 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePinzhen Chen
Fine-Tuning Large Language Models to Translate: Will a Touch of Noisy Data in Misaligned Languages Suffice?
Apr 22, 2024
Traditionally, success in multilingual machine translation can be attributed to three key factors in training data: large volume, diverse translation directions, and high quality. In the current practice of fine-tuning large language models (LLMs) for translation, we revisit the importance of all these factors. We find that LLMs display strong translation capability after being fine-tuned on as few as 32 training instances, and that fine-tuning on a single translation direction effectively enables LLMs to translate in multiple directions. However, the choice of direction is critical: fine-tuning LLMs with English on the target side can lead to task misinterpretation, which hinders translations into non-English languages. A similar problem arises when noise is introduced into the target side of parallel data, especially when the target language is well-represented in the LLM's pre-training. In contrast, noise in an under-represented language has a less pronounced effect. Our findings suggest that attaining successful alignment hinges on teaching the model to maintain a "superficial" focus, thereby avoiding the learning of erroneous biases beyond translation.
Lucky 52: How Many Languages Are Needed to Instruction Fine-Tune Large Language Models?
Apr 07, 2024Fine-tuning large language models for multilingual downstream tasks requires a diverse set of languages to capture the nuances and structures of different linguistic contexts effectively. While the specific number varies depending on the desired scope and target languages, we argue that the number of languages, language exposure, and similarity that incorporate the selection of languages for fine-tuning are some important aspects to examine. By fine-tuning large multilingual models on 1 to 52 languages, this paper answers one question: How many languages are needed in instruction fine-tuning for multilingual tasks? We investigate how multilingual instruction fine-tuned models behave on multilingual benchmarks with an increasing number of languages and discuss our findings from the perspective of language exposure and similarity.
UniArk: Improving Generalisation and Consistency for Factual Knowledge Extraction through Debiasing
Apr 01, 2024Several recent papers have investigated the potential of language models as knowledge bases as well as the existence of severe biases when extracting factual knowledge. In this work, we focus on the factual probing performance over unseen prompts from tuning, and using a probabilistic view we show the inherent misalignment between pre-training and downstream tuning objectives in language models for probing knowledge. We hypothesize that simultaneously debiasing these objectives can be the key to generalisation over unseen prompts. We propose an adapter-based framework, UniArk, for generalised and consistent factual knowledge extraction through simple methods without introducing extra parameters. Extensive experiments show that UniArk can significantly improve the model's out-of-domain generalisation as well as consistency under various prompts. Additionally, we construct ParaTrex, a large-scale and diverse dataset for measuring the inconsistency and out-of-domain generation of models. Further, ParaTrex offers a reference method for constructing paraphrased datasets using large language models.
Fine-tuning Large Language Models with Sequential Instructions
Mar 12, 2024



Large language models (LLMs) struggle to follow a sequence of instructions in a single query as they may ignore or misinterpret part of it. This impairs their performance in complex problems whose solution requires multiple intermediate steps, such as multilingual (translate then answer) and multimodal (caption then answer) tasks. We empirically verify this with open-source LLMs as large as LLaMA-2 70B and Mixtral-8x7B. Targeting the scarcity of sequential instructions in present-day data, we propose sequential instruction tuning, a simple yet effective strategy to automatically augment instruction tuning data and equip LLMs with the ability to execute multiple sequential instructions. After exploring interleaving instructions in existing datasets, such as Alpaca, with a wide range of intermediate tasks, we find that sequential instruction-tuned models consistently outperform the conventional instruction-tuned baselines in downstream tasks involving reasoning, multilingual, and multimodal abilities. To shed further light on our technique, we analyse how adversarial intermediate texts, unseen tasks, prompt verbalization, number of tasks, and prompt length affect SIT. We hope that this method will open new research avenues on instruction tuning for complex tasks.
EEE-QA: Exploring Effective and Efficient Question-Answer Representations
Mar 04, 2024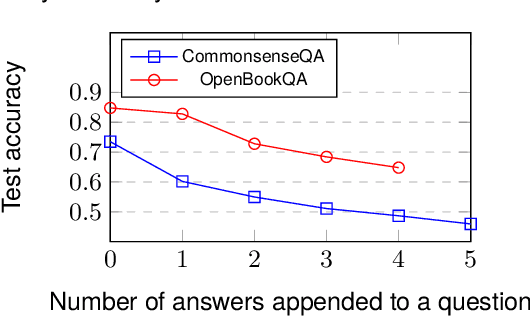

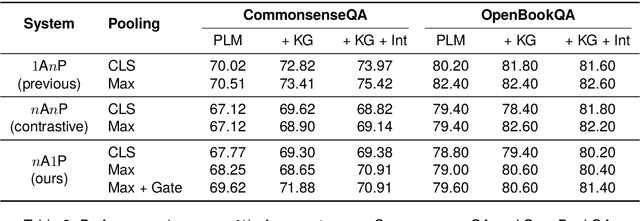

Current approaches to question answering rely on pre-trained language models (PLMs) like RoBERTa. This work challenges the existing question-answer encoding convention and explores finer representations. We begin with testing various pooling methods compared to using the begin-of-sentence token as a question representation for better quality. Next, we explore opportunities to simultaneously embed all answer candidates with the question. This enables cross-reference between answer choices and improves inference throughput via reduced memory usage. Despite their simplicity and effectiveness, these methods have yet to be widely studied in current frameworks. We experiment with different PLMs, and with and without the integration of knowledge graphs. Results prove that the memory efficacy of the proposed techniques with little sacrifice in performance. Practically, our work enhances 38-100% throughput with 26-65% speedups on consumer-grade GPUs by allowing for considerably larger batch sizes. Our work sends a message to the community with promising directions in both representation quality and efficiency for the question-answering task in natural language processing.
Large Language Model Inference with Lexical Shortlisting
Nov 16, 2023Large language model (LLM) inference is computation and memory intensive, so we adapt lexical shortlisting to it hoping to improve both. While lexical shortlisting is well-explored in tasks like machine translation, it requires modifications before being suitable for LLMs as the intended applications vary significantly. Our work studies two heuristics to shortlist sub-vocabulary at LLM inference time: Unicode-based script filtering and corpus-based selection. We explore different LLM families and sizes, and we find that lexical shortlisting can reduce the memory usage of some models by nearly 50\% and has an upper bound of 25\% improvement in generation speed. In this pilot study, we also identify the drawbacks of such vocabulary selection methods and propose avenues for future research.
Terminology-Aware Translation with Constrained Decoding and Large Language Model Prompting
Oct 09, 2023



Terminology correctness is important in the downstream application of machine translation, and a prevalent way to ensure this is to inject terminology constraints into a translation system. In our submission to the WMT 2023 terminology translation task, we adopt a translate-then-refine approach which can be domain-independent and requires minimal manual efforts. We annotate random source words with pseudo-terminology translations obtained from word alignment to first train a terminology-aware model. Further, we explore two post-processing methods. First, we use an alignment process to discover whether a terminology constraint has been violated, and if so, we re-decode with the violating word negatively constrained. Alternatively, we leverage a large language model to refine a hypothesis by providing it with terminology constraints. Results show that our terminology-aware model learns to incorporate terminologies effectively, and the large language model refinement process can further improve terminology recall.
Towards Effective Disambiguation for Machine Translation with Large Language Models
Sep 20, 2023



Resolving semantic ambiguity has long been recognised as a central challenge in the field of machine translation. Recent work on benchmarking translation performance on ambiguous sentences has exposed the limitations of conventional Neural Machine Translation (NMT) systems, which fail to capture many of these cases. Large language models (LLMs) have emerged as a promising alternative, demonstrating comparable performance to traditional NMT models while introducing new paradigms for controlling the target outputs. In this paper, we study the capabilities of LLMs to translate ambiguous sentences containing polysemous words and rare word senses. We also propose two ways to improve the handling of such ambiguity through in-context learning and fine-tuning on carefully curated ambiguous datasets. Experiments show that our methods can match or outperform state-of-the-art systems such as DeepL and NLLB in four out of five language directions. Our research provides valuable insights into effectively adapting LLMs for disambiguation during machine translation.
Monolingual or Multilingual Instruction Tuning: Which Makes a Better Alpaca
Sep 16, 2023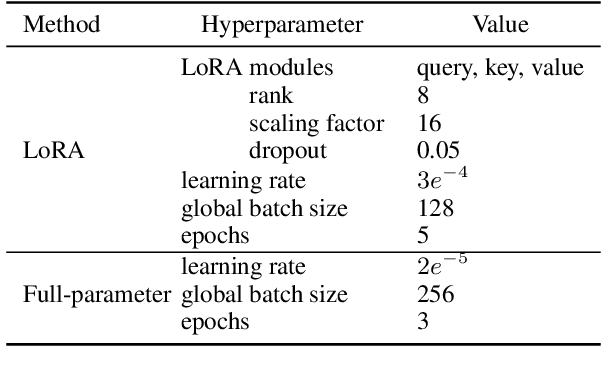

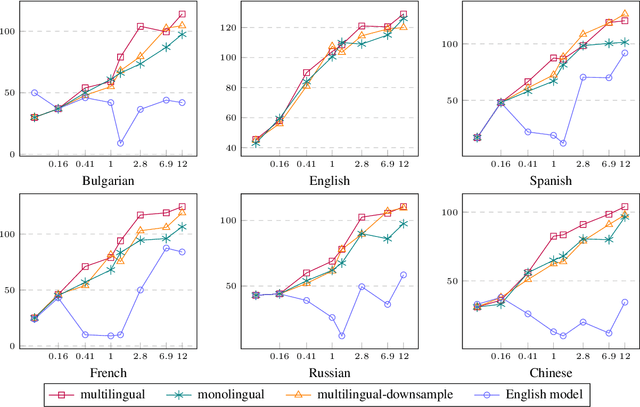

Foundational large language models (LLMs) can be instruction-tuned to develop open-ended question-answering capability, facilitating applications such as the creation of AI assistants. While such efforts are often carried out in a single language, building on prior research, we empirically analyze cost-efficient approaches of monolingual and multilingual tuning, shedding light on the efficacy of LLMs in responding to queries across monolingual and multilingual contexts. Our study employs the Alpaca dataset and machine translations of it to form multilingual training data, which is then used to tune LLMs through low-rank adaptation and full-parameter training. Comparisons reveal that multilingual tuning is not crucial for an LLM's English performance, but is key to its robustness in a multilingual environment. With a fixed budget, a multilingual instruction-tuned model, merely trained on downsampled data, can be as powerful as training monolingual models for each language. Our findings serve as a guide for expanding language support through instruction tuning with constrained computational resources.
Iterative Translation Refinement with Large Language Models
Jun 06, 2023Large language models have shown surprising performances in understanding instructions and performing natural language tasks. In this paper, we propose iterative translation refinement to leverage the power of large language models for more natural translation and post-editing. We show that by simply involving a large language model in an iterative process, the output quality improves beyond mere translation. Extensive test scenarios with GPT-3.5 reveal that although iterations reduce string-based metric scores, neural metrics indicate comparable if not improved translation quality. Further, human evaluations demonstrate that our method effectively reduces translationese compared to initial GPT translations and even human references, especially for into-English directions. Ablation studies underscore the importance of anchoring the refinement process to the source input and a reasonable initial translation.