 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKaifeng Lyu
RNNs are not Transformers (Yet): The Key Bottleneck on In-context Retrieval
Feb 29, 2024
This paper investigates the gap in representation powers of Recurrent Neural Networks (RNNs) and Transformers in the context of solving algorithmic problems. We focus on understanding whether RNNs, known for their memory efficiency in handling long sequences, can match the performance of Transformers, particularly when enhanced with Chain-of-Thought (CoT) prompting. Our theoretical analysis reveals that CoT improves RNNs but is insufficient to close the gap with Transformers. A key bottleneck lies in the inability of RNNs to perfectly retrieve information from the context, even with CoT: for several tasks that explicitly or implicitly require this capability, such as associative recall and determining if a graph is a tree, we prove that RNNs are not expressive enough to solve the tasks while Transformers can solve them with ease. Conversely, we prove that adopting techniques to enhance the in-context retrieval capability of RNNs, including Retrieval-Augmented Generation (RAG) and adding a single Transformer layer, can elevate RNNs to be capable of solving all polynomial-time solvable problems with CoT, hence closing the representation gap with Transformers.
Keeping LLMs Aligned After Fine-tuning: The Crucial Role of Prompt Templates
Feb 28, 2024Public LLMs such as the Llama 2-Chat have driven huge activity in LLM research. These models underwent alignment training and were considered safe. Recently Qi et al. (2023) reported that even benign fine-tuning (e.g., on seemingly safe datasets) can give rise to unsafe behaviors in the models. The current paper is about methods and best practices to mitigate such loss of alignment. Through extensive experiments on several chat models (Meta's Llama 2-Chat, Mistral AI's Mistral 7B Instruct v0.2, and OpenAI's GPT-3.5 Turbo), this paper uncovers that the prompt templates used during fine-tuning and inference play a crucial role in preserving safety alignment, and proposes the "Pure Tuning, Safe Testing" (PTST) principle -- fine-tune models without a safety prompt, but include it at test time. Fine-tuning experiments on GSM8K, ChatDoctor, and OpenOrca show that PTST significantly reduces the rise of unsafe behaviors, and even almost eliminates them in some cases.
Efficient Stagewise Pretraining via Progressive Subnetworks
Feb 08, 2024Recent developments in large language models have sparked interest in efficient pretraining methods. A recent effective paradigm is to perform stage-wise training, where the size of the model is gradually increased over the course of training (e.g. gradual stacking (Reddi et al., 2023)). While the resource and wall-time savings are appealing, it has limitations, particularly the inability to evaluate the full model during earlier stages, and degradation in model quality due to smaller model capacity in the initial stages. In this work, we propose an alternative framework, progressive subnetwork training, that maintains the full model throughout training, but only trains subnetworks within the model in each step. We focus on a simple instantiation of this framework, Random Path Training (RaPTr) that only trains a sub-path of layers in each step, progressively increasing the path lengths in stages. RaPTr achieves better pre-training loss for BERT and UL2 language models while requiring 20-33% fewer FLOPs compared to standard training, and is competitive or better than other efficient training methods. Furthermore, RaPTr shows better downstream performance on UL2, improving QA tasks and SuperGLUE by 1-5% compared to standard training and stacking. Finally, we provide a theoretical basis for RaPTr to justify (a) the increasing complexity of subnetworks in stages, and (b) the stability in loss across stage transitions due to residual connections and layer norm.
Dichotomy of Early and Late Phase Implicit Biases Can Provably Induce Grokking
Nov 30, 2023Recent work by Power et al. (2022) highlighted a surprising "grokking" phenomenon in learning arithmetic tasks: a neural net first "memorizes" the training set, resulting in perfect training accuracy but near-random test accuracy, and after training for sufficiently longer, it suddenly transitions to perfect test accuracy. This paper studies the grokking phenomenon in theoretical setups and shows that it can be induced by a dichotomy of early and late phase implicit biases. Specifically, when training homogeneous neural nets with large initialization and small weight decay on both classification and regression tasks, we prove that the training process gets trapped at a solution corresponding to a kernel predictor for a long time, and then a very sharp transition to min-norm/max-margin predictors occurs, leading to a dramatic change in test accuracy.
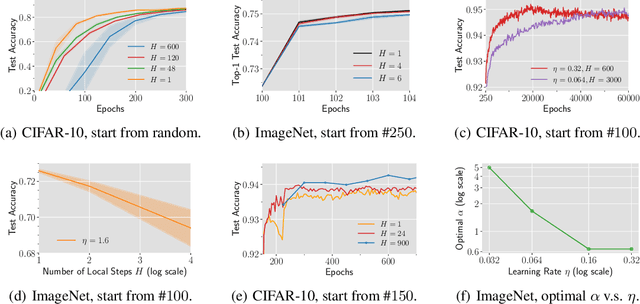
A Quadratic Synchronization Rule for Distributed Deep Learning
Oct 22, 2023In distributed deep learning with data parallelism, synchronizing gradients at each training step can cause a huge communication overhead, especially when many nodes work together to train large models. Local gradient methods, such as Local SGD, address this issue by allowing workers to compute locally for $H$ steps without synchronizing with others, hence reducing communication frequency. While $H$ has been viewed as a hyperparameter to trade optimization efficiency for communication cost, recent research indicates that setting a proper $H$ value can lead to generalization improvement. Yet, selecting a proper $H$ is elusive. This work proposes a theory-grounded method for determining $H$, named the Quadratic Synchronization Rule (QSR), which recommends dynamically setting $H$ in proportion to $\frac{1}{\eta^2}$ as the learning rate $\eta$ decays over time. Extensive ImageNet experiments on ResNet and ViT show that local gradient methods with QSR consistently improve the test accuracy over other synchronization strategies. Compared with the standard data parallel training, QSR enables Local AdamW on ViT-B to cut the training time on 16 or 64 GPUs down from 26.7 to 20.2 hours or from 8.6 to 5.5 hours and, at the same time, achieves $1.16\%$ or $0.84\%$ higher top-1 validation accuracy.
DistillSpec: Improving Speculative Decoding via Knowledge Distillation
Oct 12, 2023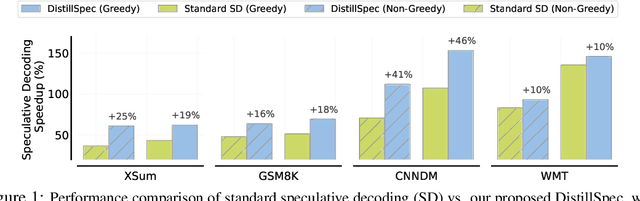

Speculative decoding (SD) accelerates large language model inference by employing a faster draft model for generating multiple tokens, which are then verified in parallel by the larger target model, resulting in the text generated according to the target model distribution. However, identifying a compact draft model that is well-aligned with the target model is challenging. To tackle this issue, we propose DistillSpec that uses knowledge distillation to better align the draft model with the target model, before applying SD. DistillSpec makes two key design choices, which we demonstrate via systematic study to be crucial to improving the draft and target alignment: utilizing on-policy data generation from the draft model, and tailoring the divergence function to the task and decoding strategy. Notably, DistillSpec yields impressive 10 - 45% speedups over standard SD on a range of standard benchmarks, using both greedy and non-greedy sampling. Furthermore, we combine DistillSpec with lossy SD to achieve fine-grained control over the latency vs. task performance trade-off. Finally, in practical scenarios with models of varying sizes, first using distillation to boost the performance of the target model and then applying DistillSpec to train a well-aligned draft model can reduce decoding latency by 6-10x with minimal performance drop, compared to standard decoding without distillation.
The Marginal Value of Momentum for Small Learning Rate SGD
Jul 27, 2023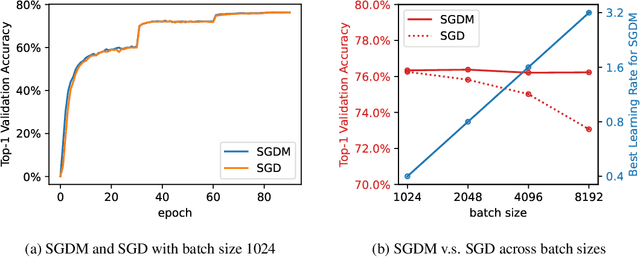

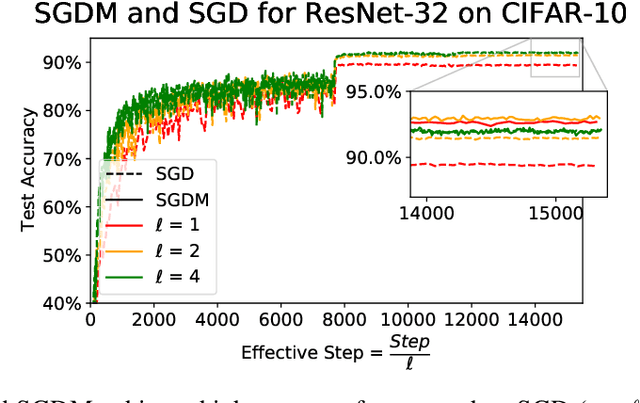
Momentum is known to accelerate the convergence of gradient descent in strongly convex settings without stochastic gradient noise. In stochastic optimization, such as training neural networks, folklore suggests that momentum may help deep learning optimization by reducing the variance of the stochastic gradient update, but previous theoretical analyses do not find momentum to offer any provable acceleration. Theoretical results in this paper clarify the role of momentum in stochastic settings where the learning rate is small and gradient noise is the dominant source of instability, suggesting that SGD with and without momentum behave similarly in the short and long time horizons. Experiments show that momentum indeed has limited benefits for both optimization and generalization in practical training regimes where the optimal learning rate is not very large, including small- to medium-batch training from scratch on ImageNet and fine-tuning language models on downstream tasks.
Why (and When) does Local SGD Generalize Better than SGD?
Mar 09, 2023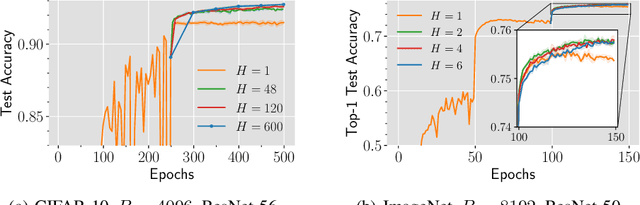
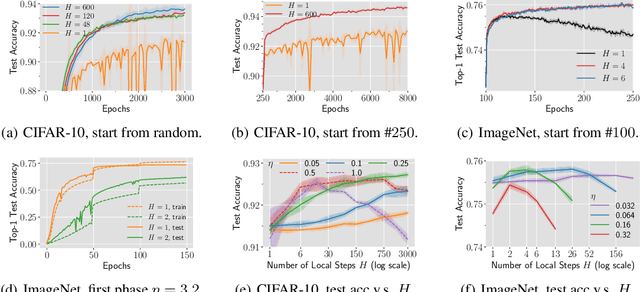
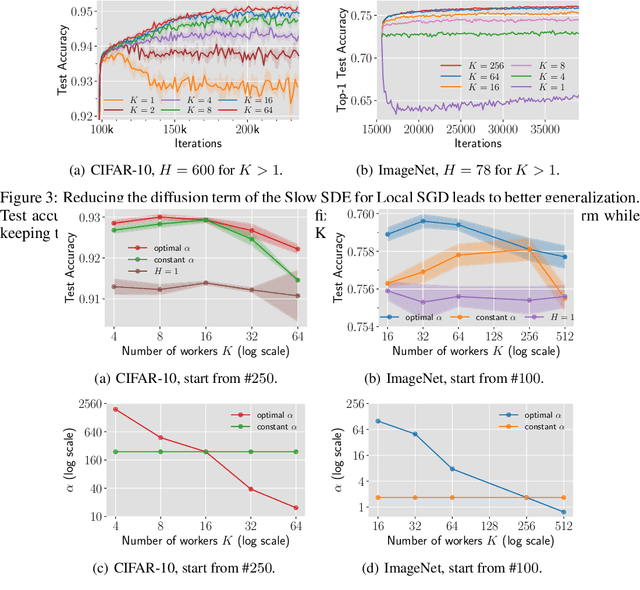
Local SGD is a communication-efficient variant of SGD for large-scale training, where multiple GPUs perform SGD independently and average the model parameters periodically. It has been recently observed that Local SGD can not only achieve the design goal of reducing the communication overhead but also lead to higher test accuracy than the corresponding SGD baseline (Lin et al., 2020b), though the training regimes for this to happen are still in debate (Ortiz et al., 2021). This paper aims to understand why (and when) Local SGD generalizes better based on Stochastic Differential Equation (SDE) approximation. The main contributions of this paper include (i) the derivation of an SDE that captures the long-term behavior of Local SGD in the small learning rate regime, showing how noise drives the iterate to drift and diffuse after it has reached close to the manifold of local minima, (ii) a comparison between the SDEs of Local SGD and SGD, showing that Local SGD induces a stronger drift term that can result in a stronger effect of regularization, e.g., a faster reduction of sharpness, and (iii) empirical evidence validating that having a small learning rate and long enough training time enables the generalization improvement over SGD but removing either of the two conditions leads to no improvement.
Understanding Incremental Learning of Gradient Descent: A Fine-grained Analysis of Matrix Sensing
Jan 27, 2023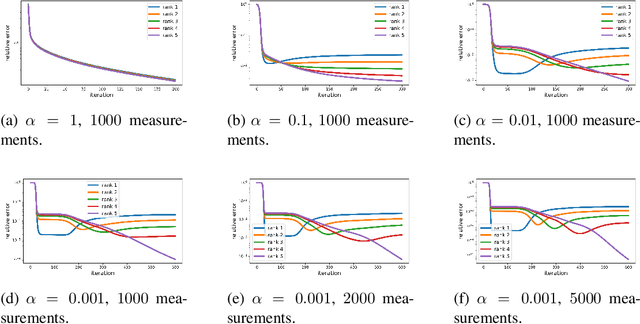
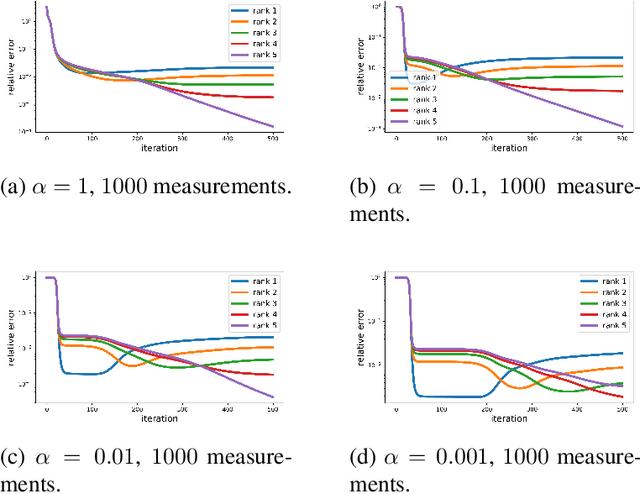
It is believed that Gradient Descent (GD) induces an implicit bias towards good generalization in training machine learning models. This paper provides a fine-grained analysis of the dynamics of GD for the matrix sensing problem, whose goal is to recover a low-rank ground-truth matrix from near-isotropic linear measurements. It is shown that GD with small initialization behaves similarly to the greedy low-rank learning heuristics (Li et al., 2020) and follows an incremental learning procedure (Gissin et al., 2019): GD sequentially learns solutions with increasing ranks until it recovers the ground truth matrix. Compared to existing works which only analyze the first learning phase for rank-1 solutions, our result provides characterizations for the whole learning process. Moreover, besides the over-parameterized regime that many prior works focused on, our analysis of the incremental learning procedure also applies to the under-parameterized regime. Finally, we conduct numerical experiments to confirm our theoretical findings.
New Definitions and Evaluations for Saliency Methods: Staying Intrinsic, Complete and Sound
Nov 05, 2022
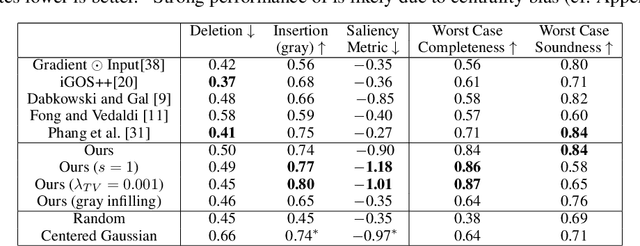


Saliency methods compute heat maps that highlight portions of an input that were most {\em important} for the label assigned to it by a deep net. Evaluations of saliency methods convert this heat map into a new {\em masked input} by retaining the $k$ highest-ranked pixels of the original input and replacing the rest with \textquotedblleft uninformative\textquotedblright\ pixels, and checking if the net's output is mostly unchanged. This is usually seen as an {\em explanation} of the output, but the current paper highlights reasons why this inference of causality may be suspect. Inspired by logic concepts of {\em completeness \& soundness}, it observes that the above type of evaluation focuses on completeness of the explanation, but ignores soundness. New evaluation metrics are introduced to capture both notions, while staying in an {\em intrinsic} framework -- i.e., using the dataset and the net, but no separately trained nets, human evaluations, etc. A simple saliency method is described that matches or outperforms prior methods in the evaluations. Experiments also suggest new intrinsic justifications, based on soundness, for popular heuristic tricks such as TV regularization and upsampling.