPU kernels capable of collecting trajectories using zero-copy access to host memory, along with remote-directed-memory access over InfiniBand, improving communication efficiency. Cluster experiments have shown that GEAR can achieve performance levels up to 6x greater than Reverb when training state-of-the-art large RL models. GEAR is open-sourced at https://github.com/bigrl-team/gear.
Large Sequence Models for Sequential Decision-Making: A Survey
Jun 24, 2023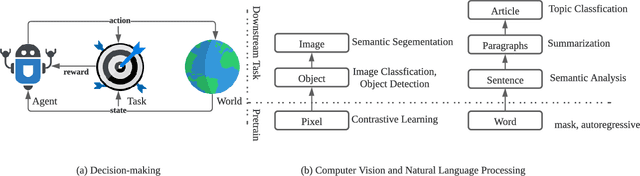
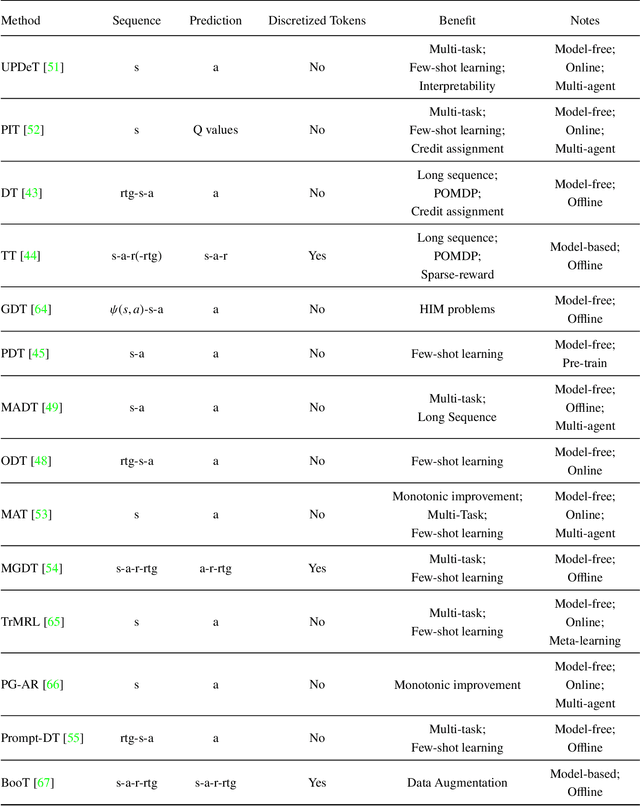
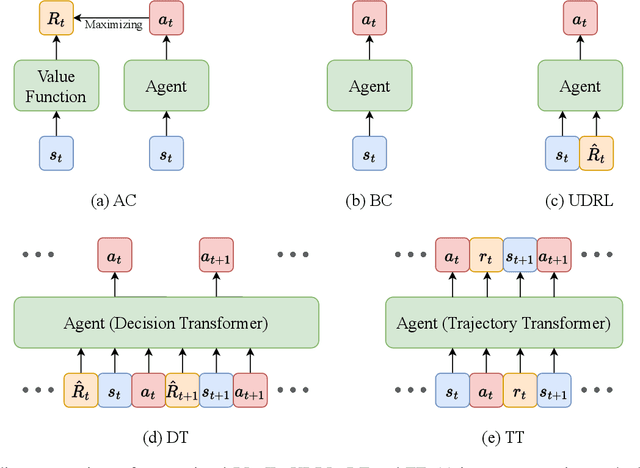
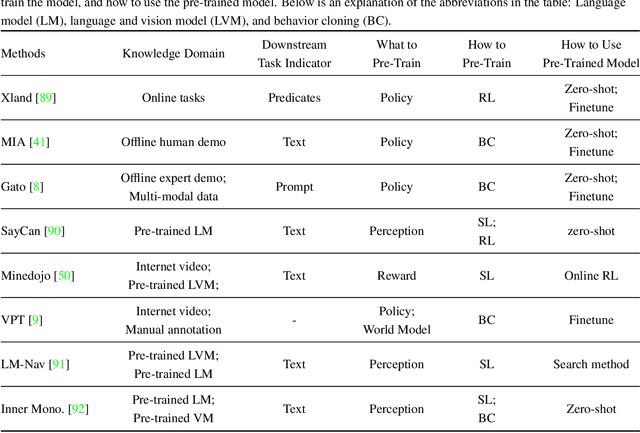
Transformer architectures have facilitated the development of large-scale and general-purpose sequence models for prediction tasks in natural language processing and computer vision, e.g., GPT-3 and Swin Transformer. Although originally designed for prediction problems, it is natural to inquire about their suitability for sequential decision-making and reinforcement learning problems, which are typically beset by long-standing issues involving sample efficiency, credit assignment, and partial observability. In recent years, sequence models, especially the Transformer, have attracted increasing interest in the RL communities, spawning numerous approaches with notable effectiveness and generalizability. This survey presents a comprehensive overview of recent works aimed at solving sequential decision-making tasks with sequence models such as the Transformer, by discussing the connection between sequential decision-making and sequence modeling, and categorizing them based on the way they utilize the Transformer. Moreover, this paper puts forth various potential avenues for future research intending to improve the effectiveness of large sequence models for sequential decision-making, encompassing theoretical foundations, network architectures, algorithms, and efficient training systems. As this article has been accepted by the Frontiers of Computer Science, here is an early version, and the most up-to-date version can be found at https://journal.hep.com.cn/fcs/EN/10.1007/s11704-023-2689-5
Quiver: Supporting GPUs for Low-Latency, High-Throughput GNN Serving with Workload Awareness
May 18, 2023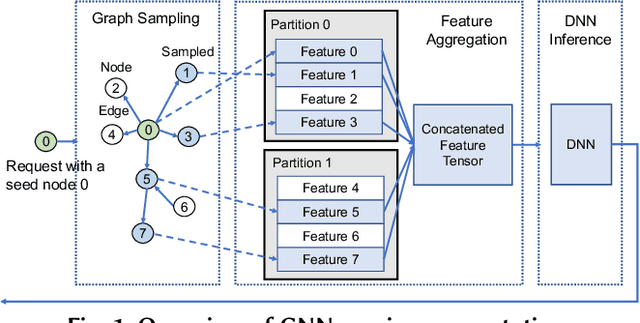
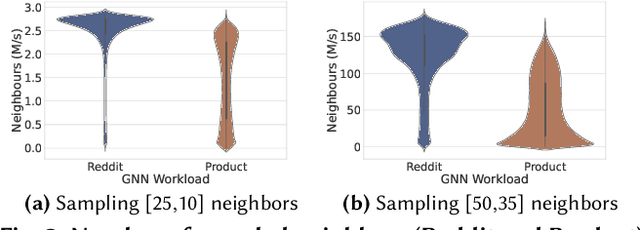
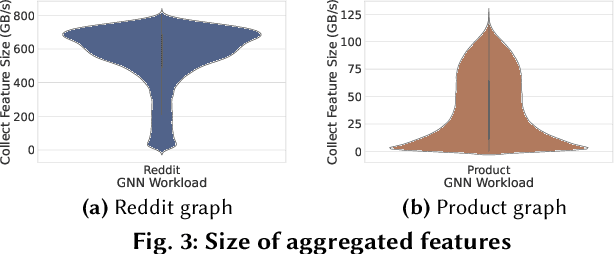
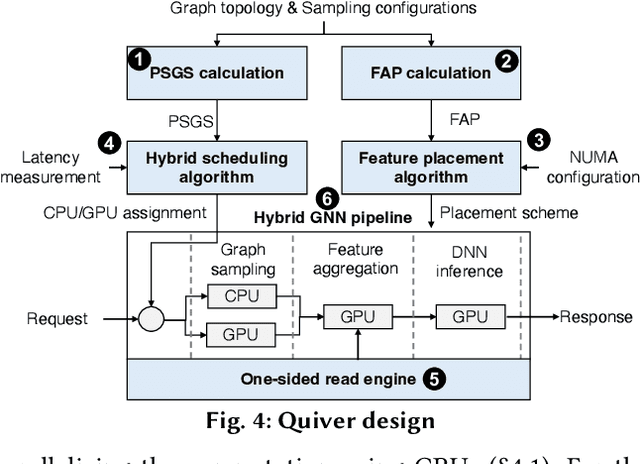
Systems for serving inference requests on graph neural networks (GNN) must combine low latency with high throughout, but they face irregular computation due to skew in the number of sampled graph nodes and aggregated GNN features. This makes it challenging to exploit GPUs effectively: using GPUs to sample only a few graph nodes yields lower performance than CPU-based sampling; and aggregating many features exhibits high data movement costs between GPUs and CPUs. Therefore, current GNN serving systems use CPUs for graph sampling and feature aggregation, limiting throughput. We describe Quiver, a distributed GPU-based GNN serving system with low-latency and high-throughput. Quiver's key idea is to exploit workload metrics for predicting the irregular computation of GNN requests, and governing the use of GPUs for graph sampling and feature aggregation: (1) for graph sampling, Quiver calculates the probabilistic sampled graph size, a metric that predicts the degree of parallelism in graph sampling. Quiver uses this metric to assign sampling tasks to GPUs only when the performance gains surpass CPU-based sampling; and (2) for feature aggregation, Quiver relies on the feature access probability to decide which features to partition and replicate across a distributed GPU NUMA topology. We show that Quiver achieves up to 35 times lower latency with an 8 times higher throughput compared to state-of-the-art GNN approaches (DGL and PyG).
TorchOpt: An Efficient Library for Differentiable Optimization
Nov 13, 2022


Recent years have witnessed the booming of various differentiable optimization algorithms. These algorithms exhibit different execution patterns, and their execution needs massive computational resources that go beyond a single CPU and GPU. Existing differentiable optimization libraries, however, cannot support efficient algorithm development and multi-CPU/GPU execution, making the development of differentiable optimization algorithms often cumbersome and expensive. This paper introduces TorchOpt, a PyTorch-based efficient library for differentiable optimization. TorchOpt provides a unified and expressive differentiable optimization programming abstraction. This abstraction allows users to efficiently declare and analyze various differentiable optimization programs with explicit gradients, implicit gradients, and zero-order gradients. TorchOpt further provides a high-performance distributed execution runtime. This runtime can fully parallelize computation-intensive differentiation operations (e.g. tensor tree flattening) on CPUs / GPUs and automatically distribute computation to distributed devices. Experimental results show that TorchOpt achieves $5.2\times$ training time speedup on an 8-GPU server. TorchOpt is available at: https://github.com/metaopt/torchopt/.
MegBA: A High-Performance and Distributed Library for Large-Scale Bundle Adjustment
Dec 10, 2021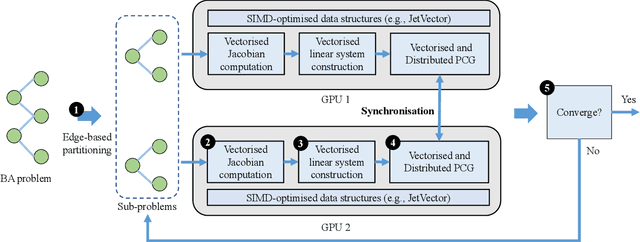
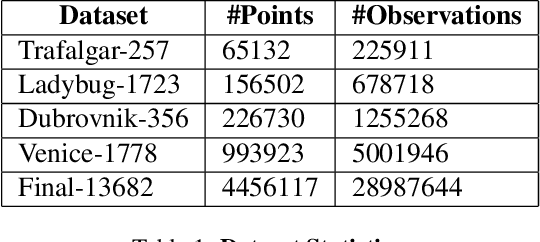
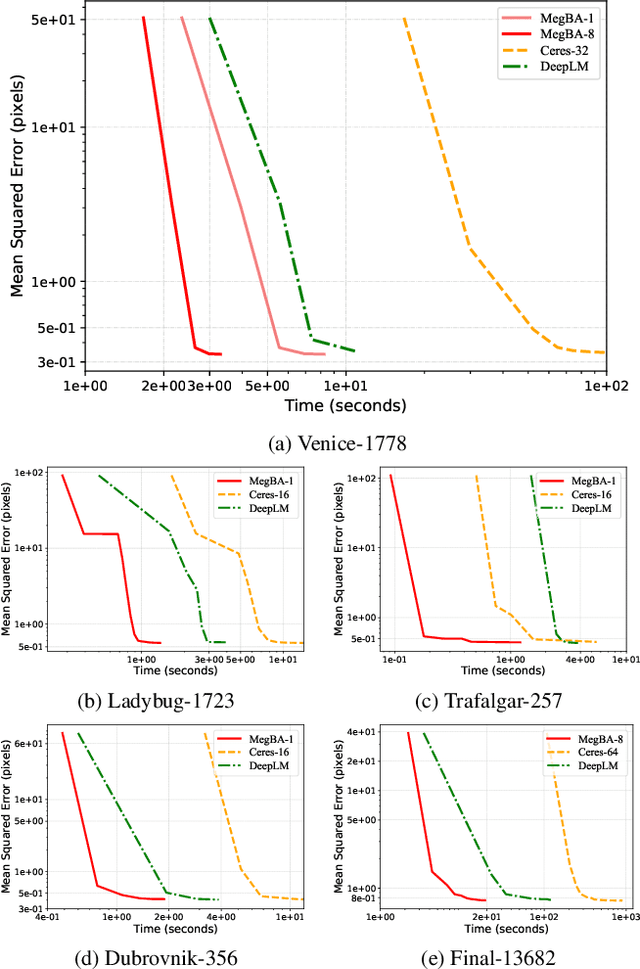
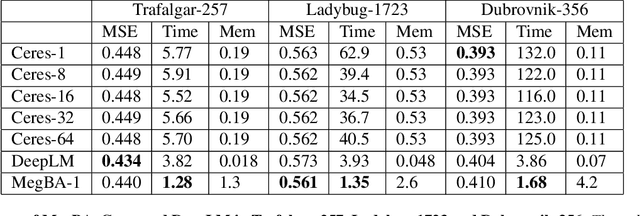
Large-scale Bundle Adjustment (BA) is the key for many 3D vision applications (e.g., Structure-from-Motion and SLAM). Though important, large-scale BA is still poorly supported by existing BA libraries (e.g., Ceres and g2o). These libraries under-utilise accelerators (i.e., GPUs), and they lack algorithms to distribute BA computation constrained by the memory on a single device. In this paper, we propose MegBA, a high-performance and distributed library for large-scale BA. MegBA has a novel end-to-end vectorised BA algorithm that can fully exploit the massive parallel cores on GPUs, thus speeding up the entire BA computation. It also has a novel distributed BA algorithm that can automatically partition BA problems, and solve BA sub-problems using distributed GPUs. The GPUs synchronise intermediate solving state using network-efficient collective communication, and the synchronisation is designed to minimise communication cost. MegBA has a memory-efficient GPU runtime and exposes g2o-compatible APIs. Experiments show that MegBA can out-perform state-of-the-art BA libraries (i.e., Ceres and DeepLM) by up to 47.6x and 6.4x respectively, in public large-scale BA benchmarks. The code of MegBA is available at: https://github.com/MegviiRobot/MegBA.
Fast and Flexible Human Pose Estimation with HyperPose
Aug 26, 2021



Estimating human pose is an important yet challenging task in multimedia applications. Existing pose estimation libraries target reproducing standard pose estimation algorithms. When it comes to customising these algorithms for real-world applications, none of the existing libraries can offer both the flexibility of developing custom pose estimation algorithms and the high-performance of executing these algorithms on commodity devices. In this paper, we introduce Hyperpose, a novel flexible and high-performance pose estimation library. Hyperpose provides expressive Python APIs that enable developers to easily customise pose estimation algorithms for their applications. It further provides a model inference engine highly optimised for real-time pose estimation. This engine can dynamically dispatch carefully designed pose estimation tasks to CPUs and GPUs, thus automatically achieving high utilisation of hardware resources irrespective of deployment environments. Extensive evaluation results show that Hyperpose can achieve up to 3.1x~7.3x higher pose estimation throughput compared to state-of-the-art pose estimation libraries without compromising estimation accuracy. By 2021, Hyperpose has received over 1000 stars on GitHub and attracted users from both industry and academy.
RLzoo: A Comprehensive and Adaptive Reinforcement Learning Library
Sep 18, 2020



Recently, we have seen a rapidly growing adoption of Deep Reinforcement Learning (DRL) technologies. Fully achieving the promise of these technologies in practice is, however, extremely difficult. Users have to invest tremendous efforts in building DRL agents, incorporating the agents into various external training environments, and tuning agent implementation/hyper-parameters so that they can reproduce state-of-the-art (SOTA) performance. In this paper, we propose RLzoo, a new DRL library that aims to make it easy to develop and reproduce DRL algorithms. RLzoo has both high-level APIs and low-level APIs, useful for constructing and customising DRL agents, respectively. It has an adaptive agent construction algorithm that can automatically integrate custom RLzoo agents into various external training environments. To help reproduce the results of SOTA algorithms, RLzoo provides rich reference DRL algorithm implementations and effective hyper-parameter settings. Extensive evaluation results show that RLzoo not only outperforms existing DRL libraries in its simplicity of API design; but also provides the largest number of reference DRL algorithm implementations.