 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJunqi Tang
Unsupervised Training of Convex Regularizers using Maximum Likelihood Estimation
Apr 08, 2024
Unsupervised learning is a training approach in the situation where ground truth data is unavailable, such as inverse imaging problems. We present an unsupervised Bayesian training approach to learning convex neural network regularizers using a fixed noisy dataset, based on a dual Markov chain estimation method. Compared to classical supervised adversarial regularization methods, where there is access to both clean images as well as unlimited to noisy copies, we demonstrate close performance on natural image Gaussian deconvolution and Poisson denoising tasks.
Unsupervised approaches based on optimal transport and convex analysis for inverse problems in imaging
Nov 29, 2023Unsupervised deep learning approaches have recently become one of the crucial research areas in imaging owing to their ability to learn expressive and powerful reconstruction operators even when paired high-quality training data is scarcely available. In this chapter, we review theoretically principled unsupervised learning schemes for solving imaging inverse problems, with a particular focus on methods rooted in optimal transport and convex analysis. We begin by reviewing the optimal transport-based unsupervised approaches such as the cycle-consistency-based models and learned adversarial regularization methods, which have clear probabilistic interpretations. Subsequently, we give an overview of a recent line of works on provably convergent learned optimization algorithms applied to accelerate the solution of imaging inverse problems, alongside their dedicated unsupervised training schemes. We also survey a number of provably convergent plug-and-play algorithms (based on gradient-step deep denoisers), which are among the most important and widely applied unsupervised approaches for imaging problems. At the end of this survey, we provide an overview of a few related unsupervised learning frameworks that complement our focused schemes. Together with a detailed survey, we provide an overview of the key mathematical results that underlie the methods reviewed in the chapter to keep our discussion self-contained.
Deep Unrolling Networks with Recurrent Momentum Acceleration for Nonlinear Inverse Problems
Aug 16, 2023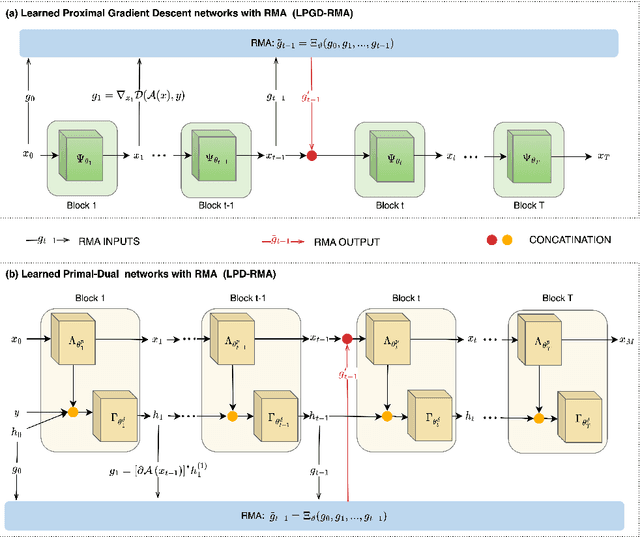
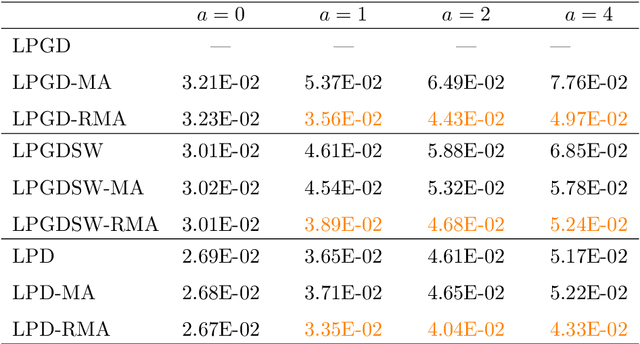
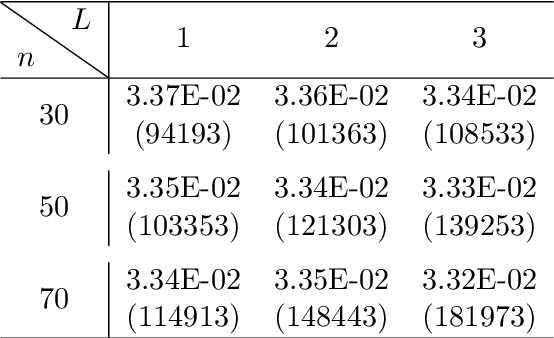
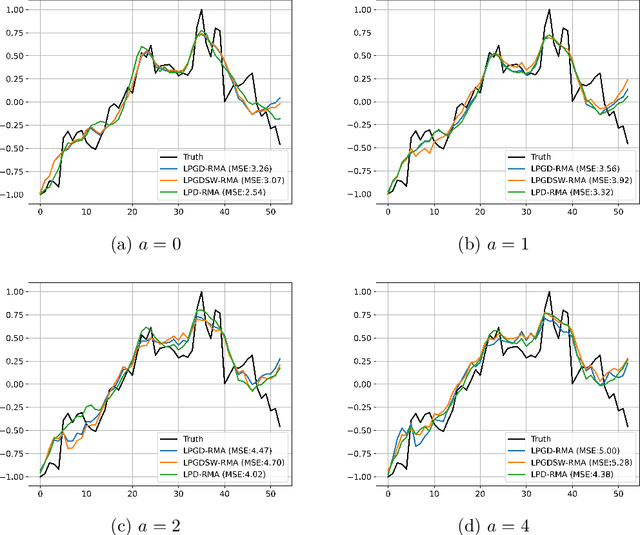
Combining the strengths of model-based iterative algorithms and data-driven deep learning solutions, deep unrolling networks (DuNets) have become a popular tool to solve inverse imaging problems. While DuNets have been successfully applied to many linear inverse problems, nonlinear problems tend to impair the performance of the method. Inspired by momentum acceleration techniques that are often used in optimization algorithms, we propose a recurrent momentum acceleration (RMA) framework that uses a long short-term memory recurrent neural network (LSTM-RNN) to simulate the momentum acceleration process. The RMA module leverages the ability of the LSTM-RNN to learn and retain knowledge from the previous gradients. We apply RMA to two popular DuNets -- the learned proximal gradient descent (LPGD) and the learned primal-dual (LPD) methods, resulting in LPGD-RMA and LPD-RMA respectively. We provide experimental results on two nonlinear inverse problems: a nonlinear deconvolution problem, and an electrical impedance tomography problem with limited boundary measurements. In the first experiment we have observed that the improvement due to RMA largely increases with respect to the nonlinearity of the problem. The results of the second example further demonstrate that the RMA schemes can significantly improve the performance of DuNets in strongly ill-posed problems.
NF-ULA: Langevin Monte Carlo with Normalizing Flow Prior for Imaging Inverse Problems
Apr 17, 2023

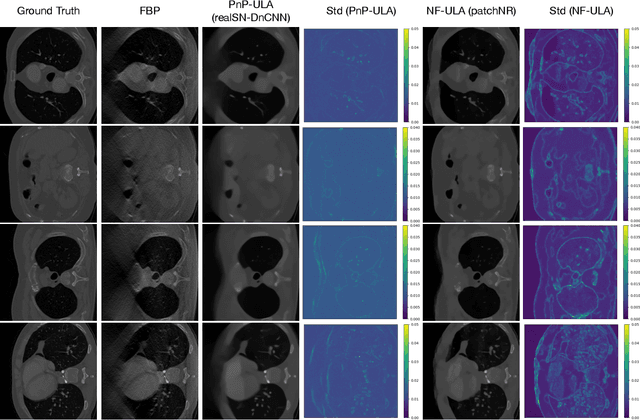
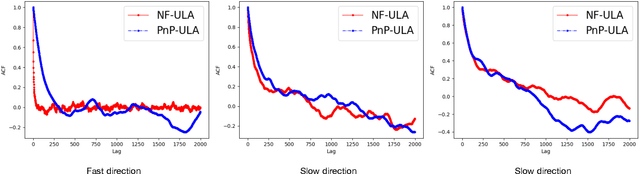
Bayesian methods for solving inverse problems are a powerful alternative to classical methods since the Bayesian approach gives a probabilistic description of the problems and offers the ability to quantify the uncertainty in the solution. Meanwhile, solving inverse problems by data-driven techniques also proves to be successful, due to the increasing representation ability of data-based models. In this work, we try to incorporate the data-based models into a class of Langevin-based sampling algorithms in Bayesian inference. Loosely speaking, we introduce NF-ULA (Unadjusted Langevin algorithms by Normalizing Flows), which involves learning a normalizing flow as the prior. In particular, our algorithm only requires a pre-trained normalizing flow, which is independent of the considered inverse problem and the forward operator. We perform theoretical analysis by investigating the well-posedness of the Bayesian solution and the non-asymptotic convergence of the NF-ULA algorithm. The efficacy of the proposed NF-ULA algorithm is demonstrated in various imaging problems, including image deblurring, image inpainting, and limited-angle X-ray computed tomography (CT) reconstruction.
Provably Convergent Plug-and-Play Quasi-Newton Methods
Mar 09, 2023



Plug-and-Play (PnP) methods are a class of efficient iterative methods that aim to combine data fidelity terms and deep denoisers using classical optimization algorithms, such as ISTA or ADMM. Existing provable PnP methods impose heavy restrictions on the denoiser or fidelity function, such as nonexpansiveness or strict convexity. In this work, we propose a provable PnP method that imposes relatively light conditions based on proximal denoisers, and introduce a quasi-Newton step to greatly accelerate convergence. By specially parameterizing the deep denoiser as a gradient step, we further characterize the fixed-points of the quasi-Newton PnP algorithm.
Accelerating Deep Unrolling Networks via Dimensionality Reduction
Aug 31, 2022



In this work we propose a new paradigm for designing efficient deep unrolling networks using dimensionality reduction schemes, including minibatch gradient approximation and operator sketching. The deep unrolling networks are currently the state-of-the-art solutions for imaging inverse problems. However, for high-dimensional imaging tasks, especially X-ray CT and MRI imaging, the deep unrolling schemes typically become inefficient both in terms of memory and computation, due to the need of computing multiple times the high-dimensional forward and adjoint operators. Recently researchers have found that such limitations can be partially addressed by unrolling the stochastic gradient descent (SGD), inspired by the success of stochastic first-order optimization. In this work, we explore further this direction and propose first a more expressive and practical stochastic primal-dual unrolling, based on the state-of-the-art Learned Primal-Dual (LPD) network, and also a further acceleration upon stochastic primal-dual unrolling, using sketching techniques to approximate products in the high-dimensional image space. The operator sketching can be jointly applied with stochastic unrolling for the best acceleration and compression performance. Our numerical experiments on X-ray CT image reconstruction demonstrate the remarkable effectiveness of our accelerated unrolling schemes.
Stochastic Primal-Dual Three Operator Splitting with Arbitrary Sampling and Preconditioning
Aug 02, 2022

In this work we propose a stochastic primal-dual preconditioned three-operator splitting algorithm for solving a class of convex three-composite optimization problems. Our proposed scheme is a direct three-operator splitting extension of the SPDHG algorithm [Chambolle et al. 2018]. We provide theoretical convergence analysis showing ergodic O(1/K) convergence rate, and demonstrate the effectiveness of our approach in imaging inverse problems.
Operator Sketching for Deep Unrolling Networks
Mar 22, 2022

In this work we propose a new paradigm for designing efficient deep unrolling networks using operator sketching. The deep unrolling networks are currently the state-of-the-art solutions for imaging inverse problems. However, for high-dimensional imaging tasks, especially the 3D cone-beam X-ray CT and 4D MRI imaging, the deep unrolling schemes typically become inefficient both in terms of memory and computation, due to the need of computing multiple times the high-dimensional forward and adjoint operators. Recently researchers have found that such limitations can be partially addressed by stochastic unrolling with subsets of operators, inspired by the success of stochastic first-order optimization. In this work, we propose a further acceleration upon stochastic unrolling, using sketching techniques to approximate products in the high-dimensional image space. The operator sketching can be jointly applied with stochastic unrolling for the best acceleration and compression performance. Our numerical experiments on X-ray CT image reconstruction demonstrate the remarkable effectiveness of our sketched unrolling schemes.
Accelerating Plug-and-Play Image Reconstruction via Multi-Stage Sketched Gradients
Mar 14, 2022


In this work we propose a new paradigm for designing fast plug-and-play (PnP) algorithms using dimensionality reduction techniques. Unlike existing approaches which utilize stochastic gradient iterations for acceleration, we propose novel multi-stage sketched gradient iterations which first perform downsampling dimensionality reduction in the image space, and then efficiently approximate the true gradient using the sketched gradient in the low-dimensional space. This sketched gradient scheme can also be naturally combined with PnP-SGD methods for further improvement on computational complexity. As a generic acceleration scheme, it can be applied to accelerate any existing PnP/RED algorithm. Our numerical experiments on X-ray fan-beam CT demonstrate the remarkable effectiveness of our scheme, that a computational free-lunch can be obtained using this dimensionality reduction in the image space.
Data-Consistent Local Superresolution for Medical Imaging
Feb 22, 2022



In this work we propose a new paradigm of iterative model-based reconstruction algorithms for providing real-time solution for zooming-in and refining a region of interest in medical and clinical tomographic (such as CT/MRI/PET, etc) images. This algorithmic framework is tailor for a clinical need in medical imaging practice, that after a reconstruction of the full tomographic image, the clinician may believe that some critical parts of the image are not clear enough, and may wish to see clearer these regions-of-interest. A naive approach (which is highly not recommended) would be performing the global reconstruction of a higher resolution image, which has two major limitations: firstly, it is computationally inefficient, and secondly, the image regularization is still applied globally which may over-smooth some local regions. Furthermore if one wish to fine-tune the regularization parameter for local parts, it would be computationally infeasible in practice for the case of using global reconstruction. Our new iterative approaches for such tasks are based on jointly utilizing the measurement information, efficient upsampling/downsampling across image spaces, and locally adjusted image prior for efficient and high-quality post-processing. The numerical results in low-dose X-ray CT image local zoom-in demonstrate the effectiveness of our approach.