 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYang Deng
Towards Human-centered Proactive Conversational Agents
Apr 19, 2024
Recent research on proactive conversational agents (PCAs) mainly focuses on improving the system's capabilities in anticipating and planning action sequences to accomplish tasks and achieve goals before users articulate their requests. This perspectives paper highlights the importance of moving towards building human-centered PCAs that emphasize human needs and expectations, and that considers ethical and social implications of these agents, rather than solely focusing on technological capabilities. The distinction between a proactive and a reactive system lies in the proactive system's initiative-taking nature. Without thoughtful design, proactive systems risk being perceived as intrusive by human users. We address the issue by establishing a new taxonomy concerning three key dimensions of human-centered PCAs, namely Intelligence, Adaptivity, and Civility. We discuss potential research opportunities and challenges based on this new taxonomy upon the five stages of PCA system construction. This perspectives paper lays a foundation for the emerging area of conversational information retrieval research and paves the way towards advancing human-centered proactive conversational systems.
Concept -- An Evaluation Protocol on Conversation Recommender Systems with System-centric and User-centric Factors
Apr 06, 2024The conversational recommendation system (CRS) has been criticized regarding its user experience in real-world scenarios, despite recent significant progress achieved in academia. Existing evaluation protocols for CRS may prioritize system-centric factors such as effectiveness and fluency in conversation while neglecting user-centric aspects. Thus, we propose a new and inclusive evaluation protocol, Concept, which integrates both system- and user-centric factors. We conceptualise three key characteristics in representing such factors and further divide them into six primary abilities. To implement Concept, we adopt a LLM-based user simulator and evaluator with scoring rubrics that are tailored for each primary ability. Our protocol, Concept, serves a dual purpose. First, it provides an overview of the pros and cons in current CRS models. Second, it pinpoints the problem of low usability in the "omnipotent" ChatGPT and offers a comprehensive reference guide for evaluating CRS, thereby setting the foundation for CRS improvement.
Strength Lies in Differences! Towards Effective Non-collaborative Dialogues via Tailored Strategy Planning
Mar 11, 2024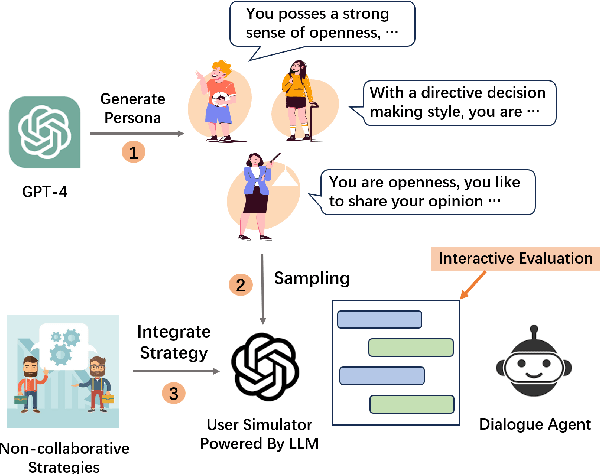
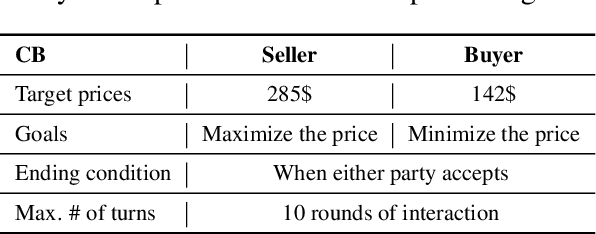

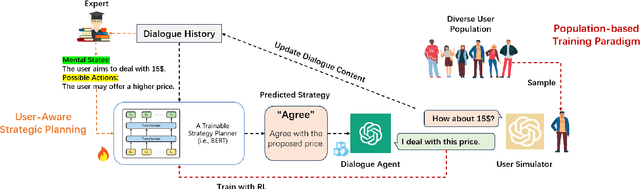
We investigate non-collaborative dialogue agents that must engage in tailored strategic planning for diverse users to secure a favorable agreement. This poses challenges for existing dialogue agents due to two main reasons: their inability to integrate user-specific characteristics into their strategic planning and their training paradigm's failure to produce strategic planners that can generalize to diverse users. To address these challenges, we propose TRIP to enhance the capability in tailored strategic planning, incorporating a user-aware strategic planning module and a population-based training paradigm. Through experiments on benchmark non-collaborative dialogue tasks, we demonstrate the effectiveness of TRIP in catering to diverse users.
Consecutive Model Editing with Batch alongside HooK Layers
Mar 08, 2024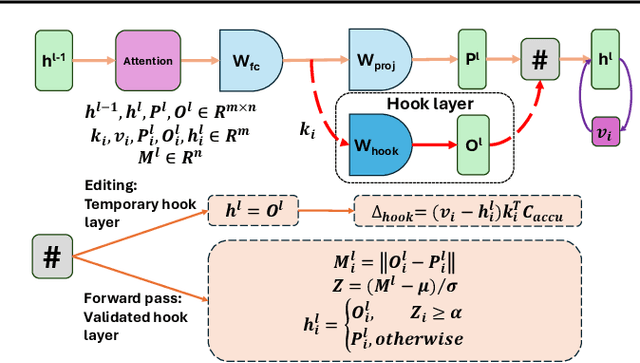
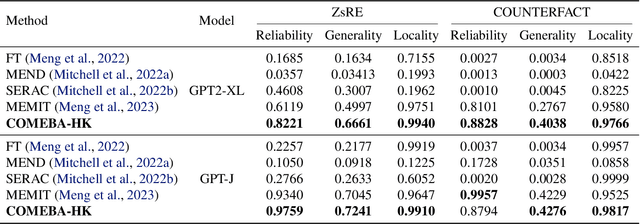
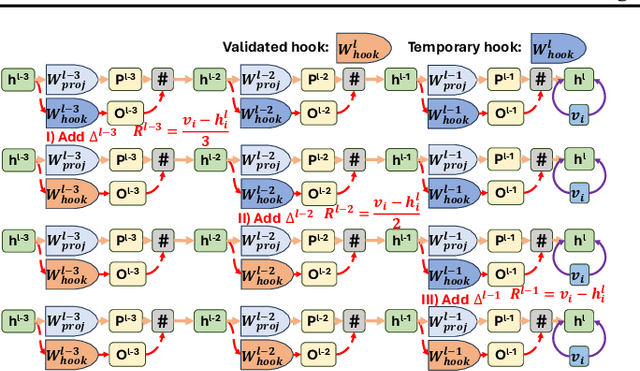
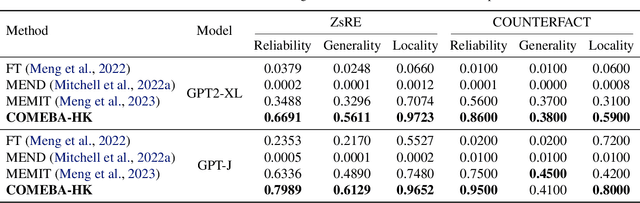
As the typical retraining paradigm is unacceptably time- and resource-consuming, researchers are turning to model editing in order to seek an effective, consecutive, and batch-supportive way to edit the model behavior directly. Despite all these practical expectations, existing model editing methods fail to realize all of them. Furthermore, the memory demands for such succession-supportive model editing approaches tend to be prohibitive, frequently necessitating an external memory that grows incrementally over time. To cope with these challenges, we propose COMEBA-HK, a model editing method that is both consecutive and batch-supportive. COMEBA-HK is memory-friendly as it only needs a small amount of it to store several hook layers with updated weights. Experimental results demonstrate the superiority of our method over other batch-supportive model editing methods under both single-round and consecutive batch editing scenarios. Extensive analyses of COMEBA-HK have been conducted to verify the stability of our method over 1) the number of consecutive steps and 2) the number of editing instance.
Gotcha! Don't trick me with unanswerable questions! Self-aligning Large Language Models for Responding to Unknown Questions
Feb 23, 2024Despite the remarkable abilities of Large Language Models (LLMs) to answer questions, they often display a considerable level of overconfidence even when the question does not have a definitive answer. To avoid providing hallucinated answers to these unknown questions, existing studies typically investigate approaches to refusing to answer these questions. In this work, we propose a novel and scalable self-alignment method to utilize the LLM itself to enhance its response-ability to different types of unknown questions, being capable of not only refusing to answer but also providing explanation to the unanswerability of unknown questions. Specifically, the Self-Align method first employ a two-stage class-aware self-augmentation approach to generate a large amount of unknown question-response data. Then we conduct disparity-driven self-curation to select qualified data for fine-tuning the LLM itself for aligning the responses to unknown questions as desired. Experimental results on two datasets across four types of unknown questions validate the superiority of the Self-Align method over existing baselines in terms of three types of task formulation.
On the Multi-turn Instruction Following for Conversational Web Agents
Feb 23, 2024Web agents powered by Large Language Models (LLMs) have demonstrated remarkable abilities in planning and executing multi-step interactions within complex web-based environments, fulfilling a wide range of web navigation tasks. Despite these advancements, the potential for LLM-powered agents to effectively engage with sequential user instructions in real-world scenarios has not been fully explored. In this work, we introduce a new task of Conversational Web Navigation, which necessitates sophisticated interactions that span multiple turns with both the users and the environment, supported by a specially developed dataset named Multi-Turn Mind2Web (MT-Mind2Web). To tackle the limited context length of LLMs and the context-dependency issue of the conversational tasks, we further propose a novel framework, named self-reflective memory-augmented planning (Self-MAP), which employs memory utilization and self-reflection techniques. Extensive experiments are conducted to benchmark the MT-Mind2Web dataset, and validate the effectiveness of the proposed method.
UniMS-RAG: A Unified Multi-source Retrieval-Augmented Generation for Personalized Dialogue Systems
Jan 24, 2024Large Language Models (LLMs) has shown exceptional capabilities in many natual language understanding and generation tasks. However, the personalization issue still remains a much-coveted property, especially when it comes to the multiple sources involved in the dialogue system. To better plan and incorporate the use of multiple sources in generating personalized response, we firstly decompose it into three sub-tasks: Knowledge Source Selection, Knowledge Retrieval, and Response Generation. We then propose a novel Unified Multi-Source Retrieval-Augmented Generation system (UniMS-RAG) Specifically, we unify these three sub-tasks with different formulations into the same sequence-to-sequence paradigm during the training, to adaptively retrieve evidences and evaluate the relevance on-demand using special tokens, called acting tokens and evaluation tokens. Enabling language models to generate acting tokens facilitates interaction with various knowledge sources, allowing them to adapt their behavior to diverse task requirements. Meanwhile, evaluation tokens gauge the relevance score between the dialogue context and the retrieved evidence. In addition, we carefully design a self-refinement mechanism to iteratively refine the generated response considering 1) the consistency scores between the generated response and retrieved evidence; and 2) the relevance scores. Experiments on two personalized datasets (DuLeMon and KBP) show that UniMS-RAG achieves state-of-the-art performance on the knowledge source selection and response generation task with itself as a retriever in a unified manner. Extensive analyses and discussions are provided for shedding some new perspectives for personalized dialogue systems.
X-Mark: Towards Lossless Watermarking Through Lexical Redundancy
Nov 16, 2023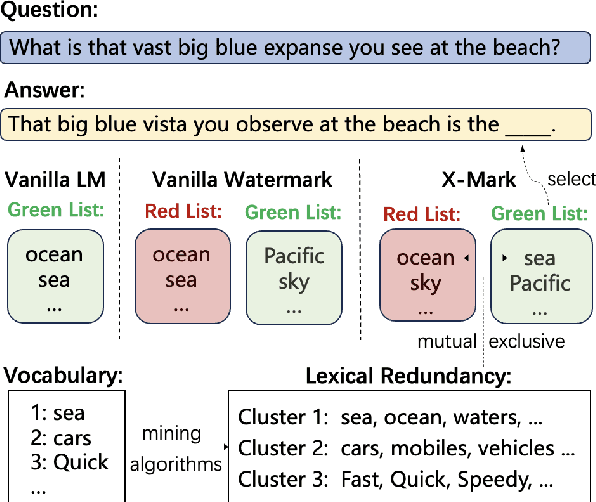
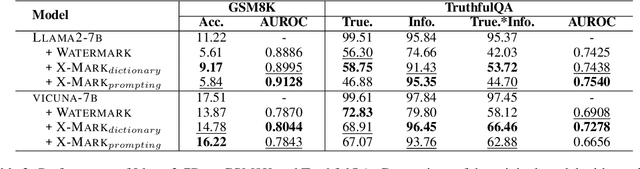
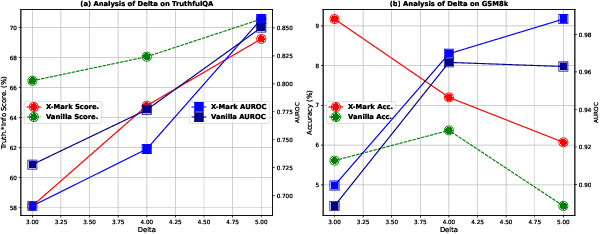
Text watermarking has emerged as an important technique for detecting machine-generated text. However, existing methods can severely degrade text quality due to arbitrary vocabulary partitioning, which disrupts the language model's expressiveness and impedes textual coherence. To mitigate this, we introduce XMark, a novel approach that capitalizes on text redundancy within the lexical space. Specifically, XMark incorporates a mutually exclusive rule for synonyms during the language model decoding process, thereby integrating prior knowledge into vocabulary partitioning and preserving the capabilities of language generation. We present theoretical analyses and empirical evidence demonstrating that XMark substantially enhances text generation fluency while maintaining watermark detectability. Furthermore, we investigate watermarking's impact on the emergent abilities of large language models, including zero-shot and few-shot knowledge recall, logical reasoning, and instruction following. Our comprehensive experiments confirm that XMark consistently outperforms existing methods in retaining these crucial capabilities of LLMs.
Plug-and-Play Policy Planner for Large Language Model Powered Dialogue Agents
Nov 01, 2023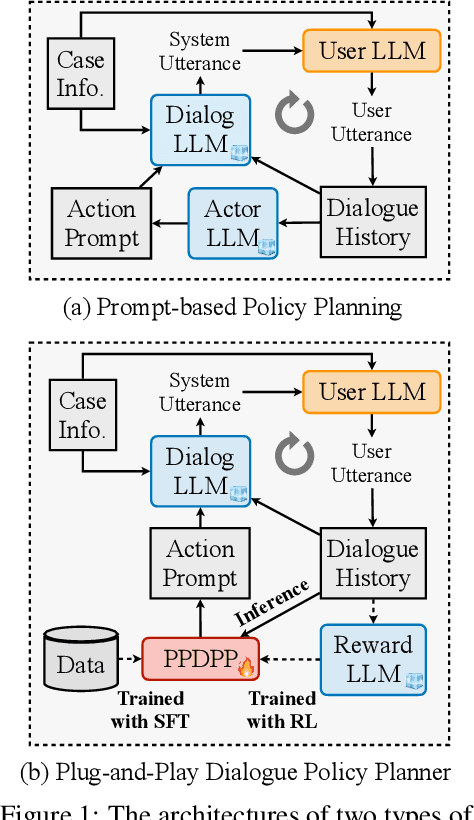
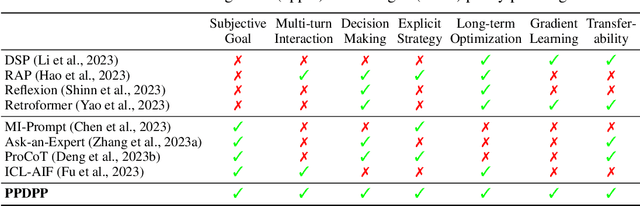
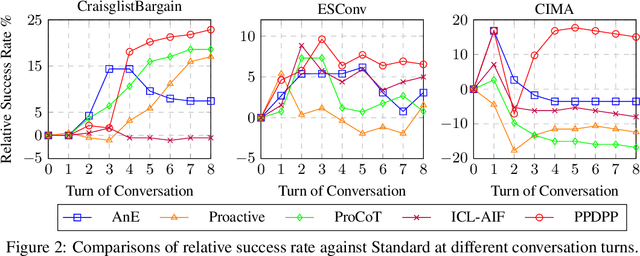
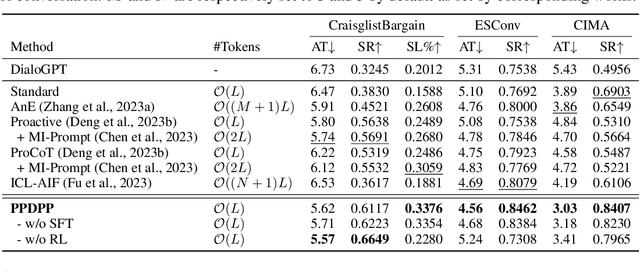
Proactive dialogues serve as a practical yet challenging dialogue problem in the era of large language models (LLMs), where the dialogue policy planning is the key to improving the proactivity of LLMs. Most existing studies enable the dialogue policy planning of LLMs using various prompting schemes or iteratively enhance this capability in handling the given case with verbal AI feedback. However, these approaches are either bounded by the policy planning capability of the frozen LLMs or hard to be transferred to new cases. In this work, we introduce a new dialogue policy planning paradigm to strategize LLMs for proactive dialogue problems with a tunable language model plug-in as a plug-and-play dialogue policy planner, named PPDPP. Specifically, we develop a novel training framework to facilitate supervised fine-tuning over available human-annotated data as well as reinforcement learning from goal-oriented AI feedback with dynamic interaction data collected by the LLM-based self-play simulation. In this manner, the LLM-powered dialogue agent can not only be generalized to different cases after the training, but also be applicable to different applications by just substituting the learned plug-in. In addition, we propose to evaluate the policy planning capability of dialogue systems under the interactive setting. Experimental results demonstrate that PPDPP consistently and substantially outperforms existing approaches on three different proactive dialogue applications, including negotiation, emotional support, and tutoring dialogues.
DepWiGNN: A Depth-wise Graph Neural Network for Multi-hop Spatial Reasoning in Text
Oct 19, 2023Spatial reasoning in text plays a crucial role in various real-world applications. Existing approaches for spatial reasoning typically infer spatial relations from pure text, which overlook the gap between natural language and symbolic structures. Graph neural networks (GNNs) have showcased exceptional proficiency in inducing and aggregating symbolic structures. However, classical GNNs face challenges in handling multi-hop spatial reasoning due to the over-smoothing issue, \textit{i.e.}, the performance decreases substantially as the number of graph layers increases. To cope with these challenges, we propose a novel \textbf{Dep}th-\textbf{Wi}se \textbf{G}raph \textbf{N}eural \textbf{N}etwork (\textbf{DepWiGNN}). Specifically, we design a novel node memory scheme and aggregate the information over the depth dimension instead of the breadth dimension of the graph, which empowers the ability to collect long dependencies without stacking multiple layers. Experimental results on two challenging multi-hop spatial reasoning datasets show that DepWiGNN outperforms existing spatial reasoning methods. The comparisons with the other three GNNs further demonstrate its superiority in capturing long dependency in the graph.