 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXin Cheng
StyleChat: Learning Recitation-Augmented Memory in LLMs for Stylized Dialogue Generation
Mar 18, 2024
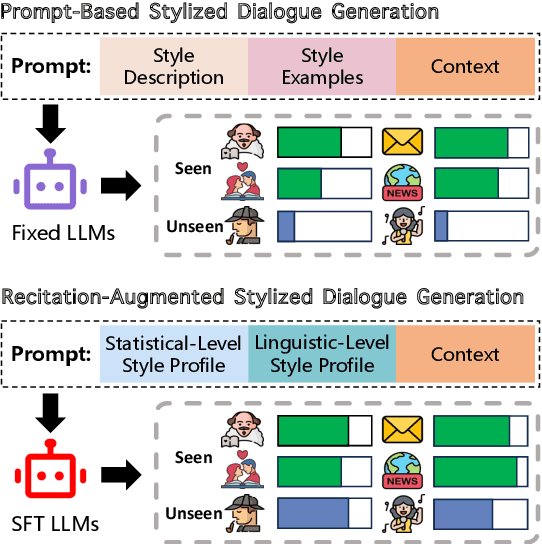
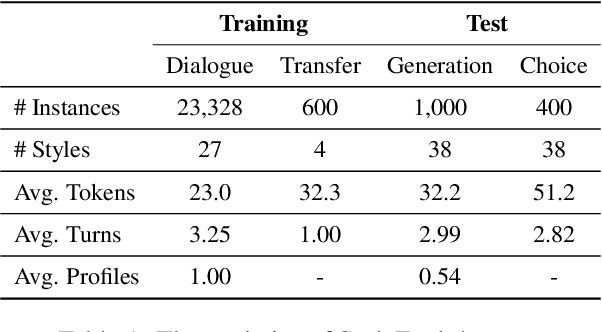
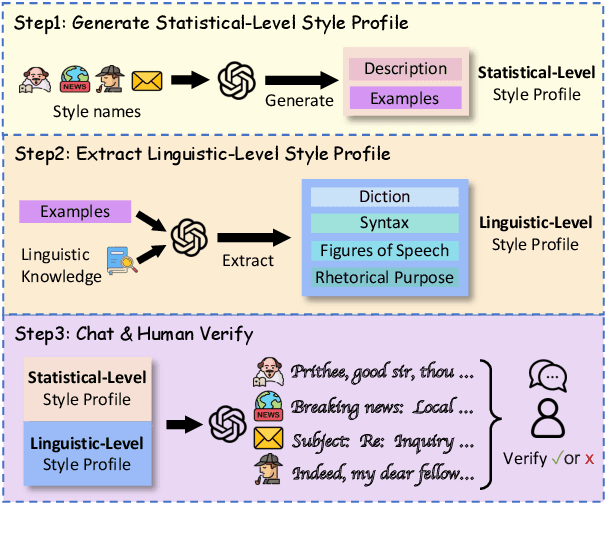
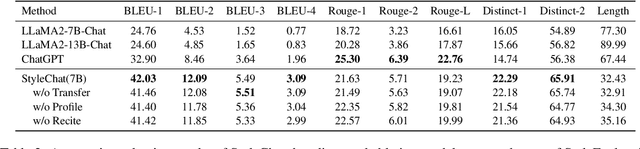
Large Language Models (LLMs) demonstrate superior performance in generative scenarios and have attracted widespread attention. Among them, stylized dialogue generation is essential in the context of LLMs for building intelligent and engaging dialogue agent. However the ability of LLMs is data-driven and limited by data bias, leading to poor performance on specific tasks. In particular, stylized dialogue generation suffers from a severe lack of supervised data. Furthermore, although many prompt-based methods have been proposed to accomplish specific tasks, their performance in complex real-world scenarios involving a wide variety of dialog styles further enhancement. In this work, we first introduce a stylized dialogue dataset StyleEval with 38 styles by leveraging the generative power of LLMs comprehensively, which has been carefully constructed with rigorous human-led quality control. Based on this, we propose the stylized dialogue framework StyleChat via recitation-augmented memory strategy and multi-task style learning strategy to promote generalization ability. To evaluate the effectiveness of our approach, we created a test benchmark that included both a generation task and a choice task to comprehensively evaluate trained models and assess whether styles and preferences are remembered and understood. Experimental results show that our proposed framework StyleChat outperforms all the baselines and helps to break the style boundary of LLMs.
Synthetic Data (Almost) from Scratch: Generalized Instruction Tuning for Language Models
Feb 20, 2024We introduce Generalized Instruction Tuning (called GLAN), a general and scalable method for instruction tuning of Large Language Models (LLMs). Unlike prior work that relies on seed examples or existing datasets to construct instruction tuning data, GLAN exclusively utilizes a pre-curated taxonomy of human knowledge and capabilities as input and generates large-scale synthetic instruction data across all disciplines. Specifically, inspired by the systematic structure in human education system, we build the taxonomy by decomposing human knowledge and capabilities to various fields, sub-fields and ultimately, distinct disciplines semi-automatically, facilitated by LLMs. Subsequently, we generate a comprehensive list of subjects for every discipline and proceed to design a syllabus tailored to each subject, again utilizing LLMs. With the fine-grained key concepts detailed in every class session of the syllabus, we are able to generate diverse instructions with a broad coverage across the entire spectrum of human knowledge and skills. Extensive experiments on large language models (e.g., Mistral) demonstrate that GLAN excels in multiple dimensions from mathematical reasoning, coding, academic exams, logical reasoning to general instruction following without using task-specific training data of these tasks. In addition, GLAN allows for easy customization and new fields or skills can be added by simply incorporating a new node into our taxonomy.
An ADMM-Based Geometric Configuration Optimization in RSSD-Based Source Localization By UAVs with Spread Angle Constraint
Nov 24, 2023Deploying multiple unmanned aerial vehicles (UAVs) to locate a signal-emitting source covers a wide range of military and civilian applications like rescue and target tracking. It is well known that the UAVs-source (sensors-target) geometry, namely geometric configuration, significantly affects the final localization accuracy. This paper focuses on the geometric configuration optimization for received signal strength difference (RSSD)-based passive source localization by drone swarm. Different from prior works, this paper considers a general measuring condition where the spread angle of drone swarm centered on the source is constrained. Subject to this constraint, a geometric configuration optimization problem with the aim of maximizing the determinant of Fisher information matrix (FIM) is formulated. After transforming this problem using matrix theory, an alternating direction method of multipliers (ADMM)-based optimization framework is proposed. To solve the subproblems in this framework, two global optimal solutions based on the Von Neumann matrix trace inequality theorem and majorize-minimize (MM) algorithm are proposed respectively. Finally, the effectiveness as well as the practicality of the proposed ADMM-based optimization algorithm are demonstrated by extensive simulations.
Regression with Cost-based Rejection
Nov 08, 2023Learning with rejection is an important framework that can refrain from making predictions to avoid critical mispredictions by balancing between prediction and rejection. Previous studies on cost-based rejection only focused on the classification setting, which cannot handle the continuous and infinite target space in the regression setting. In this paper, we investigate a novel regression problem called regression with cost-based rejection, where the model can reject to make predictions on some examples given certain rejection costs. To solve this problem, we first formulate the expected risk for this problem and then derive the Bayes optimal solution, which shows that the optimal model should reject to make predictions on the examples whose variance is larger than the rejection cost when the mean squared error is used as the evaluation metric. Furthermore, we propose to train the model by a surrogate loss function that considers rejection as binary classification and we provide conditions for the model consistency, which implies that the Bayes optimal solution can be recovered by our proposed surrogate loss. Extensive experiments demonstrate the effectiveness of our proposed method.
SCALE: Synergized Collaboration of Asymmetric Language Translation Engines
Sep 29, 2023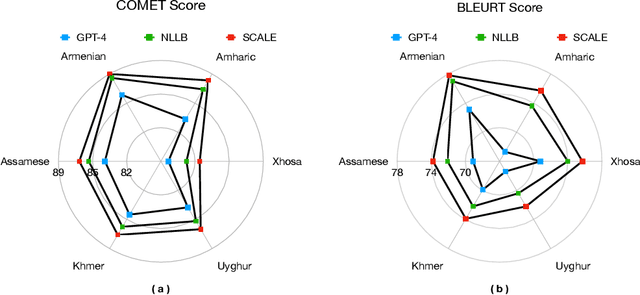
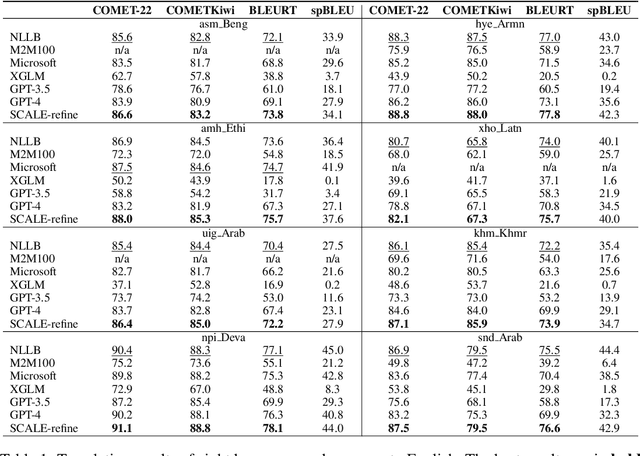
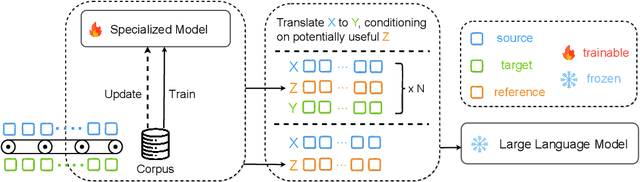
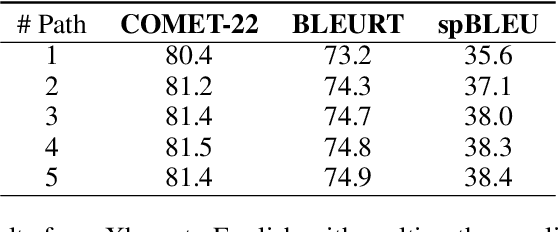
In this paper, we introduce SCALE, a collaborative framework that connects compact Specialized Translation Models (STMs) and general-purpose Large Language Models (LLMs) as one unified translation engine. By introducing translation from STM into the triplet in-context demonstrations, SCALE unlocks refinement and pivoting ability of LLM, thus mitigating language bias of LLM and parallel data bias of STM, enhancing LLM speciality without sacrificing generality, and facilitating continual learning without expensive LLM fine-tuning. Our comprehensive experiments show that SCALE significantly outperforms both few-shot LLMs (GPT-4) and specialized models (NLLB) in challenging low-resource settings. Moreover, in Xhosa to English translation, SCALE experiences consistent improvement by a 4 BLEURT score without tuning LLM and surpasses few-shot GPT-4 by 2.5 COMET score and 3.8 BLEURT score when equipped with a compact model consisting of merely 600M parameters. SCALE could also effectively exploit the existing language bias of LLMs by using an English-centric STM as a pivot for translation between any language pairs, outperforming few-shot GPT-4 by an average of 6 COMET points across eight translation directions. Furthermore we provide an in-depth analysis of SCALE's robustness, translation characteristics, and latency costs, providing solid foundation for future studies exploring the potential synergy between LLMs and more specialized, task-specific models.
Weakly Supervised Regression with Interval Targets
Jun 18, 2023

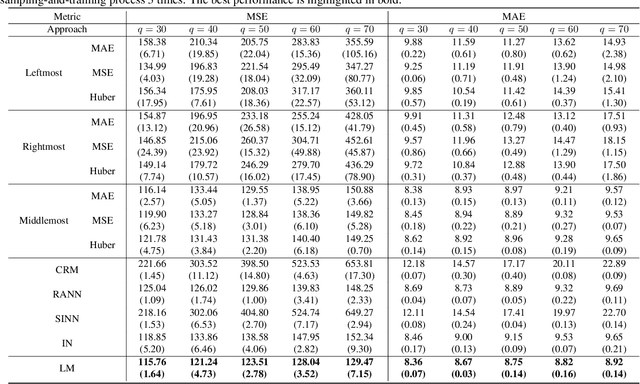
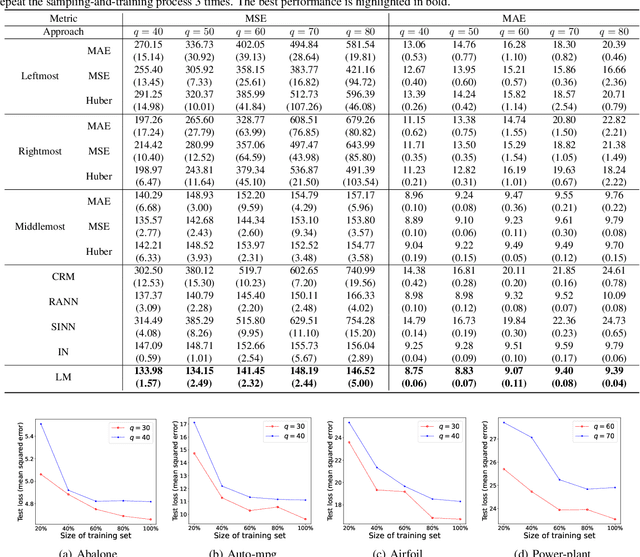
This paper investigates an interesting weakly supervised regression setting called regression with interval targets (RIT). Although some of the previous methods on relevant regression settings can be adapted to RIT, they are not statistically consistent, and thus their empirical performance is not guaranteed. In this paper, we provide a thorough study on RIT. First, we proposed a novel statistical model to describe the data generation process for RIT and demonstrate its validity. Second, we analyze a simple selection method for RIT, which selects a particular value in the interval as the target value to train the model. Third, we propose a statistically consistent limiting method for RIT to train the model by limiting the predictions to the interval. We further derive an estimation error bound for our limiting method. Finally, extensive experiments on various datasets demonstrate the effectiveness of our proposed method.
Partial-Label Regression
Jun 15, 2023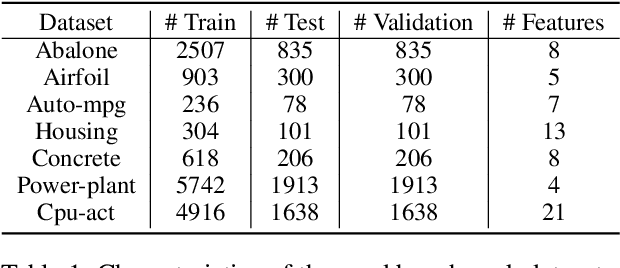
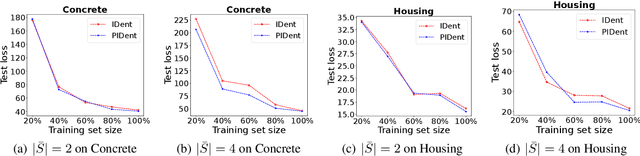
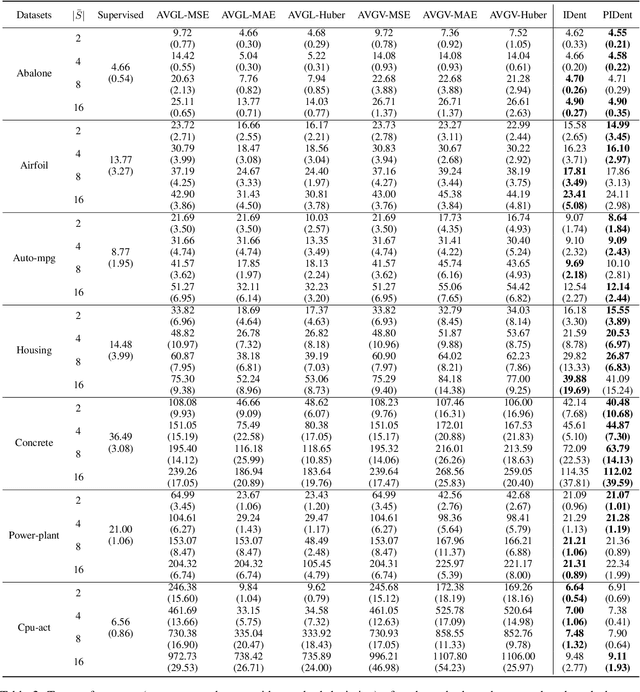
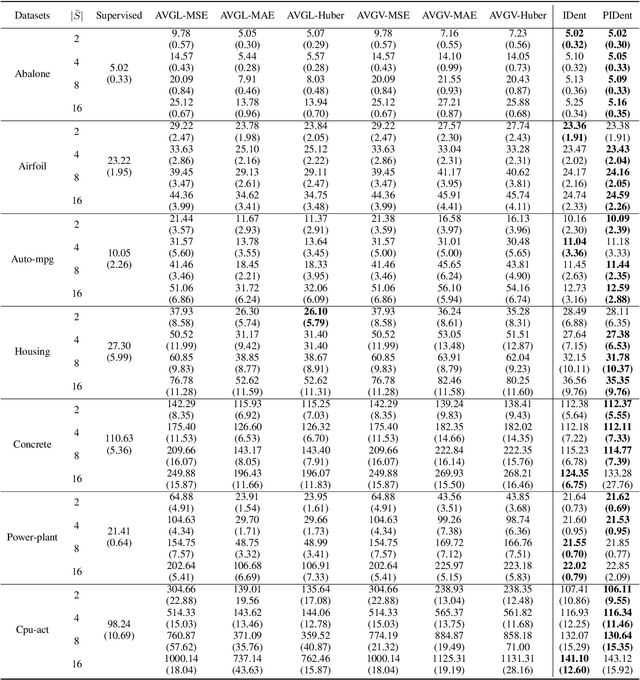
Partial-label learning is a popular weakly supervised learning setting that allows each training example to be annotated with a set of candidate labels. Previous studies on partial-label learning only focused on the classification setting where candidate labels are all discrete, which cannot handle continuous labels with real values. In this paper, we provide the first attempt to investigate partial-label regression, where each training example is annotated with a set of real-valued candidate labels. To solve this problem, we first propose a simple baseline method that takes the average loss incurred by candidate labels as the predictive loss. The drawback of this method lies in that the loss incurred by the true label may be overwhelmed by other false labels. To overcome this drawback, we propose an identification method that takes the least loss incurred by candidate labels as the predictive loss. We further improve it by proposing a progressive identification method to differentiate candidate labels using progressively updated weights for incurred losses. We prove that the latter two methods are model-consistent and provide convergence analyses. Our proposed methods are theoretically grounded and can be compatible with any models, optimizers, and losses. Experiments validate the effectiveness of our proposed methods.
RWKV: Reinventing RNNs for the Transformer Era
May 22, 2023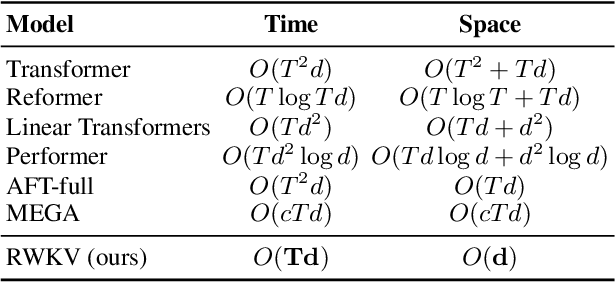

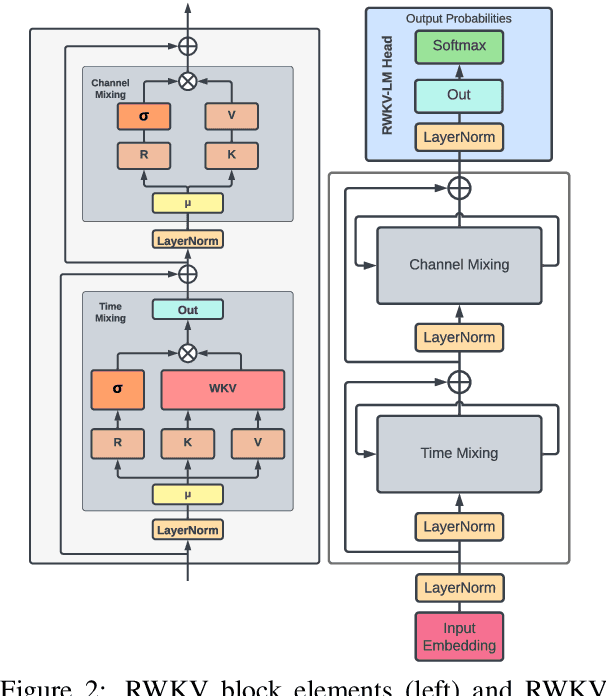
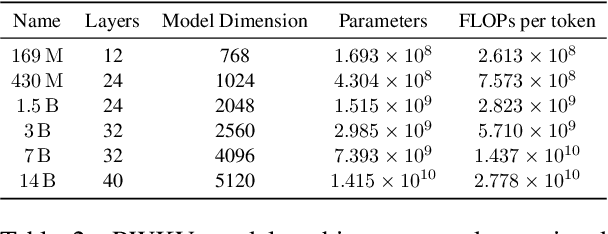
Transformers have revolutionized almost all natural language processing (NLP) tasks but suffer from memory and computational complexity that scales quadratically with sequence length. In contrast, recurrent neural networks (RNNs) exhibit linear scaling in memory and computational requirements but struggle to match the same performance as Transformers due to limitations in parallelization and scalability. We propose a novel model architecture, Receptance Weighted Key Value (RWKV), that combines the efficient parallelizable training of Transformers with the efficient inference of RNNs. Our approach leverages a linear attention mechanism and allows us to formulate the model as either a Transformer or an RNN, which parallelizes computations during training and maintains constant computational and memory complexity during inference, leading to the first non-transformer architecture to be scaled to tens of billions of parameters. Our experiments reveal that RWKV performs on par with similarly sized Transformers, suggesting that future work can leverage this architecture to create more efficient models. This work presents a significant step towards reconciling the trade-offs between computational efficiency and model performance in sequence processing tasks.
A Topic-aware Summarization Framework with Different Modal Side Information
May 19, 2023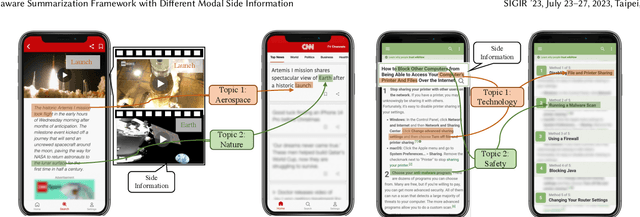
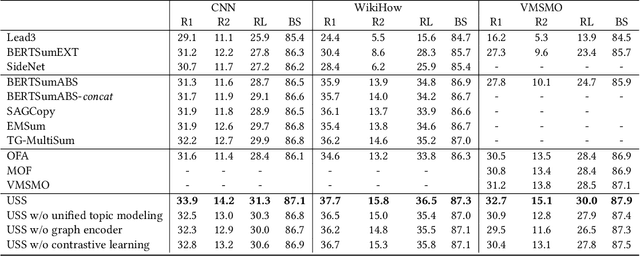
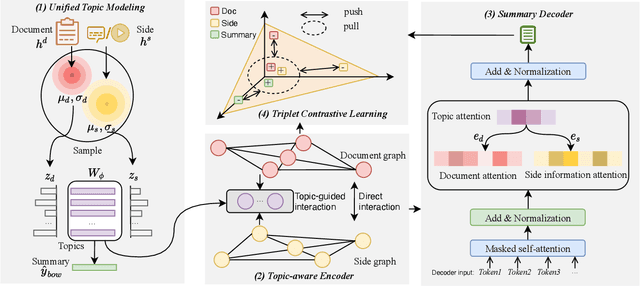
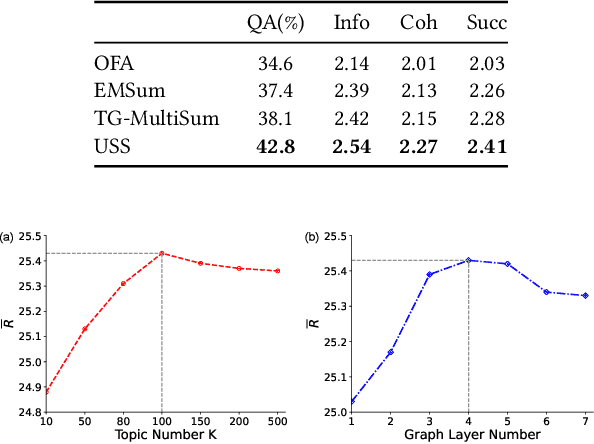
Automatic summarization plays an important role in the exponential document growth on the Web. On content websites such as CNN.com and WikiHow.com, there often exist various kinds of side information along with the main document for attention attraction and easier understanding, such as videos, images, and queries. Such information can be used for better summarization, as they often explicitly or implicitly mention the essence of the article. However, most of the existing side-aware summarization methods are designed to incorporate either single-modal or multi-modal side information, and cannot effectively adapt to each other. In this paper, we propose a general summarization framework, which can flexibly incorporate various modalities of side information. The main challenges in designing a flexible summarization model with side information include: (1) the side information can be in textual or visual format, and the model needs to align and unify it with the document into the same semantic space, (2) the side inputs can contain information from various aspects, and the model should recognize the aspects useful for summarization. To address these two challenges, we first propose a unified topic encoder, which jointly discovers latent topics from the document and various kinds of side information. The learned topics flexibly bridge and guide the information flow between multiple inputs in a graph encoder through a topic-aware interaction. We secondly propose a triplet contrastive learning mechanism to align the single-modal or multi-modal information into a unified semantic space, where the summary quality is enhanced by better understanding the document and side information. Results show that our model significantly surpasses strong baselines on three public single-modal or multi-modal benchmark summarization datasets.
Decouple knowledge from paramters for plug-and-play language modeling
May 19, 2023
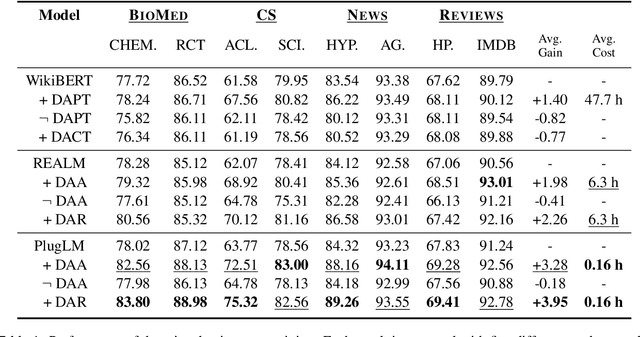
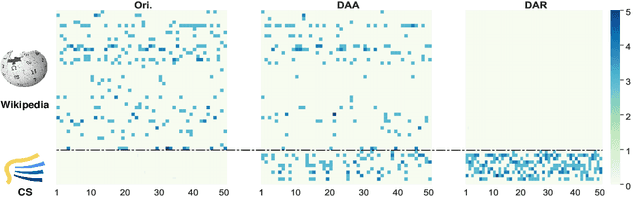
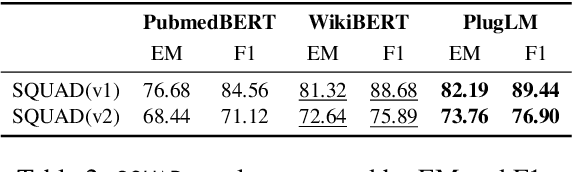
Pre-trained language models(PLM) have made impressive results in various NLP tasks. It has been revealed that one of the key factors to their success is the parameters of these models implicitly learn all kinds of knowledge during pre-training. However, encoding knowledge implicitly in the model parameters has two fundamental drawbacks. First, the knowledge is neither editable nor scalable once the model is trained, which is especially problematic in that knowledge is consistently evolving. Second, it lacks interpretability and prevents humans from understanding which knowledge PLM requires for a certain problem. In this paper, we introduce PlugLM, a pre-training model with differentiable plug-in memory(DPM). The key intuition is to decouple the knowledge storage from model parameters with an editable and scalable key-value memory and leverage knowledge in an explainable manner by knowledge retrieval in the DPM. To justify this design choice, we conduct evaluations in three settings including: (1) domain adaptation. PlugLM obtains 3.95 F1 improvements across four domains on average without any in-domain pre-training. (2) knowledge update. PlugLM could absorb new knowledge in a training-free way after pre-training is done. (3) in-task knowledge learning. PlugLM could be further improved by incorporating training samples into DPM with knowledge prompting.