 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuzhe Huang
Harder Tasks Need More Experts: Dynamic Routing in MoE Models
Mar 12, 2024
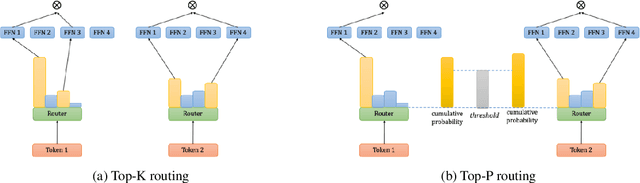
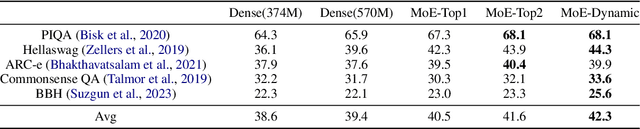
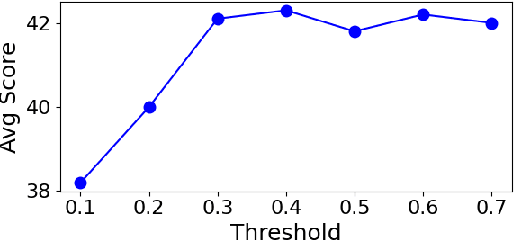
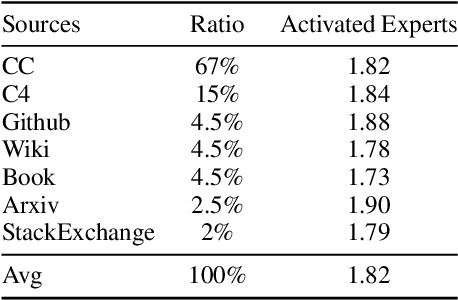
In this paper, we introduce a novel dynamic expert selection framework for Mixture of Experts (MoE) models, aiming to enhance computational efficiency and model performance by adjusting the number of activated experts based on input difficulty. Unlike traditional MoE approaches that rely on fixed Top-K routing, which activates a predetermined number of experts regardless of the input's complexity, our method dynamically selects experts based on the confidence level in expert selection for each input. This allows for a more efficient utilization of computational resources, activating more experts for complex tasks requiring advanced reasoning and fewer for simpler tasks. Through extensive evaluations, our dynamic routing method demonstrates substantial improvements over conventional Top-2 routing across various benchmarks, achieving an average improvement of 0.7% with less than 90% activated parameters. Further analysis shows our model dispatches more experts to tasks requiring complex reasoning skills, like BBH, confirming its ability to dynamically allocate computational resources in alignment with the input's complexity. Our findings also highlight a variation in the number of experts needed across different layers of the transformer model, offering insights into the potential for designing heterogeneous MoE frameworks. The code and models are available at https://github.com/ZhenweiAn/Dynamic_MoE.
Probing Multimodal Large Language Models for Global and Local Semantic Representation
Feb 27, 2024The success of large language models has inspired researchers to transfer their exceptional representing ability to other modalities. Several recent works leverage image-caption alignment datasets to train multimodal large language models (MLLMs), which achieve state-of-the-art performance on image-to-text tasks. However, there are very few studies exploring whether MLLMs truly understand the complete image information, i.e., global information, or if they can only capture some local object information. In this study, we find that the intermediate layers of models can encode more global semantic information, whose representation vectors perform better on visual-language entailment tasks, rather than the topmost layers. We further probe models for local semantic representation through object detection tasks. And we draw a conclusion that the topmost layers may excessively focus on local information, leading to a diminished ability to encode global information.
Video-LaVIT: Unified Video-Language Pre-training with Decoupled Visual-Motional Tokenization
Feb 06, 2024In light of recent advances in multimodal Large Language Models (LLMs), there is increasing attention to scaling them from image-text data to more informative real-world videos. Compared to static images, video poses unique challenges for effective large-scale pre-training due to the modeling of its spatiotemporal dynamics. In this paper, we address such limitations in video-language pre-training with an efficient video decomposition that represents each video as keyframes and temporal motions. These are then adapted to an LLM using well-designed tokenizers that discretize visual and temporal information as a few tokens, thus enabling unified generative pre-training of videos, images, and text. At inference, the generated tokens from the LLM are carefully recovered to the original continuous pixel space to create various video content. Our proposed framework is both capable of comprehending and generating image and video content, as demonstrated by its competitive performance across 13 multimodal benchmarks in image and video understanding and generation. Our code and models will be available at https://video-lavit.github.io.
Relation-Aware Question Answering for Heterogeneous Knowledge Graphs
Dec 19, 2023Multi-hop Knowledge Base Question Answering(KBQA) aims to find the answer entity in a knowledge graph (KG), which requires multiple steps of reasoning. Existing retrieval-based approaches solve this task by concentrating on the specific relation at different hops and predicting the intermediate entity within the reasoning path. During the reasoning process of these methods, the representation of relations are fixed but the initial relation representation may not be optimal. We claim they fail to utilize information from head-tail entities and the semantic connection between relations to enhance the current relation representation, which undermines the ability to capture information of relations in KGs. To address this issue, we construct a \textbf{dual relation graph} where each node denotes a relation in the original KG (\textbf{primal entity graph}) and edges are constructed between relations sharing same head or tail entities. Then we iteratively do primal entity graph reasoning, dual relation graph information propagation, and interaction between these two graphs. In this way, the interaction between entity and relation is enhanced, and we derive better entity and relation representations. Experiments on two public datasets, WebQSP and CWQ, show that our approach achieves a significant performance gain over the prior state-of-the-art. Our code is available on \url{https://github.com/yanmenxue/RAH-KBQA}.
MC^2: A Multilingual Corpus of Minority Languages in China
Nov 14, 2023Large-scale corpora play a vital role in the construction of large language models (LLMs). However, existing LLMs exhibit limited abilities in understanding low-resource languages, including the minority languages in China, due to a lack of training data. To improve the accessibility of these languages, we present MC^2, a Multilingual Corpus of Minority Languages in China, which is the largest open-source corpus so far. It encompasses four underrepresented languages, i.e., Tibetan, Uyghur, Kazakh in the Kazakh Arabic script, and Mongolian in the traditional Mongolian script. Notably, two writing systems in MC^2 are long neglected in previous corpora. As we identify serious contamination in the low-resource language split in the existing multilingual corpora, we propose a quality-centric solution for collecting MC^2, prioritizing quality and accuracy while enhancing representativeness and diversity. By in-depth analysis, we demonstrate the new research challenges MC^2 brings, such as long-text modeling and multiplicity of writing systems. We hope MC^2 can help enhance the equity of the underrepresented languages in China and provide a reliable data foundation for further research on low-resource languages.
From Simple to Complex: A Progressive Framework for Document-level Informative Argument Extraction
Oct 25, 2023Document-level Event Argument Extraction (EAE) requires the model to extract arguments of multiple events from a single document. Considering the underlying dependencies between these events, recent efforts leverage the idea of "memory", where the results of already predicted events are cached and can be retrieved to help the prediction of upcoming events. These methods extract events according to their appearance order in the document, however, the event that appears in the first sentence does not mean that it is the easiest to extract. Existing methods might introduce noise to the extraction of upcoming events if they rely on an incorrect prediction of previous events. In order to provide more reliable memory, we propose a simple-to-complex progressive framework for document-level EAE. Specifically, we first calculate the difficulty of each event and then, we conduct the extraction following a simple-to-complex order. In this way, the memory will store the most certain results, and the model could use these reliable sources to help the prediction of more difficult events. Experiments on WikiEvents show that our model outperforms SOTA by 1.4% in F1, indicating the proposed simple-to-complex framework is useful in the EAE task.
Unified Language-Vision Pretraining in LLM with Dynamic Discrete Visual Tokenization
Sep 29, 2023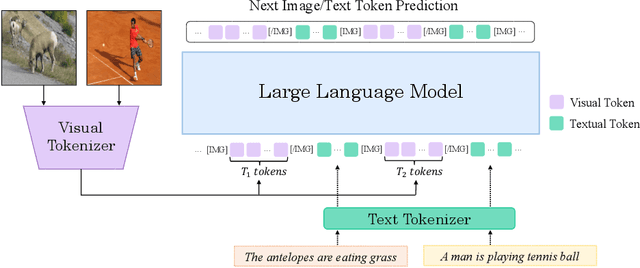
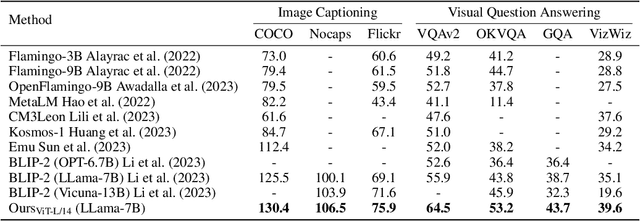
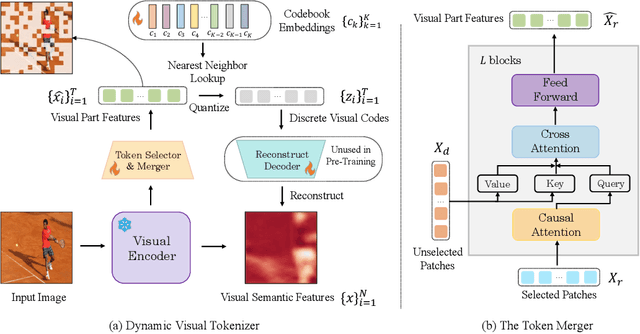
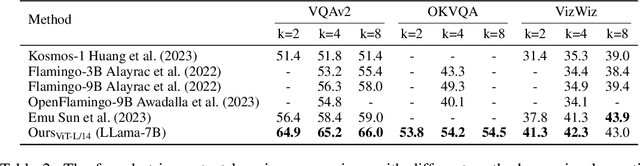
Recently, the remarkable advance of the Large Language Model (LLM) has inspired researchers to transfer its extraordinary reasoning capability to both vision and language data. However, the prevailing approaches primarily regard the visual input as a prompt and focus exclusively on optimizing the text generation process conditioned upon vision content by a frozen LLM. Such an inequitable treatment of vision and language heavily constrains the model's potential. In this paper, we break through this limitation by representing both vision and language in a unified form. Specifically, we introduce a well-designed visual tokenizer to translate the non-linguistic image into a sequence of discrete tokens like a foreign language that LLM can read. The resulting visual tokens encompass high-level semantics worthy of a word and also support dynamic sequence length varying from the image. Coped with this tokenizer, the presented foundation model called LaVIT can handle both image and text indiscriminately under the same generative learning paradigm. This unification empowers LaVIT to serve as an impressive generalist interface to understand and generate multi-modal content simultaneously. Extensive experiments further showcase that it outperforms the existing models by a large margin on massive vision-language tasks. Our code and models will be available at https://github.com/jy0205/LaVIT.
More than Classification: A Unified Framework for Event Temporal Relation Extraction
May 28, 2023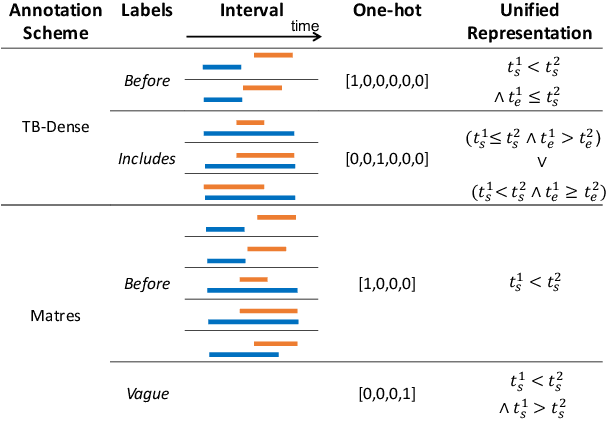
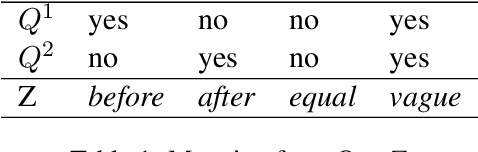
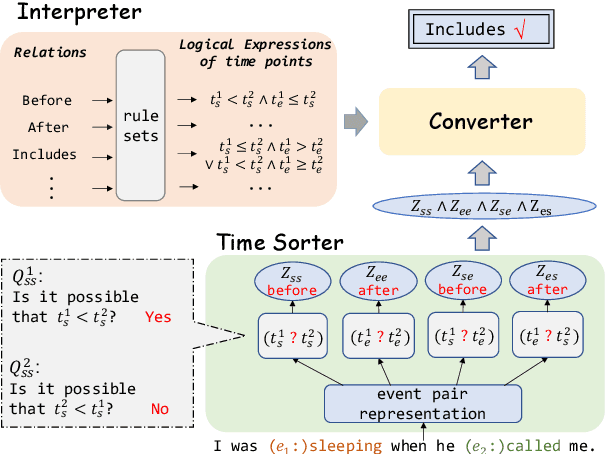

Event temporal relation extraction~(ETRE) is usually formulated as a multi-label classification task, where each type of relation is simply treated as a one-hot label. This formulation ignores the meaning of relations and wipes out their intrinsic dependency. After examining the relation definitions in various ETRE tasks, we observe that all relations can be interpreted using the start and end time points of events. For example, relation \textit{Includes} could be interpreted as event 1 starting no later than event 2 and ending no earlier than event 2. In this paper, we propose a unified event temporal relation extraction framework, which transforms temporal relations into logical expressions of time points and completes the ETRE by predicting the relations between certain time point pairs. Experiments on TB-Dense and MATRES show significant improvements over a strong baseline and outperform the state-of-the-art model by 0.3\% on both datasets. By representing all relations in a unified framework, we can leverage the relations with sufficient data to assist the learning of other relations, thus achieving stable improvement in low-data scenarios. When the relation definitions are changed, our method can quickly adapt to the new ones by simply modifying the logic expressions that map time points to new event relations. The code is released at \url{https://github.com/AndrewZhe/A-Unified-Framework-for-ETRE}.
Lawyer LLaMA Technical Report
May 24, 2023
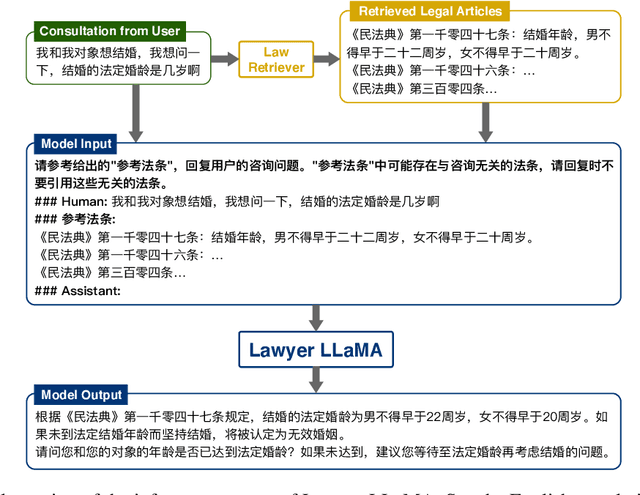

Large Language Models (LLMs), like LLaMA, have exhibited remarkable performances across various tasks. Nevertheless, when deployed to specific domains such as law or medicine, the models still confront the challenge of a deficiency in domain-specific knowledge and an inadequate capability to leverage that knowledge to resolve domain-related problems. In this paper, we focus on the legal domain and explore how to inject domain knowledge during the continual training stage and how to design proper supervised finetune tasks to help the model tackle practical issues. Moreover, to alleviate the hallucination problem during model's generation, we add a retrieval module and extract relevant articles before the model answers any queries. Augmenting with the extracted evidence, our model could generate more reliable responses. We release our data and model at https://github.com/AndrewZhe/lawyer-llama.
Do Charge Prediction Models Learn Legal Theory?
Oct 31, 2022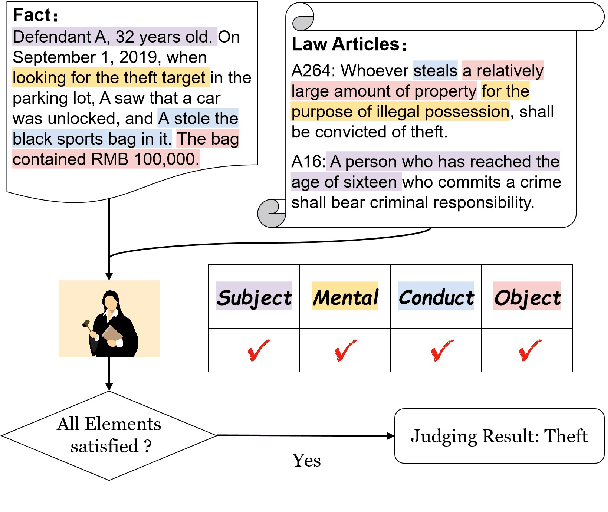
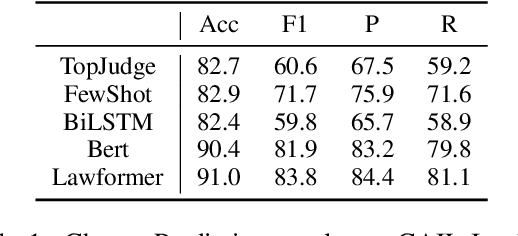


The charge prediction task aims to predict the charge for a case given its fact description. Recent models have already achieved impressive accuracy in this task, however, little is understood about the mechanisms they use to perform the judgment.For practical applications, a charge prediction model should conform to the certain legal theory in civil law countries, as under the framework of civil law, all cases are judged according to certain local legal theories. In China, for example, nearly all criminal judges make decisions based on the Four Elements Theory (FET).In this paper, we argue that trustworthy charge prediction models should take legal theories into consideration, and standing on prior studies in model interpretation, we propose three principles for trustworthy models should follow in this task, which are sensitive, selective, and presumption of innocence.We further design a new framework to evaluate whether existing charge prediction models learn legal theories. Our findings indicate that, while existing charge prediction models meet the selective principle on a benchmark dataset, most of them are still not sensitive enough and do not satisfy the presumption of innocence. Our code and dataset are released at https://github.com/ZhenweiAn/EXP_LJP.