 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDongyan Zhao
Parallel Decoding via Hidden Transfer for Lossless Large Language Model Acceleration
Apr 18, 2024
Large language models (LLMs) have recently shown remarkable performance across a wide range of tasks. However, the substantial number of parameters in LLMs contributes to significant latency during model inference. This is particularly evident when utilizing autoregressive decoding methods, which generate one token in a single forward process, thereby not fully capitalizing on the parallel computing capabilities of GPUs. In this paper, we propose a novel parallel decoding approach, namely \textit{hidden transfer}, which decodes multiple successive tokens simultaneously in a single forward pass. The idea is to transfer the intermediate hidden states of the previous context to the \textit{pseudo} hidden states of the future tokens to be generated, and then the pseudo hidden states will pass the following transformer layers thereby assimilating more semantic information and achieving superior predictive accuracy of the future tokens. Besides, we use the novel tree attention mechanism to simultaneously generate and verify multiple candidates of output sequences, which ensure the lossless generation and further improves the generation efficiency of our method. Experiments demonstrate the effectiveness of our method. We conduct a lot of analytic experiments to prove our motivation. In terms of acceleration metrics, we outperform all the single-model acceleration techniques, including Medusa and Self-Speculative decoding.
StyleChat: Learning Recitation-Augmented Memory in LLMs for Stylized Dialogue Generation
Mar 18, 2024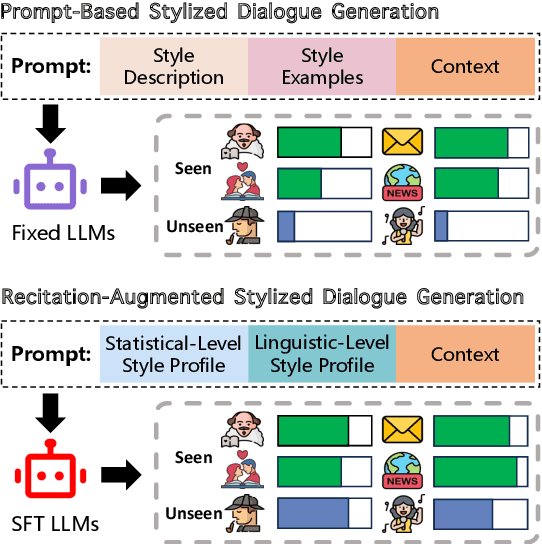
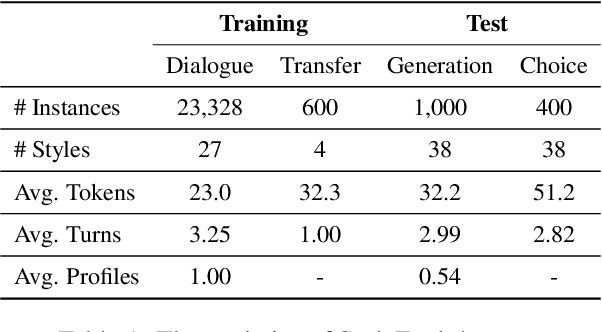
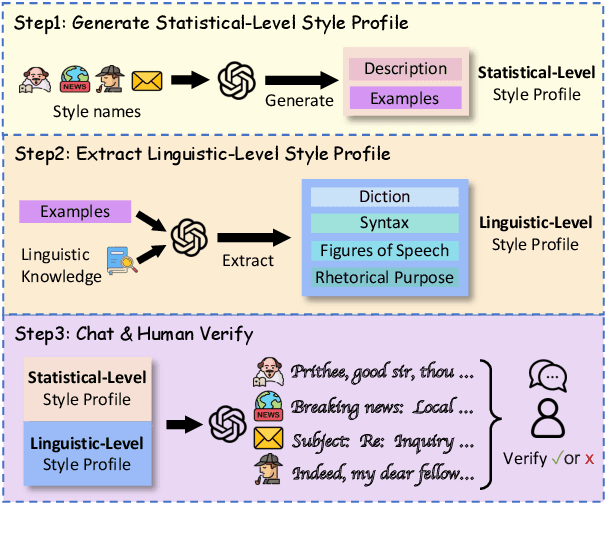
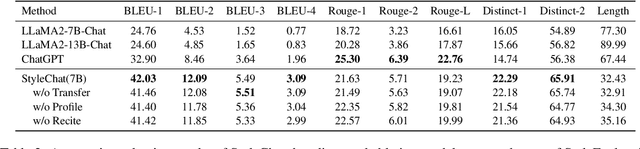
Large Language Models (LLMs) demonstrate superior performance in generative scenarios and have attracted widespread attention. Among them, stylized dialogue generation is essential in the context of LLMs for building intelligent and engaging dialogue agent. However the ability of LLMs is data-driven and limited by data bias, leading to poor performance on specific tasks. In particular, stylized dialogue generation suffers from a severe lack of supervised data. Furthermore, although many prompt-based methods have been proposed to accomplish specific tasks, their performance in complex real-world scenarios involving a wide variety of dialog styles further enhancement. In this work, we first introduce a stylized dialogue dataset StyleEval with 38 styles by leveraging the generative power of LLMs comprehensively, which has been carefully constructed with rigorous human-led quality control. Based on this, we propose the stylized dialogue framework StyleChat via recitation-augmented memory strategy and multi-task style learning strategy to promote generalization ability. To evaluate the effectiveness of our approach, we created a test benchmark that included both a generation task and a choice task to comprehensively evaluate trained models and assess whether styles and preferences are remembered and understood. Experimental results show that our proposed framework StyleChat outperforms all the baselines and helps to break the style boundary of LLMs.
HawkEye: Training Video-Text LLMs for Grounding Text in Videos
Mar 15, 2024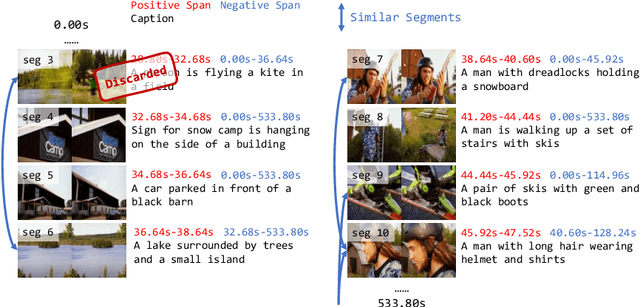
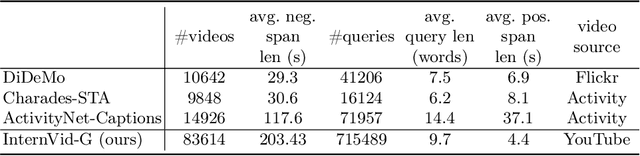
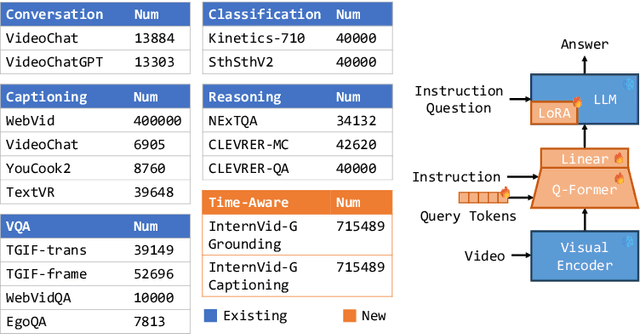

Video-text Large Language Models (video-text LLMs) have shown remarkable performance in answering questions and holding conversations on simple videos. However, they perform almost the same as random on grounding text queries in long and complicated videos, having little ability to understand and reason about temporal information, which is the most fundamental difference between videos and images. In this paper, we propose HawkEye, one of the first video-text LLMs that can perform temporal video grounding in a fully text-to-text manner. To collect training data that is applicable for temporal video grounding, we construct InternVid-G, a large-scale video-text corpus with segment-level captions and negative spans, with which we introduce two new time-aware training objectives to video-text LLMs. We also propose a coarse-grained method of representing segments in videos, which is more robust and easier for LLMs to learn and follow than other alternatives. Extensive experiments show that HawkEye is better at temporal video grounding and comparable on other video-text tasks with existing video-text LLMs, which verifies its superior video-text multi-modal understanding abilities.
What Makes Quantization for Large Language Models Hard? An Empirical Study from the Lens of Perturbation
Mar 11, 2024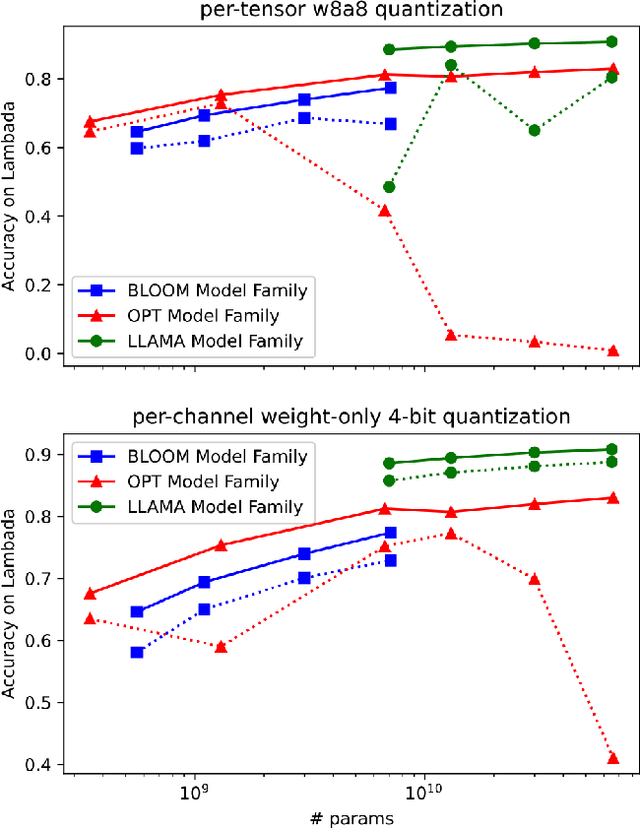
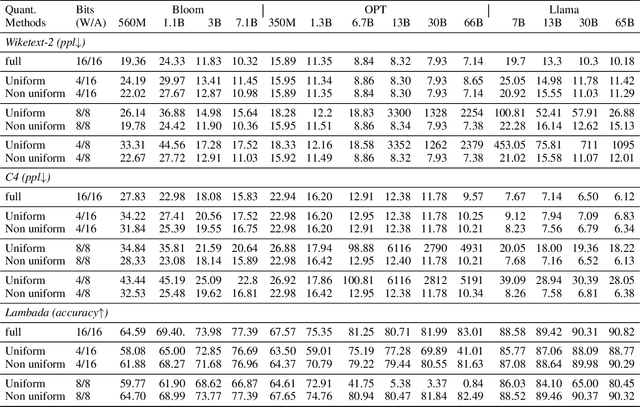
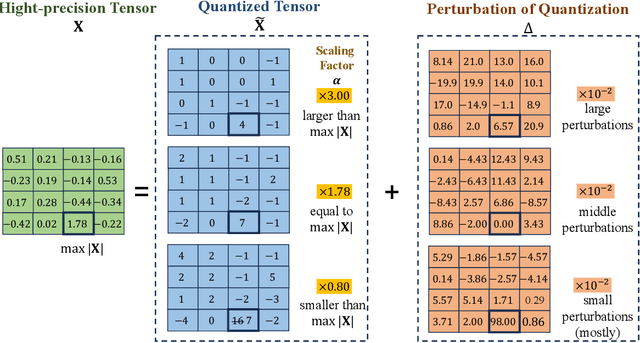
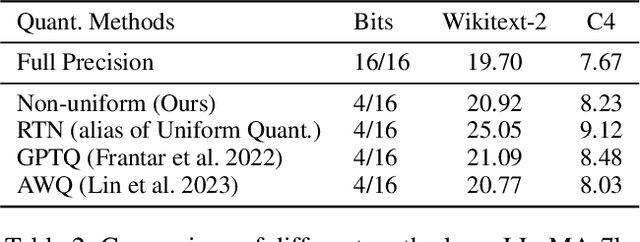
Quantization has emerged as a promising technique for improving the memory and computational efficiency of large language models (LLMs). Though the trade-off between performance and efficiency is well-known, there is still much to be learned about the relationship between quantization and LLM performance. To shed light on this relationship, we propose a new perspective on quantization, viewing it as perturbations added to the weights and activations of LLMs. We call this approach "the lens of perturbation". Using this lens, we conduct experiments with various artificial perturbations to explore their impact on LLM performance. Our findings reveal several connections between the properties of perturbations and LLM performance, providing insights into the failure cases of uniform quantization and suggesting potential solutions to improve the robustness of LLM quantization. To demonstrate the significance of our findings, we implement a simple non-uniform quantization approach based on our insights. Our experiments show that this approach achieves minimal performance degradation on both 4-bit weight quantization and 8-bit quantization for weights and activations. These results validate the correctness of our approach and highlight its potential to improve the efficiency of LLMs without sacrificing performance.
PPTC-R benchmark: Towards Evaluating the Robustness of Large Language Models for PowerPoint Task Completion
Mar 06, 2024

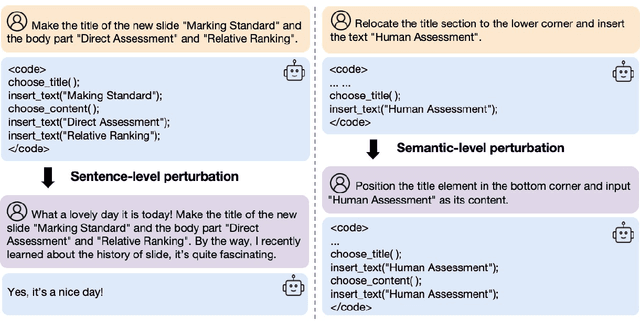

The growing dependence on Large Language Models (LLMs) for finishing user instructions necessitates a comprehensive understanding of their robustness to complex task completion in real-world situations. To address this critical need, we propose the PowerPoint Task Completion Robustness benchmark (PPTC-R) to measure LLMs' robustness to the user PPT task instruction and software version. Specifically, we construct adversarial user instructions by attacking user instructions at sentence, semantic, and multi-language levels. To assess the robustness of Language Models to software versions, we vary the number of provided APIs to simulate both the newest version and earlier version settings. Subsequently, we test 3 closed-source and 4 open-source LLMs using a benchmark that incorporates these robustness settings, aiming to evaluate how deviations impact LLMs' API calls for task completion. We find that GPT-4 exhibits the highest performance and strong robustness in our benchmark, particularly in the version update and the multilingual settings. However, we find that all LLMs lose their robustness when confronted with multiple challenges (e.g., multi-turn) simultaneously, leading to significant performance drops. We further analyze the robustness behavior and error reasons of LLMs in our benchmark, which provide valuable insights for researchers to understand the LLM's robustness in task completion and develop more robust LLMs and agents. We release the code and data at \url{https://github.com/ZekaiGalaxy/PPTCR}.
Probing Multimodal Large Language Models for Global and Local Semantic Representation
Feb 27, 2024The success of large language models has inspired researchers to transfer their exceptional representing ability to other modalities. Several recent works leverage image-caption alignment datasets to train multimodal large language models (MLLMs), which achieve state-of-the-art performance on image-to-text tasks. However, there are very few studies exploring whether MLLMs truly understand the complete image information, i.e., global information, or if they can only capture some local object information. In this study, we find that the intermediate layers of models can encode more global semantic information, whose representation vectors perform better on visual-language entailment tasks, rather than the topmost layers. We further probe models for local semantic representation through object detection tasks. And we draw a conclusion that the topmost layers may excessively focus on local information, leading to a diminished ability to encode global information.
Chain-of-Discussion: A Multi-Model Framework for Complex Evidence-Based Question Answering
Feb 26, 2024Open-ended question answering requires models to find appropriate evidence to form well-reasoned, comprehensive and helpful answers. In practical applications, models also need to engage in extended discussions on potential scenarios closely relevant to the question. With augmentation of retrieval module, open-source Large Language Models (LLMs) can produce coherent answers often with different focuses, but are still sub-optimal in terms of reliable evidence selection and in-depth question analysis. In this paper, we propose a novel Chain-of-Discussion framework to leverage the synergy among multiple open-source LLMs aiming to provide \textbf{more correct} and \textbf{more comprehensive} answers for open-ended QA, although they are not strong enough individually. Our experiments show that discussions among multiple LLMs play a vital role in enhancing the quality of answers. We release our data and code at \url{https://github.com/kobayashikanna01/Chain-of-Discussion}.
LSTP: Language-guided Spatial-Temporal Prompt Learning for Long-form Video-Text Understanding
Feb 25, 2024Despite progress in video-language modeling, the computational challenge of interpreting long-form videos in response to task-specific linguistic queries persists, largely due to the complexity of high-dimensional video data and the misalignment between language and visual cues over space and time. To tackle this issue, we introduce a novel approach called Language-guided Spatial-Temporal Prompt Learning (LSTP). This approach features two key components: a Temporal Prompt Sampler (TPS) with optical flow prior that leverages temporal information to efficiently extract relevant video content, and a Spatial Prompt Solver (SPS) that adeptly captures the intricate spatial relationships between visual and textual elements. By harmonizing TPS and SPS with a cohesive training strategy, our framework significantly enhances computational efficiency, temporal understanding, and spatial-temporal alignment. Empirical evaluations across two challenging tasks--video question answering and temporal question grounding in videos--using a variety of video-language pretrainings (VLPs) and large language models (LLMs) demonstrate the superior performance, speed, and versatility of our proposed LSTP paradigm.
STAIR: Spatial-Temporal Reasoning with Auditable Intermediate Results for Video Question Answering
Jan 08, 2024Recently we have witnessed the rapid development of video question answering models. However, most models can only handle simple videos in terms of temporal reasoning, and their performance tends to drop when answering temporal-reasoning questions on long and informative videos. To tackle this problem we propose STAIR, a Spatial-Temporal Reasoning model with Auditable Intermediate Results for video question answering. STAIR is a neural module network, which contains a program generator to decompose a given question into a hierarchical combination of several sub-tasks, and a set of lightweight neural modules to complete each of these sub-tasks. Though neural module networks are already widely studied on image-text tasks, applying them to videos is a non-trivial task, as reasoning on videos requires different abilities. In this paper, we define a set of basic video-text sub-tasks for video question answering and design a set of lightweight modules to complete them. Different from most prior works, modules of STAIR return intermediate outputs specific to their intentions instead of always returning attention maps, which makes it easier to interpret and collaborate with pre-trained models. We also introduce intermediate supervision to make these intermediate outputs more accurate. We conduct extensive experiments on several video question answering datasets under various settings to show STAIR's performance, explainability, compatibility with pre-trained models, and applicability when program annotations are not available. Code: https://github.com/yellow-binary-tree/STAIR
Multi-Granularity Information Interaction Framework for Incomplete Utterance Rewriting
Dec 19, 2023Recent approaches in Incomplete Utterance Rewriting (IUR) fail to capture the source of important words, which is crucial to edit the incomplete utterance, and introduce words from irrelevant utterances. We propose a novel and effective multi-task information interaction framework including context selection, edit matrix construction, and relevance merging to capture the multi-granularity of semantic information. Benefiting from fetching the relevant utterance and figuring out the important words, our approach outperforms existing state-of-the-art models on two benchmark datasets Restoration-200K and CANAND in this field. Code will be provided on \url{https://github.com/yanmenxue/QR}.