 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSanjeev Arora
Keeping LLMs Aligned After Fine-tuning: The Crucial Role of Prompt Templates
Feb 28, 2024
Public LLMs such as the Llama 2-Chat have driven huge activity in LLM research. These models underwent alignment training and were considered safe. Recently Qi et al. (2023) reported that even benign fine-tuning (e.g., on seemingly safe datasets) can give rise to unsafe behaviors in the models. The current paper is about methods and best practices to mitigate such loss of alignment. Through extensive experiments on several chat models (Meta's Llama 2-Chat, Mistral AI's Mistral 7B Instruct v0.2, and OpenAI's GPT-3.5 Turbo), this paper uncovers that the prompt templates used during fine-tuning and inference play a crucial role in preserving safety alignment, and proposes the "Pure Tuning, Safe Testing" (PTST) principle -- fine-tune models without a safety prompt, but include it at test time. Fine-tuning experiments on GSM8K, ChatDoctor, and OpenOrca show that PTST significantly reduces the rise of unsafe behaviors, and even almost eliminates them in some cases.
LESS: Selecting Influential Data for Targeted Instruction Tuning
Feb 20, 2024Instruction tuning has unlocked powerful capabilities in large language models (LLMs), effectively using combined datasets to develop generalpurpose chatbots. However, real-world applications often require a specialized suite of skills (e.g., reasoning). The challenge lies in identifying the most relevant data from these extensive datasets to effectively develop specific capabilities, a setting we frame as targeted instruction tuning. We propose LESS, an optimizer-aware and practically efficient algorithm to effectively estimate data influences and perform Low-rank gradiEnt Similarity Search for instruction data selection. Crucially, LESS adapts existing influence formulations to work with the Adam optimizer and variable-length instruction data. LESS first constructs a highly reusable and transferable gradient datastore with low-dimensional gradient features and then selects examples based on their similarity to few-shot examples embodying a specific capability. Experiments show that training on a LESS-selected 5% of the data can often outperform training on the full dataset across diverse downstream tasks. Furthermore, the selected data is highly transferable: smaller models can be leveraged to select useful data for larger models and models from different families. Our qualitative analysis shows that our method goes beyond surface form cues to identify data that exemplifies the necessary reasoning skills for the intended downstream application.
Language Models as Science Tutors
Feb 16, 2024NLP has recently made exciting progress toward training language models (LMs) with strong scientific problem-solving skills. However, model development has not focused on real-life use-cases of LMs for science, including applications in education that require processing long scientific documents. To address this, we introduce TutorEval and TutorChat. TutorEval is a diverse question-answering benchmark consisting of questions about long chapters from STEM textbooks, written by experts. TutorEval helps measure real-life usability of LMs as scientific assistants, and it is the first benchmark combining long contexts, free-form generation, and multi-disciplinary scientific knowledge. Moreover, we show that fine-tuning base models with existing dialogue datasets leads to poor performance on TutorEval. Therefore, we create TutorChat, a dataset of 80,000 long synthetic dialogues about textbooks. We use TutorChat to fine-tune Llemma models with 7B and 34B parameters. These LM tutors specialized in math have a 32K-token context window, and they excel at TutorEval while performing strongly on GSM8K and MATH. Our datasets build on open-source materials, and we release our models, data, and evaluations.
Unlearning via Sparse Representations
Nov 26, 2023Machine \emph{unlearning}, which involves erasing knowledge about a \emph{forget set} from a trained model, can prove to be costly and infeasible by existing techniques. We propose a nearly compute-free zero-shot unlearning technique based on a discrete representational bottleneck. We show that the proposed technique efficiently unlearns the forget set and incurs negligible damage to the model's performance on the rest of the data set. We evaluate the proposed technique on the problem of \textit{class unlearning} using three datasets: CIFAR-10, CIFAR-100, and LACUNA-100. We compare the proposed technique to SCRUB, a state-of-the-art approach which uses knowledge distillation for unlearning. Across all three datasets, the proposed technique performs as well as, if not better than SCRUB while incurring almost no computational cost.
Skill-Mix: a Flexible and Expandable Family of Evaluations for AI models
Oct 26, 2023

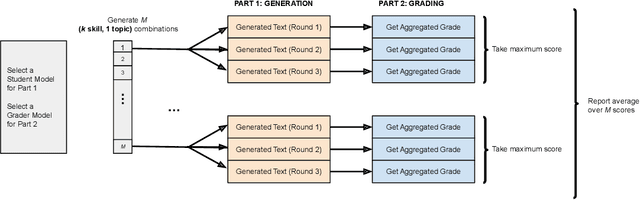

With LLMs shifting their role from statistical modeling of language to serving as general-purpose AI agents, how should LLM evaluations change? Arguably, a key ability of an AI agent is to flexibly combine, as needed, the basic skills it has learned. The capability to combine skills plays an important role in (human) pedagogy and also in a paper on emergence phenomena (Arora & Goyal, 2023). This work introduces Skill-Mix, a new evaluation to measure ability to combine skills. Using a list of $N$ skills the evaluator repeatedly picks random subsets of $k$ skills and asks the LLM to produce text combining that subset of skills. Since the number of subsets grows like $N^k$, for even modest $k$ this evaluation will, with high probability, require the LLM to produce text significantly different from any text in the training set. The paper develops a methodology for (a) designing and administering such an evaluation, and (b) automatic grading (plus spot-checking by humans) of the results using GPT-4 as well as the open LLaMA-2 70B model. Administering a version of to popular chatbots gave results that, while generally in line with prior expectations, contained surprises. Sizeable differences exist among model capabilities that are not captured by their ranking on popular LLM leaderboards ("cramming for the leaderboard"). Furthermore, simple probability calculations indicate that GPT-4's reasonable performance on $k=5$ is suggestive of going beyond "stochastic parrot" behavior (Bender et al., 2021), i.e., it combines skills in ways that it had not seen during training. We sketch how the methodology can lead to a Skill-Mix based eco-system of open evaluations for AI capabilities of future models.
A Quadratic Synchronization Rule for Distributed Deep Learning
Oct 22, 2023In distributed deep learning with data parallelism, synchronizing gradients at each training step can cause a huge communication overhead, especially when many nodes work together to train large models. Local gradient methods, such as Local SGD, address this issue by allowing workers to compute locally for $H$ steps without synchronizing with others, hence reducing communication frequency. While $H$ has been viewed as a hyperparameter to trade optimization efficiency for communication cost, recent research indicates that setting a proper $H$ value can lead to generalization improvement. Yet, selecting a proper $H$ is elusive. This work proposes a theory-grounded method for determining $H$, named the Quadratic Synchronization Rule (QSR), which recommends dynamically setting $H$ in proportion to $\frac{1}{\eta^2}$ as the learning rate $\eta$ decays over time. Extensive ImageNet experiments on ResNet and ViT show that local gradient methods with QSR consistently improve the test accuracy over other synchronization strategies. Compared with the standard data parallel training, QSR enables Local AdamW on ViT-B to cut the training time on 16 or 64 GPUs down from 26.7 to 20.2 hours or from 8.6 to 5.5 hours and, at the same time, achieves $1.16\%$ or $0.84\%$ higher top-1 validation accuracy.
A Theory for Emergence of Complex Skills in Language Models
Jul 29, 2023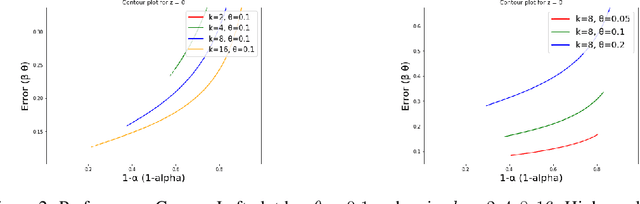
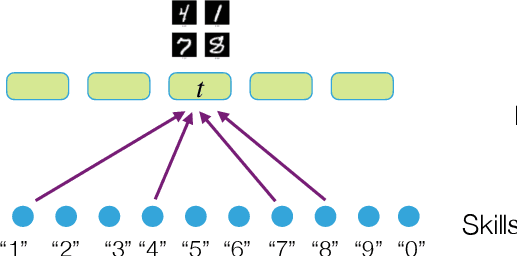
A major driver of AI products today is the fact that new skills emerge in language models when their parameter set and training corpora are scaled up. This phenomenon is poorly understood, and a mechanistic explanation via mathematical analysis of gradient-based training seems difficult. The current paper takes a different approach, analysing emergence using the famous (and empirical) Scaling Laws of LLMs and a simple statistical framework. Contributions include: (a) A statistical framework that relates cross-entropy loss of LLMs to competence on the basic skills that underlie language tasks. (b) Mathematical analysis showing that the Scaling Laws imply a strong form of inductive bias that allows the pre-trained model to learn very efficiently. We informally call this {\em slingshot generalization} since naively viewed it appears to give competence levels at skills that violate usual generalization theory. (c) A key example of slingshot generalization, that competence at executing tasks involving $k$-tuples of skills emerges essentially at the same scaling and same rate as competence on the elementary skills themselves.
Trainable Transformer in Transformer
Jul 03, 2023Recent works attribute the capability of in-context learning (ICL) in large pre-trained language models to implicitly simulating and fine-tuning an internal model (e.g., linear or 2-layer MLP) during inference. However, such constructions require large memory overhead, which makes simulation of more sophisticated internal models intractable. In this work, we propose an efficient construction, Transformer in Transformer (in short, TinT), that allows a transformer to simulate and fine-tune complex models internally during inference (e.g., pre-trained language models). In particular, we introduce innovative approximation techniques that allow a TinT model with less than 2 billion parameters to simulate and fine-tune a 125 million parameter transformer model within a single forward pass. TinT accommodates many common transformer variants and its design ideas also improve the efficiency of past instantiations of simple models inside transformers. We conduct end-to-end experiments to validate the internal fine-tuning procedure of TinT on various language modeling and downstream tasks. For example, even with a limited one-step budget, we observe TinT for a OPT-125M model improves performance by 4-16% absolute on average compared to OPT-125M. These findings suggest that large pre-trained language models are capable of performing intricate subroutines. To facilitate further work, a modular and extensible codebase for TinT is included.
Fine-Tuning Language Models with Just Forward Passes
May 27, 2023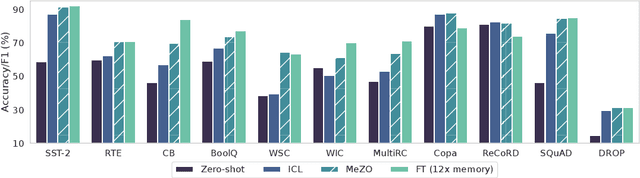
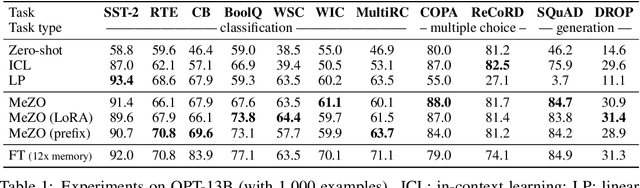
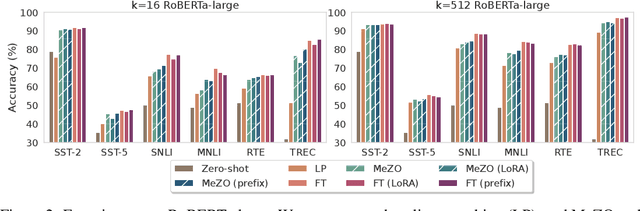
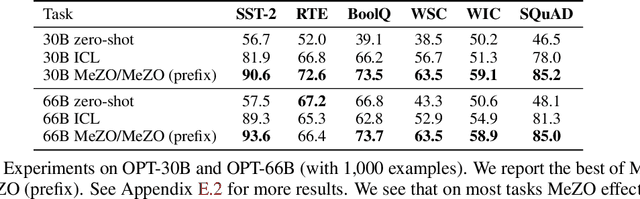
Fine-tuning language models (LMs) has yielded success on diverse downstream tasks, but as LMs grow in size, backpropagation requires a prohibitively large amount of memory. Zeroth-order (ZO) methods can in principle estimate gradients using only two forward passes but are theorized to be catastrophically slow for optimizing large models. In this work, we propose a memory-efficient zerothorder optimizer (MeZO), adapting the classical ZO-SGD method to operate in-place, thereby fine-tuning LMs with the same memory footprint as inference. For example, with a single A100 80GB GPU, MeZO can train a 30-billion parameter model, whereas fine-tuning with backpropagation can train only a 2.7B LM with the same budget. We conduct comprehensive experiments across model types (masked and autoregressive LMs), model scales (up to 66B), and downstream tasks (classification, multiple-choice, and generation). Our results demonstrate that (1) MeZO significantly outperforms in-context learning and linear probing; (2) MeZO achieves comparable performance to fine-tuning with backpropagation across multiple tasks, with up to 12x memory reduction; (3) MeZO is compatible with both full-parameter and parameter-efficient tuning techniques such as LoRA and prefix tuning; (4) MeZO can effectively optimize non-differentiable objectives (e.g., maximizing accuracy or F1). We support our empirical findings with theoretical insights, highlighting how adequate pre-training and task prompts enable MeZO to fine-tune huge models, despite classical ZO analyses suggesting otherwise.
Do Transformers Parse while Predicting the Masked Word?
Mar 14, 2023

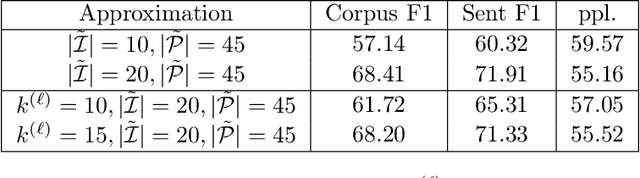
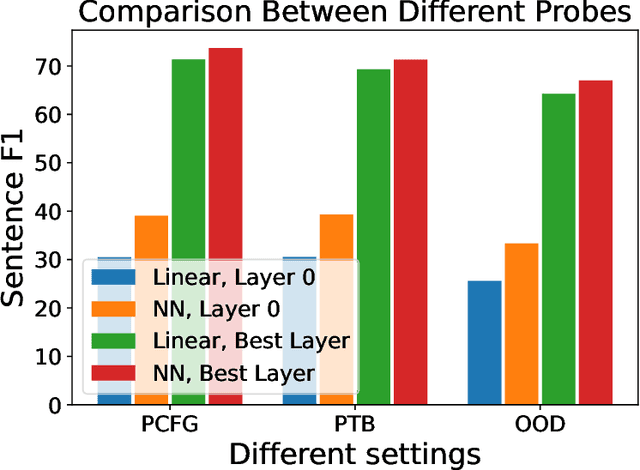
Pre-trained language models have been shown to encode linguistic structures, e.g. dependency and constituency parse trees, in their embeddings while being trained on unsupervised loss functions like masked language modeling. Some doubts have been raised whether the models actually are doing parsing or only some computation weakly correlated with it. We study questions: (a) Is it possible to explicitly describe transformers with realistic embedding dimension, number of heads, etc. that are capable of doing parsing -- or even approximate parsing? (b) Why do pre-trained models capture parsing structure? This paper takes a step toward answering these questions in the context of generative modeling with PCFGs. We show that masked language models like BERT or RoBERTa of moderate sizes can approximately execute the Inside-Outside algorithm for the English PCFG [Marcus et al, 1993]. We also show that the Inside-Outside algorithm is optimal for masked language modeling loss on the PCFG-generated data. We also give a construction of transformers with $50$ layers, $15$ attention heads, and $1275$ dimensional embeddings in average such that using its embeddings it is possible to do constituency parsing with $>70\%$ F1 score on PTB dataset. We conduct probing experiments on models pre-trained on PCFG-generated data to show that this not only allows recovery of approximate parse tree, but also recovers marginal span probabilities computed by the Inside-Outside algorithm, which suggests an implicit bias of masked language modeling towards this algorithm.